Vision-Assisted Foundation Model for Solving Multi-Task Vehicle Routing Problems
Pith reviewed 2026-06-27 14:13 UTC · model grok-4.3
The pith
A vision-assisted foundation model encodes routing constraints as images to solve multiple vehicle routing variants simultaneously.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
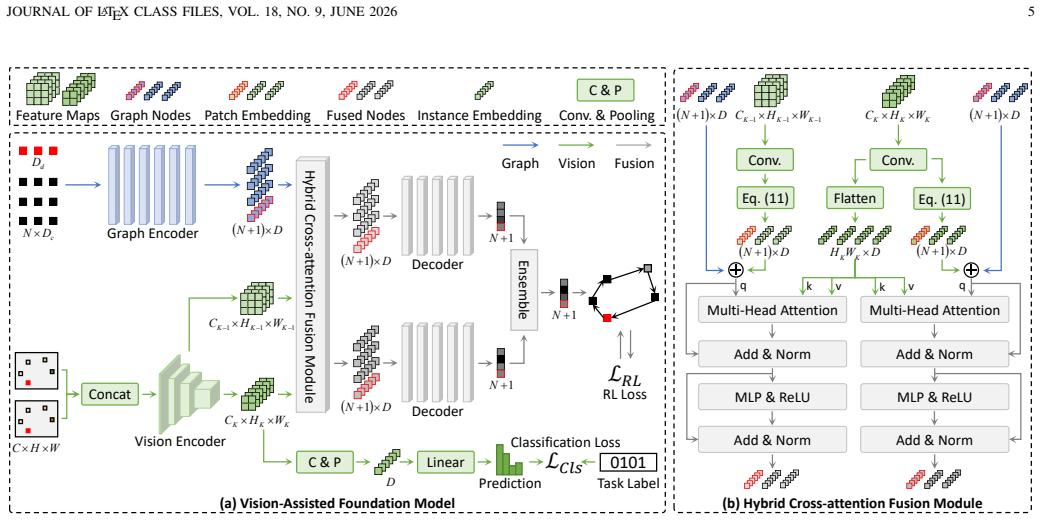
The authors claim that tailoring input images to represent all constraints, encoding them via CNN to obtain patch embeddings, fusing these with graph nodes, and applying an auxiliary task for pixel imbalance allows a single model to generate solutions for various VRP variants more effectively than graph-only solvers.
What carries the argument
The fusion of patch embeddings from CNN-encoded tailored constraint images with graph-based nodes, aided by an auxiliary task to mitigate pixel imbalance.
If this is right
- Multi-task VRPs with diverse constraints can be solved by one model instead of multiple specialized ones.
- Vision modality helps represent complex semantics that graphs miss.
- Performance gains are larger for variants with complex constraints.
- The approach addresses three specific challenges in applying vision to VRPs.
- Evaluation covers 16 different VRP variants.
Where Pith is reading between the lines
- This could allow routing systems to adapt to new constraint types by adding image representations rather than redesigning graphs.
- Similar vision-graph fusion might apply to other optimization problems like scheduling or network design.
- Reducing reliance on fixed graph structures could make solvers more flexible for real-world logistics with varying rules.
- Testing on larger scales or dynamic environments would check if the benefits hold beyond the 16-variant set.
Load-bearing premise
That tailored images for constraints, when processed by CNN into patches and fused with graphs, will effectively capture and balance the necessary constraint information that pure graph models miss.
What would settle it
A benchmark run on the 16 VRP variants where the vision-assisted model shows no superiority over state-of-the-art graph-based methods, especially on complex constraint variants.
