Energy-Based Transformers as Predictors of Reading Difficulty
Pith reviewed 2026-06-26 08:06 UTC · model grok-4.3
The pith
Energy-based transformers produce an energy measure that predicts reading times with significant fit beyond surprisal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
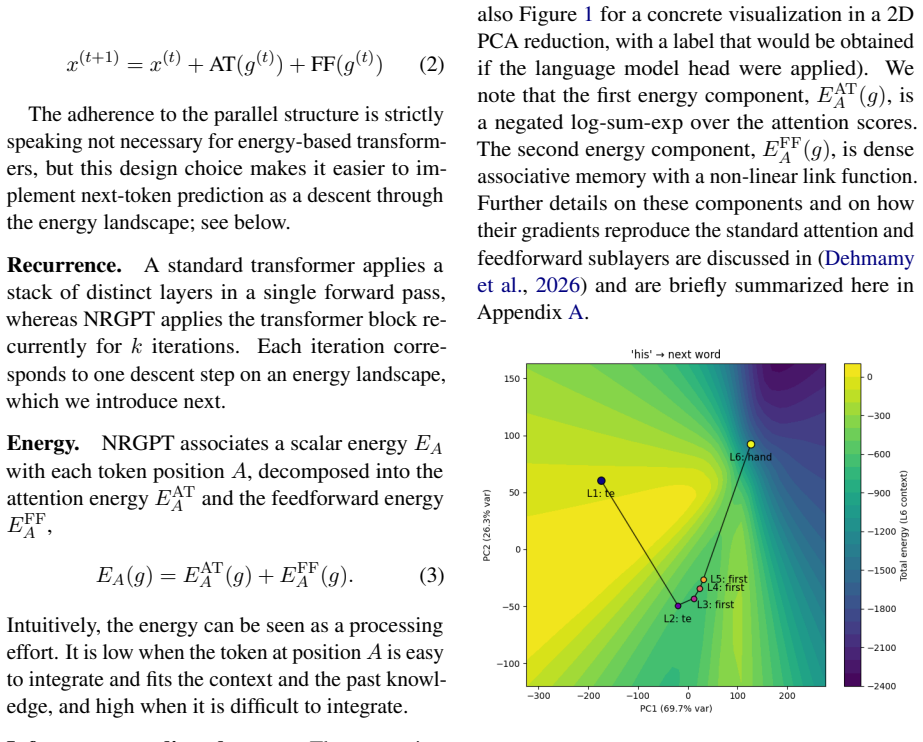
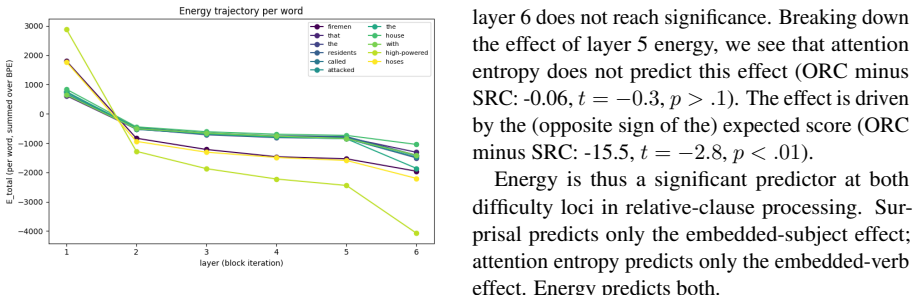
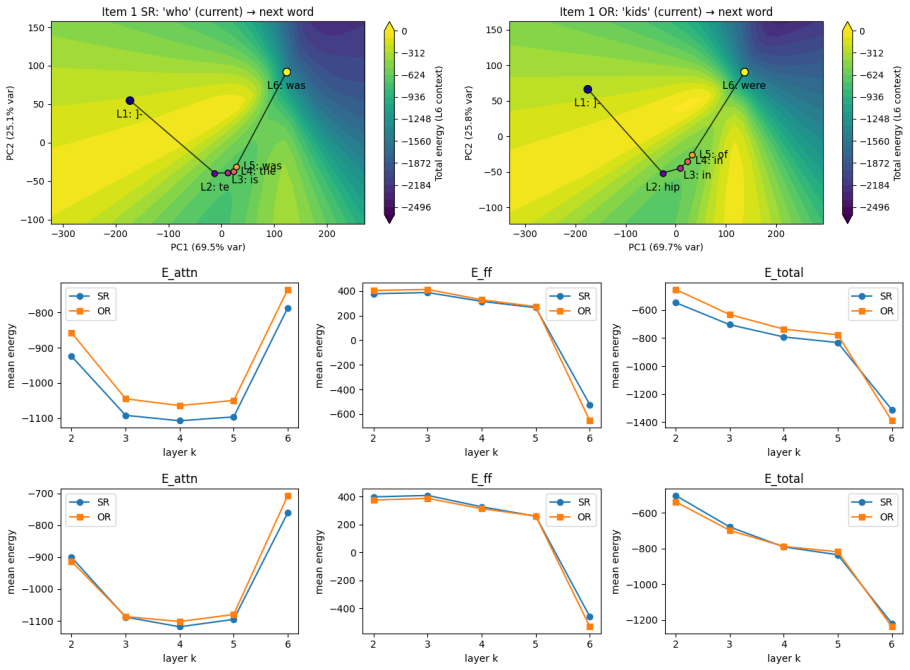
Energy-based transformers supply an energy measure that robustly predicts reading times, adding significant fit beyond surprisal in the Natural Stories, UCL eye-tracking, and UCL self-paced reading corpora. At a single layer the same measure captures the object/subject relative-clause asymmetry. It subsumes effects attributable to both attention entropy and surprisal, offering the possibility of a single unified predictor of processing load.
