Accelerating Sparse Transformer Inference on GPU
Pith reviewed 2026-05-22 01:12 UTC · model grok-4.3
The pith
STOF accelerates sparse Transformer inference on GPUs by mapping attention to row-wise or blockwise kernels and searching fusion templates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
STOF is a framework that incorporates optimizations for Sparse Transformer that enables flexible masking and Operator Fusion on GPU. For multi-head attention (MHA) structure, STOF maps the computation to row-wise or blockwise kernels with unique storage formats according to analytical modeling. For downstream operators, STOF maps the fusion scheme to compilation templates and determines the optimal running configuration through two-stage searching. The experimental results show that compared to the state-of-the-art work, STOF achieves maximum speedups of 1.6x in MHA computation and 1.4x in end-to-end inference.
What carries the argument
Analytical modeling to select row-wise versus blockwise kernels for MHA plus two-stage search over compilation templates for downstream operator fusion.
If this is right
- MHA computation in sparse Transformers runs faster when the kernel layout matches the sparsity pattern through modeling.
- End-to-end inference time decreases when fusion schemes are chosen by searching compilation templates rather than using static rules.
- Flexible masking becomes practical on GPUs because the framework adapts storage and execution to the mask without manual rewriting.
- Speedups of 1.6x in attention and 1.4x overall hold when the two-stage search converges on good templates for the target hardware.
Where Pith is reading between the lines
- The same modeling and search approach could be applied to other sparse operators beyond attention to compound gains in full model inference.
- Extending the analytical model to predict energy use in addition to latency would help deployment decisions for large-scale LLM serving.
- Testing the framework on emerging GPU architectures would reveal whether the row-versus-block decision rules remain stable or need recalibration.
Load-bearing premise
Analytical modeling of GPU kernel performance for row-wise versus blockwise mappings, together with two-stage template search, will reliably identify optimal configurations across diverse sparse masks and hardware.
What would settle it
Running STOF on a new sparse mask pattern or different GPU model and finding that a hand-tuned or alternative kernel choice runs faster than the automatically selected configuration.
Figures






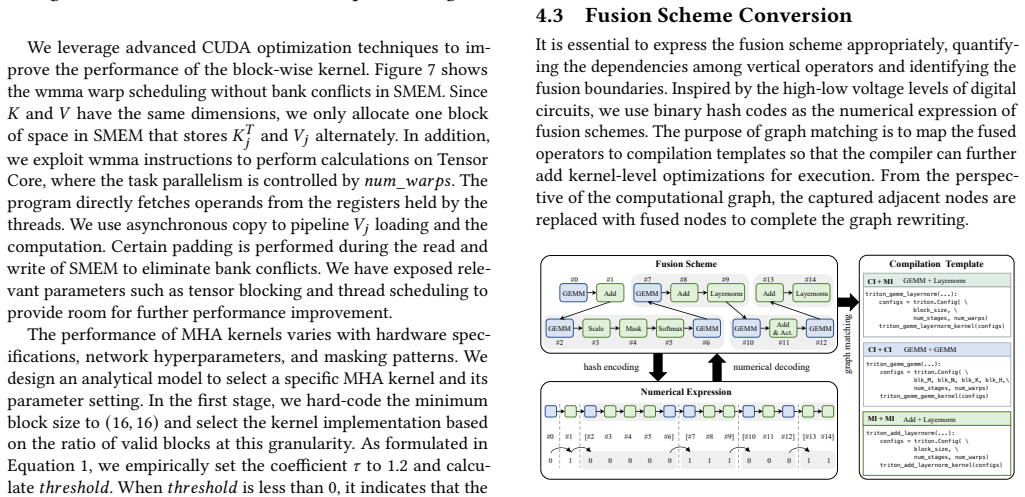
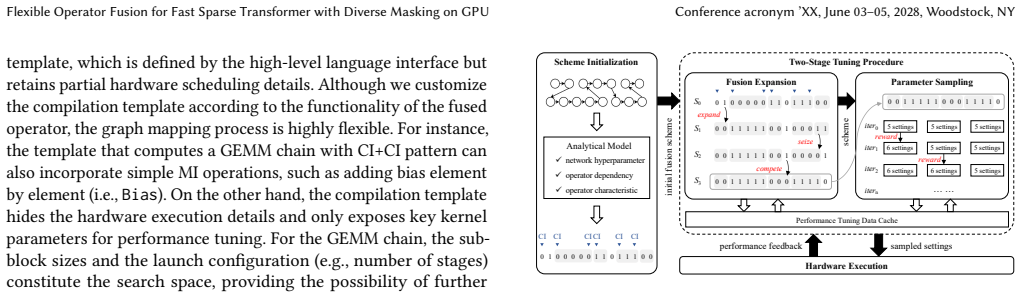

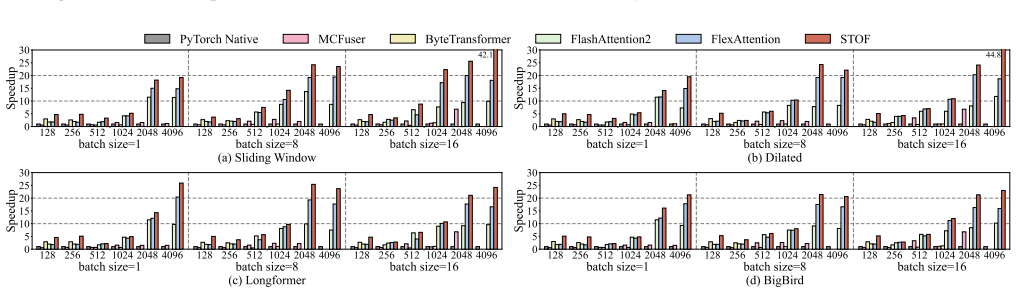



read the original abstract