Figures



read the original abstract
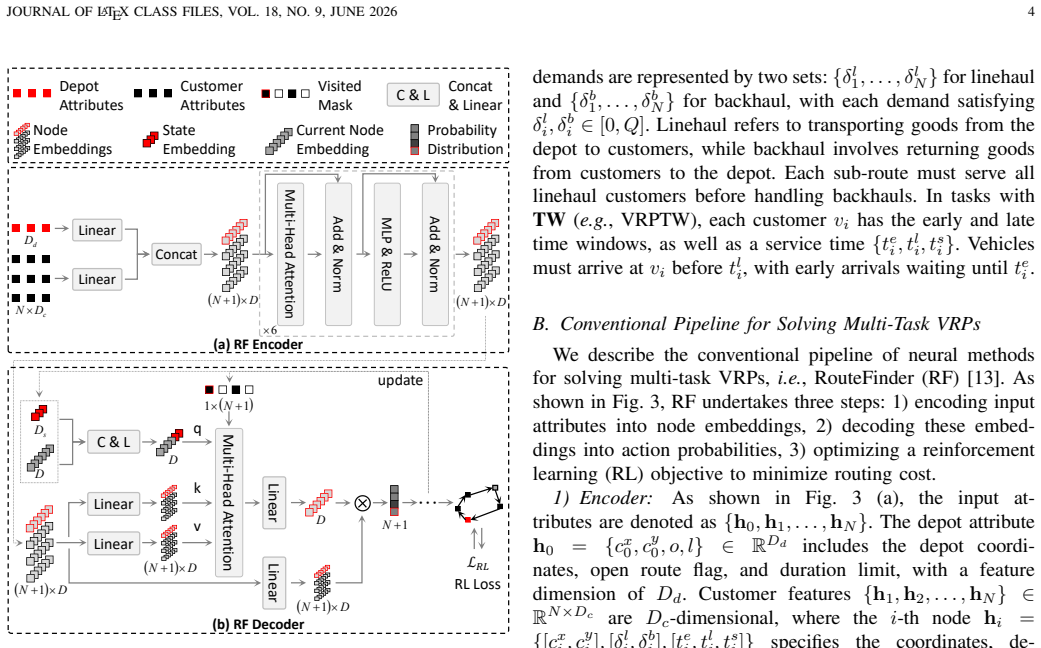
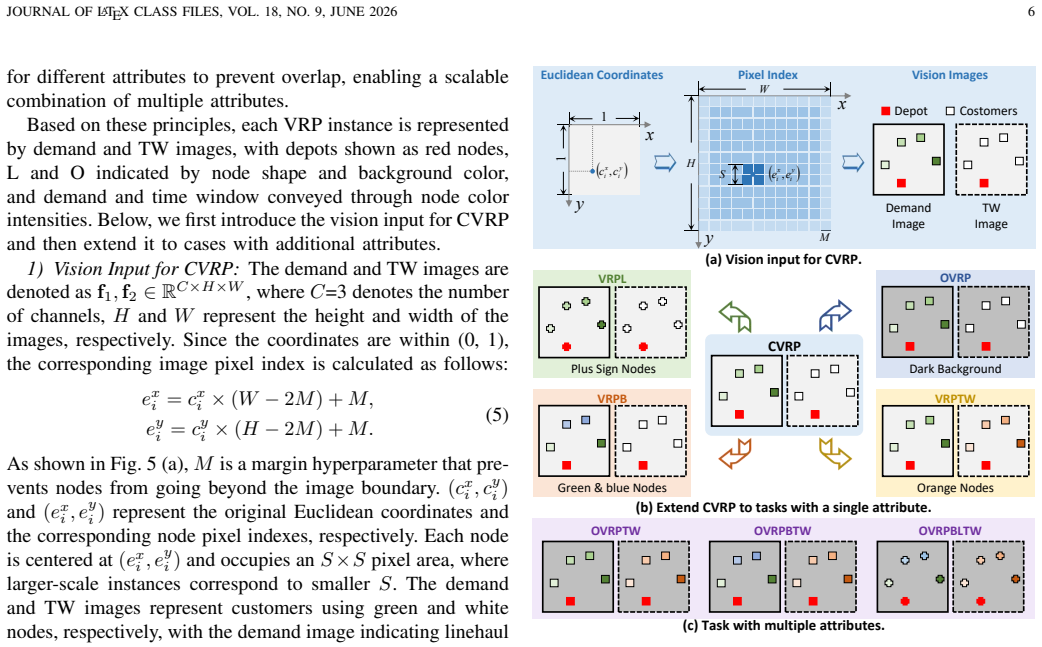
Multi-task vehicle routing problems play a critical role in enhancing efficiency across various industries and service sectors. These problems consist of multiple variants that optimize routing costs while meeting diverse customer constraints. Existing multi-task VRP solvers solely utilize a graph-based modality, limiting their ability to address variants with multiple constraints. As a format to represent complex semantics, vision modality shows great potential for encoding diverse VRP constraints. This motivates us to learn patch-level semantics from the vision images, and then integrate them into a graph-based model to solve various VRP variants simultaneously. However, directly applying this approach to multi-task VRPs presents three challenges: 1) existing VRP images lack constraint representations, which are essential for multi-task VRPs, 2) the fixed receptive field of individual patches cannot effectively accommodate varying requirements across tasks, and 3) imbalanced pixel distribution among constraints may cause the model to overlook constraints with fewer pixels. In this paper, we propose a vision-assisted foundation model (VaFM) to address these challenges. In the vision modality, input images tailored to all constraints are encoded by a convolutional neural network. The obtained patch embeddings are fused with graph-based nodes to generate solutions, with an auxiliary task designed to address the pixel-imbalanced issue. The performance of VaFM is evaluated across 16 different VRP variants. The experimental results demonstrate the superiority of VaFM over state-of-the-art methods, especially for variants with complex constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VaFM, a vision-assisted foundation model for multi-task vehicle routing problems (VRPs). It encodes tailored constraint-specific images via CNN to produce patch embeddings, fuses them with graph nodes to generate solutions, and uses an auxiliary task to mitigate pixel imbalance. The central claim is that this multi-modal approach outperforms state-of-the-art graph-only solvers across 16 VRP variants, with particular gains on instances involving complex constraints.
