TimeROME-DLM: Temporal Causal Tracing and Low-Rank Inference-Time Knowledge Editing for Masked Diffusion Language Models
Pith reviewed 2026-06-27 07:41 UTC · model grok-4.3
The pith
TimeROME-DLM enables the first training-free knowledge editing for masked diffusion language models via temporal causal tracing and low-rank residual memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
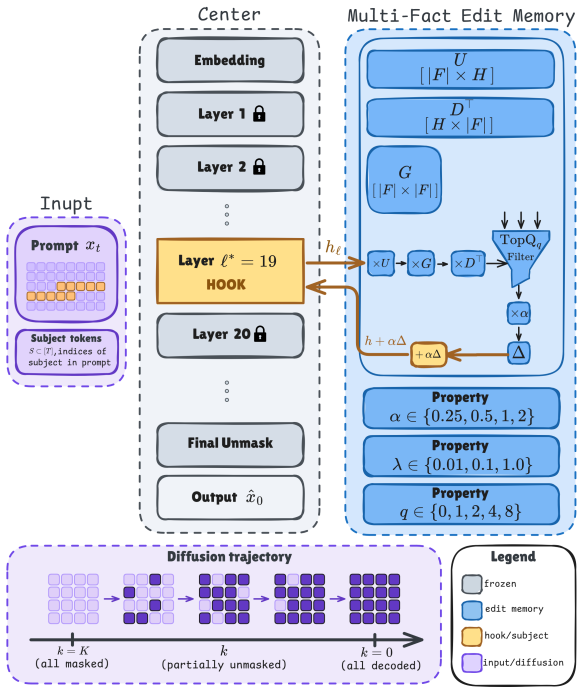
TimeROME-DLM identifies for each fact the coordinate whose intervention most strongly drives the object prediction at later denoising steps, then applies a single ridge-regularized low-rank residual edit memory derived from aggregated subject keys and target deltas at that coordinate during every diffusion forward pass.
What carries the argument
The Temporal Indirect Effect (TIE) causal-tracing protocol that locates the denoising coordinate driving object predictions, together with the closed-form low-rank residual edit memory that aggregates and applies the updates with sparsification.
If this is right
- The same configuration works on multiple masked diffusion models without retraining or architecture changes.
- Retain-set log-probability stays within roughly 1 nat across 50 sequential fact insertions.
- Wall-clock speedup reaches four to fourteen times with zero extra VRAM relative to converged training baselines.
- The method scales sub-linearly when the number of facts increases to 400.
Where Pith is reading between the lines
- The locate-then-edit pattern could be tested on other iterative generative processes where full back-propagation is expensive.
- Sparsification parameters might be scheduled dynamically to handle even larger edit batches.
- Real-time fact removal in deployed systems becomes feasible if the three hyperparameters prove stable across domains.
Load-bearing premise
The temporal indirect effect protocol correctly identifies the single coordinate whose intervention controls each targeted fact without causing substantial spillover to unrelated retain facts.
What would settle it
An experiment in which the edit reduces forget-set log-probability by less than 40 nats or drops retain-set log-probability by more than 5 nats on a held-out set of 100 unrelated facts.