Large language models (LLMs) are popular around the world due to their powerful understanding capabilities. As the core component of LLMs, accelerating Transformer through parallelization has gradually become a hot research topic. Mask layers introduce sparsity into Transformer to reduce calculations. However, previous works rarely focus on the performance optimization of sparse Transformer. In addition, current static operator fusion schemes fail to adapt to diverse application scenarios. To address the above problems, we propose STOF, a framework that incorporates optimizations for Sparse Transformer that enables flexible masking and Operator Fusion on GPU. For multi-head attention (MHA) structure, STOF maps the computation to row-wise or blockwise kernels with unique storage formats according to analytical modeling. For downstream operators, STOF maps the fusion scheme to compilation templates and determines the optimal running configuration through two-stage searching. The experimental results show that compared to the stateof-the-art work, STOF achieves maximum speedups of 1.6x in MHA computation and 1.4x in end-to-end inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes STOF, a framework for accelerating sparse Transformer inference on GPUs. It enables flexible masking and operator fusion by mapping MHA computations to row-wise or blockwise kernels (with tailored storage formats) via analytical performance modeling, and by mapping downstream operator fusion to compilation templates whose optimal configurations are selected via two-stage search. Experiments are reported to yield maximum speedups of 1.6x in MHA and 1.4x end-to-end versus prior state-of-the-art work.
Significance. If the modeling and search reliably generalize, the work could deliver practical speedups for sparse Transformer deployments on GPUs. The combination of analytical modeling with lightweight search is a potentially efficient alternative to exhaustive autotuning or purely static fusion, provided the predictions hold across varied sparsity patterns and hardware.
major comments (2)
- The central claim that analytical modeling of row-wise versus blockwise kernel performance, together with two-stage search, identifies configurations that generalize to diverse sparse masks and hardware (abstract and STOF design description) is load-bearing for the adaptability and speedup assertions. The manuscript provides no explicit validation of the modeling equations or search procedure on held-out mask families, alternate densities, or different GPU architectures; without such evidence the reported 1.6x/1.4x gains risk being instance-specific rather than framework-driven.
- Experimental results section: the maximum speedups are stated without accompanying details on sparsity densities, mask generation methods, number of runs, error bars, or the precise set of baselines and datasets. This absence prevents assessment of whether the gains are robust or sensitive to post-hoc configuration choices.
minor comments (2)
- Abstract: 'stateof-the-art' is missing a hyphen.
