LLM-Powered Personalized Glycemic Assessment in Type 2 Diabetes with Wearable Sensor Data
Pith reviewed 2026-06-27 09:54 UTC · model grok-4.3
The pith
GlyLLM combines continuous glucose monitor readings with personal metadata inside a pre-trained LLM to improve forecasting and classification for type 2 diabetes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
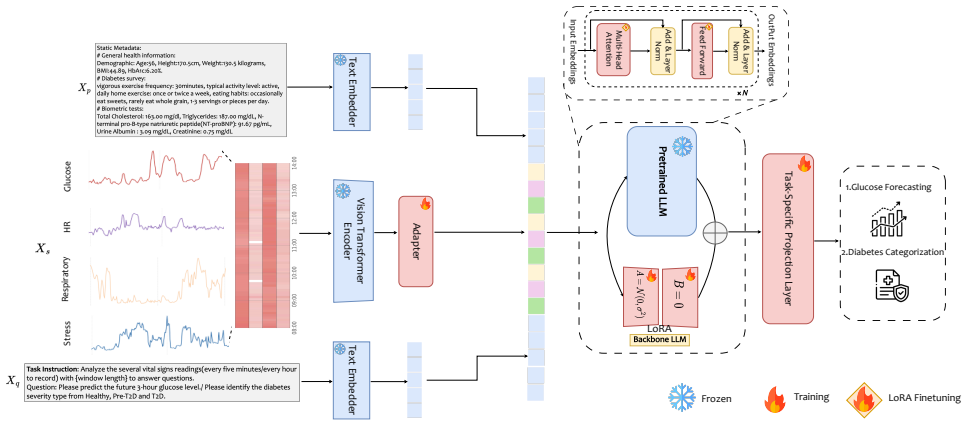
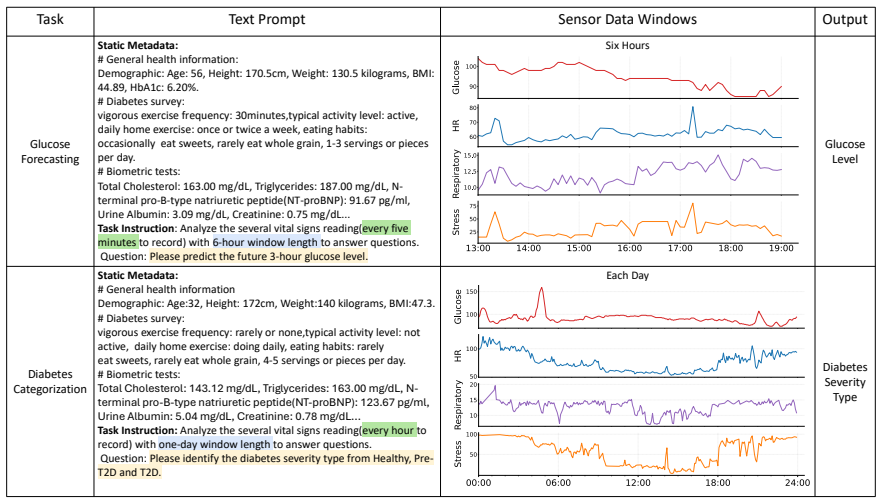
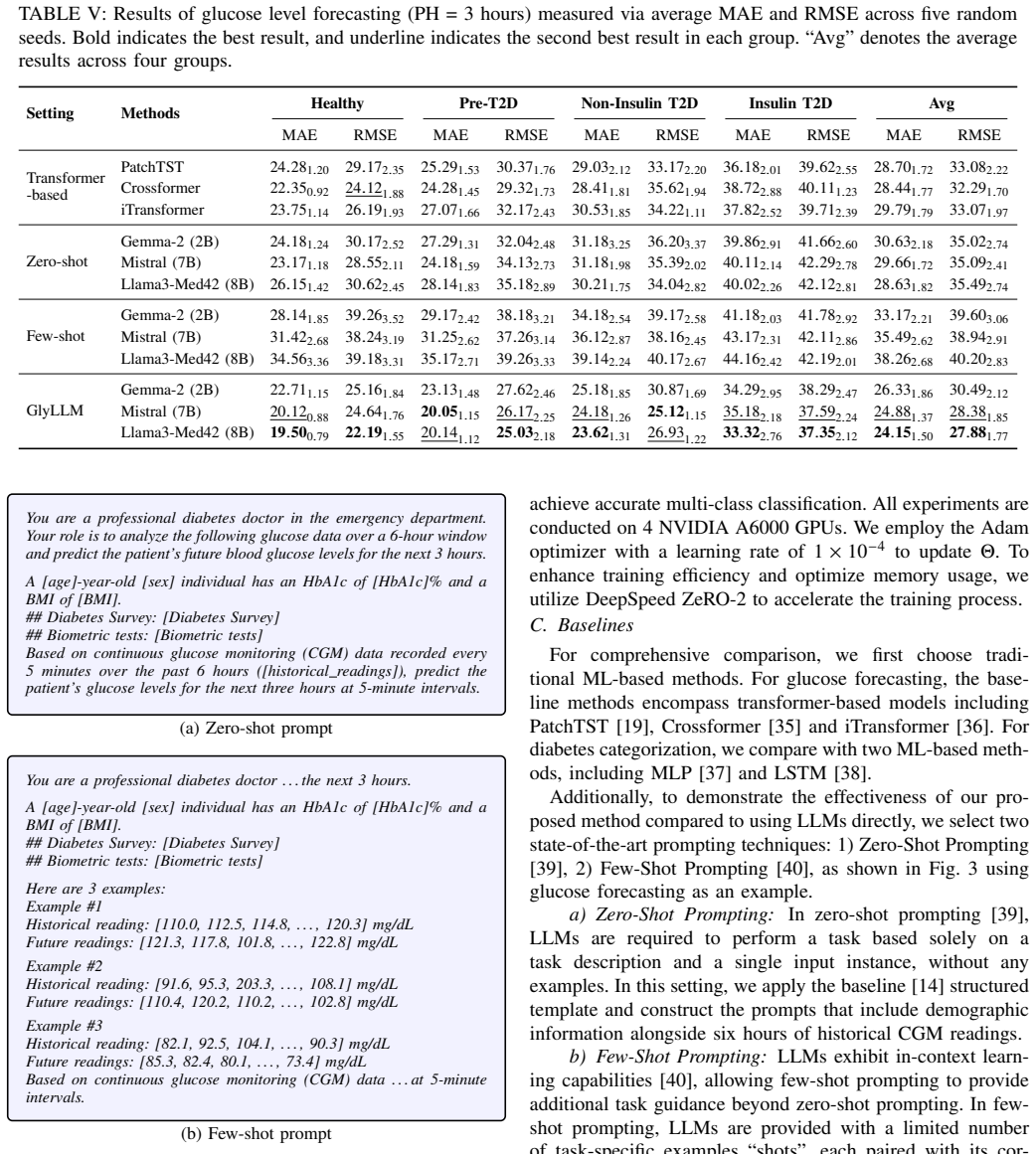
GlyLLM achieves sensor-text semantic abstraction at decision time by integrating continuous glucose monitor data with structured metadata inside a pre-trained large language model, yielding lower forecasting error and higher categorization accuracy than traditional machine-learning baselines on the AI-READI dataset.
What carries the argument
GlyLLM, an LLM-powered framework that performs sensor-text semantic abstraction using pre-trained knowledge plus provided metadata at decision time.
If this is right
- Glucose forecasting error drops by an average of 13.66 percent RMSE compared with standard machine-learning methods.
- Diabetes categorization improves by an average of 13.08 percent AUROC compared with standard machine-learning methods.
- Diabetes surveys and biometric test results contribute more to performance than other categories of health metadata.
Where Pith is reading between the lines
- The same metadata-plus-LLM pattern could be tested on other wearable-driven chronic-disease tasks such as hypertension or sleep-apnea monitoring.
- Real-time mobile applications could deliver daily glycemic guidance without collecting large amounts of patient-specific training data.