Significance. If the reported gains hold under rigorous controls, the work would be significant for combinatorial optimization: it supplies a reproducible mechanism (constraint-tailored image generation, CNN patch encoding, node fusion, and auxiliary loss) that directly targets the three stated limitations of graph-only multi-task VRP solvers. The experimental scope (16 variants) and emphasis on complex-constraint cases provide a concrete test bed for multi-modal extensions in routing problems.
major comments (2)
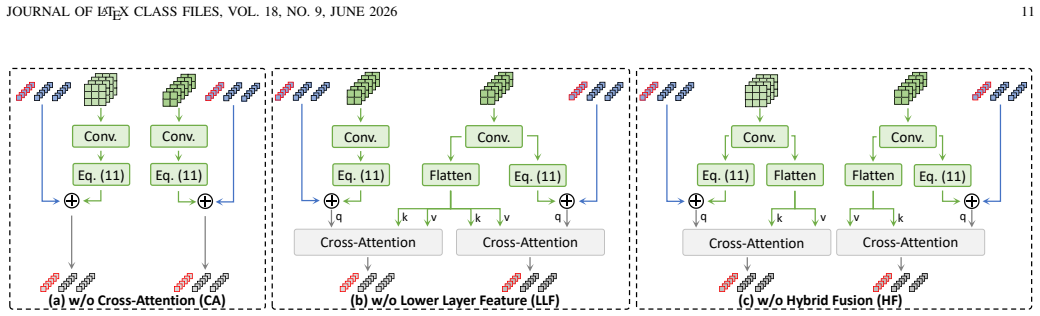
- [§4.3, Table 2] §4.3 and Table 2: the superiority claim for complex-constraint variants rests on the fusion step; the manuscript should report an ablation that isolates the contribution of the vision branch versus a pure graph baseline with identical auxiliary loss, to confirm the fusion is load-bearing rather than incidental.
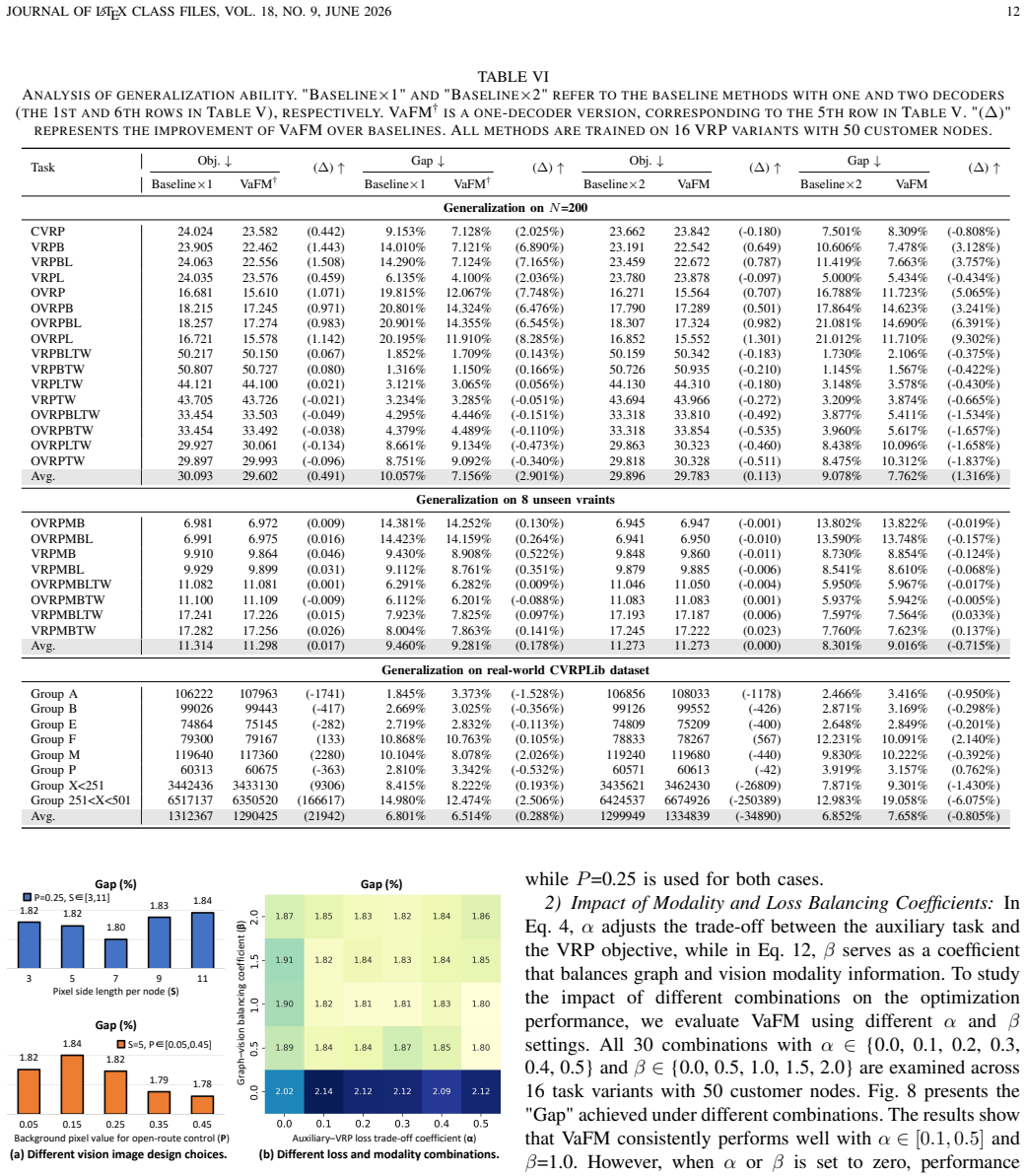
- [§5.2, Eq. (8)] §5.2, Eq. (8): the auxiliary loss weighting hyper-parameter is introduced to address pixel imbalance, yet no sensitivity analysis across the 16 variants is provided; if the weighting is task-specific, the multi-task foundation-model claim requires explicit justification that a single set of weights generalizes.
minor comments (3)
- [Figure 3] Figure 3 caption: the legend for the three image-generation variants is missing; readers cannot map the visual examples to the textual description in §3.1 without it.
- [§6.1] §6.1: the baseline implementations are referenced only by citation; a short paragraph confirming that all baselines were re-run with the authors' code and identical random seeds would strengthen reproducibility.