- Notation for the unique storage formats associated with row-wise and blockwise mappings should be introduced explicitly when first used.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We provide detailed responses to each major comment below and indicate the revisions we plan to make to address the concerns raised.
read point-by-point responses
-
Referee: The central claim that analytical modeling of row-wise versus blockwise kernel performance, together with two-stage search, identifies configurations that generalize to diverse sparse masks and hardware (abstract and STOF design description) is load-bearing for the adaptability and speedup assertions. The manuscript provides no explicit validation of the modeling equations or search procedure on held-out mask families, alternate densities, or different GPU architectures; without such evidence the reported 1.6x/1.4x gains risk being instance-specific rather than framework-driven.
Authors: We recognize that the manuscript does not present explicit validation on held-out data or different hardware. The modeling equations are derived from analytical performance models based on GPU memory hierarchy and arithmetic intensity, which are intended to be general. However, to fully substantiate the generalization claim, we will add experiments validating the model predictions on additional mask families and report results on a second GPU architecture in the revised manuscript. We have also clarified in the design section how the two-stage search adapts to new configurations. revision: yes
-
Referee: Experimental results section: the maximum speedups are stated without accompanying details on sparsity densities, mask generation methods, number of runs, error bars, or the precise set of baselines and datasets. This absence prevents assessment of whether the gains are robust or sensitive to post-hoc configuration choices.
Authors: We agree with the referee that additional experimental details are necessary. The revised manuscript now includes: sparsity densities used in experiments (e.g., 25%, 50%, 75% sparsity), mask generation methods (random masking and block-sparse patterns), number of runs (10 runs per configuration with mean and standard deviation reported), error bars in all figures, the full list of baselines with citations, and the specific datasets for end-to-end inference (e.g., language modeling tasks). These additions will allow readers to better evaluate the robustness of the reported speedups. revision: yes
Circularity Check
No circularity: engineering framework with independent experimental validation
full rationale
The paper describes STOF as a GPU optimization framework that applies analytical modeling to select row-wise or blockwise kernels for MHA and uses two-stage search over compilation templates for operator fusion. No equations, fitted parameters presented as predictions, or self-citation chains are invoked to derive the reported speedups. The 1.6x MHA and 1.4x end-to-end gains are measured against external SOTA baselines on concrete hardware and masks, making the contribution self-contained rather than tautological. This is a standard engineering result with no load-bearing derivation that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Analytical modeling can accurately predict and select between row-wise and blockwise kernel performance for sparse MHA on GPU hardware.
- domain assumption Two-stage search over compilation templates will identify near-optimal fusion configurations for downstream operators.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
STOF maps the computation to row-wise or blockwise kernels with unique storage formats according to analytical modeling... two-stage searching
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose STOF, a framework that incorporates optimizations for Sparse Transformer via flexible masking and operator fusion on GPU
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. GPT-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Muhammad Adnan, Akhil Arunkumar, Gaurav Jain, Prashant Nair, Ilya Solovey- chik, and Purushotham Kamath. 2024. Keyformer: KV cache reduction through key tokens selection for efficient generative inference. In Conference on Machine Learning and Systems. MIT Press, 114–127
work page 2024
-
[3]
Reza Yazdani Aminabadi, Samyam Rajbhandari, Ammar Ahmad Awan, Cheng Li, Du Li, Elton Zheng, Olatunji Ruwase, Shaden Smith, Minjia Zhang, Jeff Rasley, et al. 2022. DeepSpeed Inference: Enabling efficient inference of Transformer models at unprecedented scale. In International Conference on High Performance Computing, Networking, Storage and Analysis . IEEE, 1–15
work page 2022
-
[4]
Jason Ansel, Edward Yang, Horace He, Natalia Gimelshein, Animesh Jain, Michael Voznesensky, Bin Bao, Peter Bell, David Berard, Evgeni Burovski, et al . 2024. PyTorch 2: Faster machine learning through dynamic python bytecode trans- formation and graph compilation. In International Conference on Architectural Support for Programming Languages and Operating...
