GeoHAT: Geometry-Adaptive Hybrid Action Transformer for Mobile Manipulation
Pith reviewed 2026-06-27 06:35 UTC · model grok-4.3
The pith
GeoHAT improves whole-body mobile manipulation by injecting reliable 3D geometry only where depth is valid and decoding arm and base actions in separate subspaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
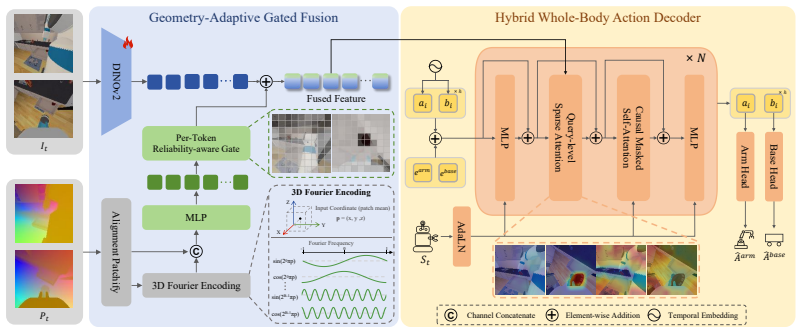
GeoHAT establishes that whole-body mobile manipulation policies improve when geometry is injected only where reliable and attended to only where needed, using a Fourier spatial encoder to produce geometric tokens, per-token gated fusion modulated by depth validity to preserve semantic representations, and a Hybrid Whole-Body Action Decoder that decomposes arm and base into distinct subspaces linked by sparse cross-attention.
What carries the argument
The per-token gated fusion modulated by depth validity, which selectively enriches vision features with geometric tokens without corrupting pretrained semantics, together with the Hybrid Whole-Body Action Decoder that separates arm and base subspaces for sparse cross-attention and causal temporal modeling.
If this is right
- Policies maintain performance under noisy depth by avoiding corruption of semantic priors from vision foundation models.
- Separate subspaces for arm and base allow each to focus on its own task-relevant visual context without a single shared action vector.
- Lightweight Fourier encoding supplies dense geometry without requiring a second full 3D vision backbone.
- The same gains appear across both simulated benchmarks and real-world trials on diverse tasks.
Where Pith is reading between the lines
- The selective gating idea may extend to other sensor-fusion settings where only part of the input is reliable at any moment.
- The subspace separation suggests modular extensions could handle additional robot components such as grippers or sensors.
- Further tests on longer-horizon tasks would show whether the causal temporal modeling continues to coordinate arm and base effectively.
Load-bearing premise
The per-token gated fusion based on depth validity enriches spatial understanding without harming pretrained semantic representations from the vision model, and separating arm and base into distinct subspaces with sparse cross-attention is enough to handle their different control demands.
What would settle it
An ablation study on the same benchmark tasks in which the depth-validity gating is removed and the resulting success rate falls to or below the level of the strongest baseline.
Figures








read the original abstract
Whole-body mobile manipulation requires coordinating mobile base and manipulator under shifting viewpoints, posing challenges in geometric perception and action generation. Current policies either rely on 2D features or sparse 3D representations that lack dense spatial structure, and typically encode arm and base within one action vector that ignores their distinct control demands. Moreover, existing dense fusion strategies risk corrupting pretrained representations under noisy depth while incurring heavy computational overhead. We present GeoHAT, an end-to-end diffusion-based framework built on a simple principle: geometry should be injected only where reliable and attended to only where needed. GeoHAT employs a lightweight Fourier spatial encoder that maps dense per-pixel 3D coordinates into geometric tokens without an additional 3D vision backbone. These tokens are then selectively injected into vision foundation model features through per-token gated fusion modulated by depth validity, preserving the semantic prior while enriching spatial understanding. For action generation, a Hybrid Whole-Body Action Decoder decomposes arm and base into distinct subspaces and lets each action modality attend to its task-relevant visual context through sparse cross-attention, while causal temporal modeling captures intra-timestep coordination and inter-timestep dependencies. Experiments on the ManiSkill-HAB simulation benchmark demonstrate that GeoHAT achieves a 79.3% mean success rate, surpassing the strongest baseline by 23.7%. Furthermore, real-world experiments on diverse tasks also confirm consistent improvements over all baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents GeoHAT, an end-to-end diffusion-based framework for whole-body mobile manipulation. It introduces a lightweight Fourier spatial encoder to map dense per-pixel 3D coordinates into geometric tokens, selectively injects them into vision foundation model features via per-token gated fusion modulated by depth validity, and uses a Hybrid Whole-Body Action Decoder that decomposes arm and base into distinct subspaces with sparse cross-attention plus causal temporal modeling. Experiments claim a 79.3% mean success rate on the ManiSkill-HAB simulation benchmark (23.7% above the strongest baseline) with consistent real-world improvements on diverse tasks.
Significance. If the empirical results are robust, the work offers a practical approach to injecting reliable geometry into pretrained vision representations without corruption or excessive compute, while addressing distinct control demands of base and arm through modality-specific attention. The core design principle of selective geometry injection is a clear strength for handling noisy depth in mobile manipulation.
major comments (1)
- [Abstract] Abstract: the abstract states empirical results but supplies no experimental protocol, baseline descriptions, error bars, ablation studies, or statistical tests; without these details it is impossible to assess whether the 79.3% figure supports the architectural claims about gated fusion and hybrid decoding.
minor comments (1)
- The description of the per-token gated fusion and sparse cross-attention would benefit from an accompanying diagram showing token flow and attention masks.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The single major comment concerns the level of detail in the abstract. We address it point-by-point below and agree that a modest expansion of the abstract will improve clarity without altering the paper's technical contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the abstract states empirical results but supplies no experimental protocol, baseline descriptions, error bars, ablation studies, or statistical tests; without these details it is impossible to assess whether the 79.3% figure supports the architectural claims about gated fusion and hybrid decoding.