- If distribution shift proves problematic, lightweight metadata-only adapters might be added without full model retraining.
Load-bearing premise
The pre-trained LLM can reliably translate sensor readings into useful abstractions from metadata alone without task-specific fine-tuning or performance loss from patient distribution shift.
What would settle it
Performance on a held-out patient cohort drawn from a different demographic or sensor distribution falls back to or below the level of traditional ML methods.
Figures
read the original abstract
Type 2 Diabetes (T2D) poses an increasing global health threat, demanding effective glycemic assessment to support personalized and improved diabetes care. Wearable sensors such as continuous glucose monitors (CGM) and fitness trackers offer many valuable insights for glycemic assessment. However, effectively analyzing these data requires integration with essential individual-level context. Existing methods are often based on traditional machine learning (ML) and rely primarily on historical blood glucose measurements and overlook personalized information, which limits their performance across diverse diabetes populations. Recent advances in large language models (LLMs) have demonstrated their ability to integrate diverse data modalities while modeling sequential dependencies, motivating the exploration of their potential for personalized glycemic assessment. In this paper, we propose GlyLLM, an LLM-powered framework for modeling CGM-based glycemic dynamics through the integration of wearable sensor data and structured metadata. GlyLLM can leverage the extensive prior knowledge of pre-trained LLMs and achieve sensor-text semantic abstraction at decision time. Experiments on two related tasks on the AI-READI dataset demonstrate that our model outperforms traditional ML methods by an average of 13.66\% in Root Mean Squared Error (RMSE) for glucose forecasting and 13.08\% in Area Under the Receiver Operating Characteristic (AUROC) for diabetes categorization. Additionally, our ablation study shows that diabetes surveys and biometric tests are more critical than other health information for glycemic assessment. Our work presents a promising step toward harnessing the power of LLMs to advance personalized glycemic assessment in T2D care.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GlyLLM, an LLM-powered framework that integrates CGM wearable sensor data with structured metadata (including diabetes surveys and biometric tests) to model glycemic dynamics for Type 2 diabetes. It reports that GlyLLM outperforms traditional ML baselines by an average of 13.66% RMSE on glucose forecasting and 13.08% AUROC on diabetes categorization tasks using the AI-READI dataset, with an ablation study identifying surveys and biometric tests as the most critical metadata components.
Significance. If the performance margins are reproducible and attributable to the LLM component rather than data-processing choices, the work would represent a meaningful exploration of pre-trained LLMs for multimodal sensor-text integration in personalized glycemic assessment, addressing a gap in traditional ML approaches that overlook individual context.
major comments (3)
- [Abstract and §3] Abstract and §3 (Methods): no description is given of CGM time-series tokenization, input formatting for the LLM, use of in-context examples, fine-tuning procedure, or whether the LLM operates zero-shot at inference; without these details the central claim that 'sensor-text semantic abstraction at decision time' drives the reported gains cannot be evaluated.
- [§4] §4 (Experiments): the 13.66% RMSE and 13.08% AUROC margins are stated without patient-level train/test splits, baseline implementation details, statistical significance tests, or variance across runs; this prevents verification that improvements are not due to distribution shift or leakage within the AI-READI cohort.
- [§4.2] §4.2 (Ablation): the finding that 'diabetes surveys and biometric tests are more critical' is presented without quantitative ablation tables or controls for feature correlation, so it is impossible to assess whether the result is load-bearing for the personalization claim.
minor comments (2)
- [Abstract] Abstract: the phrase 'outperforms traditional ML methods by an average of 13.66%' should specify the exact set of baselines and whether the average is macro or weighted.
- [§2] Notation: 'sensor-text semantic abstraction' is used without a formal definition or pseudocode showing how metadata is concatenated with CGM sequences.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important gaps in methodological and experimental transparency. We will revise the manuscript to address each point and improve reproducibility and clarity.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Methods): no description is given of CGM time-series tokenization, input formatting for the LLM, use of in-context examples, fine-tuning procedure, or whether the LLM operates zero-shot at inference; without these details the central claim that 'sensor-text semantic abstraction at decision time' drives the reported gains cannot be evaluated.
