Explicit Fuzzy Logic in the Feed-Forward Layer: Self-Forgetting Quantifiers Discover Legible Grammatical-Licensing Detectors
Pith reviewed 2026-07-01 05:41 UTC · model grok-4.3
The pith
Explicit fuzzy logic and self-forgetting quantifiers in the feed-forward layer turn units into legible grammatical licensing detectors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A parameter-neutral NC-FFN using intersection A*B and bounded negation A*(1-B), augmented by soft sequence quantifiers with per-unit forgetting rates, recovers the licensing deficit at epoch one, lets logical structure migrate into depth, and produces units that read directly as grammatical licensing detectors while matching baseline language-model quality.
What carries the argument
The NC-FFN (negation-capable feed-forward network) of explicit fuzzy set operations combined with soft existential and soft proportion quantifiers each equipped with a learned per-unit forgetting rate from sticky initialization.
If this is right
- Grammatical structure migrates from layer zero into deeper semantic layers.
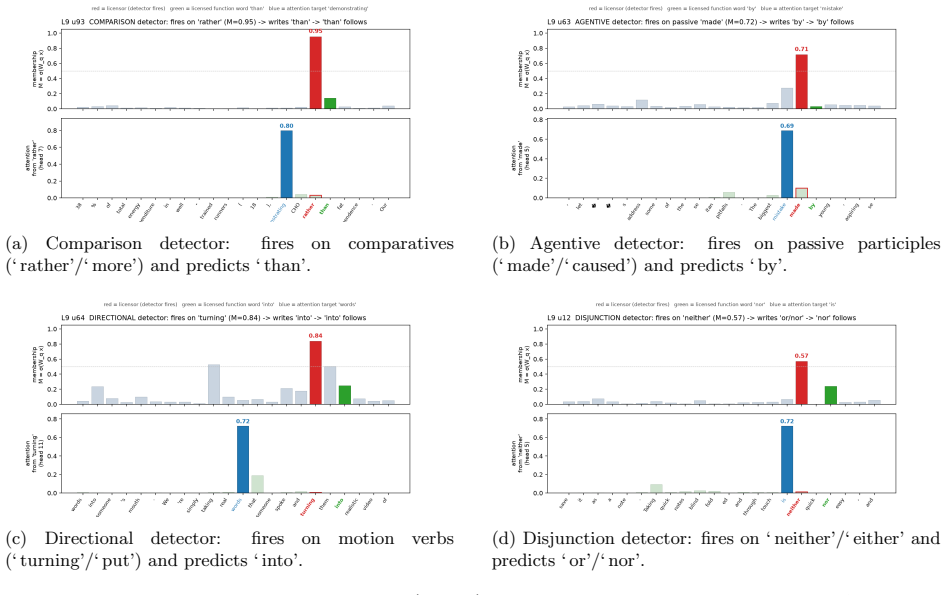
- Units become readable as licensing detectors for comparatives, passives, and negative-polarity items without auxiliary analysis.
- The wider performance gap at epoch two is halved while LAMBADA scores modestly improve.
- A fully Boolean version of the same layer diverges, showing that the fuzzy partition is required for stable training.
Where Pith is reading between the lines
- The same quantifier-plus-forgetting construction could be tested on other long-range syntactic dependencies such as agreement or binding.
- Building explicit logical forms into the architecture may reduce reliance on post-training interpretability methods across other sequence tasks.
- The observed median forgetting half-life of roughly 1.5 tokens suggests a natural mechanism for controlling memory span in deeper layers.
Load-bearing premise
Two-operand logic stays localized at layer zero and erodes during training, and adding sequence quantifiers with forgetting rates will keep the logic intact, move it deeper, and preserve overall training dynamics.
What would settle it
If the added quantifiers fail to produce units that selectively activate on licensors and improve prediction of the corresponding licensed words, or if the model diverges when the quantifiers are removed, the central claim does not hold.
