Zero-Label Driving Scenario Complexity Detection via Joint Embedding Predictive Architecture
Pith reviewed 2026-06-30 10:47 UTC · model grok-4.3
The pith
A self-supervised world model can score driving scenario complexity using only its temporal prediction errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
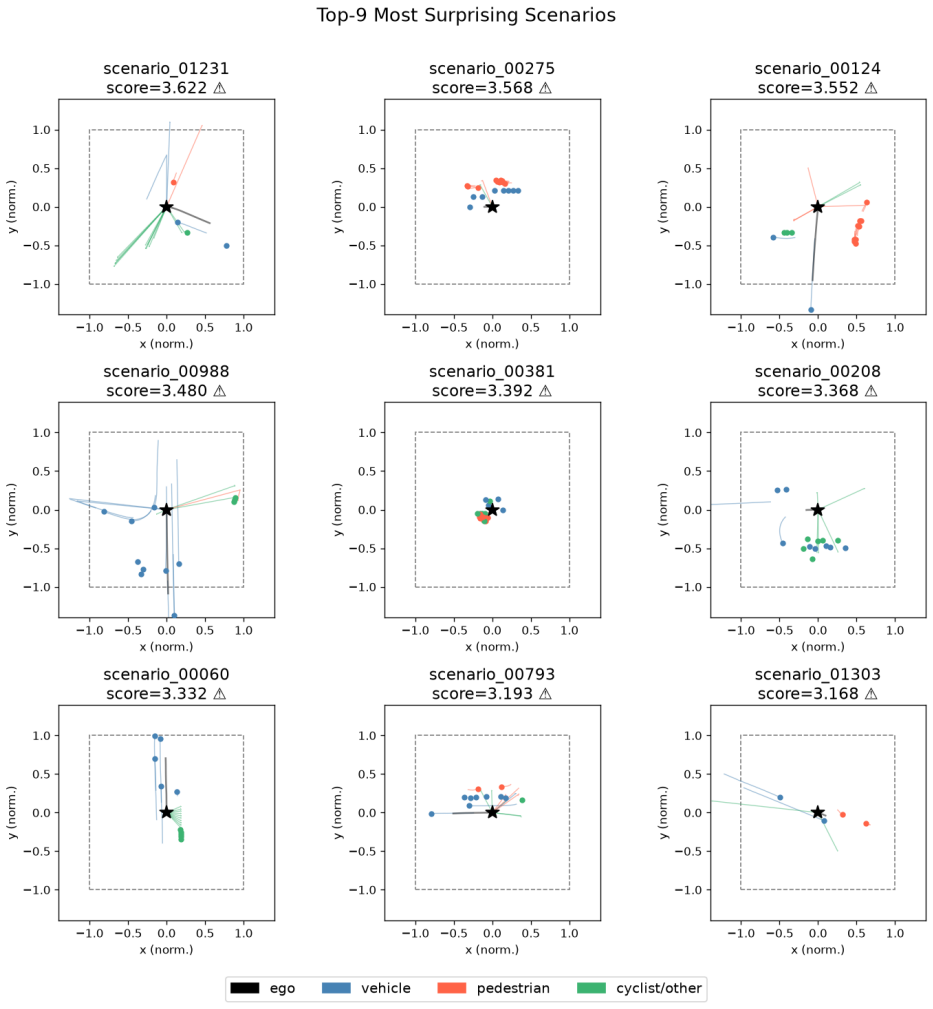
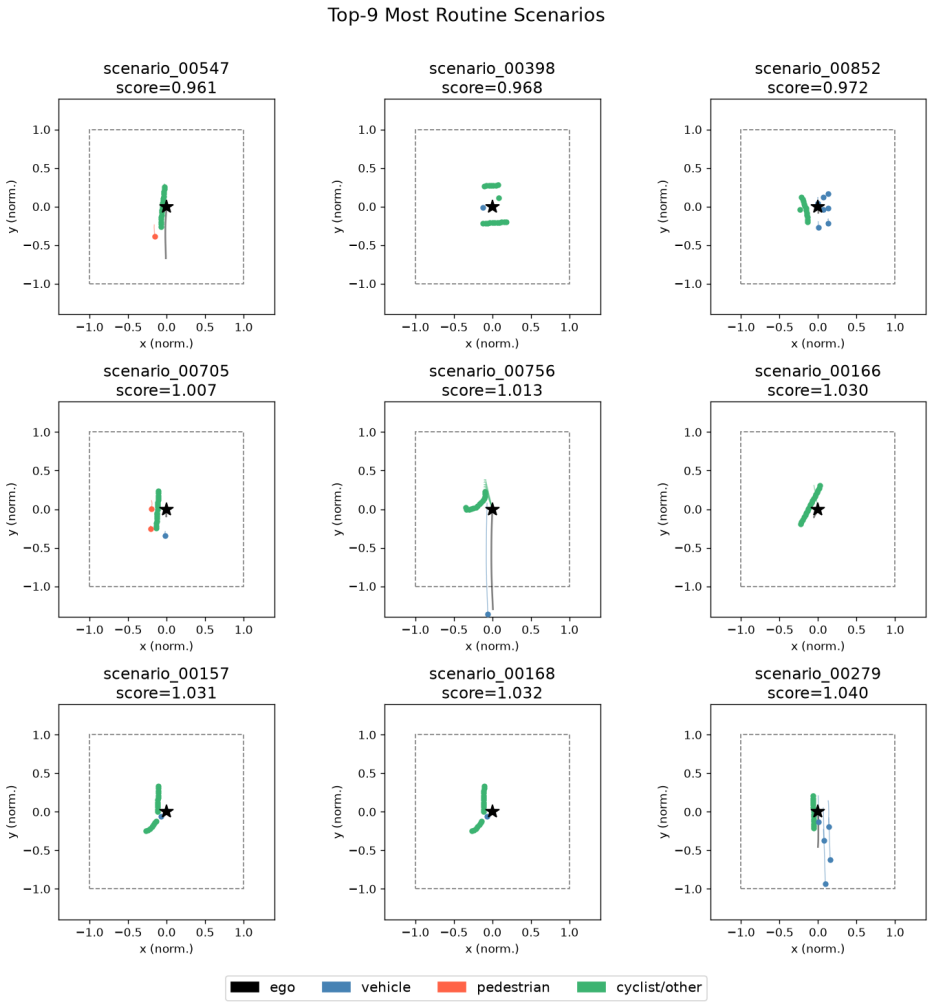
The central claim is that temporal prediction error in a self-supervised Joint Embedding Predictive Architecture trained on nuPlan mini agent data