Authors: We agree these details are required to evaluate the LLM's contribution. In the revised §3 we will add a full description of the CGM tokenization process (including how time-series values are discretized and embedded), the precise prompt/input formatting for the LLM, whether in-context examples were used, the fine-tuning procedure (or confirmation of zero-shot operation), and the inference setting. This will directly support the sensor-text abstraction claim. revision: yes
-
Referee: [§4] §4 (Experiments): the 13.66% RMSE and 13.08% AUROC margins are stated without patient-level train/test splits, baseline implementation details, statistical significance tests, or variance across runs; this prevents verification that improvements are not due to distribution shift or leakage within the AI-READI cohort.
Authors: We acknowledge that these experimental controls are necessary to rule out leakage and confirm robustness. We will update §4 to explicitly state patient-level train/test splits, provide complete baseline implementation details (hyperparameters, libraries, preprocessing), report statistical significance (e.g., paired tests with p-values), and include variance or standard deviation across multiple random seeds/runs. revision: yes
-
Referee: [§4.2] §4.2 (Ablation): the finding that 'diabetes surveys and biometric tests are more critical' is presented without quantitative ablation tables or controls for feature correlation, so it is impossible to assess whether the result is load-bearing for the personalization claim.
Authors: We agree that quantitative tables and correlation controls are needed. We will expand §4.2 with full ablation tables showing performance changes when each metadata type is removed, plus an analysis of feature correlations (e.g., correlation matrix or controlled ablations) to demonstrate that the identified components remain critical after accounting for inter-feature dependencies. revision: yes
Circularity Check
No circularity; empirical ML framework with standard evaluation
full rationale
The paper proposes GlyLLM as an LLM integration framework for CGM and metadata, then reports empirical outperformance (13.66% RMSE, 13.08% AUROC) on the AI-READI dataset. No mathematical derivation chain, equations, or first-principles results exist that reduce to inputs by construction. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text. The central claims rest on experimental results rather than any closed logical loop, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained LLMs contain transferable knowledge sufficient for sensor-text abstraction in glycemic tasks
Reference graph
Works this paper leans on
-
[1]
Global, regional, and national burden of type 2 diabetes mellitus caused by high BMI from 1990 to 2021, and forecasts to 2045: Analysis from the global burden of disease study 2021
X. Huang, Y . Wu, Y . Ni, H. Xu, and Y . He, “Global, regional, and national burden of type 2 diabetes mellitus caused by high BMI from 1990 to 2021, and forecasts to 2045: Analysis from the global burden of disease study 2021”,Frontiers in Public Health, vol. 13, 2025
1990
-
[2]
The burden and risks of emerging complications of diabetes mellitus
D. Tomic, J. E. Shaw, and D. J. Magliano, “The burden and risks of emerging complications of diabetes mellitus”,Nature Reviews Endocrinology, vol. 18, no. 9, pp. 525–539, 2022
2022
-
[3]
Economic costs of diabetes in the U.S. in 2022
E. D. Parker, J. Lin, T. Mahoney, N. Ume, G. Yang, R. A. Gabbay, N. A. ElSayed, and R. R. Bannuru, “Economic costs of diabetes in the U.S. in 2022”,Diabetes Care, vol. 47, no. 1, pp. 26–43, 2023
2022
-
[4]
Mobile and wearable technology for the monitoring of diabetes-related parameters: Systematic review
C. Rodriguez-Le ´on, C. Villalonga, M. Munoz-Torres, J. R. Ruiz, and O. Banos, “Mobile and wearable technology for the monitoring of diabetes-related parameters: Systematic review”,JMIR mHealth and uHealth, vol. 9, no. 6, p. e25138, 2021
2021
-
[5]
Applications of federated learning in mobile health: Scoping review
T. Wang, Y . Du, Y . Gong, K.-K. R. Choo, and Y . Guo, “Applications of federated learning in mobile health: Scoping review”,Journal of Medical Internet Research, vol. 25, p. e43006, 2023
2023
-
[6]
Heterogeneity of continuous glucose monitoring features and their clinical associations in a type 2 diabetes population
E. Healey, C. Morato, J. Murillo, and I. Kohane, “Heterogeneity of continuous glucose monitoring features and their clinical associations in a type 2 diabetes population”,Diabetes, Obesity and Metabolism, vol. 27, no. 7, pp. 3957–3966, 2025
2025
-
[7]
Continuous glucose monitoring data analysis 2.0: Functional data pattern recognition and artificial intelligence applications
D. C. Klonoff, R. M. Bergenstal, E. Cengiz, M. A. Clements, D. Espes, J. Espinoza, D. Kerr, B. Kovatchev, D. M. Maahs, J. K. Mader, N. Mathioudakis, A. A. Metwally, S. N. Shah, B. Sheng, M. P. Snyder, G. Umpierrez, M. M. Shao, A. F. Scheideman, A. T. Ayers, C. N. Ho, and E. Healey, “Continuous glucose monitoring data analysis 2.0: Functional data pattern ...
