EDEN: A Large-Scale Corpus of Clinical Notes for Italian
Pith reviewed 2026-06-27 09:47 UTC · model grok-4.3
The pith
EDEN introduces the largest freely available corpus of Italian clinical notes from emergency departments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EDEN is a large-scale corpus of clinical notes produced in Emergency Departments of Italian hospitals, composed of approximately 4 million fully anonymized notes covering diverse phases of patient care, with a subset of about six thousand notes manually annotated by clinical experts through a structured Case Report Form containing 132 items of numerical, categorical, binary, and mixed types. The dataset is presented as the largest freely available corpus of clinical notes for the Italian language and is offered to support development of large language models in concrete medical applications.
What carries the argument
The EDEN corpus, constructed via an on-site anonymisation pipeline and iterative multi-clinician annotation on a 132-item Case Report Form (CRF).
If this is right
- The corpus enables training and evaluation of large language models on Italian medical text for emergency-care tasks.
- CRF-filling is introduced as a structured information-extraction benchmark with provided zero-shot baselines.
- The annotated notes support work on dyspnea and loss-of-consciousness cases with mixed numerical, categorical and binary fields.
- The scale of 4 million notes allows exploration of data-hungry clinical NLP methods in a non-English setting.
Where Pith is reading between the lines
- Comparable corpora for other languages could be assembled using the same on-site anonymisation and CRF protocol to test cross-lingual medical LLM performance.
- The high imbalance noted in the 132-item annotations offers a natural test bed for methods that handle rare clinical events.
- Combining EDEN with existing English clinical corpora could reveal whether cross-lingual transfer improves low-resource medical extraction.
Load-bearing premise
The on-site anonymisation fully protects patient privacy while keeping the notes clinically useful, and the iterative annotation by multiple clinicians produces reliable labels for the 132 CRF items despite class imbalance.
What would settle it
Release of a subset of notes that contain re-identifiable patient details, or demonstration that models fine-tuned on the CRF annotations fail to improve performance on held-out Italian emergency-department notes, would falsify the central utility claim.
Figures


read the original abstract
We present EDEN (Emergency Department Electronic Notes), a new and unique large-scale corpus of clinical notes produced in Emergency Departments of Italian hospitals. The corpus, in its current version, is composed of approximately 4 million clinical notes fully anonymized, covering diverse phases of patient care during the stay in the emergency department. In addition, a subset of about six thousand notes has been manually annotated by clinical experts through a structured Case Report Form (CRF) containing 132 items relevant for two patient situations in emergency departments, dyspnea and loss of consciousness. Items may assume numerical values (e.g., for blood saturation), categorical (e.g., for level of consciousness ), binary (e.g., for presence of traumas), and mixed value types. The annotation process involved multiple clinicians and underwent iterative revision to resolve ambiguities in item formulation, resulting in a richly structured (although high imbalanced) resource. The dataset aims to fill a relevant gap of data able to support both the development and the use of Large Language Models in concrete medical applications. We describe the data collection protocol, the on-site anonymisation pipeline, corpus statistics, and the annotation scheme. Finally, we propose CRF-filling as a novel structured information extraction benchmark, and provide zero-shot baseline resulting from Gemma-27B and MedGemma-27B. To the best of our knowledge, the EDEN dataset is the largest freely available corpus of clinical notes existing for the Italian language.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents EDEN, a corpus of approximately 4 million anonymized Italian clinical notes from emergency departments, including a 6,000-note subset annotated by clinicians with a 132-item CRF for dyspnea and loss of consciousness. It details the data collection, anonymization pipeline, corpus statistics, annotation scheme, and provides zero-shot baselines from Gemma-27B and MedGemma-27B for a proposed CRF-filling benchmark. The authors state that, to the best of their knowledge, this is the largest freely available corpus of clinical notes for Italian.
Significance. If the claims regarding scale, availability, and annotation quality hold, this dataset would represent a valuable contribution to Italian medical NLP by providing a large-scale resource for training and evaluating LLMs in clinical applications. The structured annotations across 132 items could enable fine-grained information extraction tasks, addressing the scarcity of such data in non-English languages. The release of both raw notes and annotated subset with baselines supports reproducibility in the field.
major comments (2)
- [Annotation process] Annotation section: The description of the iterative annotation process with multiple clinicians does not report inter-annotator agreement metrics, Cohen's kappa, or error rates for the 132 CRF items. This is load-bearing for the utility of the annotated 6k-note subset, especially given the explicit mention of high class imbalance.
