MineXplore: An Open-Source Reinforcement Learning Exploration Benchmark for GNSS-Denied Underground Environment
Pith reviewed 2026-06-28 06:17 UTC · model grok-4.3
The pith
MineXplore converts real underground mine survey data into a MuJoCo environment for training reinforcement learning navigation policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
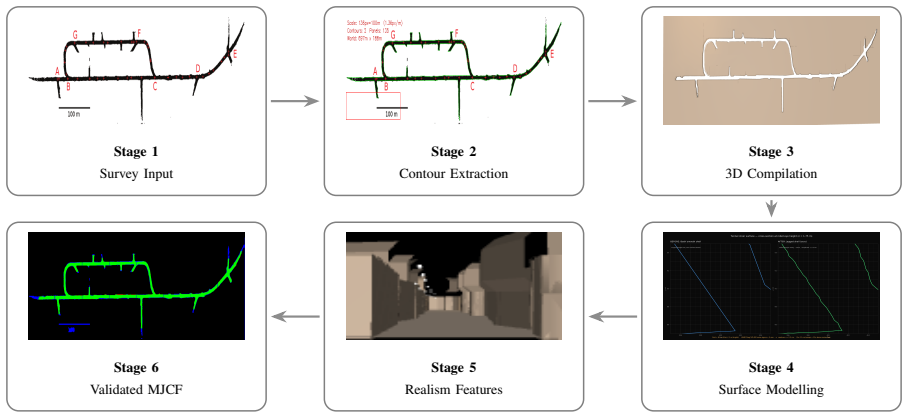
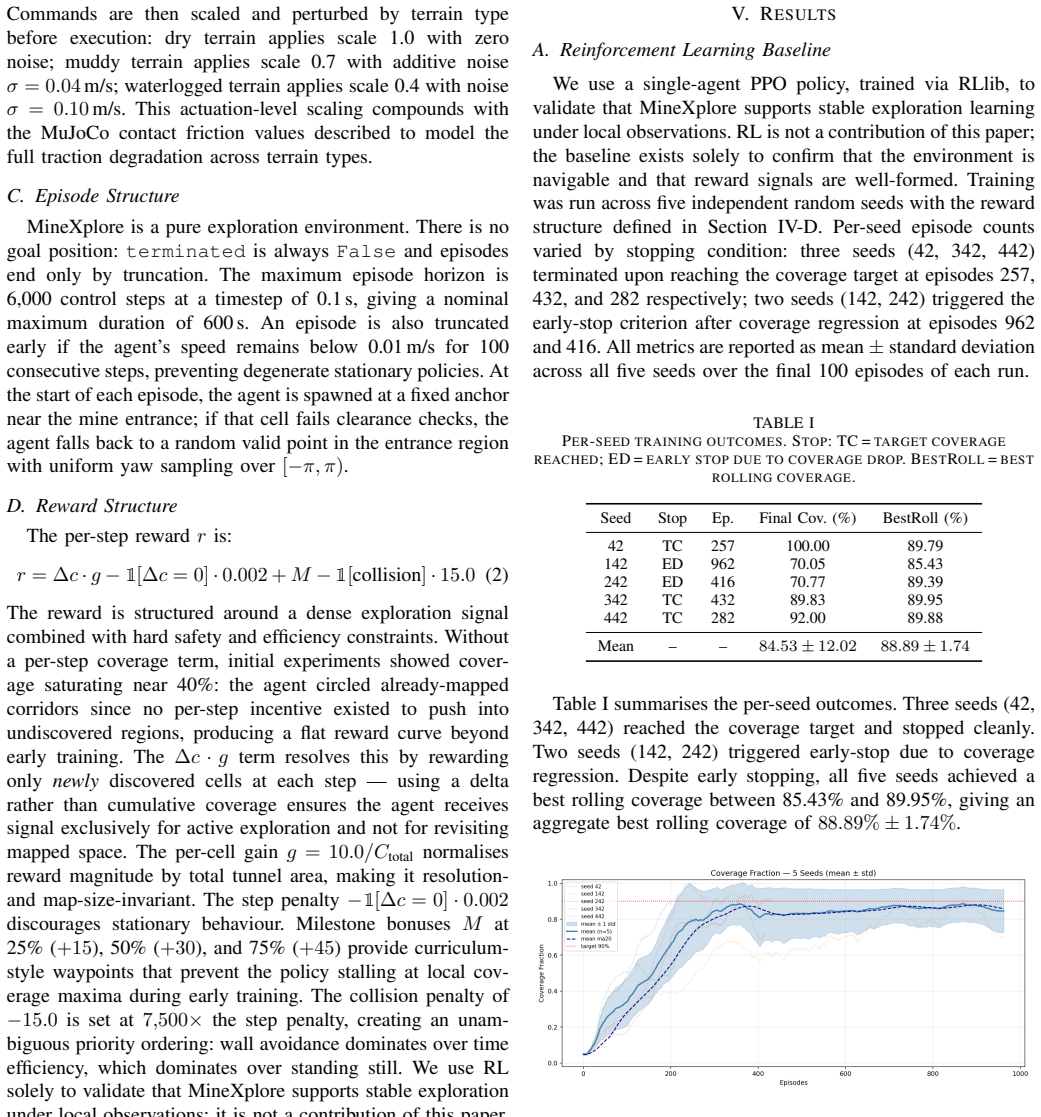
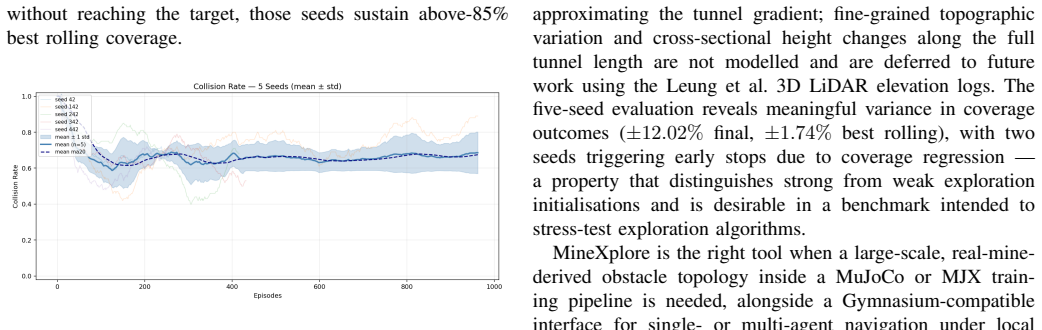
