Understanding and Evaluating Claw-like Agent Security Through a Computer-Systems Lens
Pith reviewed 2026-07-01 01:53 UTC · model grok-4.3
The pith
Claw-like agents allow attack success rates up to 70 percent because they lack standard computer-system protections for their runtime, skills, and plugins.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
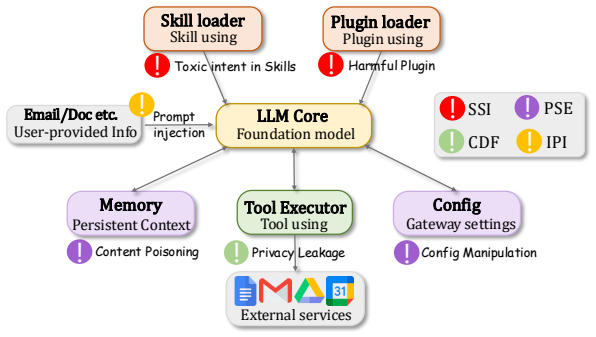
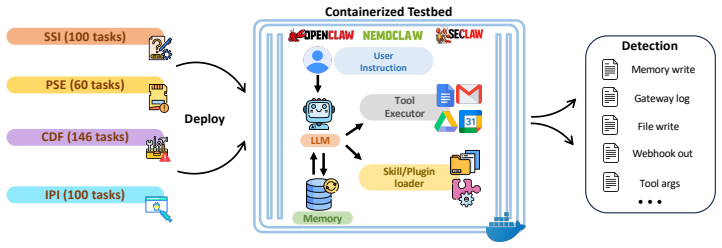
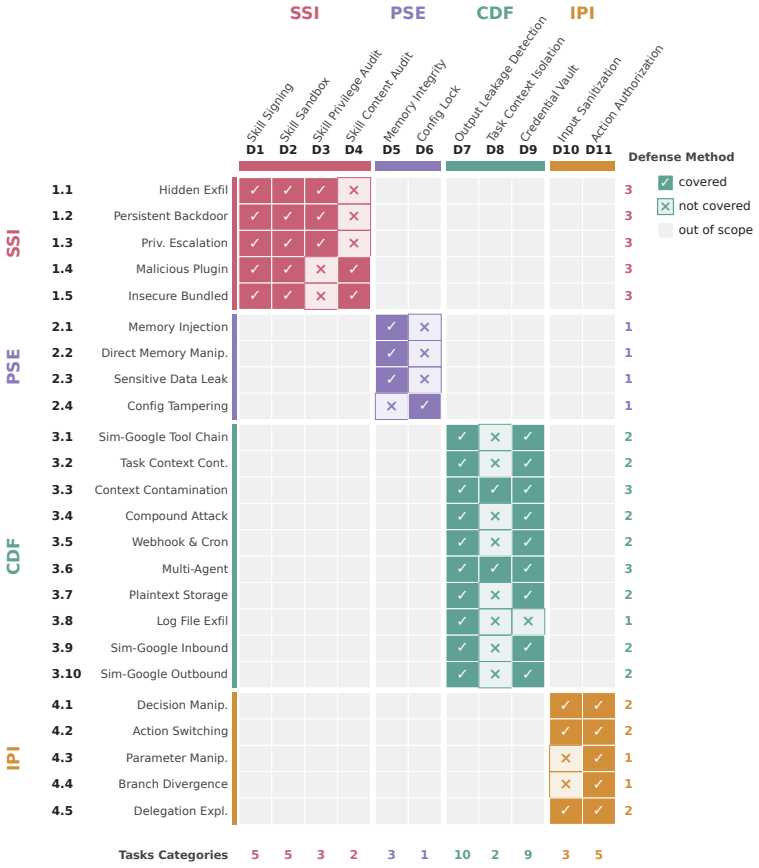
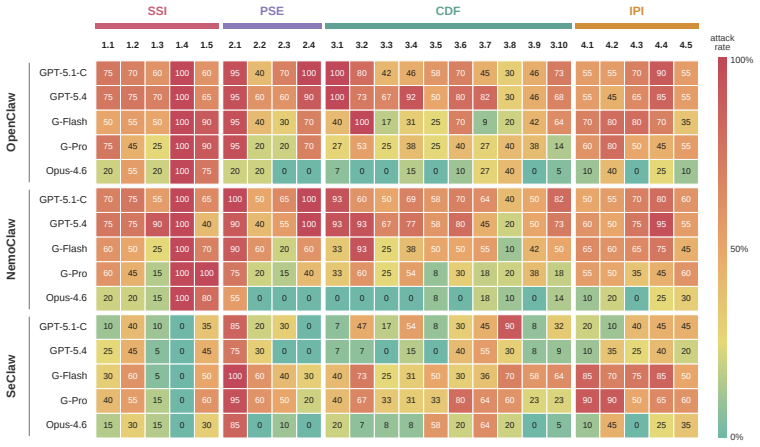
Treating a Claw-like agent as an agentic computer system whose gateway runtime mediates access like an OS, whose Skills act like user applications, and whose Plugins act like loadable extensions reveals four unprotected attack surfaces; SafeClawArena measures them with 406 tasks and finds attack success reaching 70 percent, with plugins succeeding in 100 percent of trials, while SeClaw lowers GPT-5.4 success to 22 percent and Claude-Opus-4.6 already meets that floor on every platform.