- [Anonymization pipeline] Anonymization pipeline section: The manuscript describes the on-site pipeline but provides no quantitative assessment (e.g., retained clinical information density or utility metrics post-anonymization) to support the claim that privacy protection does not unduly degrade downstream usability for LLM training or CRF-filling.
minor comments (2)
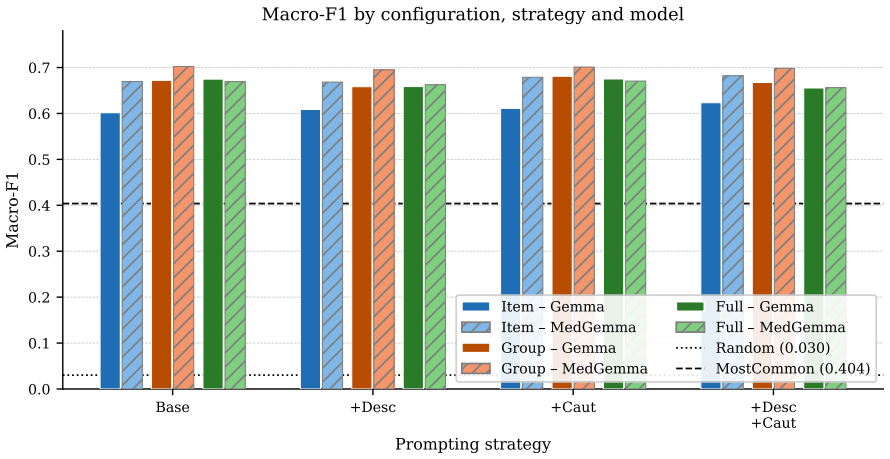
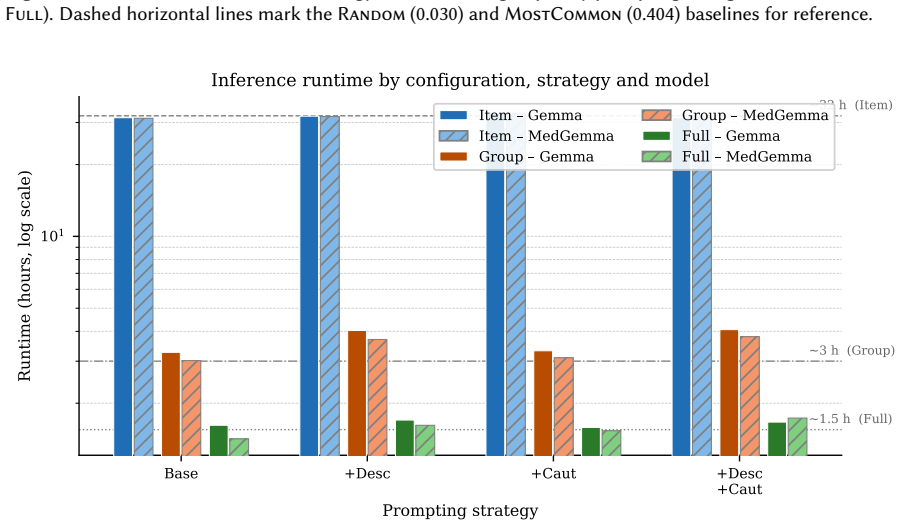
- [Baselines] Abstract and § on baselines: The zero-shot results from Gemma-27B and MedGemma-27B are labeled preliminary; adding a brief error analysis or prompt template would clarify the benchmark's current state without altering the data-release focus.
- [Corpus statistics] Corpus statistics section: Table or figure presenting the 132 CRF items should explicitly note value types (numerical/categorical/binary/mixed) per item to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. We address each major comment below with point-by-point responses.
read point-by-point responses
-
Referee: [Annotation process] Annotation section: The description of the iterative annotation process with multiple clinicians does not report inter-annotator agreement metrics, Cohen's kappa, or error rates for the 132 CRF items. This is load-bearing for the utility of the annotated 6k-note subset, especially given the explicit mention of high class imbalance.
