Theoretical Analysis of Engression and Reverse Markov Engression
Pith reviewed 2026-06-28 16:57 UTC · model grok-4.3
The pith
Deep neural networks achieve nonasymptotic convergence for Engression by directly bounding energy distance to target conditional distributions, with excess risk near the minimax rate over Hölder classes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under deep neural network parameterizations, nonasymptotic convergence bounds are established for Engression by directly controlling the Energy Distance between the learned and target conditional distributions. For the Reverse Markov framework, an Energy-Distance-based chain rule is developed that enables rigorous analysis of error propagation across the reverse steps. The resulting excess-risk bounds are near-optimal up to logarithmic factors relative to the classical minimax rate over a general Hölder class.
What carries the argument
Energy Distance as the discrepancy measure between conditional distributions, together with the Energy-Distance-based chain rule that tracks propagation of approximation error through sequential reverse transitions.
If this is right
- Convergence holds for any deep neural network parameterization that can approximate the target conditionals.
- Error introduced at each reverse step remains controllable through the chain rule, preventing exponential blow-up across multiple transitions.
- Excess risk stays within logarithmic factors of the minimax rate, so the method matches the best possible statistical performance up to logs.
- Finite-sample guarantees apply directly without requiring asymptotic regimes.
Where Pith is reading between the lines
- The same energy-distance control might be used to analyze other conditional generative procedures that rely on discrepancy minimization.
- Training algorithms could be modified to optimize energy distance explicitly rather than surrogate losses, potentially tightening the bounds in practice.
- The chain-rule technique could extend to forward Markov chains or other sequential decomposition schemes in distribution learning.
Load-bearing premise
The target conditional distributions belong to a general Hölder class.
What would settle it
Finding a Hölder-class conditional distribution and a deep-network Engression estimator whose excess risk exceeds the classical minimax rate by more than logarithmic factors would falsify the near-optimality result.
Figures
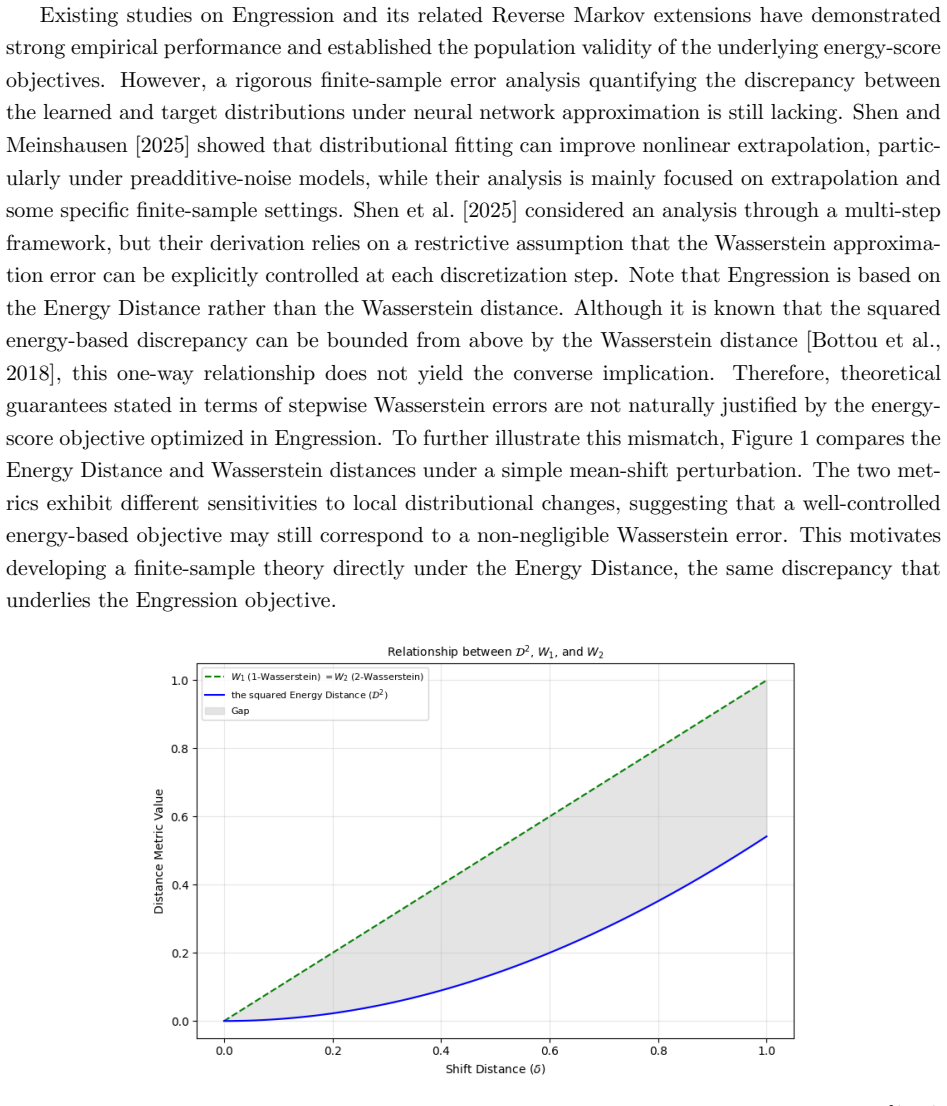
read the original abstract