What carries the argument
The energy function computed from the parameters of an energy-based transformer, which supplies a formal link to Hopfield networks and dense associative memory.
If this is right
- Energy supplies statistically significant additional fit to reading times beyond surprisal in three independent corpora.
- Single-layer energy reproduces the classic object/subject relative-clause asymmetry.
- Energy accounts for variance previously attributed separately to surprisal and to attention entropy.
- Processing research gains a direct formal connection to associative memory models.
Where Pith is reading between the lines
- If the energy-reading time link holds, the same quantity could be extracted from other transformer variants without separate surprisal calculations.
- The approach invites direct tests of whether energy predicts processing measures outside English or outside reading.
- Training regimes that alter the energy landscape might be examined for their effect on the correlation with human difficulty.
Load-bearing premise
The energy value obtained from the trained transformer directly indexes the cognitive load experienced by human readers rather than merely correlating with it.
What would settle it
A new corpus or controlled experiment in which energy shows no reliable additional predictive power for reading times once surprisal is accounted for, or fails to capture the object/subject asymmetry.
Figures
read the original abstract
Transformer language models have become established tools for modeling human sentence processing, with measures such as surprisal and attention entropy serving as effective predictors of reading difficulty that together capture complementary aspects of processing load. Here, we explore a related class of transformer models: energy-based transformers, which provide a principled formal link to associative memory models, bringing processing research into direct contact with the broader literature on Hopfield networks and dense associative memory. To our knowledge, this is the first exploration of an energy-based transformer measure in computational psycholinguistics. Across reading-time corpora (Natural Stories, UCL eye-tracking, UCL self-paced reading), the energy measure is a robust predictor of reading times, providing significant fit beyond surprisal in all three. In a controlled experiment on relative clause processing, energy at a single layer captures the well-known object/subject asymmetry. We find evidence that it subsumes effects attributable to both attention entropy and surprisal, suggesting that energy may serve as a single unified predictor where multiple complementary measures have previously been required.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces energy-based transformers as a new class of models for computational psycholinguistics, linking them to Hopfield networks and associative memory. It claims that an energy measure derived from these models is a robust predictor of reading times, yielding significant incremental fit beyond surprisal across three corpora (Natural Stories, UCL eye-tracking, UCL self-paced reading), capturing the object/subject relative clause asymmetry at a single layer in a controlled experiment, and subsuming effects of both attention entropy and surprisal to serve as a unified predictor.
Significance. If the central results hold after controls, the work would strengthen connections between transformer-based language modeling and classical associative-memory formalisms, potentially offering a single theoretically motivated predictor in place of multiple ad-hoc measures. The provision of machine-checked or reproducible elements is not mentioned, but the cross-corpus replication and controlled experiment are positive features if the statistical details support the incremental-fit claims.
major comments (2)
- [Abstract] Abstract and introduction: the claim that energy 'provides significant fit beyond surprisal in all three' corpora and 'subsumes' attention entropy rests on regression results whose details (model specifications, error-bar reporting, data-exclusion rules, multiple-comparison correction) are not visible in the provided text; without these it is impossible to verify whether the incremental R² survives standard controls.
- No equations or formal definition of the energy function E(·) appear in the abstract or opening sections; the mapping from network energy (computed post-training) to human processing load is therefore invoked without derivation from the Hopfield/associative-memory formalism or any pre-registered test that would distinguish it from post-hoc correlation inherited from the training distribution.
minor comments (2)
- Notation for the energy measure, surprisal, and attention entropy should be introduced with explicit equations early in the methods section to allow readers to assess independence.