2025
-
[8]
Deep multitask learning by stacked long short-term memory for predicting personalized blood glucose concentration
M. M. H. Shuvo, and S. K. Islam, “Deep multitask learning by stacked long short-term memory for predicting personalized blood glucose concentration”,IEEE Journal of Biomedical and Health Informatics, vol. 27, no. 3, pp. 1612–1623, 2023
2023
-
[9]
Prediction of metabolic subphenotypes of type 2 diabetes via continuous glucose monitoring and machine learning
A. A. Metwally, D. Perelman, H. Park, Y . Wu, A. Jha, S. Sharp, A. Celli, E. Ayhan, F. Abbasi, A. L. Gloyn, T. McLaughlin, and M. P. Snyder, “Prediction of metabolic subphenotypes of type 2 diabetes via continuous glucose monitoring and machine learning”,Nature Biomedical Engineering, vol. 9, no. 8, pp. 1222–1239, 2024
2024
-
[10]
Multi-horizon glucose prediction across populations with deep domain generalization
T. Zhu, I. Afentakis, K. Li, R. Armiger, N. Hill, N. Oliver, and P. Georgiou, “Multi-horizon glucose prediction across populations with deep domain generalization”,IEEE Journal of Biomedical and Health Informatics, vol. 29, no. 8, pp. 5424–5437, 2025
2025
-
[11]
Perspective on harnessing large language models to uncover insights in diabetes wearable data
A. Alavi, K. Cha, D. P. Esfarjani, B. Patel, J. L. P. Than, A. Y . Lee, C. Nebeker, M. Snyder, and A. Bahmani, “Perspective on harnessing large language models to uncover insights in diabetes wearable data”, medRxiv preprint medRxiv:2024.07.29.24310315, 2024
2024
-
[12]
LLM-CGM: A benchmark for large language model-enabled querying of continuous glucose monitoring data for conversational diabetes management
E. Healey, and I. Kohane, “LLM-CGM: A benchmark for large language model-enabled querying of continuous glucose monitoring data for conversational diabetes management”, inBiocomputing, pp. 82–93, 2025
2025
-
[13]
DM-Bench: Benchmarking LLMs for personalized decision making in diabetes management
M. A. Cardei, J. Lamp, M. Derdzinski, and K. Bhatia, “DM-Bench: Benchmarking LLMs for personalized decision making in diabetes management”,arXiv preprint arXiv:2510.00038, 2025
-
[14]
Empowering digital health management with on-device large language models for glucose prediction
T. Zhu, J. Howson, and A. Nevado-Holgado, “Empowering digital health management with on-device large language models for glucose prediction”,medRxiv preprint medRxiv:2025.07.12.25331188, 2025
2025
-
[15]
Mental-LLM: Leveraging large language models for mental health prediction via online text data
X. Xu, B. Yao, Y . Dong, S. Gabriel, H. Yu, J. Hendler, M. Ghassemi, A. K. Dey, and D. Wang, “Mental-LLM: Leveraging large language models for mental health prediction via online text data”,Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, vol. 8, no. 1, pp. 1–32, 2024
2024
-
[16]
Health- LLM: Large language models for health prediction via wearable sensor data
Y . Kim, X. Xu, D. McDuff, C. Breazeal, and H. W. Park, “Health- LLM: Large language models for health prediction via wearable sensor data”, inProceedings of the 5th Conference on Health, Inference, and Learning, 2024
2024
-
[17]
Empowering time series analysis with large language models: A survey