Engression is a recently proposed and effective framework for conditional distribution learning. Its multi-step Reverse Markov extension further improves generative flexibility by decomposing complex conditional sampling into sequential reverse transitions. Despite their strong empirical performance, rigorous finite-sample statistical guarantees for these methods remain unavailable. In this paper, under deep neural network parameterizations, we establish nonasymptotic convergence bounds for Engression by directly controlling the Energy Distance between the learned and target conditional distributions. For the Reverse Markov framework, we further develop an Energy-Distance-based chain rule that enables a rigorous analysis of error propagation across reverse steps. Our analysis yields corresponding excess-risk bounds that are near-optimal up to logarithmic factors relative to the classical minimax rate over a general H\"older class.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper establishes nonasymptotic convergence bounds for Engression under deep neural network parameterizations by directly controlling the Energy Distance between learned and target conditional distributions. For the Reverse Markov Engression extension, it develops an Energy-Distance-based chain rule to analyze error propagation across sequential reverse transitions. The resulting excess-risk bounds are shown to be near-optimal up to logarithmic factors relative to the classical minimax rate over a general Hölder class.
Significance. If the derivations hold, the work supplies the first rigorous finite-sample statistical guarantees for these empirically successful conditional distribution learning methods. The direct energy-distance control and the chain-rule propagation argument under DNN parameterization are strengths that enable the near-minimax excess-risk rates; the manuscript also ships the requisite approximation and propagation arguments under the stated assumptions.
minor comments (3)
- The abstract invokes a 'general Hölder class' without specifying the smoothness index or dimension dependence in the rate statement; the main text should make the precise dependence explicit when stating the near-minimax claim.
- Notation for the energy distance and the reverse-step operators should be introduced with a dedicated preliminary section or table to improve readability for readers unfamiliar with the Engression framework.
- The manuscript would benefit from a short discussion of how the DNN parameterization assumptions (width, depth, activation) interact with the Hölder ball radius in the approximation error term.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our manuscript, the recognition of its significance in providing the first rigorous finite-sample guarantees for Engression and Reverse Markov Engression, and the recommendation for minor revision. We appreciate the acknowledgment of the strengths in our direct energy-distance control and chain-rule propagation arguments.