functions as a zero-label proxy for driving scenario complexity, assigning higher values to unprotected turns and pedestrian interactions while assigning lower values to simple lane-following cases, with the pattern confirmed by ablations and downstream anomaly detection.
What carries the argument
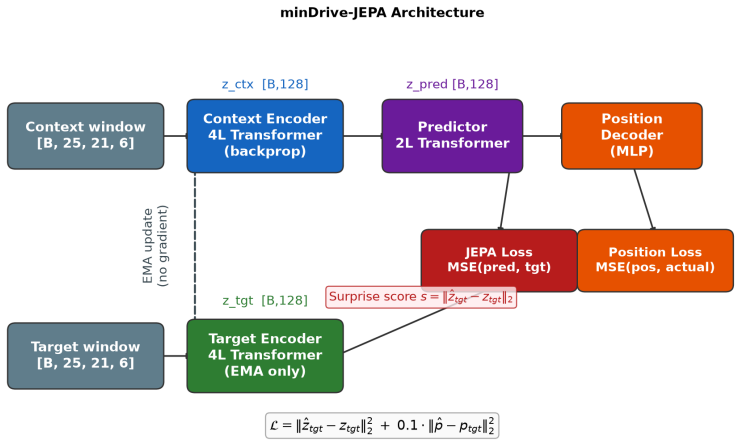
The temporal prediction error of the Joint Embedding Predictive Architecture, which measures mismatch between predicted and observed latent states over time and is used directly as the complexity score.