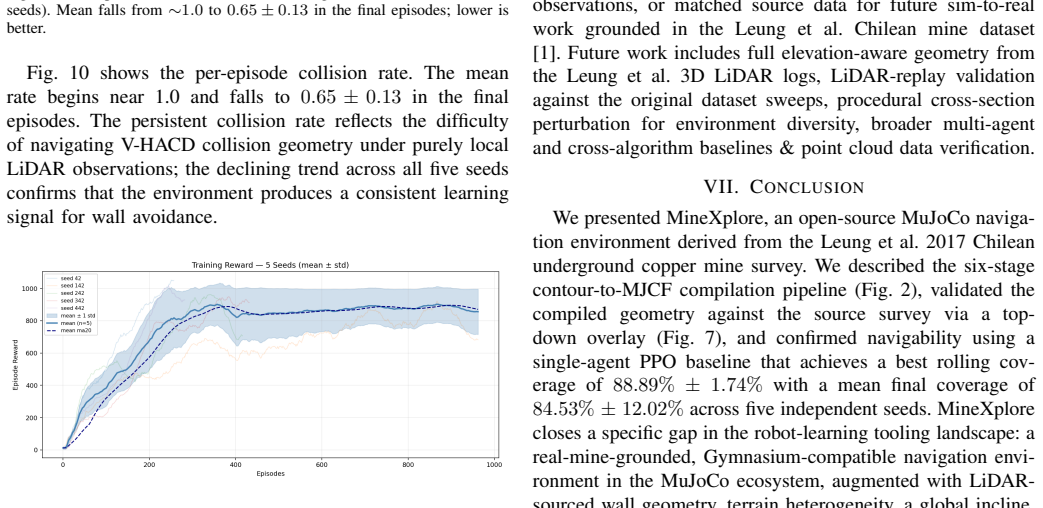
MineXplore is a MuJoCo-based navigation benchmark derived from the Leung et al. 2017 dataset via a six-stage contour-to-MJCF pipeline that produces octagonal walls, LiDAR jagged geometry, three friction zones, a global 5 degree incline, and periodic spot lighting, validated at 0.9538 IoU and 79.4 percent surface similarity, and shown to support stable PPO policy learning with a best rolling coverage of 88.89 percent across five random seeds.