- The controlled experiment on relative clauses is mentioned only briefly; a table or figure showing the layer-specific energy values and statistical contrast for object vs. subject conditions would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below, indicating where revisions will be made to improve clarity and verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract and introduction: the claim that energy 'provides significant fit beyond surprisal in all three' corpora and 'subsumes' attention entropy rests on regression results whose details (model specifications, error-bar reporting, data-exclusion rules, multiple-comparison correction) are not visible in the provided text; without these it is impossible to verify whether the incremental R² survives standard controls.
Authors: The full regression model specifications (including formulas with fixed and random effects), data-exclusion rules, multiple-comparison corrections, and error-bar details are reported in the Methods (Section 3.3) and Results (Section 4), with supplementary tables providing the complete coefficient tables and incremental R² values. We agree that the abstract and introduction would benefit from explicit pointers to these sections. We will revise the introduction to include a one-sentence summary of the regression approach and add a reference to the supplementary materials for the full statistical tables. revision: partial
-
Referee: [—] No equations or formal definition of the energy function E(·) appear in the abstract or opening sections; the mapping from network energy (computed post-training) to human processing load is therefore invoked without derivation from the Hopfield/associative-memory formalism or any pre-registered test that would distinguish it from post-hoc correlation inherited from the training distribution.
Authors: Section 2.1–2.2 provides the formal definition of the energy function E(·) derived directly from the Hopfield energy and its equivalence to the transformer’s associative-memory formulation, along with the post-training computation. We acknowledge that the opening sections would be strengthened by an early reference to this derivation. We will add a concise paragraph in the introduction that states the energy definition and its theoretical grounding in associative memory, while noting that the controlled relative-clause experiment (Section 5) was designed to test predictions beyond training-distribution correlations. The analyses were not pre-registered; we will add an explicit statement to this effect in the Methods. revision: yes
Circularity Check
No significant circularity; energy measure independent of reading-time targets
full rationale
The derivation begins with the standard energy-based transformer formulation (linked formally to Hopfield/associative memory networks) whose energy function is computed from the model's own parameters after language-model training. This energy is then applied as a regressor to separate reading-time corpora without any indication that the energy definition, parameters, or selection were fitted to or defined in terms of the reading-time data itself. No self-definitional equations, fitted-input predictions, or load-bearing self-citations appear in the abstract or described chain; the mapping from energy to processing load is an interpretive step rather than a definitional reduction. The result is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Energy-based transformers provide a formal link to associative memory models such as Hopfield networks.
Reference graph
Works this paper leans on
-
[1]
A probabilistic
Hale, John , booktitle =. A probabilistic. 2001 , address =
2001
-
[2]
Cognition , volume =
Expectation-based syntactic comprehension , author =. Cognition , volume =. 2008 , publisher =
2008
-
[3]
Frontiers in Psychology , volume=
Surprisal, the PDC, and the primary locus of processing difficulty in relative clauses , author=. Frontiers in Psychology , volume=. 2013 , publisher=
2013
-
[4]
Proceedings of the 15th conference of the european chapter of the association for computational linguistics: Volume 1, long papers , pages=
Noisy-context surprisal as a human sentence processing cost model , author=. Proceedings of the 15th conference of the european chapter of the association for computational linguistics: Volume 1, long papers , pages=
-
[5]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Entropy-and distance-based predictors from GPT-2 attention patterns predict reading times over and above GPT-2 surprisal , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[6]
arXiv preprint arXiv:2603.09872 , year=
N-gram-like Language Models Predict Reading Time Best , author=. arXiv preprint arXiv:2603.09872 , year=
-
[7]
The dependency locality theory:
Gibson, Edward , booktitle =. The dependency locality theory:. 2000 , publisher =
2000
-
[8]
Cognitive Science , volume =
An activation-based model of sentence processing as skilled memory retrieval , author =. Cognitive Science , volume =. 2005 , publisher =
2005
-
[9]
Cognitive Science , volume =
Consequences of the serial nature of linguistic input for sentential complexity , author =. Cognitive Science , volume =. 2005 , publisher =
2005
-
[10]