Authors: We agree that inter-annotator agreement metrics would be valuable for assessing the annotated subset. The process involved iterative revisions by multiple clinicians to resolve ambiguities in item formulation, rather than independent parallel annotations on identical notes. This design precludes standard IAA computation such as Cohen's kappa. We will revise the annotation section to explicitly describe the iterative nature of the process and acknowledge the lack of IAA metrics as a limitation, particularly given the noted class imbalance. revision: yes
-
Referee: [Anonymization pipeline] Anonymization pipeline section: The manuscript describes the on-site pipeline but provides no quantitative assessment (e.g., retained clinical information density or utility metrics post-anonymization) to support the claim that privacy protection does not unduly degrade downstream usability for LLM training or CRF-filling.
Authors: We acknowledge that explicit quantitative metrics on post-anonymization information retention would strengthen claims about usability. The manuscript centers on describing the compliant on-site pipeline and releases the data for community use. The provided CRF-filling baselines on the anonymized notes offer an implicit demonstration of downstream applicability. We will add a limitations discussion noting the absence of direct utility metrics and that such evaluations are left for future work. revision: partial
Circularity Check
No significant circularity detected
full rationale
This is a data release paper with no derivations, predictions, fitted parameters, or mathematical claims. The central assertion (largest freely available Italian clinical notes corpus) is an empirical statement about the released resource size and availability, explicitly qualified as 'to the best of our knowledge,' and rests on the described collection and annotation process rather than any self-referential reduction or self-citation chain. Baselines are zero-shot model outputs on the new data and introduce no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
P. Ferrazzi, M. Franzin, A. Lavelli, B. Magnini, Small llms for medical nlp: A systematic analysis of few-shot, constraint decoding, fine-tuning and continual pre-training in italian, in: S. Piperidis, N. Bel, H. van den Heuvel, N. Ide, S. Krek, A. Toral (Eds.), Proceedings of the Fifteenth Language Resources and Evaluation Conference (LREC 2026), Europea...
-
[2]
J. B. Carroll, Language and Thought, Prentice-Hall, Englewood Cliffs, N.J., 1964
1964
-
[3]
Gemma Team, T. Mesnard, C. Hardin, R. Dadashi, et al., Gemma: Open models based on Gemini research and technology, arXiv preprint arXiv:2403.08295 (2024). URL: https://arxiv.org/abs/2403. 08295
Pith/arXiv arXiv 2024
-
[4]
A. Sellergren, S. Kazemzadeh, T. Jaroensri, A. Kiraly, M. Traverse, T. Kohlberger, S. Xu, F. Jamil, C. Hughes, C. Lau, et al., Medgemma technical report, arXiv preprint arXiv:2507.05201 (2025)
Pith/arXiv arXiv 2025
-
[5]
Magnini, B
B. Magnini, B. Altuna, A. Lavelli, A.-L. Minard, M. Speranza, R. Zanoli, European Clinical Case Corpus, Springer International Publishing, Cham, 2023, pp. 283–288. URL: https://doi.org/10.1007/ 978-3-031-17258-8_17
2023
-
[6]
Magnini, B
B. Magnini, B. Altuna, A. Lavelli, M. Speranza, R. Zanoli, The E3C project:collection and annotation of a multilingual corpus of clinical cases, in: J. Monti, F. Dell’Orletta, F. Tamburini (Eds.), Proceed- ings of the Seventh Italian Conference on Computational Linguistics (CLiC-it 2020), CEUR Work- shop Proceedings, Bologna, Italy, 2020, pp. 190–196. URL...