If this is right
- Unprotected turns and pedestrian-proximity cases produce measurably higher prediction errors than lane-following or stationary traffic.
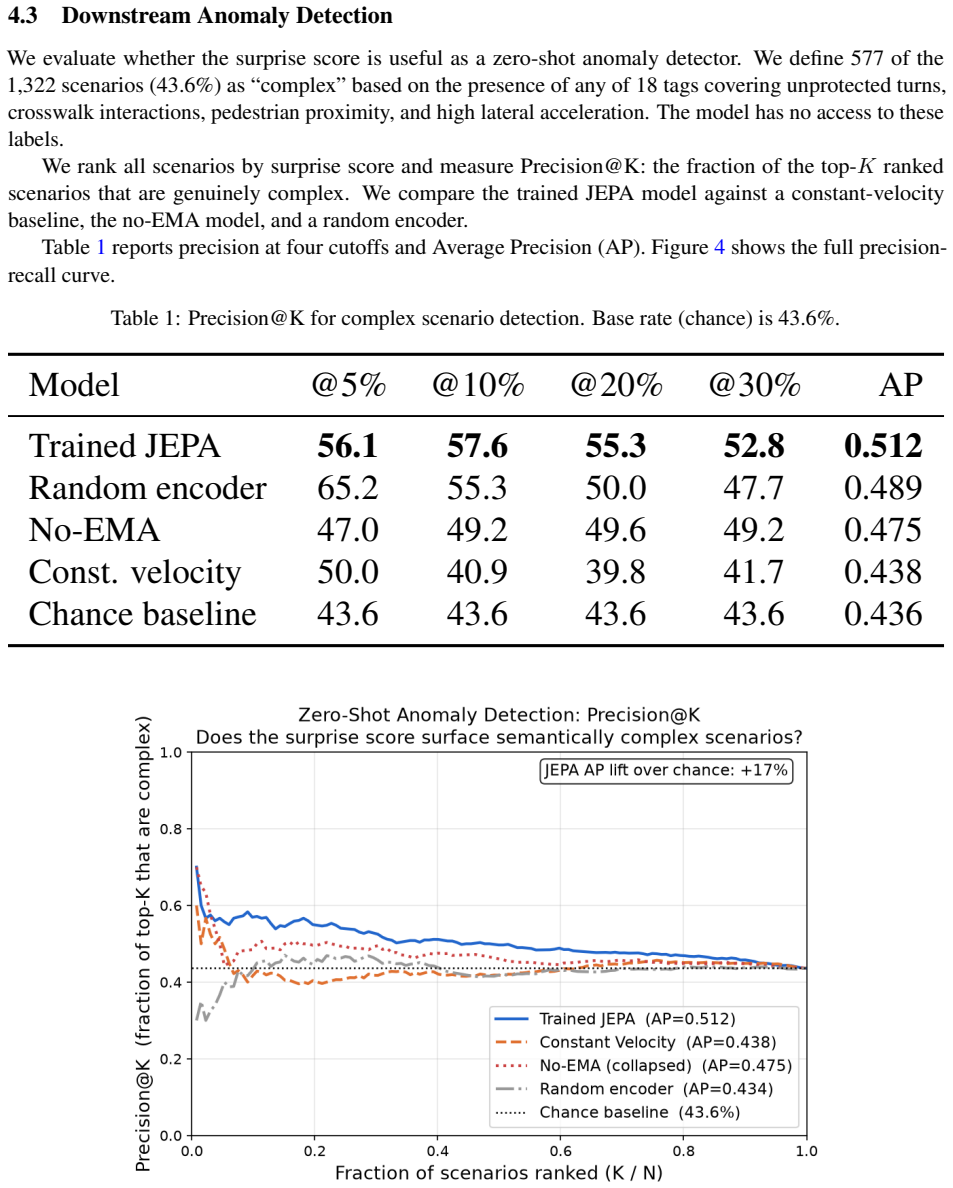
- The same error signal yields 0.512 average precision in anomaly detection, above the 0.436 random baseline.