work page 2024
-
[5]
Zhenyu Bai, Pranav Dangi, Huize Li, and Tulika Mitra. 2024. SWAT: Scalable and efficient window attention-based Transformers acceleration on FPGAs. In Design Automation Conference. ACM, 1–6
work page 2024
-
[6]
Iz Beltagy, Matthew E Peters, and Arman Cohan. 2020. Longformer: The long- document Transformer. arXiv preprint arXiv:2004.05150 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[7]
Lefaudeux Benjamin, Massa Francisco, Liskovich Diana, Xiong Wenhan, Caggiano Vittorio, Naren Sean, Xu Min, Hu Jieru, Tintore Marta, Zhang Su- san, Labatut Patrick, Haziza Daniel, Wehrstedt Luca, Reizenstein Jeremy, and Sizov Grigory. 2022. xFormers: A modular and hackable Transformer modelling library. https://github.com/facebookresearch/xformers
work page 2022
-
[8]
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al . 2024. A survey on evaluation of large language models. ACM Transactions on Intelligent Systems and Technology 15, 3 (2024), 1–45
work page 2024
-
[9]
Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Haichen Shen, Meghan Cowan, Leyuan Wang, Yuwei Hu, Luis Ceze, et al. 2018. TVM: An automated end-to-end optimizing compiler for deep learning. In USENIX Symposium on Operating Systems Design and Implementations . USENIX, 579–594
work page 2018
-
[10]
Zhaodong Chen, Andrew Kerr, Richard Cai, Jack Kosaian, Haicheng Wu, Yufei Ding, and Yuan Xie. 2024. EVT: Accelerating deep learning training with Epilogue Visitor Tree. In International Conference on Architectural Support for Programming Languages and Operating Systems . ACM, 301–316
work page 2024
-
[11]
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. 2019. Generating long sequences with sparse Transformers. arXiv preprint arXiv:1904.10509 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[12]
Younghyun Cho, James W Demmel, Jacob King, Xiaoye S Li, Yang Liu, and Hengrui Luo. 2023. Harnessing the crowd for autotuning high-performance com- puting applications. In International Parallel & Distributed Processing Symposium . IEEE, 635–645
work page 2023
-
[13]
Tri Dao. 2023. FlashAttention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. FlashAt- tention: Fast and memory-efficient exact attention with IO-awareness. Advances in neural information processing systems 35 (2022), 16344–16359
work page 2022
-
[15]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional Transformers for language understanding. In Annual Conference of the North American chapter of the association for computa- tional linguistics: human language technologies . 4171–4186
work page 2019
-
[16]
Juechu Dong, Boyuan Feng, Driss Guessous, Yanbo Liang, and Horace He. 2024. Flex Attention: A programming model for generating optimized attention kernels. arXiv preprint arXiv:2412.05496 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Jack Dongarra, Mark Gates, Jakub Kurzak, Piotr Luszczek, and Yaohung M Tsai
-
[18]
Autotuning numerical dense linear algebra for batched computation with GPU hardware accelerators. Proc. IEEE 106, 11 (2018), 2040–2055
work page 2018
-
[19]
Hongxiang Fan, Thomas Chau, Stylianos I Venieris, Royson Lee, Alexandros Kouris, Wayne Luk, Nicholas D Lane, and Mohamed S Abdelfattah. 2022. Adapt- able butterfly accelerator for attention-based NNs via hardware and algorithm co-design. In IEEE/ACM International Symposium on Microarchitecture . IEEE, 599–615
work page 2022
-
[20]
Jiarui Fang, Yang Yu, Chengduo Zhao, and Jie Zhou. 2021. TurboTransformers: An efficient GPU serving system for Transformer models. In ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming . ACM, 389–402