Y . Jiang, Z. Pan, X. Zhang, S. Garg, A. Schneider, Y . Nevmyvaka, and D. Song, “Empowering time series analysis with large language models: A survey”, inProceedings of the 33rd International Joint Conference on Artificial Intelligence, 2024
2024
-
[18]
An image is worth 16x16 words: Trans- formers for image recognition at scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Trans- formers for image recognition at scale”, inInternational Conference on Learning Representations, 2021
2021
-
[19]
A time series is worth 64 words: Long-term forecasting with transformers
Y . Nie, N. H. Nguyen, P. Sinthong, and J. Kalagnanam, “A time series is worth 64 words: Long-term forecasting with transformers”, in International Conference on Learning Representations, 2023
2023
-
[20]
SensorLM: Learning the language of wearable sensors
Y . Zhang, K. Ayush, S. Qiao, A. A. Heydari, G. Narayanswamy, M. A. Xu, A. Metwally, J. Xu, J. Garrison, X. Xu, T. Althoff, Y . Liu, P. Kohli, J. Zhan, M. Malhotra, S. Patel, C. Mascolo, X. Liu, D. McDuff, and Y . Yang, “SensorLM: Learning the language of wearable sensors”, in 39th Conference on Neural Information Processing Systems, 2025
2025
-
[21]
LoRA: Low-rank adaptation of large language models
E. J. Hu, yelong shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models”, inInternational Conference on Learning Representations, 2022
2022
-
[22]
Navigating text-to-image customization: From LyCORIS fine-tuning to model evaluation
S.-Y . Yeh, Y .-G. Hsieh, Z. Gao, B. B. Yang, G. Oh, and Y . Gong, “Navigating text-to-image customization: From LyCORIS fine-tuning to model evaluation”, inICLR, 2023
2023
-
[23]
Federated adaptive fine-tuning of large language models with heterogeneous quantization and LoRA
Z. Gao, Z. Zhang, Y . Guo, and Y . Gong, “Federated adaptive fine-tuning of large language models with heterogeneous quantization and LoRA”, inIEEE INFOCOM, 2025
2025
-
[24]
FedKRSO: Commu- nication and memory efficient federated fine-tuning of large language models
G. Yang, T. Wu, Y . Guo, Y . Sun, and Y . Gong, “FedKRSO: Commu- nication and memory efficient federated fine-tuning of large language models”, inIEEE INFOCOM, 2026
2026
-
[25]
Management of diabetes and hyperglycaemia in the hospital
F. J. Pasquel, M. C. Lansang, K. Dhatariya, and G. E. Umpierrez, “Management of diabetes and hyperglycaemia in the hospital”,The Lancet Diabetes and Endocrinology, vol. 9, no. 3, pp. 174–188, 2021
2021
-
[26]
Ana- lyzing the impact of personalization on fairness in federated learning for healthcare
T. Wang, K. Zhang, J. Cai, Y . Gong, K.-K. R. Choo, and Y . Guo, “Ana- lyzing the impact of personalization on fairness in federated learning for healthcare”,Journal of Healthcare Informatics Research, vol. 8, no. 2, pp. 181–205, 2024
2024
-
[27]
AI-READI: Rethinking data collection, prepa- ration and sharing for propelling AI-based discoveries in diabetes research and beyond
AI-READI Consortium, “AI-READI: Rethinking data collection, prepa- ration and sharing for propelling AI-based discoveries in diabetes research and beyond”,Nature Metabolism, vol. 6, no. 12, pp. 2210– 2212, 2024
2024
-
[28]
Are time series foundation models ready for vital sign forecasting in healthcare?