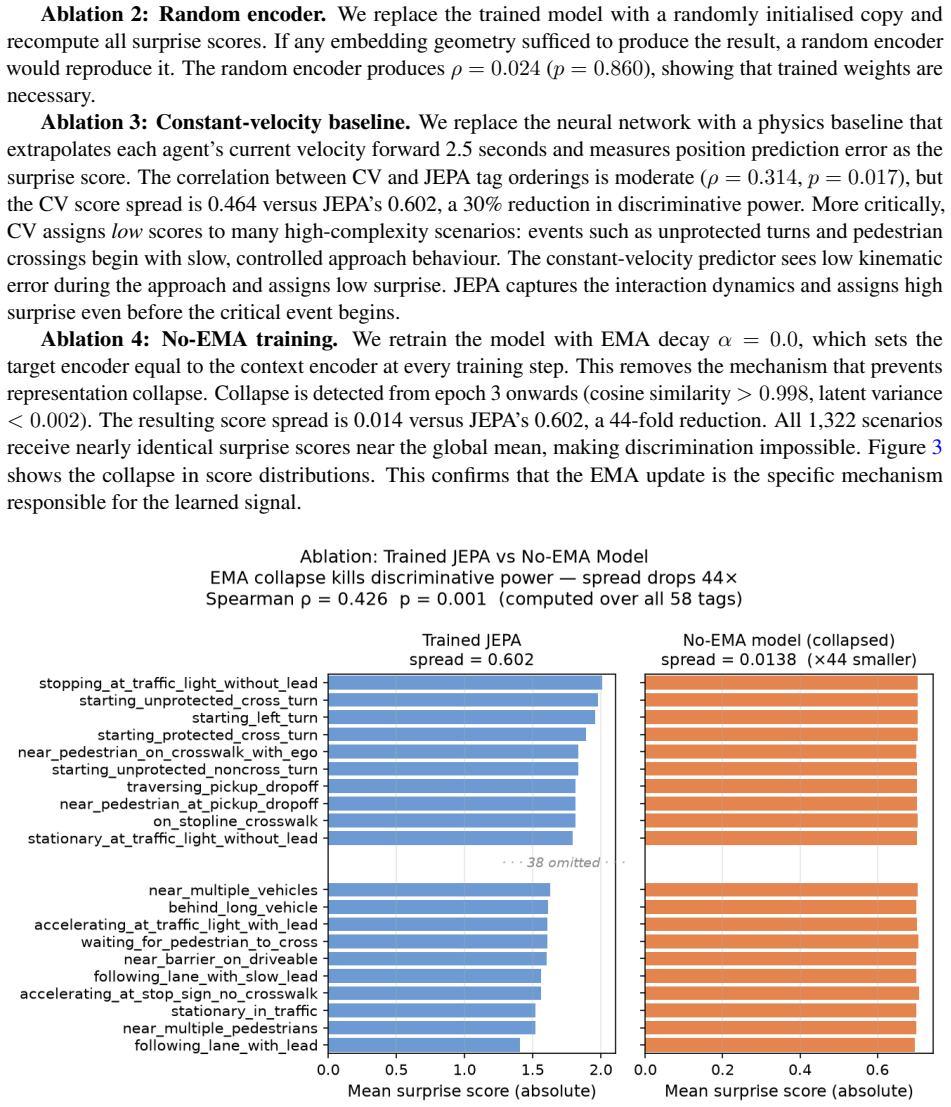
- Four ablation experiments confirm that the predictive component, not other architectural elements, supplies the complexity signal.