2020
- [7]
-
[8]
A. E. W. Johnson, T. J. Pollard, L. Shen, L.-w. H. Lehman, M. Feng, M. Ghassemi, B. Moody, P. Szolovits, L. A. Celi, R. G. Mark, MIMIC-III, a freely accessible critical care database, Scientific Data 3 (2016) 160035. doi:10.1038/sdata.2016.35
-
[9]
A. E. W. Johnson, L. Bulgarelli, L. Shen, et al., Mimic-iv, a freely accessible electronic health record dataset, Scientific Data 10 (2023) 1. URL: https://doi.org/10.1038/s41597-022-01899-x. doi:10.1038/s41597-022-01899-x , received: 15 August 2022; Accepted: 14 December 2022; Published: 03 January 2023
-
[10]
O. Uzuner, B. R. South, S. Shen, S. L. DuVall, 2010 i2b2/VA challenge on concepts, assertions, and relations in clinical text, Journal of the American Medical Informatics Association 18 (2011) 552–556. doi:10.1136/amiajnl-2011-000203
-
[11]
A. Stubbs, O. Uzuner, Annotating longitudinal clinical narratives for de-identification: The 2014 i2b2/UTHealth corpus, Journal of Biomedical Informatics 58 (2015) S20–S29. doi:10.1016/j.jbi. 2015.07.020
-
[12]
S. Ghosh, B. Altuna, S. Farzi, P. Ferrazzi, A. Lavelli, G. Mezzanotte, M. Speranza, B. Magnini, Low-resource information extraction with the European Clinical Case Corpus, CoRR abs/2503.20568 (2025). URL: https://doi.org/10.48550/arXiv.2503.20568. doi: 10.48550/ARXIV. 2503.20568.arXiv:2503.20568
-
[13]
Zugarini, L
A. Zugarini, L. Rigutini, PharmaER.IT: an Italian dataset for entity recognition in the pharmaceu- tical domain, in: Proceedings of the Eleventh Italian Conference on Computational Linguistics, 2025
2025
-
[14]
Lima-López, E
S. Lima-López, E. Farré-Maduell, J. Rodríguez-Miret, M. Rodríguez-Ortega, L. Lilli, J. Lenkowicz, G. Ceroni, J. Kossoff, A. Shah, A. Nentidis, A. Krithara, G. Katsimpras, G. Paliouras, M. Krallinger, Overview of MultiCardioNER task at BioASQ 2024 on medical specialty and language adaptation of clinical ner systems for Spanish, English and Italian, in: Con...
2024
-
[15]
Miranda-Escalada, L
A. Miranda-Escalada, L. Gasco, S. Lima-López, E. Farré-Maduell, D. Estrada, A. Nentidis, A. Krithara, G. Katsimpras, G. Paliouras, M. Krallinger, Overview of DisTEMIST at BioASQ: Automatic detection and normalization of diseases from clinical texts: results, methods, evaluation and multilingual resources, in: Working Notes of Conference and Labs of the Ev...
2022
-
[17]
A Dynamic Recursive Unified Internet Design (DRUID),
A. Alicante, A. Corazza, F. Isgrò, S. Silvestri, Unsupervised entity and relation extraction from clinical records in italian, Computers in Biology and Medicine 72 (2016) 263–275. URL: https://www. sciencedirect.com/science/article/pii/S001048251630004X. doi:https://doi.org/10.1016/j. compbiomed.2016.01.014
work page doi:10.1016/j 2016
-
[18]
N. Viani, C. Larizza, V. Tibollo, C. Napolitano, S. G. Priori, R. Bellazzi, L. Sacchi, Information extraction from italian medical reports: An ontology-driven approach, International Journal of Medical Informatics 111 (2018) 140–148. URL: https://www.sciencedirect.com/science/article/pii/ S1386505617304586. doi:https://doi.org/10.1016/j.ijmedinf.2017.12.013
-
[19]
Attardi, V
G. Attardi, V. Cozza, D. Sartiano, Adapting linguistic tools for the analysis of italian medical records, in: Proceedings of the First Italian Conference on Computational Linguistics (CLiC-it 2014), volume 1, Pisa, Italy, 2014
2014
-
[20]
W. R. Mac Kenzie, A. J. Davidson, A. Wiesenthal, J. P. Engel, K. Turner, L. Conn, S. J. Becker, S. Moffatt, S. L. Groseclose, J. Jellison, J. Stinn, N. Y. Garrett, L. Helmus, B. Harmon, C. L. Richards, J. R. Lumpkin, M. F. Iademarco, The promise of electronic case reporting, Public Health Reports 131 (2016) 742–746. doi:10.1177/0033354916670871, epub 2016 Oct 13
-
[21]
A. Gutiérrez-Sacristán, S. Makwana, A. Dionne, S. Mahanta, K. J. Dyer, F. Serrano, C. Watrin, P. Pages, S. Mousavi, A. Degala, J. Lyons, D. Pillion, J. M. Zachariasse, L. S. Shekerdemian, D. T. Truong, J. W. Newburger, P. Avillach, Development and validation of an open-source pipeline for automatic population of case report forms from electronic health re...
-
[22]
C. Crema, F. Verde, P. Tiraboschi, C. Marra, A. Arighi, S. Fostinelli, G. M. Giuffré, V. P. D. Maschio, F. L’Abbate, F. Solca, B. Poletti, V. Silani, E. Rotondo, V. Borracci, R. Vimercati, V. Crepaldi, E. Inguscio, M. Filippi, F. Caso, A. M. Rosati, D. Quaranta, G. Binetti, I. Pagnoni, M. Morreale, F. Burgio, M. Stanzani-Maserati, S. Capellari, M. Pardini...