What carries the argument
The six-stage contour-to-MJCF pipeline that turns survey contours into a MuJoCo model incorporating realistic tunnel cross-sections, jagged walls, friction zones, incline, and lighting.
If this is right
- The benchmark enables reproducible evaluation of single-agent exploration policies in non-convex, loop-rich tunnel networks.
- Compatibility with RLlib supports GPU-accelerated training runs that produce stable results across random seeds.
- The environment provides a standardized testbed for GNSS-denied navigation under realistic underground sensing conditions.
- High IoU and surface similarity scores establish a baseline for comparing future model variants or sensor additions.
Where Pith is reading between the lines
- Similar reconstruction pipelines could be applied to other mine survey datasets to expand the set of available underground benchmarks.
- Policies trained here could be tested for transfer to physical robots operating in comparable real tunnels.
- The setup allows direct comparison of different reinforcement learning algorithms or multi-agent variants within the same fixed environment.
Load-bearing premise
The converted simulation model matches the real mine's geometry and surface properties closely enough for reinforcement learning policies to be meaningful.
What would settle it
Retraining the PPO baseline after deliberately lowering the model's geometric IoU and checking whether the 88.89 percent coverage result disappears would test whether the fidelity level is required for the reported learning outcome.
Figures




read the original abstract
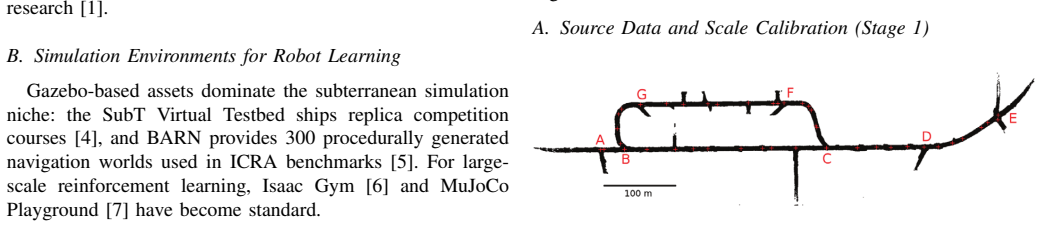
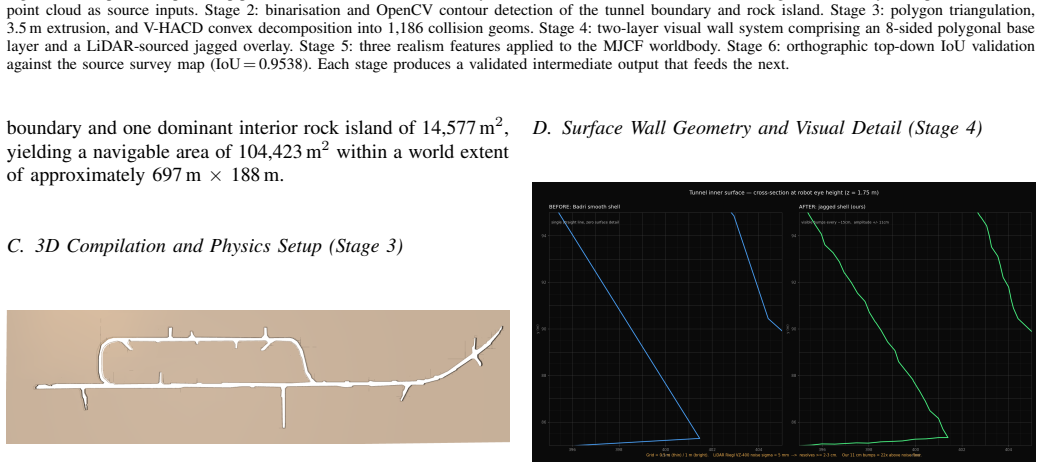
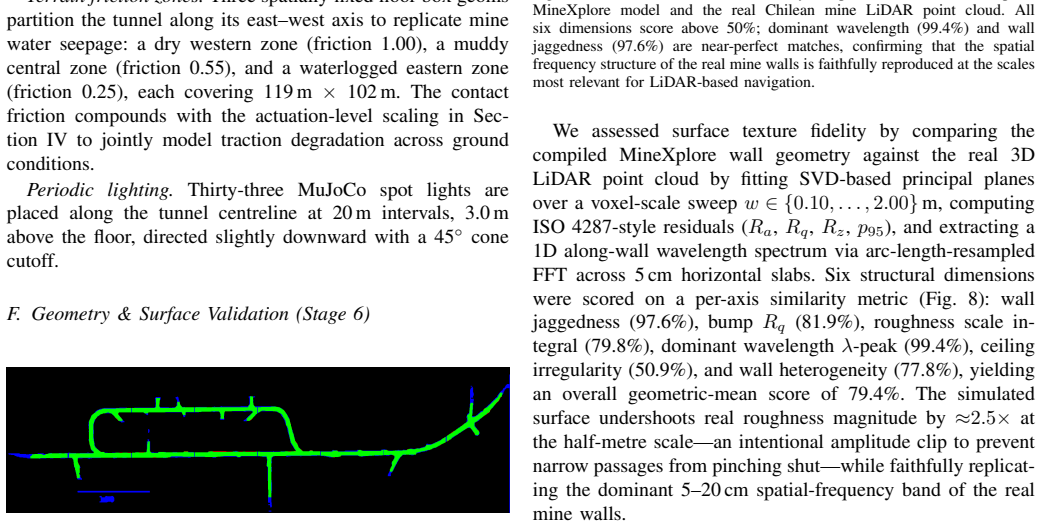