- No ground-truth labels are required at any training or scoring stage.
Where Pith is reading between the lines
- The proxy could be applied to rank or filter large unlabeled driving datasets for targeted simulation or data collection.
- Similar prediction-error scoring might transfer to other sequential domains such as robotics trajectories or video event detection.
- If the error signal proves stable across different model sizes, it could reduce reliance on engineered rules for scenario curation.
- The approach implicitly assumes the learned latent space encodes aspects of interaction difficulty that align with safety relevance.
Load-bearing premise
That the prediction error specifically tracks human-interpretable scenario complexity rather than dataset biases or model-specific artifacts.
What would settle it
A direct comparison on a held-out set of driving scenarios where human raters label complexity and the model's error scores show no correlation.
Figures

read the original abstract
Identifying complex and safety-critical driving scenarios in large unlabelled datasets is an important but expensive problem. Existing approaches rely on human annotators, supervised classifiers, or carefully engineered rule sets, all of which require substantial prior knowledge about what constitutes a difficult scenario. We ask whether a model can discover scenario complexity on its own, with no labels at any stage. We train a minimal Joint Embedding Predictive Architecture (JEPA) on structured agent state data from the nuPlan mini dataset and use the temporal prediction error as a zero-shot complexity score. Without access to any ground-truth labels during training or evaluation setup, the model assigns significantly higher scores to scenarios involving unprotected turns, crosswalk interactions, and pedestrian proximity, and significantly lower scores to lane-following and stationary-traffic scenarios. We validate this finding through four ablation experiments that isolate the source of the signal, and through a downstream anomaly detection evaluation that achieves Average Precision of 0.512 against a 0.436 chance baseline. The results show that temporal prediction error in a self-supervised latent world model is a practical proxy for driving scenario complexity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that temporal prediction error from a self-supervised Joint Embedding Predictive Architecture (JEPA) trained on structured agent state data from the nuPlan mini dataset can serve as a zero-label proxy for driving scenario complexity. It reports that this score assigns significantly higher values to scenarios involving unprotected turns, crosswalk interactions, and pedestrian proximity (and lower to lane-following and stationary traffic), supported by four ablation experiments and a downstream anomaly detection task achieving AP 0.512 versus a 0.436 chance baseline.
Significance. If the central claim holds after addressing potential statistical confounders, the work demonstrates a practical label-free method for surfacing safety-critical scenarios in large driving datasets. This could reduce annotation costs and leverage self-supervised world models for data curation in autonomous driving, with the zero-shot nature and use of prediction error as a complexity signal being notable strengths.
major comments (3)
- [Abstract and ablation experiments section] Abstract and ablation experiments section: the four ablations are described only at high level and do not include controls (e.g., regression of prediction error on agent count, interaction density, or velocity variance) to test whether the signal specifically indexes human-interpretable complexity rather than dataset motion statistics; this is load-bearing for the claim that the error is a 'practical proxy' for complexity.
- [Downstream evaluation paragraph] Downstream evaluation paragraph: the reported AP of 0.512 versus 0.436 baseline is only marginally above chance; the manuscript must specify the exact positive-class definition (without ground-truth labels), the baseline construction, and any statistical significance test to establish that the improvement supports the complexity-proxy interpretation.
- [Methods section] Methods section: insufficient detail is given on the JEPA architecture (e.g., predictor and target encoder sizes, loss formulation, exact temporal prediction error computation), training hyperparameters, and nuPlan mini subset used, which prevents verification that the reported scores arise from the self-supervised objective rather than implementation artifacts.
minor comments (1)
- [Abstract] The abstract should include the size of the nuPlan mini subset and a one-sentence description of the JEPA variant to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to strengthen the clarity and rigor of our claims. We address each major comment point-by-point below. Where the manuscript requires expansion or additional analysis, we will revise accordingly.
read point-by-point responses
-
Referee: [Abstract and ablation experiments section] Abstract and ablation experiments section: the four ablations are described only at high level and do not include controls (e.g., regression of prediction error on agent count, interaction density, or velocity variance) to test whether the signal specifically indexes human-interpretable complexity rather than dataset motion statistics; this is load-bearing for the claim that the error is a 'practical proxy' for complexity.