Circularity Check
No significant circularity
full rationale
The derivation establishes nonasymptotic convergence bounds for Engression by directly controlling the Energy Distance between learned and target conditional distributions under DNN parameterizations, then extends this via an Energy-Distance-based chain rule for error propagation in the Reverse Markov case. These steps produce excess-risk bounds relative to the Hölder minimax rate. No quoted equation or step reduces a claimed prediction or bound to a fitted input, self-definition, or self-citation chain; the central claims rest on approximation and propagation arguments that are independent of the target result and do not invoke uniqueness theorems or ansatzes from prior author work as load-bearing justification. The analysis is therefore self-contained against the stated assumptions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Target conditional distributions lie in a Hölder class
- standard math Energy distance metrizes weak convergence of distributions
Reference graph
Works this paper leans on
-
[1]
Biostatistics , volume=
Sieve estimation in semiparametric modeling of longitudinal data with informative observation times , author=. Biostatistics , volume=. 2014 , publisher=
2014
-
[2]
Journal of the American Medical Informatics Association , volume=
Reliable generation of privacy-preserving synthetic electronic health record time series via diffusion models , author=. Journal of the American Medical Informatics Association , volume=. 2024 , publisher=
2024
-
[3]
Shen, Xinwei and Meinshausen, Nicolai and Zhang, Tong , journal=
-
[4]
International Conference on Machine Learning , pages=
Deep unsupervised learning using nonequilibrium thermodynamics , author=. International Conference on Machine Learning , pages=. 2015 , organization=
2015
-
[5]
11th International Conference on Learning Representations, ICLR 2023 , year=
Flow Matching for Generative Modeling , author=. 11th International Conference on Learning Representations, ICLR 2023 , year=
2023
-
[6]
Advances in Neural Information Processing Systems , volume=
Denoising diffusion probabilistic models , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
International Conference on Machine Learning , pages=
simple diffusion: End-to-end diffusion for high resolution images , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[8]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Engression: extrapolation through the lens of distributional regression , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2025 , publisher=
2025
-
[9]
2019 , publisher=
High-dimensional statistics: A non-asymptotic viewpoint , author=. 2019 , publisher=
2019
-
[10]
Annual Review of Statistics and Its Application , volume=
The energy of data , author=. Annual Review of Statistics and Its Application , volume=. 2017 , publisher=
2017
-
[11]
Journal of Machine Learning Research , volume=
Adaptive approximation and generalization of deep neural network with intrinsic dimensionality , author=. Journal of Machine Learning Research , volume=
-
[12]
The Annals of Statistics , volume=
Deep nonparametric regression on approximate manifolds: Nonasymptotic error bounds with polynomial prefactors , author=. The Annals of Statistics , volume=. 2023 , publisher=
2023
- [13]
-
[14]
Journal of Machine Learning Research , volume=
Nearly-tight VC-dimension and pseudodimension bounds for piecewise linear neural networks , author=. Journal of Machine Learning Research , volume=
-
[15]
2009 , publisher =
Neural Network Learning: Theoretical Foundations , author =. 2009 , publisher =
2009
-
[16]
Journal of the American Statistical Association , volume=
A deep generative approach to conditional sampling , author=. Journal of the American Statistical Association , volume=. 2023 , publisher=
2023
-
[17]
MICCAI Workshop on Deep Generative Models , pages=
Synthbraingrow: Synthetic diffusion brain aging for longitudinal mri data generation in young people , author=. MICCAI Workshop on Deep Generative Models , pages=. 2024 , organization=
2024
-
[18]
Machine learning for healthcare conference , pages=
Generating multi-label discrete patient records using generative adversarial networks , author=. Machine learning for healthcare conference , pages=. 2017 , organization=
2017
-
[19]
Journal of the American Medical Informatics Association , volume=
Synthesizing electronic health records using improved generative adversarial networks , author=. Journal of the American Medical Informatics Association , volume=. 2019 , publisher=
2019
-
[20]
NPJ digital medicine , volume=