- [§3.2] Notation in §3.2: the symbol for fused node features is introduced without an explicit equation; adding a one-line definition would improve clarity for readers unfamiliar with the graph-vision fusion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We address each major comment below and will update the manuscript accordingly to strengthen the claims regarding the vision branch contribution and the auxiliary loss weighting.
read point-by-point responses
-
Referee: [§4.3, Table 2] §4.3 and Table 2: the superiority claim for complex-constraint variants rests on the fusion step; the manuscript should report an ablation that isolates the contribution of the vision branch versus a pure graph baseline with identical auxiliary loss, to confirm the fusion is load-bearing rather than incidental.
Authors: We agree that an explicit ablation isolating the vision branch is necessary to substantiate that the reported gains on complex-constraint variants arise from the multi-modal fusion rather than from the auxiliary loss alone. In the revised version we will add a controlled comparison of VaFM against a pure graph baseline that uses the identical auxiliary loss formulation and training protocol. The new results will be inserted into §4.3 and Table 2 (or a supplementary table) to quantify the incremental benefit of the patch-embedding fusion step. revision: yes
-
Referee: [§5.2, Eq. (8)] §5.2, Eq. (8): the auxiliary loss weighting hyper-parameter is introduced to address pixel imbalance, yet no sensitivity analysis across the 16 variants is provided; if the weighting is task-specific, the multi-task foundation-model claim requires explicit justification that a single set of weights generalizes.