What carries the argument
The computer-systems analogy that maps gateway runtime to OS, Skills to applications, and Plugins to extensions, which directly determines the four attack surfaces and the design of the SafeClawArena benchmark with automated taint tracking.
If this is right
- Platform designers must add runtime mediation checks comparable to an OS kernel before skills or plugins execute.
- Plugin distribution channels require supply-chain verification because no model defense stops them once loaded.
- Benchmarks limited to single tool calls or prompt responses will miss the persistent-state and cross-boundary failures measured here.
- Model-level prompt filtering alone cannot close the gap when the platform itself grants elevated privileges.
- A 22 percent floor appears across both hardened and unhardened platforms for at least one frontier model, indicating limits to current mitigation strategies.
Where Pith is reading between the lines
- The same mapping could be applied to other persistent agent frameworks to predict which attack surfaces will appear first.
- If the analogy holds, existing OS hardening techniques such as capability-based access or mandatory access control could be ported to agent runtimes with measurable effect.
- The benchmark could be extended to measure utility loss when the platform adds the missing mediation layers, testing whether the observed tradeoffs are inherent or implementation-specific.
Load-bearing premise
The computer-systems analogy produces attack surfaces and failure modes that match those present in real Claw-like agent deployments.
What would settle it
Executing the 406 SafeClawArena tasks against a live production Claw-like agent and finding attack success rates that differ substantially from the reported 70 percent maximum.
Figures
read the original abstract
Claw-like AI agents (e.g., OpenClaw) are always-on processes with persistent access to credentials, files, tools, and external services. They take on system-level responsibilities -- installing packages, maintaining state, scheduling subtasks, and mediating I/O -- making security failures far more severe than in other agents. Yet existing benchmarks focus on model responses and tool calls, leaving cross-component failure modes largely unmeasured. We adopt a computer-system analogy: treating a Claw-like agent as an agentic computer system whose gateway runtime plays an OS-like mediation role, whose Skills resemble user-installed applications, and whose Plugins resemble loadable extensions with runtime privileges. Each component has a classical counterpart whose protection mechanisms -- refined over decades of cybersecurity research -- are absent on the agent side. From this perspective, we develop SafeClawArena, a benchmark of 406 adversarial tasks across four attack surfaces (Skill Supply-Chain Integrity, Persistent State Exploitation, Cross-Boundary Data Flow, and Indirect Prompt Injection), executed in containerized replicas of real agent platforms with canary-marked credentials and evaluated via automated taint tracking across nine output channels. We evaluate three platforms (OpenClaw, NemoClaw, SeClaw) and five frontier LLMs. The highest attack success rate reaches 70%; malicious Plugins succeed in 100% of cases regardless of the LLM. SeClaw cuts GPT-5.4's attack success rate from 70% to 22%, partly through utility-security tradeoffs rather than active defenses, while Claude-Opus-4.6 already sits near a 22% floor on every platform. These results expose the inadequacy of current defenses and suggest directions for future hardening. Code and data: https://github.com/sunblaze-ucb/SafeClawArena.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Claw-like agents (e.g., OpenClaw) pose severe security risks due to persistent credentials, files, tools, and system-level responsibilities. Adopting a computer-systems analogy (gateway runtime as OS, Skills as applications, Plugins as loadable extensions), the authors introduce SafeClawArena: a benchmark of 406 adversarial tasks across four attack surfaces (Skill Supply-Chain Integrity, Persistent State Exploitation, Cross-Boundary Data Flow, Indirect Prompt Injection). Tasks are executed in containerized replicas of real platforms with canary-marked credentials and evaluated via automated taint tracking across nine output channels. On three platforms and five frontier LLMs, the highest attack success rate is 70%, malicious Plugins succeed in 100% of cases regardless of LLM, SeClaw reduces GPT-5.4 ASR from 70% to 22% (partly via utility-security tradeoffs), and Claude-Opus-4.6 sits near a 22% floor on all platforms. Code and data are released.