EHR-Safe: generating high-fidelity and privacy-preserving synthetic electronic health records , author=. NPJ digital medicine , volume=. 2023 , publisher=
2023
-
[21]
Journal of Healthcare Informatics Research , pages=
Methods for generating and evaluating synthetic longitudinal patient data: a systematic review , author=. Journal of Healthcare Informatics Research , pages=. 2025 , publisher=
2025
-
[22]
ACM Computing Surveys (CSUR) , volume=
Generative adversarial networks (GANs) challenges, solutions, and future directions , author=. ACM Computing Surveys (CSUR) , volume=. 2021 , publisher=
2021
-
[23]
arXiv preprint arXiv:2508.01018 , year=
Frugal, Flexible, Faithful: Causal Data Simulation via Frengression , author=. arXiv preprint arXiv:2508.01018 , year=
-
[24]
Journal of the Royal Statistical Society Series B: Statistical Methodology , pages=
Wasserstein generative regression , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , pages=. 2025 , publisher=
2025
-
[25]
The Eleventh International Conference on Learning Representations , year=
Provable memorization capacity of transformers , author=. The Eleventh International Conference on Learning Representations , year=
-
[26]
Geophysical Research Letters , volume=
Modeling uncertainty with engression: A deep generative time-series approach , author=. Geophysical Research Letters , volume=. 2026 , publisher=
2026
-
[27]
arXiv preprint arXiv:2502.02483 , year=
Distributional diffusion models with scoring rules , author=. arXiv preprint arXiv:2502.02483 , year=
-
[28]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Wasserstein generative regression , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2026 , publisher=
2026
-
[29]
Advances in Neural Information Processing Systems , volume=
Generative modeling by estimating gradients of the data distribution , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
MICCAI workshop on deep generative models , pages=
Brain imaging generation with latent diffusion models , author=. MICCAI workshop on deep generative models , pages=. 2022 , organization=
2022
-
[31]
arXiv preprint arXiv:2012.08125 , year=
Learning energy-based models by diffusion recovery likelihood , author=. arXiv preprint arXiv:2012.08125 , year=
-
[32]
arXiv preprint arXiv:2002.03938 , year=
Distribution approximation and statistical estimation guarantees of generative adversarial networks , author=. arXiv preprint arXiv:2002.03938 , year=
-
[33]
Forty-second International Conference on Machine Learning , year=
An error analysis of flow matching for deep generative modeling , author=. Forty-second International Conference on Machine Learning , year=
-
[34]
Nonparametric Regression Using Deep Neural Networks with
Schmidt-Hieber, Johannes , journal=. Nonparametric Regression Using Deep Neural Networks with. 2020 , publisher=
2020
-
[35]
Advances in Neural Information Processing Systems , volume=
Card: Classification and regression diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Wasserstein
Su, Wen and Liu, Changyu and Yin, Guosheng and Huang, Jian , journal=. Wasserstein. 2026 , publisher=
2026
-
[37]
Journal of the American Statistical Association , volume=
Strictly proper scoring rules, prediction, and estimation , author=. Journal of the American Statistical Association , volume=. 2007 , publisher=
2007
-
[38]
arXiv preprint arXiv:2310.18078 , year=
Lipschitz and H " older Continuity in Reproducing Kernel Hilbert Spaces , author=. arXiv preprint arXiv:2310.18078 , year=
-
[39]
Transactions of the American mathematical society , volume=
Theory of reproducing kernels , author=. Transactions of the American mathematical society , volume=
-
[40]
2002 , publisher =
A Distribution-Free Theory of Nonparametric Regression , author =. 2002 , publisher =
2002
-
[41]
2016 , publisher=
An introduction to the theory of reproducing kernel Hilbert spaces , author=. 2016 , publisher=
2016
-
[42]
Equivalence of Distance-Based and
Sejdinovic, Dino and Sriperumbudur, Bharath and Gretton, Arthur and Fukumizu, Kenji , journal =. Equivalence of Distance-Based and
-
[43]
Journal of Statistical Planning and Inference , volume=
Energy statistics: A class of statistics based on distances , author=. Journal of Statistical Planning and Inference , volume=. 2013 , publisher=
2013
-
[44]
Braverman Readings in Machine Learning
Geometrical insights for implicit generative modeling , author=. Braverman Readings in Machine Learning. Key Ideas from Inception to Current State: International Conference Commemorating the 40th Anniversary of Emmanuil Braverman's Decease, Boston, MA, USA, April 28-30, 2017, Invited Talks , pages=. 2018 , organization=
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.