Authors: We acknowledge that a sensitivity study on the auxiliary-loss weight would further support the multi-task foundation-model claim. Although a single fixed weight was selected after preliminary tuning on a representative subset of variants and then held constant across all 16 tasks, we will include in the revision a sensitivity plot (new figure in §5.2) showing performance variation for a range of weights on both simple and complex-constraint instances. This analysis will explicitly justify why the chosen weight generalizes without requiring per-task retuning. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces VaFM as a new architecture that encodes tailored constraint images via CNN, fuses patch embeddings with graph nodes, and adds an auxiliary task for pixel imbalance, then validates superiority empirically across 16 VRP variants. No derivation chain, equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described full text. The claims rest on reproducible experimental mechanisms rather than reducing to inputs by construction, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Toth and D
P. Toth and D. Vigo,Vehicle routing: problems, methods, and applica- tions. SIAM, 2014
2014
-
[2]
An efficient graph convo- lutional network technique for the travelling salesman problem,
C. K. Joshi, T. Laurent, and X. Bresson, “An efficient graph convo- lutional network technique for the travelling salesman problem,”arXiv preprint arXiv:1906.01227, 2019
arXiv 1906
-
[3]
Attention, learn to solve routing problems!
W. Kool, H. Van Hoof, and M. Welling, “Attention, learn to solve routing problems!”arXiv preprint arXiv:1803.08475, 2018
Pith/arXiv arXiv 2018
-
[4]
Pomo: Policy optimization with multiple optima for reinforcement learning,
Y .-D. Kwon, J. Choo, B. Kim, I. Yoon, Y . Gwon, and S. Min, “Pomo: Policy optimization with multiple optima for reinforcement learning,”Advances in Neural Information Processing Systems, vol. 33, pp. 21 188–21 198, 2020
2020
-
[5]
Learning improvement heuristics for solving routing problems,
Y . Wu, W. Song, Z. Cao, J. Zhang, and A. Lim, “Learning improvement heuristics for solving routing problems,”IEEE Transactions on Neural Networks and Learning Systems, vol. 33, no. 9, pp. 5057–5069, 2021
2021
-
[6]
Learning to search feasible and infeasible regions of routing problems with flexible neural k-opt,
Y . Ma, Z. Cao, and Y . M. Chee, “Learning to search feasible and infeasible regions of routing problems with flexible neural k-opt,” Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[7]
Difusco: Graph-based diffusion solvers for combinatorial optimization,
Z. Sun and Y . Yang, “Difusco: Graph-based diffusion solvers for combinatorial optimization,”Advances in Neural Information Processing Systems, vol. 36, pp. 3706–3731, 2023
2023
-
[8]
Neural combinatorial optimization with heavy decoder: Toward large scale generalization,
F. Luo, X. Lin, F. Liu, Q. Zhang, and Z. Wang, “Neural combinatorial optimization with heavy decoder: Toward large scale generalization,” Advances in Neural Information Processing Systems, vol. 36, pp. 8845– 8864, 2023
2023
-
[9]
A concise guide to existing and emerging vehicle routing problem variants,
T. Vidal, G. Laporte, and P. Matl, “A concise guide to existing and emerging vehicle routing problem variants,”European Journal of Oper- ational Research, vol. 286, no. 2, pp. 401–416, 2020
2020
-
[10]
The vehicle routing problem: State of the art classification and review,
K. Braekers, K. Ramaekers, and I. Van Nieuwenhuyse, “The vehicle routing problem: State of the art classification and review,”Computers & Industrial Engineering, vol. 99, pp. 300–313, 2016
2016
-
[11]
An overview and experimental study of learning-based optimization algorithms for the vehicle routing problem,
B. Li, G. Wu, Y . He, M. Fan, and W. Pedrycz, “An overview and experimental study of learning-based optimization algorithms for the vehicle routing problem,”IEEE/CAA Journal of Automatica Sinica, vol. 9, no. 7, pp. 1115–1138, 2022
2022
-
[12]
Multi-task learning for routing problem with cross-problem zero-shot generalization,