work page 2021
-
[21]
Yu Gu, Robert Tinn, Hao Cheng, Michael Lucas, Naoto Usuyama, Xiaodong Liu, Tristan Naumann, Jianfeng Gao, and Hoifung Poon. 2021. Domain-specific language model pretraining for biomedical natural language processing. ACM Transactions on Computing for Healthcare 3, 1 (2021), 1–23
work page 2021
-
[22]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Tae Jun Ham, Sung Jun Jung, Seonghak Kim, Young H Oh, Yeonhong Park, Yoonho Song, Jung-Hun Park, Sanghee Lee, Kyoung Park, Jae W Lee, et al. 2020. 𝐴3: Accelerating attention mechanisms in neural networks with approximation. In High Performance Computer Architecture. IEEE, 328–341
work page 2020
-
[24]
Tae Jun Ham, Yejin Lee, Seong Hoon Seo, Soosung Kim, Hyunji Choi, Sung Jun Jung, and Jae W Lee. 2021. ELSA: Hardware-software co-design for efficient, light- weight self-attention mechanism in neural networks. In International Symposium on Computer Architecture. ACM/IEEE, 692–705
work page 2021
-
[25]
Sheng-Chun Kao, Suvinay Subramanian, Gaurav Agrawal, Amir Yazdanbakhsh, and Tushar Krishna. 2023. FLAT: An optimized dataflow for mitigating attention bottlenecks. In International Conference on Architectural Support for Programming Languages and Operating Systems . ACM, 295–310
work page 2023
-
[26]
Chendi Li, Yufan Xu, Sina Mahdipour Saravani, and Ponnuswamy Sadayappan
-
[27]
In Inter- national Conference on Supercomputing
Accelerated auto-tuning of GPU kernels for tensor computations. In Inter- national Conference on Supercomputing . ACM, 549–561
-
[28]
Mingzhen Li, Hailong Yang, Shanjun Zhang, Fengwei Yu, Ruihao Gong, Yi Liu, Zhongzhi Luan, and Depei Qian. 2023. Exploiting subgraph similarities for efficient auto-tuning of tensor programs. In International Conference on Parallel Processing. ACM, 786–796
work page 2023
-
[29]
Shutao Li, Weiwei Song, Leyuan Fang, Yushi Chen, Pedram Ghamisi, and Jon Atli Benediktsson. 2019. Deep learning for hyperspectral image classification: An overview. IEEE Transactions on Geoscience and Remote Sensing 57, 9 (2019), 6690–6709
work page 2019
-
[30]
Tianyang Lin, Yuxin Wang, Xiangyang Liu, and Xipeng Qiu. 2022. A survey of Transformers. AI open 3 (2022), 111–132
work page 2022
-
[31]
Zichang Liu, Jue Wang, Tri Dao, Tianyi Zhou, Binhang Yuan, Zhao Song, Anshu- mali Shrivastava, Ce Zhang, Yuandong Tian, Christopher Re, et al. 2023. Deja Vu: Contextual sparsity for efficient LLMs at inference time. In International Conference on Machine Learning . ACM, 22137–22176
work page 2023
-
[32]
Siyuan Lu, Meiqi Wang, Shuang Liang, Jun Lin, and Zhongfeng Wang. 2020. Hardware accelerator for multi-head attention and position-wise feed-forward in the Transformer. In International System-on-Chip Conference. IEEE, 84–89
work page 2020
-
[33]
Lingxiao Ma, Zhiqiang Xie, Zhi Yang, Jilong Xue, Youshan Miao, Wei Cui, Wenx- iang Hu, Fan Yang, Lintao Zhang, and Lidong Zhou. 2020. Rammer: Enabling holistic deep learning compiler optimizations with rTasks. InUSENIX Symposium on Operating Systems Design and Implementation . USENIX, 881–897
work page 2020
-
[34]
Yanjun Ma, Dianhai Yu, Tian Wu, and Haifeng Wang. 2019. PaddlePaddle: An open-source deep learning platform from industrial practice. Frontiers of Data and Computing 1, 1 (2019), 105–115
work page 2019
-
[35]
Wei Niu, Jiexiong Guan, Yanzhi Wang, Gagan Agrawal, and Bin Ren. 2021. DNN- Fusion: Accelerating deep neural networks execution with advanced operator fusion. In International Conference on Programming Language Design and Imple- mentation. ACM, 883–898