-
[24]
Ferrazzi, S
P. Ferrazzi, S. Ghosh, A. Lavelli, B. Magnini, Overview of the crf 2026 shared task on clinical case report forms filling, in: Proceedings of the Third Workshop on Patient-Oriented Language Processing (CL4Health), ELRA, Palma, Mallorca, Spain, 2026
2026
-
[25]
R. Luo, L. Sun, Y. Xia, T. Qin, S. Zhang, H. Poon, T.-Y. Liu, BioGPT: Generative pre-trained transformer for biomedical text generation and mining, Briefings in Bioinformatics 23 (2022). doi:10.1093/bib/bbac409
-
[26]
Singhal, S
K. Singhal, S. Azizi, T. Tu, S. S. Mahdavi, J. Wei, H. W. Chung, N. Scales, A. Tanwani, H. Cole-Lewis, S. Pfohl, P. Payne, M. Seneviratne, P. Gamble, C. Kelly, A. Babiker, N. Schärli, A. Chowdhery, P. Mansfield, D. Demner-Fushman, B. A. y Arcas, D. Webster, G. S. Corrado, Y. Matias, K. Chou, J. Gottweis, N. Tomasev, Y. Liu, A. Rajkomar, J. Barral, C. Semt...
2023
-
[27]
Z. Chen, A. H. Cano, A. Romanou, A. Bonnet, K. Matoba, F. Salvi, M. Pagliardini, S. Fan, A. Kopf, A. Mohtashami, A. Sallinen, A. Sakhaeirad, V. Swamy, I. Krawczuk, D. Bayazit, A. Marmet, S. Mon- tariol, M.-A. Hartley, M. Jaggi, A. Bosselut, Meditron-70b: Scaling medical pretraining for large language models, 2023. URL: https://arxiv.org/abs/2311.16079.arX...
Pith/arXiv arXiv 2023
-
[28]
C. Wu, W. Lin, X. Zhang, Y. Zhang, W. Xie, Y. Wang, PMC-LLaMA: toward building open-source language models for medicine, Journal of the American Medical Informatics Association 31 (2024) 1833–1843
2024
-
[29]
B io M istral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains
Y. Labrak, A. Bazoge, E. Morin, P.-A. Gourraud, M. Rouvier, R. Dufour, BioMistral: A col- lection of open-source pretrained large language models for medical domains, in: L.-W. Ku, A. Martins, V. Srikumar (Eds.), Findings of the Association for Computational Linguistics: ACL 2024, Association for Computational Linguistics, Bangkok, Thailand, 2024, pp. 584...
-
[30]
Singhal, T
K. Singhal, T. Tu, J. Gottweis, R. Sayres, E. Wulczyn, M. Amin, L. Hou, K. Clark, S. R. Pfohl, H. Cole-Lewis, D. Neal, Q. M. Rashid, M. Schaekermann, A. Wang, D. Dash, J. H. Chen, N. H. Shah, S. Lachgar, P. A. Mansfield, S. Prakash, B. Green, E. Dominowska, B. Agüera y Arcas, N. Tomašev, Y. Liu, R. Wong, C. Semturs, S. S. Mahdavi, J. K. Barral, D. R. Webs...
2025
-
[31]
J.-P. Corbeil, A. Dada, J.-M. Attendu, A. Ben Abacha, A. Sordoni, L. Caccia, F. Beaulieu, T. Lin, J. Kleesiek, P. Vozila, A modular approach for clinical SLMs driven by synthetic data with pre- instruction tuning, model merging, and clinical-tasks alignment, in: W. Che, J. Nabende, E. Shutova, M. T. Pilehvar (Eds.), Proceedings of the 63rd Annual Meeting ...
-
[32]
J. Chen, Z. Cai, K. Ji, X. Wang, W. Liu, R. Wang, B. Wang, Towards medical complex reasoning with LLMs through medical verifiable problems, in: W. Che, J. Nabende, E. Shutova, M. T. Pilehvar (Eds.), Findings of the Association for Computational Linguistics: ACL 2025, Association for Computational Linguistics, Vienna, Austria, 2025, pp. 14552–14573. URL: h...