Underground mines present extreme conditions for autonomous robot navigation: GPS is denied, lighting is degraded, and tunnel topology is loop-rich and non-convex. Simulation benchmarks grounded in real production-mine geometry and compatible with GPU-accelerated learning pipelines do not yet exist in the open-source ecosystem. We present MineXplore, an open-source MuJoCo-based navigation benchmark derived from the Leung et al. 2017 Chilean underground copper mine dataset. The environment reconstructs a 104,423 sq.m tunnel network through an six-stage contour-to-MJCF pipeline incorporating octagonal wall cross-sections, LiDAR-sourced jagged wall geometry, three terrain friction zones, a global 5 degree incline, and periodic spot lighting. Geometric fidelity is validated at an Intersection over Union (IoU) of 0.9538 against the source survey map, and surface texture similarity scores 79.4% across six structural dimensions. A single-agent PPO baseline trained via RLlib across five independent random seeds achieves a best rolling coverage of 88.89% (3 of 5 seeds reaching the 90% coverage target), confirming that MineXplore supports stable and reproducible policy learning under realistic underground sensing and topology.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MineXplore, an open-source MuJoCo-based benchmark for RL exploration in GNSS-denied underground mines. Derived from the Leung et al. 2017 dataset via a six-stage contour-to-MJCF pipeline, it includes octagonal cross-sections, jagged walls, friction zones, incline, and lighting. Validation shows IoU of 0.9538 and 79.4% texture similarity. A PPO baseline with RLlib across 5 seeds achieves 88.89% best rolling coverage, with 3 seeds reaching 90%.