work page 2021
-
[36]
Yuyao Niu, Zhengyang Lu, Haonan Ji, Shuhui Song, Zhou Jin, and Weifeng Liu
-
[37]
In ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming
TileSpGEMM: A tiled algorithm for parallel sparse general matrix-matrix multiplication on GPUs. In ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. ACM, 90–106
-
[38]
NVIDIA. 2022. https://github.com/NVIDIA/FasterTransformer
work page 2022
-
[39]
NVIDIA. 2022. https://github.com/NVIDIA/cutlass
work page 2022
-
[40]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. In Con- ference on Neural Information Processing Systems . MIT Press, 27730–27744
work page 2022
-
[41]
Philip Pfaffe, Tobias Grosser, and Martin Tillmann. 2019. Efficient hierarchical online-autotuning: A case study on polyhedral accelerator mapping. In Interna- tional Conference on Supercomputing . ACM, 354–366
work page 2019
-
[42]
Yubin Qin, Yang Wang, Dazheng Deng, Zhiren Zhao, Xiaolong Yang, Leibo Liu, Shaojun Wei, Yang Hu, and Shouyi Yin. 2023. FACT: FFN-attention co-optimized Transformer architecture with eager correlation prediction. In International Sym- posium on Computer Architecture. ACM/IEEE, 1–14
work page 2023
-
[43]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog 1, 8 (2019), 9
work page 2019
-
[44]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, ichael MMatena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text Transformer. Journal of Machine Learning Research 21, 140 (2020), 1–67. 11 Conference acronym ’XX, June 03–05, 2028, Woodstock, NY Dai et al
work page 2020
-
[45]
Jonathan Ragan-Kelley, Connelly Barnes, Andrew Adams, Sylvain Paris, Frédo Durand, and Saman Amarasinghe. 2013. Halide: A language and compiler for optimizing parallelism, locality, and recomputation in image processing pipelines. ACM Sigplan Notices 48, 6 (2013), 519–530
work page 2013
-
[46]
Thomas Randall, Jaehoon Koo, Brice Videau, Michael Kruse, Xingfu Wu, Paul Hovland, Mary Hall, Rong Ge, and Prasanna Balaprakash. 2023. Transfer-learning- based autotuning using Gaussian copula. In International Conference on Super- computing. ACM, 37–49
work page 2023
-
[47]
Francisco Romero, Mark Zhao, Neeraja J Yadwadkar, and Christos Kozyrakis
-
[48]
In ACM Symposium on Cloud Computing
Llama: A heterogeneous & serverless framework for auto-tuning video analytics pipelines. In ACM Symposium on Cloud Computing . ACM, 1–17
-
[49]
Aurko Roy, Mohammad Saffar, Ashish Vaswani, and David Grangier. 2021. Effi- cient content-based sparse attention with routing Transformers. Transactions of the Association for Computational Linguistics 9 (2021), 53–68
work page 2021
-
[50]
Yining Shi, Zhi Yang, Jilong Xue, Lingxiao Ma, Yuqing Xia, Ziming Miao, Yuxiao Guo, Fan Yang, and Lidong Zhou. 2023. Welder: Scheduling deep learning memory access via tile-graph. In USENIX Symposium on Operating Systems Design and Implementations. USENIX, 701–718
work page 2023
-
[51]
Felix Stahlberg. 2020. Neural machine translation: A review. Journal of Artificial Intelligence Research 69 (2020), 343–418
work page 2020
-
[52]
Qingxiao Sun, Yi Liu, Hailong Yang, Zhonghui Jiang, Xiaoyan Liu, Ming Dun, Zhongzhi Luan, and Depei Qian. 2021. csTuner: Scalable auto-tuning framework for complex stencil computation on GPUs. In IEEE International Conference on Cluster Computing. IEEE, 192–203
work page 2021
-
[53]