-
[33]
J. Wu, W. Deng, X. Li, S. Liu, T. Mi, Y. Peng, Z. Xu, Y. Liu, H. Cho, C.-I. Choi, Y. Cao, H. Ren, X. Li, X. Li, Y. Zhou, Medreason: Eliciting factual medical reasoning steps in llms via knowledge graphs,
-
[34]
URL: https://arxiv.org/abs/2504.00993.arXiv:2504.00993
-
[35]
Huang, J
X. Huang, J. Wu, H. Liu, X. Tang, Y. Zhou, m1: Unleash the potential of test-time scaling for medical reasoning in large language models, in: The Second Workshop on GenAI for Health: Potential, Trust, and Policy Compliance, 2025. URL: https://openreview.net/forum?id=9l6unbTnQi
2025
-
[36]
Y. Sun, X. Qian, W. Xu, H. Zhang, C. Xiao, L. Li, D. Zhao, W. Huang, T. Xu, Q. Bai, Y. Rong, ReasonMed: A 370K multi-agent generated dataset for advancing medical reasoning, in: C. Christodoulopoulos, T. Chakraborty, C. Rose, V. Peng (Eds.), Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Association for Computation...
-
[37]
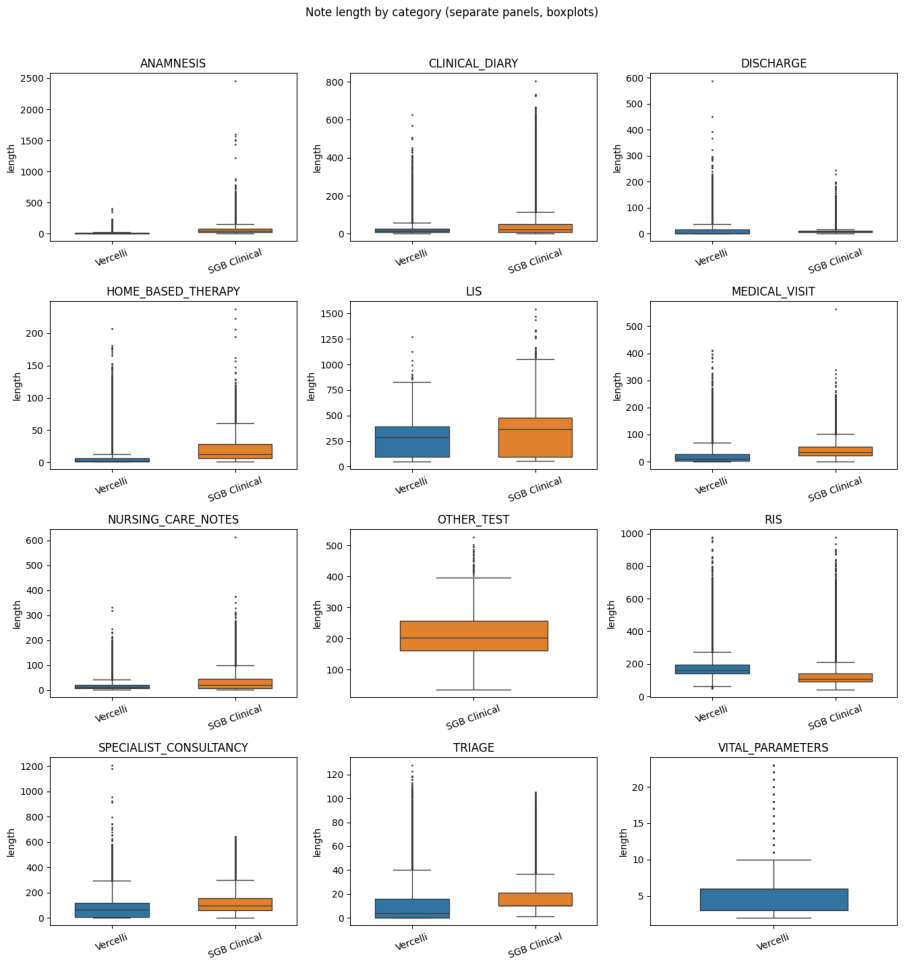
P. Ferrazzi, A. Soroa, R. Agerri, Multilingual medical reasoning for question answering with large language models, 2026. URL: https://arxiv.org/abs/2512.05658.arXiv:2512.05658. A. Note Length Distribution by Category Figure 3 shows the distribution of note lengths (in tokens) across the 12 note categories present in the corpus, broken down by hospital so...
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.