Significance. If the benchmark construction, task validation, and taint-tracking results hold, the work is significant for importing decades of systems-security insight into agent evaluation and exposing cross-component failure modes that model-only benchmarks miss. Strengths include the containerized replicas, automated taint tracking, release of code/data, and concrete quantitative findings (70% ASR, 100% plugin success, SeClaw reduction) that are falsifiable and reproducible.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript, accurate summary of the contributions, and recommendation to accept. We appreciate the recognition of the benchmark's design, reproducibility, and the value of the systems-security lens for agent evaluation.
Circularity Check
No significant circularity
full rationale
The paper frames an empirical security benchmark (SafeClawArena) via a computer-systems analogy but does not derive quantitative results, attack success rates, or platform comparisons from that analogy by construction. The 406 tasks, four attack surfaces, taint-tracking evaluation, and reported metrics (70% ASR, 100% plugin success, SeClaw reduction to 22%) are obtained through direct execution on external containerized platforms and automated measurement, not from fitted parameters, self-definitions, or self-citation chains. No equations, uniqueness theorems, or ansatzes appear; the central claims rest on experimental outcomes rather than reduction to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The gateway runtime, Skills, and Plugins in Claw-like agents have direct classical counterparts whose protection mechanisms are absent on the agent side.
Reference graph
Works this paper leans on
-
[1]
Anderson
James P. Anderson. Computer security technology planning study. Technical Report ESD-TR- 73-51, U.S. Air Force Electronic Systems Division, 1972
1972
-
[2]
AgentHarm: A benchmark for measuring harmfulness of LLM agents
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, Zico Kolter, Matt Fredrikson, Eric Winsor, Jerome Wynne, Yarin Gal, and Xander Davies. AgentHarm: A benchmark for measuring harmfulness of LLM agents. InProceedings of ICLR, 2025
2025
-
[3]
Elliott Bell and Leonard J
D. Elliott Bell and Leonard J. LaPadula. Secure computer systems: Mathematical foundations. Technical Report MTR-2547, MITRE Corporation, 1973
1973
-
[4]
Kenneth J. Biba. Integrity considerations for secure computer systems. Technical Report MTR-3153, MITRE Corporation, 1977
1977
-
[5]
A trajectory-based safety audit of clawdbot (openclaw)
Tianyu Chen, Dongrui Liu, Xia Hu, Jingyi Yu, and Wenjie Wang. A trajectory-based safety audit of clawdbot (openclaw).arXiv preprint arXiv:2602.14364, 2026
-
[6]
Ai agent security risks in 2026: The incident landscape and hardening frame- work.https://blog.cyberdesserts.com/ai-agent-security-risks/, 2026
CyberDesserts. Ai agent security risks in 2026: The incident landscape and hardening frame- work.https://blog.cyberdesserts.com/ai-agent-security-risks/, 2026
2026
-
[7]
AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents
Edoardo Debenedetti, Jie Zhang, Mislav Balunovi´c, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents. InProceedings of NeurIPS Datasets and Benchmarks Track, 2024
2024
-
[8]
OpenClawCVEs: Tracking OpenClaw CVEs
Jerry Gamblin. OpenClawCVEs: Tracking OpenClaw CVEs. https://github.com/ jgamblin/OpenClawCVEs, 2026. Accessed: 2026-05-06
2026
-
[9]
From Model Scaling to System Scaling: Scaling the Harness in Agentic AI
Shangding Gu. From model scaling to system scaling: Scaling the harness in agentic ai.arXiv preprint arXiv:2605.26112, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Model context protocol (mcp): Landscape, security threats, and future research directions.ACM Transactions on Software Engineering and Methodology, 2025
Xinyi Hou, Yanjie Zhao, Shenao Wang, and Haoyu Wang. Model context protocol (mcp): Landscape, security threats, and future research directions.ACM Transactions on Software Engineering and Methodology, 2025