Qingxiao Sun, Yi Liu, Hailong Yang, Zhonghui Jiang, Zhongzhi Luan, and Depei Qian. 2024. Adaptive auto-tuning framework for global exploration of stencil optimization on GPUs. IEEE Transactions on Parallel and Distributed Systems 35, 1 (2024), 20–33
work page 2024
-
[54]
Qi Sun, Xinyun Zhang, Hao Geng, Yuxuan Zhao, Yang Bai, Haisheng Zheng, and Bei Yu. 2022. GTuner: Tuning DNN computations on GPU via graph attention network. In Asia and South Pacific Design Automation Conference . ACM/IEEE, 1045–1050
work page 2022
-
[55]
Niko Sünderhauf, Oliver Brock, Walter Scheirer, Raia Hadsell, Dieter Fox, Jürgen Leitner, Ben Upcroft, Pieter Abbeel, Wolfram Burgard, Michael Milford, et al
-
[56]
The International journal of robotics research 37, 4-5 (2018), 405–420
The limits and potentials of deep learning for robotics. The International journal of robotics research 37, 4-5 (2018), 405–420
work page 2018
-
[57]
Ryan Swann, Muhammad Osama, Karthik Sangaiah, and Jalal Mahmud. 2024. Seer: Predictive runtime kernel selection for irregular problems. In Code Generation and Optimization. IEEE, 133–142
work page 2024
-
[58]
Arun James Thirunavukarasu, Darren Shu Jeng Ting, Kabilan Elangovan, Laura Gutierrez, Ting Fang Tan, and Daniel Shu Wei Ting. 2023. Large language models in medicine. Nature medicine 29, 8 (2023), 1930–1940
work page 2023
-
[59]
Philippe Tillet, Hsiang-Tsung Kung, and David Cox. 2019. Triton: An intermediate language and compiler for tiled neural network computations. In ACM SIGPLAN International Workshop on Machine Learning and Programming Languages . ACM, 10–19
work page 2019
-
[60]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Conference on Neural Information Processing Systems . MIT Press, 6000–6010
work page 2017
- [61]
-
[62]
Haoran Wang, Haobo Xu, Ying Wang, and Yinhe Han. 2023. CTA: Hardware- software co-design for compressed token attention mechanism. In High Perfor- mance Computer Architecture. IEEE, 429–441
work page 2023
-
[63]
Hulin Wang, Donglin Yang, Yaqi Xia, Zheng Zhang, Qigang Wang, Jianping Fan, Xiaobo Zhou, and Dazhao Cheng. 2024. Raptor-T: A fused and memory-efficient sparse Transformer for long and variable-length sequences. IEEE Trans. Comput. 73, 7 (2024), 1852–1865
work page 2024
-
[64]
Xiaohui Wang, Yang Wei, Ying Xiong, Guyue Huang, Xian Qian, Yufei Ding, Mingxuan Wang, and Lei Li. 2022. LightSeq2: Accelerated training for Transformer-based models on GPUs. In International Conference on High Perfor- mance Computing, Networking, Storage and Analysis . IEEE, 1–14
work page 2022
-
[65]
Jiarong Xing, Leyuan Wang, Shang Zhang, Jack Chen, Ang Chen, and Yibo Zhu. 2022. Bolt: Bridging the gap between auto-tuners and hardware-native performance. Proceedings of Machine Learning and Systems 4 (2022), 204–216
work page 2022
-
[66]
Jiaming Xu, Shan Huang, Jinhao Li, Guyue Huang, Yuan Xie, Yu Wang, and Guo- hao Dai. 2024. Enabling efficient sparse multiplications on GPUs with heuristic adaptability. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems PP (2024), 1–1
work page 2024
-
[67]
Zhiying Xu, Jiafan Xu, Hongding Peng, Wei Wang, Xiaoliang Wang, Haoran Wan, Haipeng Dai, Yixu Xu, Hao Cheng, Kun Wang, et al. 2023. ALT: Breaking the wall between data layout and loop optimizations for deep learning compilation. In European Conference on Computer Systems . ACM, 199–214
work page 2023
-
[68]
Haoran You, Zhanyi Sun, Huihong Shi, Zhongzhi Yu, Yang Zhao, Yongan Zhang, Chaojian Li, Baopu Li, and Yingyan Lin. 2023. ViTCoD: Vision Transformer accel- eration via dedicated algorithm and accelerator co-design. In High Performance Computer Architecture. IEEE, 273–286