Cognition , volume =
Eye movements and processing difficulty in object relative clauses , author =. Cognition , volume =. 2010 , publisher =
2010
-
[11]
and Blank, Idan and Vishnevetsky, Anastasia and Piantadosi, Steven T
Futrell, Richard and Gibson, Edward and Tily, Harry J. and Blank, Idan and Vishnevetsky, Anastasia and Piantadosi, Steven T. and Fedorenko, Evelina , journal =. The. 2021 , publisher =
2021
-
[12]
Transactions of the Association for Computational Linguistics , volume =
Why does surprisal from larger transformer-based language models provide a poorer fit to human reading times? , author =. Transactions of the Association for Computational Linguistics , volume =. 2023 , doi =
2023
-
[13]
and Monsalve, Irene Fernandez and Thompson, Robin L
Frank, Stefan L. and Monsalve, Irene Fernandez and Thompson, Robin L. and Vigliocco, Gabriella. Reading time data for evaluating broad-coverage models of English sentence processing. Behavior Research Methods
-
[14]
Proceedings of
NRGPT: An Energy-based Alternative for GPT , author=. Proceedings of
-
[15]
Journal of Memory and Language , volume=
Memory for prediction: A Transformer-based theory of sentence processing , author=. Journal of Memory and Language , volume=. 2025 , publisher=
2025
-
[16]
arXiv preprint arXiv:2510.05141 , year=
To model human linguistic prediction, make LLMs less superhuman , author=. arXiv preprint arXiv:2510.05141 , year=
-
[17]
A Language Model with Limited Memory Capacity Captures Interference in Human Sentence Processing
Timkey, William and Linzen, Tal. A Language Model with Limited Memory Capacity Captures Interference in Human Sentence Processing. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.582
-
[18]
Psychometric Predictive Power of Large Language Models
Kuribayashi, Tatsuki and Oseki, Yohei and Baldwin, Timothy. Psychometric Predictive Power of Large Language Models. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi:10.18653/v1/2024.findings-naacl.129
-
[19]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Linear recency bias during training improves transformers’ fit to reading times , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[20]
2025 , eprint=
Human-like fleeting memory improves language learning but impairs reading time prediction in transformer language models , author=. 2025 , eprint=
2025
-
[21]
Proceedings of the workshop on cognitive modeling and computational linguistics , pages=
Locally biased transformers better align with human reading times , author=. Proceedings of the workshop on cognitive modeling and computational linguistics , pages=
-
[22]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Causal estimation of memorisation profiles , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[23]
Gokaslan, Aaron and Cohen, Vanya , year =
-
[24]
Cognitive science , volume=
Lossy-context surprisal: An information-theoretic model of memory effects in sentence processing , author=. Cognitive science , volume=. 2020 , publisher=
2020
-
[25]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[26]
Transactions of the Association for Computational Linguistics , volume=
Testing the predictions of surprisal theory in 11 languages , author=. Transactions of the Association for Computational Linguistics , volume=. 2023 , publisher=
2023
-
[27]
Hao, Yiding and Mendelsohn, Simon and Sterneck, Rachel and Martinez, Randi and Frank, Robert. Probabilistic Predictions of People Perusing: Evaluating Metrics of Language Model Performance for Psycholinguistic Modeling. Proceedings of the Workshop on Cognitive Modeling and Computational Linguistics. 2020. doi:10.18653/v1/2020.cmcl-1.10
-
[28]
Open Mind , volume=
The plausibility of sampling as an algorithmic theory of sentence processing , author=. Open Mind , volume=. 2023 , publisher=
2023
-
[29]
Proceedings of the National Academy of Sciences , volume=
A resource-rational model of human processing of recursive linguistic structure , author=. Proceedings of the National Academy of Sciences , volume=. 2022 , publisher=
2022
-
[30]
Proceedings of the workshop on cognitive modeling and computational linguistics , pages=
Accounting for agreement phenomena in sentence comprehension with transformer language models: Effects of similarity-based interference on surprisal and attention , author=. Proceedings of the workshop on cognitive modeling and computational linguistics , pages=
-
[31]
, author=
Neural networks and physical systems with emergent collective computational abilities. , author=. Proceedings of the national academy of sciences , volume=
-
[32]
Advances in neural information processing systems , volume=
Energy transformer , author=. Advances in neural information processing systems , volume=
-
[33]
Advances in neural information processing systems , volume=
Dense associative memory for pattern recognition , author=. Advances in neural information processing systems , volume=
-
[34]
arXiv preprint arXiv:2008.02217 , year=
Hopfield networks is all you need , author=. arXiv preprint arXiv:2008.02217 , year=
Pith/arXiv arXiv 2008
-
[35]
arXiv preprint arXiv:2507.06211 , year=
Modern methods in associative memory , author=. arXiv preprint arXiv:2507.06211 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.