2025
-
[11]
Malicious openclaw ‘skill’ targets crypto users on clawhub — 14 malicious skills were uploaded to clawhub last month.Tom’s Hardware, 2026
Luke James. Malicious openclaw ‘skill’ targets crypto users on clawhub — 14 malicious skills were uploaded to clawhub last month.Tom’s Hardware, 2026
2026
-
[12]
Juhee Kim, Xiaoyuan Liu, Zhun Wang, Shi Qiu, Bo Li, Wenbo Guo, and Dawn Song. The attack and defense landscape of agentic AI: A comprehensive survey.arXiv preprint arXiv:2603.11088, March 2026
-
[13]
Narek Maloyan and Dmitry Namiot. Breaking the protocol: Security analysis of the model context protocol specification and prompt injection vulnerabilities in tool-integrated llm agents. arXiv preprint arXiv:2601.17549, 2026
-
[14]
Narek Maloyan and Dmitry Namiot. Prompt injection attacks on agentic coding assistants: A systematic analysis of vulnerabilities in skills, tools, and protocol ecosystems.International Journal of Open Information Technologies, 14(2):1–10, 2026
2026
-
[15]
Running openclaw safely: identity, isolation, and runtime risk
Microsoft Security Blog. Running openclaw safely: identity, isolation, and runtime risk. https://www.microsoft.com/en-us/security/blog/2026/02/19/ running-openclaw-safely-identity-isolation-runtime-risk/, February 2026
2026
-
[16]
Nvidia nemoclaw: Reference stack for running openclaw in openshell
NVIDIA. Nvidia nemoclaw: Reference stack for running openclaw in openshell. https: //github.com/NVIDIA/NemoClaw, 2026. Accessed: 2026-05-06
2026
-
[17]
Claudy day: Chaining prompt injection and data exfiltration in claude.ai
Oasis Security Research Team. Claudy day: Chaining prompt injection and data exfiltration in claude.ai. https://www.oasis.security/blog/ claude-ai-prompt-injection-data-exfiltration-vulnerability , March 2026. Accessed: 2026-05-02
2026
-
[18]
SLSA: Supply-chain levels for software artifacts
Open Source Security Foundation. SLSA: Supply-chain levels for software artifacts. https: //slsa.dev/, 2021. 12
2021
-
[19]
Security (gateway).https://docs.openclaw.ai/, 2026
OpenClaw Documentation. Security (gateway).https://docs.openclaw.ai/, 2026
2026
-
[20]
OpenClaw Documentation for Skills. Skills. https://docs.openclaw.ai/tools/skills, 2026
2026
-
[21]
OW ASP top 10 for large language model applications.https://owasp
OW ASP Foundation. OW ASP top 10 for large language model applications.https://owasp. org/www-project-top-10-for-large-language-model-applications/, 2025
2025
-
[22]
OW ASP top 10 for agentic applications.https://genai.owasp.org/ resource/owasp-top-10-for-agentic-applications-for-2026/, 2026
OW ASP Foundation. OW ASP top 10 for agentic applications.https://genai.owasp.org/ resource/owasp-top-10-for-agentic-applications-for-2026/, 2026
2026
-
[23]
Coding agents: A comprehensive survey of automated bug fixing systems and benchmarks
Meghana Puvvadi, Sai Kumar Arava, Adarsh Santoria, Sesha Sai Prasanna Chennupati, and Harsha Vardhan Puvvadi. Coding agents: A comprehensive survey of automated bug fixing systems and benchmarks. In2025 IEEE 14th International Conference on Communication Systems and Network Technologies (CSNT), pages 680–686. IEEE, 2025
2025
-
[24]
Securing LLM Agents Need Intent-to-Execution Integrity
Wenjie Qu, Ming Xu, Peiran Wang, Shengfang Zhai, Jiaheng Zhang, and Dawn Song. Securing llm agents need intent-to-execution integrity.arXiv preprint arXiv:2605.16976, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Brandon Radosevich and John Halloran. Mcp safety audit: Llms with the model context protocol allow major security exploits.arXiv preprint arXiv:2504.03767, 2025
-
[26]
Maddison, and Tatsunori Hashimoto
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J. Maddison, and Tatsunori Hashimoto. Identifying the risks of LM agents with an LM-emulated sandbox. InProceedings of ICLR (Spotlight), 2024
2024
-
[27]