Significance. If the simulation fidelity is adequate, this benchmark fills an important gap in open-source tools for realistic underground robot navigation research. The grounding in real survey data and compatibility with RLlib are notable strengths that could facilitate reproducible studies on exploration policies in challenging environments.
major comments (2)
- [Abstract] Abstract: The claim that the PPO baseline confirms MineXplore supports 'stable and reproducible policy learning under realistic underground sensing and topology' depends on simulation fidelity, yet the reported validation (IoU 0.9538, 79.4% texture similarity) addresses only static geometry and surface properties; no evidence is given that dynamics, connectivity, or sensor behavior match the source survey sufficiently to rule out artifacts.
- [Abstract] Abstract / baseline results: The 'best rolling coverage of 88.89%' is obtained by post-hoc selection across seeds, with only 3 of 5 reaching the 90% target; this selection procedure and the absence of reported statistical significance testing or full hyperparameter details undermine the reproducibility and stability claims.
minor comments (2)
- [Abstract] The six-stage pipeline is referenced but the individual stages are not listed in the abstract; a concise enumeration or pointer to the methods section would improve clarity.
- The open-source release is a strength; ensure the repository includes exact environment configuration files, random seeds, and training scripts matching the reported baseline.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and will revise the manuscript accordingly to improve clarity on validation scope and baseline reporting.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the PPO baseline confirms MineXplore supports 'stable and reproducible policy learning under realistic underground sensing and topology' depends on simulation fidelity, yet the reported validation (IoU 0.9538, 79.4% texture similarity) addresses only static geometry and surface properties; no evidence is given that dynamics, connectivity, or sensor behavior match the source survey sufficiently to rule out artifacts.
Authors: We agree that the reported validation is limited to static geometric (IoU 0.9538) and textural (79.4%) fidelity derived from the Leung et al. 2017 survey. No direct validation of dynamics, connectivity, or sensor models against the source data is provided. The abstract claim regarding 'realistic underground sensing and topology' will be revised to specify that the benchmark is grounded in real geometry and topology while noting the absence of dynamic validation, to avoid overstating fidelity. revision: yes
-
Referee: [Abstract] Abstract / baseline results: The 'best rolling coverage of 88.89%' is obtained by post-hoc selection across seeds, with only 3 of 5 reaching the 90% target; this selection procedure and the absence of reported statistical significance testing or full hyperparameter details undermine the reproducibility and stability claims.
Authors: The referee correctly identifies that the reported 'best rolling coverage' reflects post-hoc selection across the five seeds, with only three reaching the 90% target. We will revise the abstract to report mean coverage and standard deviation across seeds instead, and we will add full hyperparameter details and any available statistical tests to the methods section to support reproducibility claims. revision: yes
Circularity Check
No circularity: benchmark derived from external data with standard RL baseline
full rationale
The paper constructs MineXplore from the external Leung et al. 2017 survey dataset via a six-stage contour-to-MJCF pipeline, reports geometric validation (IoU 0.9538) against that source, and evaluates a standard off-the-shelf PPO implementation from RLlib across random seeds. No equations, fitted parameters, or predictions reduce to the paper's own inputs by construction; the central claim rests on external data and unmodified algorithms rather than self-definition or self-citation chains. This is the most common honest non-finding for benchmark papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chilean underground mine dataset,