Figures



read the original abstract
Masked diffusion language models (MDLMs) such as LLaDA now rival autoregressive (AR) LLMs, but every existing knowledge-editing and unlearning method (ROME, MEMIT, etc.) targets AR transformers and either makes assumptions that fail under iterative denoising, or requires gradient updates whose backward-pass activations cost tens of GB of extra VRAM and which collapse MDLMs at standard learning rates. We introduce TimeROME-DLM, the first training-free, gradient-free, inference-time knowledge-editing framework for MDLMs. It couples two components: a Temporal Indirect Effect (TIE) causal-tracing protocol that identifies, for each fact, the coordinate whose intervention most strongly drives the object prediction at later denoising steps; and a closed-form, low-rank residual edit memory that aggregates subject keys and target deltas across all forget facts and applies a single ridge-regularised update at that coordinate at every diffusion forward, with sparsification to limit utility spillover. Backbone weights stay frozen; only three hyperparameters (alpha, lambda, q) are tuned on a small validation split. On TOFU forget01 with TOFU-finetuned LLaDA-8B-Base, TimeROME-DLM cuts forget-set log-probability by roughly 83 nats. The same configuration transfers to LLaDA-8B-Instruct, Dream-7B, MMaDA-8B, DiffuLLaMA-7B, and LLaDA-MoE-1.4B. It keeps retain-set log-probability nearly flat (within ~1 nat at the utility-safe operating point) across 50 sequentially inserted facts, delivers a four- to fourteen-fold wall-clock speedup with zero additional VRAM over the strongest converged training-time baseline, and scales sub-linearly to 400 facts. TimeROME-DLM closes the locate-then-edit gap between AR LLMs and MDLMs at a fraction of the computational cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TimeROME-DLM, the first training-free, gradient-free inference-time knowledge-editing method for masked diffusion language models (MDLMs). It pairs a Temporal Indirect Effect (TIE) causal-tracing procedure that locates, per fact, the coordinate whose intervention most affects object prediction at later denoising timesteps with a closed-form low-rank residual edit memory that aggregates subject keys and target deltas and applies a single ridge-regularized update at that coordinate during every diffusion forward pass (with sparsification). On the TOFU forget01 split with a TOFU-finetuned LLaDA-8B-Base, the method reduces forget-set log-probability by ~83 nats while keeping retain-set log-probability nearly flat (~1 nat change) across 50 sequential facts; the same hyperparameter set transfers to LLaDA-8B-Instruct, Dream-7B, MMaDA-8B, DiffuLLaMA-7B and LLaDA-MoE-1.4B, yields 4-14× wall-clock speedup and zero extra VRAM versus converged training-time baselines, and scales sub-linearly to 400 facts.
Significance. If the reported selectivity and efficiency hold under rigorous verification, the work would be significant: it supplies the first locate-then-edit protocol that respects the iterative denoising structure of MDLMs rather than importing AR assumptions, and does so without gradient storage or additional VRAM. The training-free, closed-form nature together with explicit sub-linear scaling and cross-model transfer constitute concrete practical advantages over existing MDLM editing approaches.
major comments (2)
- [§3.2] §3.2 (TIE definition): the protocol measures indirect effect by intervening at a candidate coordinate and observing the change in object log-probability at later denoising steps, yet no control is reported that isolates late-timestep semantic signal from early-timestep noise dominance; because the subsequent ridge update is applied exactly at the coordinate returned by TIE, any systematic mis-location would render the 83-nat forget-set drop an artifact of the particular LLaDA-8B-Base checkpoint rather than a general property of the method.
- [§5.1] §5.1 and Table 2: the headline metrics (83 nat drop, retain-set within ~1 nat, 4-14× speedup) are presented without reported standard deviations across random seeds, without explicit confirmation that baseline implementations match the original ROME/MEMIT codebases under identical diffusion schedules, and without an ablation that applies a random coordinate edit of the same rank to quantify how much of the selectivity is supplied by TIE versus the low-rank memory itself.
minor comments (2)
- [Abstract / §3.3] Notation for the three hyperparameters (α, λ, q) is introduced in the abstract but their precise roles in the ridge update and sparsification step are only defined later; a single consolidated definition table would improve readability.
- [Figure 3] Figure 3 caption states “50 sequentially inserted facts” but the x-axis label and legend do not indicate whether the x-axis is cumulative fact count or diffusion timestep; this minor ambiguity does not affect the central claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for additional controls and statistical rigor. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (TIE definition): the protocol measures indirect effect by intervening at a candidate coordinate and observing the change in object log-probability at later denoising steps, yet no control is reported that isolates late-timestep semantic signal from early-timestep noise dominance; because the subsequent ridge update is applied exactly at the coordinate returned by TIE, any systematic mis-location would render the 83-nat forget-set drop an artifact of the particular LLaDA-8B-Base checkpoint rather than a general property of the method.