work page 2023
-
[69]
Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. 2020. Big Bird: Transformers for longer sequences. In Conference on Neural Information Processing Systems . MIT Press, 1–15
work page 2020
-
[70]
Yujia Zhai, Chengquan Jiang, Leyuan Wang, Xiaoying Jia, Shang Zhang, Zizhong Chen, Xin Liu, and Yibo Zhu. 2023. ByteTransformer: A high-performance Trans- former boosted for variable-length inputs. In International Parallel & Distributed Processing Symposium. IEEE, 344–355
work page 2023
-
[71]
Zheng Zhang, Donglin Yang, Xiaobo Zhou, and Dazhao Cheng. 2024. MCFuser: High-performance and rapid fusion of memory-bound compute-intensive opera- tors. In International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 1–15
work page 2024
-
[72]
Jie Zhao, Bojie Li, Wang Nie, Zhen Geng, Renwei Zhang, Xiong Gao, Bin Cheng, Chen Wu, Yun Cheng, Zheng Li, et al. 2021. AKG: Automatic kernel generation for neural processing units using polyhedral transformations. In ACM SIGPLAN Conference on Programming Language Design and Implementation . ACM, 1233– 1248
work page 2021
-
[73]
Jieru Zhao, Pai Zeng, Guan Shen, Quan Chen, and Minyi Guo. 2024. Hard- ware–software co-design enabling static and dynamic sparse attention mecha- nisms. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 43, 9 (2024), 2783–2796
work page 2024
-
[74]
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. 2023. A survey of large language models. arXiv preprint arXiv:2303.18223 1, 2 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[75]
Lianmin Zheng, Chengfan Jia, Minmin Sun, Zhao Wu, Cody Hao Yu, Ameer Haj-Ali, Yida Wang, Jun Yang, Danyang Zhuo, Koushik Sen, et al. 2020. Ansor: Generating high-performance tensor programs for deep learning. In USENIX Symposium on Operating Systems Design and Implementation . USENIX, 863–879
work page 2020
-
[76]
Lianmin Zheng, Ruochen Liu, Junru Shao, Tianqi Chen, Joseph E Gonzalez, Ion Stoica, and Ameer Haj Ali. 2021. TenSet: A large-scale program performance dataset for learned tensor compilers. In Conference on Neural Information Pro- cessing Systems. MIT Press, 1–14
work page 2021
-
[77]
Size Zheng, Renze Chen, Yicheng Jin, Anjiang Wei, Bingyang Wu, Xiuhong Li, Shengen Yan, and Yun Liang. 2021. NeoFlow: A flexible framework for enabling efficient compilation for high performance DNN training. IEEE Transactions on Parallel and Distributed Systems 33, 11 (2021), 3220–3232
work page 2021
-
[78]
Size Zheng, Siyuan Chen, Peidi Song, Renze Chen, Xiuhong Li, Shengen Yan, Dahua Lin, Jingwen Leng, and Yun Liang. 2023. Chimera: An analytical optimizing framework for effective compute-intensive operators fusion. InHigh Performance Computer Architecture. ACM, 1113–1126
work page 2023
-
[79]
Size Zheng, Yun Liang, Shuo Wang, Renze Chen, and Kaiwen Sheng. 2020. Flex- Tensor: An automatic schedule exploration and optimization framework for tensor computation on heterogeneous system. In International Conference on Architectural Support for Programming Languages and Operating Systems . ACM, 859–873
work page 2020
-
[80]
Zhen Zheng, Xuanda Yang, Pengzhan Zhao, Guoping Long, Kai Zhu, Feiwen Zhu, Wenyi Zhao, Xiaoyong Liu, Jun Yang, Jidong Zhai, et al. 2022. AStitch: Enabling a new multi-dimensional optimization space for memory-intensive ML training and inference on modern SIMT architectures. In International Conference on Architectural Support for Programming Languages and...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.