K. Y . K. Leung, D. Luhr, H. Houshiar, F. Inostroza, D. Borrmann, M. Adams, A. N ¨uchter, and J. Ruiz-del-Solar, “Chilean underground mine dataset,”The International Journal of Robotics Research, vol. 36, no. 1, pp. 16–23, 2017. DOI: 10.1177/0278364916679497
-
[2]
CERBERUS in the DARPA Subterranean Challenge,
M. Tranzatto, T. Miki, M. Dharmadhikari, L. Bernreiter, M. Kulkarni, F. Mascarich, O. Andersson, S. Khattak, M. Hutter, R. Siegwart, and K. Alexis, “CERBERUS in the DARPA Subterranean Challenge,” Science Robotics, vol. 7, no. 66, p. eabp9742, 2022
2022
-
[3]
Present and future of SLAM in extreme environments: The DARPA SubT Challenge,
K. Ebadi, L. Bernreiter, H. Biggie, G. Catt, Y . Changet al., “Present and future of SLAM in extreme environments: The DARPA SubT Challenge,”IEEE Transactions on Robotics, vol. 40, pp. 936–959, 2024
2024
-
[4]
DARPA SubT Virtual Testbed,
Open Robotics, “DARPA SubT Virtual Testbed,” 2021. [Online]. Avail- able: https://github.com/osrf/subt
2021
-
[5]
Benchmarking metric ground navigation,
D. Perille, A. Truong, X. Xiao, and P. Stone, “Benchmarking metric ground navigation,” inProc. IEEE Int. Symp. Safety, Security, and Rescue Robotics (SSRR), 2020
2020
-
[6]
Isaac Gym: High performance GPU based physics simulation for robot learning,
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, and G. State, “Isaac Gym: High performance GPU based physics simulation for robot learning,” in NeurIPS Datasets and Benchmarks Track, 2021
2021
-
[7]
arXiv preprint arXiv:2502.08844 , year=
K. Zakka, B. Tabanpour, Q. Liao, M. Haiderbhai, S. Holt, J. Y . Luo, A. Allshire, E. Frey, K. Sreenath, L. A. Kahrs, C. Sferrazza, Y . Tassa, and P. Abbeel, “MuJoCo Playground,”arXiv preprint arXiv:2502.08844, 2025
-
[8]
Navigation in underground mine environ- ments: A simulation framework for quadruped robots,
Y . Gao and K. Awuah-Offei, “Navigation in underground mine environ- ments: A simulation framework for quadruped robots,” inProc. IEEE Int. Conf. Automation Science and Engineering (CASE), 2025, pp. 1464– 1469
2025
-
[9]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proxi- mal Policy Optimization Algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
M. Towers, A. Kwiatkowski, J. Terry, J. U. Balis, G. De Cola, T. Deleu, M. Goul ˜ao, A. Kallinteris, M. Krimmel, A. KG, R. Perez-Vicente, A. Pierr´e, S. Schulhoff, J. J. Tai, H. Tan, and O. G. Younis, “Gymnasium: A Standard Interface for Reinforcement Learning Environments,”arXiv preprint arXiv:2407.17032, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
RLlib: Abstractions for Distributed Reinforcement Learning,
E. Liang, R. Liaw, R. Nishihara, P. Moritz, R. Fox, K. Goldberg, J. Gon- zalez, M. Jordan, and I. Stoica, “RLlib: Abstractions for Distributed Reinforcement Learning,” inProc. 35th Int. Conf. Machine Learning (ICML), 2018, pp. 3053–3062
2018
-
[12]
MuJoCo: A physics engine for model-based control,
E. Todorov, T. Erez, and Y . Tassa, “MuJoCo: A physics engine for model-based control,” inProc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems (IROS), 2012, pp. 5026–5033
2012
-
[13]
A frontier-based approach for autonomous exploration,
B. Yamauchi, “A frontier-based approach for autonomous exploration,” inProc. IEEE Int. Symp. Computational Intelligence in Robotics and Automation (CIRA), 1997, pp. 146–151
1997
-
[14]
Policy invariance under reward transformations: Theory and application to reward shaping,
A. Y . Ng, D. Harada, and S. Russell, “Policy invariance under reward transformations: Theory and application to reward shaping,” inProc. 16th Int. Conf. Machine Learning (ICML), 1999, pp. 278–287
1999
-
[15]
Unifying count-based exploration and intrinsic motivation,
M. G. Bellemare, S. Srinivasan, G. Ostrovski, T. Schaul, D. Saxton, and R. Munos, “Unifying count-based exploration and intrinsic motivation,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 29, 2016
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.