Figures
read the original abstract
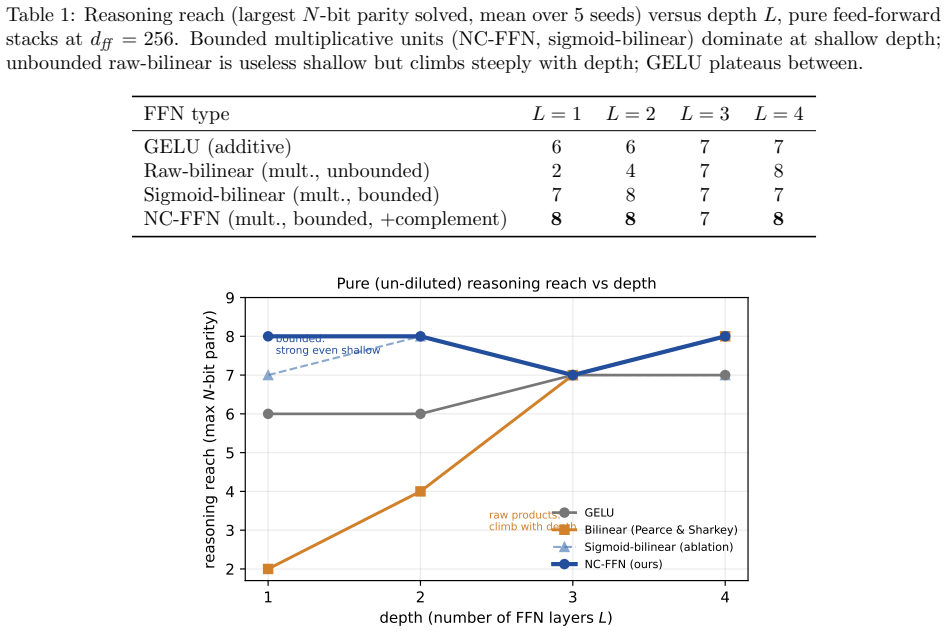
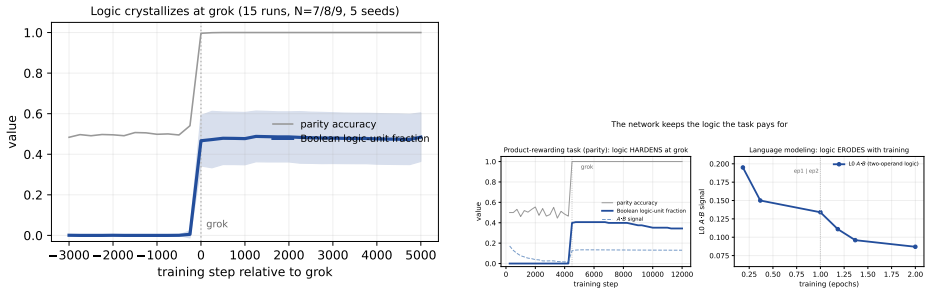
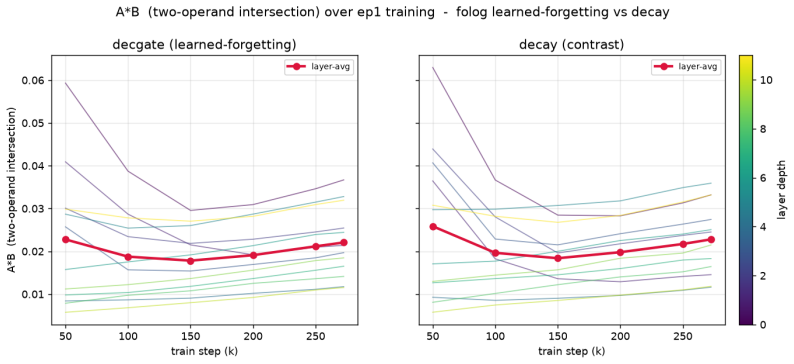
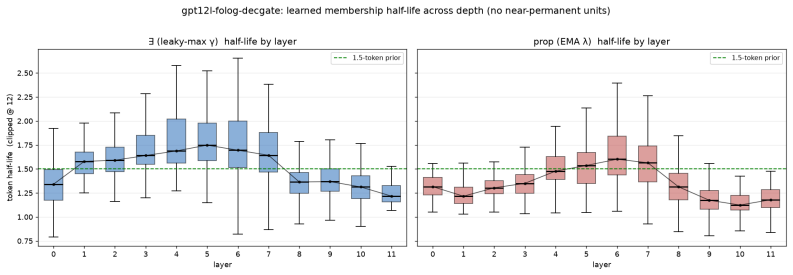
A transformer's feed-forward (FFN) sublayer materializes the distinctions attention gathers, yet gives no account of what it computes. In a parameter-neutral replacement, each hidden unit is an explicit fuzzy set operation on sigmoid-bounded [0,1] memberships: intersection A*B and set-difference A*(1-B), the latter a bounded positive negation ("A but not B") that gated/bilinear units lack -- a negation-capable FFN (NC-FFN). On N-bit parity they are the most parameter-efficient reasoning basis at shallow depth; at scale (125M, OpenWebText) NC-FFN ties the GELU baseline's perplexity, every unit carrying explicit logical form. Two limits share one cause: two-operand logic localizes to layer 0 and erodes under training, and the one robust grammatical deficit concentrates in licensing and quantifiers, beyond within-token operators. We resolve both with a small block of sequence quantifiers: a soft existential and a soft proportion, each with a per-unit learned forgetting rate from a sticky init. This recovers the deficit at epoch one (halving the wider epoch-two gap), modestly leads on LAMBADA, and makes the FFN legible: the structure now holds and migrates into depth; the decay un-learns its stickiness (median half-life ~1.5 tokens; zero latch units); and at the semantic layers the units read, without dictionary learning, as grammatical licensing detectors: each fires on a licensor (a comparative, a passive participle, a negative-polarity item) and carries its memory forward to predict the licensed word (than, by, nor). This legibility is localized and free only up to a partition (a fully Boolean FFN diverges in training), but the result is a parameter-neutral, language-model-quality transformer with a readable, interpretable-by-construction grammatical mechanism -- an account not just of what a feed-forward layer represents but how it licenses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes replacing the standard FFN with a negation-capable version (NC-FFN) that implements explicit fuzzy-set operations (intersection A*B and bounded set-difference A*(1-B)) on sigmoid-bounded memberships, yielding per-unit logical forms. At 125M scale on OpenWebText this matches GELU perplexity; on N-bit parity it is parameter-efficient at shallow depth. The authors identify that two-operand logic localizes to layer 0 and erodes, while a grammatical deficit appears in licensing/quantifiers. They add a small block of soft sequence quantifiers (existential and proportion) each equipped with a per-unit learned forgetting rate initialized stickily; this recovers the deficit at epoch one (halving the epoch-two gap), modestly improves LAMBADA, allows logical structure to migrate into depth, and produces units that, without dictionary learning, read as grammatical licensing detectors (firing on licensors and carrying memory to predict licensed tokens). The final model remains parameter-neutral and training-stable, though a fully Boolean FFN diverges.