X. Gu, Y . Liu, Z. Mohsin, J. Bedford, A. Thakur, P. Watkinson, L. Clifton, T. Zhu, and D. Clifton, “Are time series foundation models ready for vital sign forecasting in healthcare?”, inProceedings of the 4th Machine Learning for Health Symposium, pp. 401–419, 2025
2025
-
[29]
A foundation model for continuous glucose monitoring data
G. Lutsker, G. Sapir, S. Shilo, J. Merino, A. Godneva, J. R. Greenfield, D. Samocha-Bonet, R. Dhir, F. Gude, S. Mannor, E. Meirom, E. P. Xing, G. Chechik, H. Rossman, and E. Segal, “A foundation model for continuous glucose monitoring data”,Nature, vol. 650, no. 8103, pp. 978–986, 2026
2026
-
[30]
A pretrained transformer model for decoding individual glucose dynamics from continuous glucose monitoring data
Y . Lu, D. Liu, Z. Liang, R. Liu, P. Chen, Y . Liu, J. Li, Z. Feng, L. M. Li, B. Sheng, W. Jia, L. Chen, H. Li, and Y . Wang, “A pretrained transformer model for decoding individual glucose dynamics from continuous glucose monitoring data”,National Science Review, vol. 12, no. 5, 2025
2025
-
[31]
Integration of artificial intelligence and wearable technology in the management of diabetes and prediabetes
R. A. Fraser, R. J. Walker, J. A. Campbell, O. Ekwunife, and L. E. Egede, “Integration of artificial intelligence and wearable technology in the management of diabetes and prediabetes”,npj Digital Medicine, vol. 8, no. 1, 2025
2025
-
[32]
Med42-v2: A suite of clinical LLMs
C. Christophe, P. K. Kanithi, T. Raha, S. Khan, and M. A. Pi- mentel, “Med42-v2: A suite of clinical LLMs”,arXiv preprint arXiv:2408.06142, 2024
-
[33]
Gemma 2: Improving Open Language Models at a Practical Size
G. Team, M. Riviere, S. Pathak, P. G. Sessa, C. Hardin, S. Bhupatiraju, L. Hussenot, T. Mesnard, B. Shahriari, A. Ram ´e et al., “Gemma 2: Improving open language models at a practical size”,arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand et al., “Mistral 7B”,arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Crossformer: Transformer utilizing cross- dimension dependency for multivariate time series forecasting
Y . Zhang, and J. Yan, “Crossformer: Transformer utilizing cross- dimension dependency for multivariate time series forecasting”, in International Conference on Learning Representations, 2023
2023
-
[36]
iTrans- former: Inverted transformers are effective for time series forecasting
Y . Liu, T. Hu, H. Zhang, H. Wu, S. Wang, L. Ma, and M. Long, “iTrans- former: Inverted transformers are effective for time series forecasting”, inInternational Conference on Learning Representations, 2024
2024
-
[37]
Multilayer feedforward networks are universal approximators
K. Hornik, M. Stinchcombe, and H. White, “Multilayer feedforward networks are universal approximators”,Neural Networks, vol. 2, no. 5, pp. 359–366, 1989
1989
-
[38]
Long short-term memory
S. Hochreiter, and J. Schmidhuber, “Long short-term memory”,Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997
1997
-
[39]
Large language models are zero-shot reasoners
T. Kojima, S. S. Gu, M. Reid, Y . Matsuo, and Y . Iwasawa, “Large language models are zero-shot reasoners”, in36th Conference on Neural Information Processing Systems, 2022
2022
-
[40]
Language models are few-shot learners
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al., “Language models are few-shot learners”, in34th Conference on Neural Information Processing Systems, 2020
2020
-
[41]
Are language models actually useful for time series forecasting?
M. Tan, M. A. Merrill, V . Gupta, T. Althoff, and T. Hartvigsen, “Are language models actually useful for time series forecasting?”, in38th Conference on Neural Information Processing Systems, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.