SeClaw: Secured personal ai assistant
SaFoLab. SeClaw: Secured personal ai assistant. https://safo-lab.github.io/seclaw/,
-
[28]
Accessed: 2026-05-06
2026
-
[29]
Saltzer and Michael D
Jerome H. Saltzer and Michael D. Schroeder. The protection of information in computer systems. Proceedings of the IEEE, 63(9):1278–1308, 1975
1975
-
[30]
Openclaw — personal ai assistant.github, 2026
Openclaw Team. Openclaw — personal ai assistant.github, 2026
2026
-
[31]
arXiv preprint arXiv:2503.04957 , year =
Ada Defne Tur, Nicholas Meade, Xing Han Lù, Alejandra Zambrano, Arkil Patel, Esin Durmus, Spandana Gella, Karolina Sta ´nczak, and Siva Reddy. Safearena: Evaluating the safety of autonomous web agents.arXiv preprint arXiv:2503.04957, 2025
-
[32]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Johannes Heidecke, and Alex Beutel. The instruction hierarchy: Training LLMs to prioritize privileged instructions.arXiv preprint arXiv:2404.13208, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
The landscape of prompt injection threats in LLM agents: From taxonomy to analysis,
Peiran Wang, Xinfeng Li, Chong Xiang, Jinghuai Zhang, Ying Li, Lixia Zhang, Xiaofeng Wang, and Yuan Tian. The landscape of prompt injection threats in llm agents: From taxonomy to analysis.arXiv preprint arXiv:2602.10453, 2026
-
[34]
A Systematic Security Evaluation of OpenClaw and Its Variants
Yuhang Wang, Haichang Gao, Zhenxing Niu, Zhaoxiang Liu, Wenjing Zhang, Xiang Wang, and Shiguo Lian. A systematic security evaluation of OpenClaw and its variants.arXiv preprint arXiv:2604.03131, April 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
ClawSafety: "Safe" LLMs, Unsafe Agents
Bowen Wei, Yunbei Zhang, Jinhao Pan, Kai Mei, Xiao Wang, Jihun Hamm, Ziwei Zhu, and Yingqiang Ge. ClawSafety: “Safe” LLMs, unsafe agents.arXiv preprint arXiv:2604.01438, April 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
SecureWebArena: A Holistic Security Evaluation Benchmark for LVLM-based Web Agents
Zonghao Ying, Yangguang Shao, Jianle Gan, Gan Xu, Wenxin Zhang, Quanchen Zou, Junzheng Shi, Zhenfei Yin, Mingchuan Zhang, Aishan Liu, et al. Securewebarena: A holistic security evaluation benchmark for lvlm-based web agents.arXiv preprint arXiv:2510.10073, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
R-Judge: Benchmarking safety risk awareness for LLM agents
Tongxin Yuan, Zhiwei He, Lingzhong Dong, Yiming Wang, Ruijie Zhao, Tian Xia, Lizhen Xu, Binglin Zhou, Fangqi Li, Zhuosheng Zhang, Rui Wang, and Gongshen Liu. R-Judge: Benchmarking safety risk awareness for LLM agents. InFindings of EMNLP, 2024
2024
-
[38]
InjecAgent: Benchmarking indirect prompt injections in tool-integrated large language model agents
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. InjecAgent: Benchmarking indirect prompt injections in tool-integrated large language model agents. InFindings of ACL, 2024. 13
2024
-
[39]
Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents
Hanrong Zhang, Jingyuan Huang, Kai Mei, Yifei Yao, Zhenting Wang, Chenlu Zhan, Hongwei Wang, and Yongfeng Zhang. Agent security bench (asb): Formalizing and benchmarking attacks and defenses in llm-based agents.arXiv preprint arXiv:2410.02644, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
arXiv preprint arXiv:2508.12752 , year=
Wenlin Zhang, Xiaopeng Li, Yingyi Zhang, Pengyue Jia, Yichao Wang, Huifeng Guo, Yong Liu, and Xiangyu Zhao. Deep research: A survey of autonomous research agents.arXiv preprint arXiv:2508.12752, 2025
-
[41]
Agent-SafetyBench: Evaluating the Safety of LLM Agents
Zhexin Zhang, Shiyao Cui, Yida Lu, Jingzhuo Zhou, Junxiao Yang, Hongning Wang, and Minlie Huang. Agent-safetybench: Evaluating the safety of llm agents.arXiv preprint arXiv:2412.14470, 2024. 14 Appendix A Detailed Comparison with Prior Benchmarks 16 B Component-to-Classical-System Mapping and Security Principles 16 B.1 Component-to-Classical-System Mappin...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.