F. Liu, X. Lin, Z. Wang, Q. Zhang, T. Xialiang, and M. Yuan, “Multi-task learning for routing problem with cross-problem zero-shot generalization,” inProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 1898–1908
2024
-
[13]
RouteFinder: Towards foundation models for vehicle routing problems,
F. Berto, C. Hua, N. G. Zepeda, A. Hottung, N. Wouda, L. Lan, K. Tierney, and J. Park, “RouteFinder: Towards foundation models for vehicle routing problems,” inICML 2024 Workshop on Foundation Models in the Wild (Oral), 2024. [Online]. Available: https://openreview.net/forum?id=hCiaiZ6e4G
2024
-
[14]
Image enhancement guided object detection in visually degraded scenes,
H. Liu, F. Jin, H. Zeng, H. Pu, and B. Fan, “Image enhancement guided object detection in visually degraded scenes,”IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 10, pp. 14 164– 14 177, 2024
2024
-
[15]
A survey and evaluation of adversarial attacks in object de- tection,
K. N. T. Nguyen, W. Zhang, K. Lu, Y .-H. Wu, X. Zheng, H. Li Tan, and L. Zhen, “A survey and evaluation of adversarial attacks in object de- tection,”IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 9, pp. 15 706–15 722, 2025
2025
-
[16]
Continuation multiple instance learning for weakly and fully supervised object detection,
Q. Ye, F. Wan, C. Liu, Q. Huang, and X. Ji, “Continuation multiple instance learning for weakly and fully supervised object detection,”IEEE Transactions on Neural Networks and Learning Systems, vol. 33, no. 10, pp. 5452–5466, 2021
2021
-
[17]
Contrastive registra- tion for unsupervised medical image segmentation,
L. Liu, A. I. Aviles-Rivero, and C.-B. Schönlieb, “Contrastive registra- tion for unsupervised medical image segmentation,”IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 1, pp. 147–159, 2025
2025
-
[18]
Swinpa-net: Swin transformer-based multiscale feature pyramid aggregation network for medical image segmentation,
H. Du, J. Wang, M. Liu, Y . Wang, and E. Meijering, “Swinpa-net: Swin transformer-based multiscale feature pyramid aggregation network for medical image segmentation,”IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 4, pp. 5355–5366, 2022
2022
-
[19]
One-click-based perception for interactive image segmentation,
T. Wang, H. Li, Y . Zheng, and Q. Sun, “One-click-based perception for interactive image segmentation,”IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 10, pp. 13 975–13 989, 2024
2024
-
[20]
Solving optimization problems through fully convolutional networks: An application to the traveling salesman problem,
Z. Ling, X. Tao, Y . Zhang, and X. Chen, “Solving optimization problems through fully convolutional networks: An application to the traveling salesman problem,”IEEE Transactions on Systems, Man, and Cyber- netics: Systems, vol. 51, no. 12, pp. 7475–7485, 2020
2020
-
[21]
A deep reinforcement learning based real-time solution policy for the traveling salesman problem,
Z. Ling, Y . Zhang, and X. Chen, “A deep reinforcement learning based real-time solution policy for the traveling salesman problem,”IEEE Transactions on Intelligent Transportation Systems, vol. 24, no. 6, pp. 5871–5882, 2023
2023
-
[22]
Diffusion models as plug-and-play priors,
A. Graikos, N. Malkin, N. Jojic, and D. Samaras, “Diffusion models as plug-and-play priors,”Advances in Neural Information Processing Systems, vol. 35, pp. 14 715–14 728, 2022
2022
-
[23]
Vn-solver: Vision-based neural solver for combinatorial optimization over graphs,
M. Samizadeh and G. Tong, “Vn-solver: Vision-based neural solver for combinatorial optimization over graphs,” inProceedings of the 32nd ACM International Conference on Information and Knowledge Management, 2023, pp. 4269–4273
2023
-
[24]
Reinforcement learning for solving the vehicle routing problem,
M. Nazari, A. Oroojlooy, L. Snyder, and M. Takác, “Reinforcement learning for solving the vehicle routing problem,”Advances in Neural Information Processing Systems, vol. 31, 2018
2018
-
[25]
Pointer networks,
O. Vinyals, M. Fortunato, and N. Jaitly, “Pointer networks,”Advances in Neural Information Processing Systems, vol. 28, 2015
2015
-
[26]
Simple statistical gradient-following algorithms for connectionist reinforcement learning,