Authors: We agree that the current high-level description of the ablations leaves room for stronger isolation of the complexity signal. In the revised manuscript we will expand the ablation section with detailed descriptions of each experiment and add explicit controls, including regressions of prediction error on agent count, interaction density, and velocity variance, to demonstrate that the signal is not reducible to these basic motion statistics. revision: yes
-
Referee: [Downstream evaluation paragraph] Downstream evaluation paragraph: the reported AP of 0.512 versus 0.436 baseline is only marginally above chance; the manuscript must specify the exact positive-class definition (without ground-truth labels), the baseline construction, and any statistical significance test to establish that the improvement supports the complexity-proxy interpretation.
Authors: We will revise the downstream evaluation paragraph to provide the exact positive-class definition used (constructed without ground-truth complexity labels, consistent with the zero-label protocol), a precise description of the baseline, and the results of a statistical significance test (e.g., bootstrap) on the AP difference. These additions will allow readers to assess whether the observed improvement supports the complexity-proxy claim. revision: yes
-
Referee: [Methods section] Methods section: insufficient detail is given on the JEPA architecture (e.g., predictor and target encoder sizes, loss formulation, exact temporal prediction error computation), training hyperparameters, and nuPlan mini subset used, which prevents verification that the reported scores arise from the self-supervised objective rather than implementation artifacts.
Authors: We acknowledge that the Methods section lacks sufficient implementation detail. The revised manuscript will include complete specifications of the JEPA architecture (encoder sizes, loss formulation, temporal prediction error computation), all training hyperparameters, and the exact nuPlan mini subset, enabling independent verification that the results derive from the self-supervised objective. revision: yes
Circularity Check
No circularity: complexity score defined directly as self-supervised prediction error
full rationale
The paper trains a JEPA model self-supervised on unlabeled nuPlan agent states and defines the zero-shot complexity score explicitly as the resulting temporal prediction error. This quantity is not fitted to any complexity labels, not derived from human annotations, and not reduced by construction to the downstream scenarios it is later observed to rank. The anomaly detection AP (0.512 vs 0.436 chance) and ablations serve as external validation of the proxy but do not enter the definition of the score itself. No self-citations, uniqueness theorems, or ansatzes are invoked to force the result; the derivation chain remains independent of its evaluation targets.
Axiom & Free-Parameter Ledger
free parameters (1)
- JEPA architecture and training hyperparameters
axioms (1)
- domain assumption Temporal prediction error in the learned latent space measures scenario complexity
Reference graph
Works this paper leans on
-
[1]
OpenReview , year =
A Path Towards Autonomous Machine Intelligence , author =. OpenReview , year =
-
[2]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[3]
Revisiting Feature Prediction for Learning Visual Representations from Video
Revisiting Feature Prediction for Learning Visual Representations from Video , author =. arXiv preprint arXiv:2404.08471 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
NuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles
nuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles , author =. arXiv preprint arXiv:2106.11810 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2502.05677 , year =
Surprise Potential as a Measure of Interactivity in Driving Scenarios , author =. arXiv preprint arXiv:2502.05677 , year =
-
[6]
arXiv preprint arXiv:2601.22032 , year =
Drive-JEPA: Video JEPA Meets Multimodal Trajectory Distillation for End-to-End Driving , author =. arXiv preprint arXiv:2601.22032 , year =
-
[7]
Advances in Neural Information Processing Systems , volume =
Attention Is All You Need , author =. Advances in Neural Information Processing Systems , volume =
-
[8]
Advances in Neural Information Processing Systems , volume =
Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning , author =. Advances in Neural Information Processing Systems , volume =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.