Significance. If the experimental claims hold, the work supplies a parameter-neutral, interpretable-by-construction account of how an FFN can implement grammatical licensing via explicit fuzzy logic and sequence quantifiers whose forgetting dynamics are learned. The migration of structure into depth and the emergence of legible detectors without post-hoc analysis would be a concrete advance for mechanistic interpretability of feed-forward sublayers while preserving language-model quality.
major comments (2)
- [Abstract] Abstract and § on sequence quantifiers: the central claim that the added quantifiers recover the grammatical deficit at epoch one while tying perplexity rests on experimental outcomes, yet the provided text supplies no equations defining the soft existential/proportion operators, no training curves, no ablation tables, and no statistical details on the halving of the gap or the LAMBADA lead; without these the result cannot be verified or reproduced.
- [Abstract] Abstract: the assertion that NC-FFN plus quantifiers is 'parameter-neutral' requires explicit accounting of the extra parameters introduced by the per-unit forgetting rates and the quantifier block; if these are non-negligible the neutrality claim is load-bearing for the scaling argument.
minor comments (1)
- [Abstract] The abstract refers to 'median half-life ~1.5 tokens' and 'zero latch units' without defining how half-life is computed from the learned forgetting rates.
Simulated Author's Rebuttal
We thank the referee for highlighting issues of verifiability and parameter accounting. Both points are addressable by expanding the manuscript with the requested details; we outline the planned revisions below.
read point-by-point responses
-
Referee: [Abstract] Abstract and § on sequence quantifiers: the central claim that the added quantifiers recover the grammatical deficit at epoch one while tying perplexity rests on experimental outcomes, yet the provided text supplies no equations defining the soft existential/proportion operators, no training curves, no ablation tables, and no statistical details on the halving of the gap or the LAMBADA lead; without these the result cannot be verified or reproduced.
Authors: We agree that the abstract and the section on sequence quantifiers omit the defining equations for the soft existential and proportion operators as well as supporting experimental evidence. The current text therefore does not allow direct verification or reproduction of the reported recovery of the grammatical deficit, the halving of the epoch-two gap, or the LAMBADA improvement. In the revised version we will insert the explicit equations for both quantifiers, include training curves and ablation tables that isolate their contribution, and report statistical details (means, standard deviations, and any significance tests) for the performance deltas. These additions will appear in the main text or as a dedicated supplementary section. revision: yes
-
Referee: [Abstract] Abstract: the assertion that NC-FFN plus quantifiers is 'parameter-neutral' requires explicit accounting of the extra parameters introduced by the per-unit forgetting rates and the quantifier block; if these are non-negligible the neutrality claim is load-bearing for the scaling argument.