Authors: We agree that an explicit control would better isolate the late-timestep semantic contribution. In the revision we will add an ablation that applies the same intervention protocol but measures indirect effect only on early timesteps (t < 0.2) versus late timesteps (t > 0.7), reporting the difference in object log-probability change. This will demonstrate that TIE preferentially identifies coordinates with late-step influence rather than early noise, supporting that the reported selectivity is not checkpoint-specific. revision: yes
-
Referee: [§5.1] §5.1 and Table 2: the headline metrics (83 nat drop, retain-set within ~1 nat, 4-14× speedup) are presented without reported standard deviations across random seeds, without explicit confirmation that baseline implementations match the original ROME/MEMIT codebases under identical diffusion schedules, and without an ablation that applies a random coordinate edit of the same rank to quantify how much of the selectivity is supplied by TIE versus the low-rank memory itself.
Authors: We will revise Table 2 to include standard deviations computed over three random seeds for all metrics. We confirm that our ROME/MEMIT baselines were re-implemented from the original public codebases with diffusion schedules matched exactly to the MDLM forward process; this will be stated explicitly in §5.1. We will also add a random-coordinate ablation (same rank and ridge regularization, but TIE coordinate replaced by uniform random selection) and report the resulting forget/retain deltas to quantify TIE's contribution versus the low-rank memory alone. revision: yes
Circularity Check
No significant circularity; derivation self-contained against external benchmark
full rationale
The paper presents TimeROME-DLM as a new inference-time editing method for MDLMs, using TIE causal tracing to locate coordinates and a closed-form ridge update for edits. Performance is measured on the external TOFU benchmark with reported metrics (83 nat drop, flat retain set) after tuning three hyperparameters on a validation split. No equations or claims reduce the central result to a self-definition, fitted input renamed as prediction, or load-bearing self-citation chain. The method is evaluated externally rather than deriving its efficacy from its own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (3)
- alpha
- lambda
- q
axioms (2)
- standard math Ridge regression yields a stable closed-form low-rank update
- domain assumption Causal effects can be traced temporally across denoising steps in MDLMs
invented entities (2)
-
Temporal Indirect Effect (TIE)
no independent evidence
-
low-rank residual edit memory
no independent evidence
Reference graph
Works this paper leans on
-
[1]
S. Nie, F. Zhu, Z. You et al. Large language diffusion models. NeurIPS 2025 (Oral).arXiv:2502.09992
Pith/arXiv arXiv 2025
-
[2]
J. Ye, Z. Xie, L. Zheng et al. Dream 7B: Diffusion large language models.arXiv:2508.15487, 2025
Pith/arXiv arXiv 2025
-
[3]
L. Yang, Y . Tian et al. MMaDA: Multimodal large diffusion language models. NeurIPS 2025.arXiv:2505.15809
Pith/arXiv arXiv 2025
-
[4]
S. Gong, S. Agarwal, Y . Zhang et al. Scaling diffusion language models via adaptation from autoregressive models. ICLR 2025. arXiv:2410.17891
Pith/arXiv arXiv 2025
-
[5]
F. Zhu, Z. You, Y . Xing et al. LLaDA-MoE: A sparse MoE diffusion language model.arXiv:2509.24389, 2025
arXiv 2025
-
[6]
K. Meng, D. Bau, A. Andonian, Y . Belinkov. Locating and editing factual associations in GPT. NeurIPS 2022