R. J. Williams, “Simple statistical gradient-following algorithms for connectionist reinforcement learning,”Machine Learning, vol. 8, pp. 229–256, 1992
1992
-
[27]
Distance-aware attention reshaping for enhancing generalization of neural solvers,
Y . Wang, Y .-H. Jia, W.-N. Chen, and Y . Mei, “Distance-aware attention reshaping for enhancing generalization of neural solvers,”IEEE Trans- actions on Neural Networks and Learning Systems, vol. 36, no. 10, pp. 18 900–18 914, 2025
2025
-
[28]
Mapdp: Cooperative multi- agent reinforcement learning to solve pickup and delivery problems,
Z. Zong, M. Zheng, Y . Li, and D. Jin, “Mapdp: Cooperative multi- agent reinforcement learning to solve pickup and delivery problems,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 9, 2022, pp. 9980–9988
2022
-
[29]
Efficient neural collabo- rative search for pickup and delivery problems,
D. Kong, Y . Ma, Z. Cao, T. Yu, and J. Xiao, “Efficient neural collabo- rative search for pickup and delivery problems,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 12, pp. 11 019– 11 034, 2024
2024
-
[30]
Constructing selection hyper-heuristics for open vehicle routing with time delay neural networks using multiple experts,
R. Tyasnurita, E. Özcan, J. H. Drake, and S. Asta, “Constructing selection hyper-heuristics for open vehicle routing with time delay neural networks using multiple experts,”Knowledge-Based Systems, vol. 295, p. 111731, 2024
2024
-
[31]
A general vns for the multi-depot open vehicle routing problem with time windows,
S. N. Bezerra, S. R. de Souza, and M. J. F. Souza, “A general vns for the multi-depot open vehicle routing problem with time windows,” Optimization Letters, vol. 17, no. 9, pp. 2033–2063, 2023
2033
-
[32]
Hybrid iterated local search algorithm for the vehicle routing problem with lockers,
B. Oliveira, A. Pessoa, and M. Roboredo, “Hybrid iterated local search algorithm for the vehicle routing problem with lockers,”Journal of Heuristics, vol. 31, no. 2, Apr. 2025
2025
-
[33]
Learning to solve multiple-tsp with time window and rejections via deep reinforcement learning,
R. Zhang, C. Zhang, Z. Cao, W. Song, P. S. Tan, J. Zhang, B. Wen, and J. Dauwels, “Learning to solve multiple-tsp with time window and rejections via deep reinforcement learning,”IEEE Transactions on Intelligent Transportation Systems, vol. 24, no. 1, pp. 1325–1336, 2022. JOURNAL OF LATEX CLASS FILES, VOL. 18, NO. 9, JUNE 2026 15
2022
-
[34]
Deep reinforcement learning for the electric vehicle routing problem with time windows,
B. Lin, B. Ghaddar, and J. Nathwani, “Deep reinforcement learning for the electric vehicle routing problem with time windows,”IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 8, pp. 11 528–11 538, 2021
2021
-
[35]
Cross-problem learning for solving vehicle routing problems,
Z. Lin, Y . Wu, B. Zhou, Z. Cao, W. Song, Y . Zhang, and S. Jayavelu, “Cross-problem learning for solving vehicle routing problems,” inPro- ceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, 2024, pp. 6958–6966
2024
-
[36]
MVMoE: Multi-task vehicle routing solver with mixture-of-experts,
J. Zhou, Z. Cao, Y . Wu, W. Song, Y . Ma, J. Zhang, and X. Chi, “MVMoE: Multi-task vehicle routing solver with mixture-of-experts,” in Proceedings of the 41st International Conference on Machine Learning, vol. 235. PMLR, 21–27 Jul 2024, pp. 61 804–61 824
2024
-
[37]
Routefinder: Towards foundation models for vehicle routing problems,
F. Berto, C. Hua, N. G. Zepeda, A. Hottung, N. Wouda, L. Lan, J. Park, K. Tierney, and J. Park, “Routefinder: Towards foundation models for vehicle routing problems,”Transactions on Machine Learning Research, 2025. [Online]. Available: https: //openreview.net/forum?id=QzGLoaOPiY
2025
-
[38]
Goal: A generalist com- binatorial optimization agent learner,
D. Drakuli ´c, S. Michel, and J.-M. Andreoli, “Goal: A generalist com- binatorial optimization agent learner,” inInternational Conference on Learning Representations, vol. 2025, 2025, pp. 52 465–52 488
2025
-
[39]
The development of embodied cognition: Six lessons from babies,
L. Smith and M. Gasser, “The development of embodied cognition: Six lessons from babies,”Artificial Life, vol. 11, no. 1-2, pp. 13–29, 2005
2005
-
[40]
Unsupervised learning of spoken language with visual context,