Authors: The manuscript asserts parameter neutrality, yet does not supply a line-item count of the additional parameters arising from the per-unit forgetting rates and the quantifier block. We accept that an explicit accounting is required to support the claim at scale. The revision will include a table or paragraph that enumerates the exact parameter overhead of the forgetting rates (one scalar per unit) and the quantifier block, demonstrating that the net increase remains negligible relative to the 125 M baseline and does not alter the scaling argument. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces an architectural change (NC-FFN using explicit intersection and bounded set-difference on [0,1] memberships, plus soft sequence quantifiers with per-unit learned forgetting rates) and reports empirical outcomes: parity efficiency, tying GELU perplexity at 125M scale, recovery of grammatical licensing at epoch one, and emergence of legible detectors. These are training results on external benchmarks (OpenWebText, LAMBADA) rather than quantities defined by the model's own fitted parameters or equations. No self-definitional loop, fitted-input-as-prediction, or load-bearing self-citation chain appears in the provided text; the central claims remain falsifiable against held-out data and baselines.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Artificial Intelligence , volume=
Tensor Product Variable Binding and the Representation of Symbolic Structures in Connectionist Systems , author=. Artificial Intelligence , volume=
-
[2]
Tensor Logic: The Language of
Domingos, Pedro , journal=. Tensor Logic: The Language of
-
[3]
International Conference on Machine Learning (ICML) , year=
Language Modeling with Gated Convolutional Networks , author=. International Conference on Machine Learning (ICML) , year=
-
[4]
Shazeer, Noam , journal=
-
[5]
and Dooms, Thomas and Rigg, Alice and Oramas, Jose and Sharkey, Lee , journal=
Pearce, Michael T. and Dooms, Thomas and Rigg, Alice and Oramas, Jose and Sharkey, Lee , journal=. Bilinear
-
[6]
and Dooms, Thomas and Rigg, Alice , journal=
Pearce, Michael T. and Dooms, Thomas and Rigg, Alice , journal=. Weight-based Decomposition: A Case for Bilinear
-
[7]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Attention Is All You Need , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[8]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Neural Arithmetic Logic Units , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[9]
Artificial Intelligence , volume=
Analyzing Differentiable Fuzzy Logic Operators , author=. Artificial Intelligence , volume=
-
[10]
Artificial Intelligence , volume=
Logic Tensor Networks , author=. Artificial Intelligence , volume=
-
[11]
arXiv preprint arXiv:2006.13155 , year=
Logical Neural Networks , author=. arXiv preprint arXiv:2006.13155 , year=
-
[12]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Deep Differentiable Logic Gate Networks , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[13]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Convolutional Differentiable Logic Gate Networks , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[14]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Beta Embeddings for Multi-Hop Logical Reasoning in Knowledge Graphs , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[15]
International Conference on Learning Representations (ICLR) , year=
Query2box: Reasoning over Knowledge Graphs in Vector Space using Box Embeddings , author=. International Conference on Learning Representations (ICLR) , year=
-
[16]
Zhang, Zhanqiu and Wang, Jie and Chen, Jiajun and Ji, Shuiwang and Wu, Feng , booktitle=
-
[17]
AAAI Conference on Artificial Intelligence , year=
Fuzzy Logic Based Logical Query Answering on Knowledge Graphs , author=. AAAI Conference on Artificial Intelligence , year=
-
[18]
Transformer Circuits Thread , year=
Softmax Linear Units , author=. Transformer Circuits Thread , year=
-
[19]
arXiv preprint arXiv:2310.17230 , year=
Codebook Features: Sparse and Discrete Interpretability for Neural Networks , author=. arXiv preprint arXiv:2310.17230 , year=
-
[20]
Transformer Circuits Thread , year=
Toy Models of Superposition , author=. Transformer Circuits Thread , year=
-
[21]
Transformer Circuits Thread , year=
Towards Monosemanticity: Decomposing Language Models with Dictionary Learning , author=. Transformer Circuits Thread , year=
-
[22]
International Conference on Learning Representations (ICLR) , year=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[23]
Empirical Methods in Natural Language Processing (EMNLP) , year=
Transformer Feed-Forward Layers Are Key-Value Memories , author=. Empirical Methods in Natural Language Processing (EMNLP) , year=
-
[24]
arXiv preprint arXiv:2509.13357 , year=
Semantic Fusion with Fuzzy-Membership Features for Controllable Language Modelling , author=. arXiv preprint arXiv:2509.13357 , year=
-
[25]
, journal=
Warstadt, Alex and Parrish, Alicia and Liu, Haokun and Mohananey, Anhad and Peng, Wei and Wang, Sheng-Fu and Bowman, Samuel R. , journal=
-
[26]
Paperno, Denis and Kruszewski, Germ. The. Association for Computational Linguistics (ACL) , year=
-
[27]
Zellers, Rowan and Holtzman, Ari and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin , booktitle=
-
[28]
Sakaguchi, Keisuke and Le Bras, Ronan and Bhagavatula, Chandra and Choi, Yejin , journal=
-
[29]
Think You Have Solved Question Answering? Try
Clark, Peter and Cowhey, Isaac and Etzioni, Oren and Khot, Tushar and Sabharwal, Ashish and Schoenick, Carissa and Tafjord, Oyvind , journal=. Think You Have Solved Question Answering? Try
-
[30]
A Framework for Few-Shot Language Model Evaluation , author=
-
[31]
and Schmidhuber, J
Gers, Felix A. and Schmidhuber, J. Learning to Forget: Continual Prediction with. Neural Computation , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.