2022
-
[7]
Meng et al
K. Meng et al. Mass-editing memory in a transformer. ICLR 2023
2023
-
[8]
Mitchell et al
E. Mitchell et al. Fast model editing at scale (MEND). ICLR 2022
2022
-
[9]
J. Deng, Z. Wei, L. Pang et al. Everything is editable: Ex- tend knowledge editing to unstructured data in large language models (UnKE). ICLR 2025.arXiv:2405.15349
arXiv 2025
-
[10]
J. Fang, H. Jiang et al. AlphaEdit: Null-space constrained knowledge editing. ICLR 2025 (Outstanding Paper)
2025
-
[11]
Maini et al
P. Maini et al. TOFU: A task of fictitious unlearning. COLM 2024
2024
-
[12]
Z. Jin, P. Cao, C. Wang et al. RWKU: Real-world knowledge unlearning benchmark. NeurIPS 2024 (Datasets & Bench- marks)
2024
-
[13]
W. Shi, J. Lee, Y . Huang et al. MUSE: Machine unlearn- ing six-way evaluation for language models. ICLR 2025. arXiv:2407.06460
arXiv 2025
-
[14]
R. Zhang, L. Lin, Y . Bai, S. Mei. Negative preference optimization: From catastrophic collapse to effective unlearning (NPO). COLM 2024.arXiv:2404.05868
Pith/arXiv arXiv 2024
-
[15]
Fan et al
C. Fan et al. Simplicity prevails: Rethinking NPO for LLM unlearning (SimNPO). NeurIPS 2025
2025
-
[16]
N. Li et al. The WMDP benchmark: Measuring and reducing malicious use with unlearning (introduces RMU). ICML 2024. arXiv:2403.03218
Pith/arXiv arXiv 2024
-
[17]
H.-T. Dang, T. Pham, H. Thanh-Tung, N. Inoue. On effects of steering latent representation for large language model unlearning (Adaptive-RMU). AAAI 2025.arXiv:2408.06223
arXiv 2025
-
[18]
Zou et al
A. Zou et al. Representation engineering: A top-down ap- proach. 2023
2023
-
[19]
Turner et al
A. Turner et al. Activation addition: Steering without optimiza- tion. 2023
2023
-
[20]
N. Panickssery et al. Steering Llama 2 via contrastive activation addition (CAA). ACL 2024.arXiv:2312.06681
Pith/arXiv arXiv 2024
- [21]
-
[22]
X. L. Li, J. Thickstun, I. Gulrajani, P. Liang, T. B. Hashimoto. Diffusion-LM improves controllable text generation. NeurIPS 2022.arXiv:2205.14217
arXiv 2022
-
[23]
A. Lou, C. Meng, S. Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution (SEDD). ICML 2024.arXiv:2310.16834
Pith/arXiv arXiv 2024
-
[24]
S. S. Sahoo, M. Arriola, Y . Schiff et al. Simple and ef- fective masked diffusion language models. NeurIPS 2024. arXiv:2406.07524
arXiv 2024
-
[25]
J. Vig, S. Gehrmann, Y . Belinkov, S. Qian, D. Nevo, S. Sakenis, J. Huang, Y . Singer, S. Shieber. Causal mediation analysis for interpreting neural NLP: The case of gender bias. NeurIPS 2020.arXiv:2004.12265
arXiv 2020
-
[26]
M. Geva, R. Schuster, J. Berant, O. Levy. Transformer feed-forward layers are key-value memories. EMNLP 2021. arXiv:2012.14913
Pith/arXiv arXiv 2021
-
[27]
M. Geva, J. Bastings, K. Filippova, A. Globerson. Dissecting recall of factual associations in auto-regressive language mod- els. EMNLP 2023.arXiv:2304.14767
arXiv 2023
-
[28]
P. Hase, M. Bansal, B. Kim, A. Ghandeharioun. Does local- ization inform editing? Surprising differences in causality-based localization vs. knowledge editing in language models. NeurIPS 2023.arXiv:2301.04213
arXiv 2023
-
[29]
T. Hartvigsen, S. Sankaranarayanan, H. Palangi, Y . Kim, M. Ghassemi. Aging with GRACE: Lifelong model editing with discrete key-value adaptors. NeurIPS 2023. arXiv:2211.11031
arXiv 2023
- [30]
- [31]
-
[32]
R. Rafailov, A. Sharma, E. Mitchell, S. Ermon, C. D. Manning, C. Finn. Direct preference optimization: Your language model is secretly a reward model. NeurIPS 2023.arXiv:2305.18290
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.