D. Harwath, A. Torralba, and J. Glass, “Unsupervised learning of spoken language with visual context,”Advances in Neural Information Processing Systems, vol. 29, 2016
2016
-
[41]
Cross-modal self-attention network for referring image segmentation,
L. Ye, M. Rochan, Z. Liu, and Y . Wang, “Cross-modal self-attention network for referring image segmentation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 10 502–10 511
2019
-
[42]
Road network representation learning with the third law of geography,
H. Zhou, W. Huang, Y . Chen, T. He, G. Cong, and Y . S. Ong, “Road network representation learning with the third law of geography,” in Advances in Neural Information Processing Systems, vol. 37. Curran Associates, Inc., 2024, pp. 11 789–11 813
2024
-
[43]
What makes multi-modal learning better than single (provably),
Y . Huang, C. Du, Z. Xue, X. Chen, H. Zhao, and L. Huang, “What makes multi-modal learning better than single (provably),”Advances in Neural Information Processing Systems, vol. 34, pp. 10 944–10 956, 2021
2021
-
[44]
Concise and effective network for 3d human modeling from orthogonal silhouettes,
B. Liu, X. Liu, Z. Yang, and C. C. Wang, “Concise and effective network for 3d human modeling from orthogonal silhouettes,”Journal of Computing and Information Science in Engineering, vol. 22, no. 5, p. 051004, 2022
2022
-
[45]
Black holes and white rabbits: Metaphor identification with visual features,
E. Shutova, D. Kiela, and J. Maillard, “Black holes and white rabbits: Metaphor identification with visual features,” inProceedings of the 2016 conference of the North American chapter of the association for computational linguistics: Human language technologies, 2016, pp. 160–170
2016
-
[46]
Neural language modeling with visual features,
A. Anastasopoulos, S. Kumar, and H. Liao, “Neural language modeling with visual features,”arXiv preprint arXiv:1903.02930, 2019
Pith/arXiv arXiv 1903
-
[47]
Mfas: Multimodal fusion architecture search,
J.-M. Pérez-Rúa, V . Vielzeuf, S. Pateux, M. Baccouche, and F. Jurie, “Mfas: Multimodal fusion architecture search,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 6966–6975
2019
-
[48]
Majority vote of diverse classifiers for late fusion,
E. Morvant, A. Habrard, and S. Ayache, “Majority vote of diverse classifiers for late fusion,” inStructural, Syntactic, and Statistical Pattern Recognition: Joint IAPR International Workshop, S+ SSPR 2014, Joensuu, Finland, August 20-22, 2014. Proceedings. Springer, 2014, pp. 153–162
2014
-
[49]
Deep multimodal fusion of image and non-image data in disease diagnosis and prognosis: a review,
C. Cui, H. Yang, Y . Wang, S. Zhao, Z. Asad, L. A. Coburn, K. T. Wilson, B. A. Landman, and Y . Huo, “Deep multimodal fusion of image and non-image data in disease diagnosis and prognosis: a review,”Progress in Biomedical Engineering, vol. 5, no. 2, p. 022001, 2023
2023
-
[50]
Goodfellow, Y
I. Goodfellow, Y . Bengio, A. Courville, and Y . Bengio,Deep learning. MIT press Cambridge, 2016, vol. 1, no. 2
2016
-
[51]
Pytorch: an imperative style, high- performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala, “Pytorch: an imperative style, high- performance deep learning library,” inAdvances in Neural Information Processing S...
2019
-
[52]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778
2016
-
[53]
Pyvrp: A high-performance vrp solver package,
“Pyvrp: A high-performance vrp solver package,”INFORMS Journal on Computing, vol. 36, no. 4, pp. 943–955, 2024
2024
-
[54]
A review of sparse expert models in deep learning,
W. Fedus, J. Dean, and B. Zoph, “A review of sparse expert models in deep learning,”arXiv preprint arXiv:2209.01667, 2022
arXiv 2022
-
[55]
Visualizing data using t-sne
L. Van der Maaten and G. Hinton, “Visualizing data using t-sne.”Journal of Machine Learning Research, vol. 9, no. 11, 2008
2008
-
[56]
Flashattention: Fast and memory-efficient exact attention with io-awareness,
T. Dao, D. Fu, S. Ermon, A. Rudra, and C. Ré, “Flashattention: Fast and memory-efficient exact attention with io-awareness,”Advances in neural information processing systems, vol. 35, pp. 16 344–16 359, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.