Authors: We agree that the abstract, constrained by length, does not enumerate the full experimental protocol, baseline list, error bars, or ablation results. The body of the manuscript supplies these details: Section 4 describes the ManiSkill-HAB benchmark and evaluation protocol; Section 4.1 lists all baselines with implementation references; Section 4.3 presents ablations on the gated fusion and hybrid decoder; and all reported success rates include standard deviations computed over five random seeds together with pairwise statistical comparisons. To address the concern directly, we will revise the abstract to include a concise statement of the benchmark, the primary baseline, and that results are means with standard deviations across multiple runs. This change will make the empirical claims more self-contained while preserving the abstract's brevity. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical architecture (GeoHAT) whose central claims are performance numbers on ManiSkill-HAB and real-world tasks. These are reported as measured outcomes of training and evaluation, not quantities derived from or forced by the model's own equations. No self-definitional steps, fitted-input predictions, or load-bearing self-citation chains appear in the abstract or described method; the design choices (Fourier encoder, gated fusion, hybrid decoder) are presented as engineering decisions whose value is validated externally by benchmark results rather than by internal reduction to inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S. Chen, J. Liu, S. Qian, H. Jiang, Z. Liu, C. Gu, X. Li, C. Hou, P. Wang, Z. Wang, et al. Ac- dit: Adaptive coordination diffusion transformer for mobile manipulation.Advances in Neural Information Processing Systems, 38:64008–64036, 2026
2026
-
[2]
Z. Wu, Y . Zhou, X. Xu, Z. Wang, and H. Yan. Momanipvla: Transferring vision-language- action models for general mobile manipulation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1714–1723, 2025
2025
-
[3]
Jiang, R
Y . Jiang, R. Zhang, J. Wong, C. Wang, Y . Ze, H. Yin, C. Gokmen, S. Song, J. Wu, and L. Fei- Fei. Behavior robot suite: Streamlining real-world whole-body manipulation for everyday household activities. InConference on Robot Learning, pages 1246–1281. PMLR, 2025
2025
- [4]
- [5]
-
[6]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[8]
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations. InProceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[9]
S. Yan, Z. Zhang, M. Han, Z. Wang, Q. Xie, Z. Li, Z. Li, H. Liu, X. Wang, and S.-C. Zhu. M 2 diffuser: Diffusion-based trajectory optimization for mobile manipulation in 3d scenes.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[10]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[11]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, et al. Openvla: An open-source vision-language-action model. InConference on Robot Learning, pages 2679–2713. PMLR, 2025
2025
-
[12]
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
X. Jia, Q. Wang, A. Wang, H. Wang, B. Gyenes, E. Gospodinov, X. Jiang, G. Li, H. Zhou, W. Liao, et al. Pointmappolicy: Structured point cloud processing for multi-modal imitation learning.Advances in Neural Information Processing Systems, 38:160188–160216, 2026
2026
- [14]
- [15]
-
[16]
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, Y . Ding, Z. Wang, J. Gu, B. Zhao, D. Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Shridhar, L
M. Shridhar, L. Manuelli, and D. Fox. Perceiver-actor: A multi-task transformer for robotic manipulation. InConference on Robot Learning, pages 785–799. PMLR, 2023
2023
-
[18]
Goyal, J
A. Goyal, J. Xu, Y . Guo, V . Blukis, Y .-W. Chao, and D. Fox. Rvt: Robotic view transformer for 3d object manipulation. InConference on Robot Learning, pages 694–710. PMLR, 2023
2023
- [19]
- [20]
-
[21]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haz- iza, F. Massa, A. El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Shukla, S
A. Shukla, S. Tao, and H. Su. Maniskill-hab: A benchmark for low-level manipulation in home rearrangement tasks. InInternational Conference on Learning Representations, volume 2025, pages 15288–15317, 2025
2025
- [23]
-
[24]
T.-W. Ke, N. Gkanatsios, and K. Fragkiadaki. 3d diffuser actor: Policy diffusion with 3d scene representations.arXiv preprint arXiv:2402.10885, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Gervet and Z
T. Gervet and Z. Xiao. Act3d: 3d feature field transformers for multi-task robotic manipulation. InConference on Robot Learning. Proceedings of Machine Learning Research, 2023
2023
- [26]
- [27]
-
[28]
C. R. Garrett, R. Chitnis, R. Holladay, B. Kim, T. Silver, L. P. Kaelbling, and T. Lozano-P´erez. Integrated task and motion planning.Annual review of control, robotics, and autonomous systems, 4(1):265–293, 2021
2021
-
[29]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakr- ishnan, K. Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Z. Fu, T. Z. Zhao, and C. Finn. Mobile aloha: Learning bimanual mobile manipulation us- ing low-cost whole-body teleoperation. InConference on Robot Learning, pages 4066–4083. PMLR, 2025
2025
-
[31]
Tancik, P
M. Tancik, P. Srinivasan, B. Mildenhall, S. Fridovich-Keil, N. Raghavan, U. Singhal, R. Ra- mamoorthi, J. Barron, and R. Ng. Fourier features let networks learn high frequency functions in low dimensional domains.Advances in neural information processing systems, 33:7537– 7547, 2020
2020
-
[32]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022. 11
2022
-
[33]
Perez, F
E. Perez, F. Strub, H. De Vries, V . Dumoulin, and A. Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[34]
J. Song, C. Meng, and S. Ermon. Denoising diffusion implicit models. InInternational Con- ference on Learning Representations, 2021. URLhttps://openreview.net/forum?id= St1giarCHLP
2021
-
[35]
Xiang, Y
F. Xiang, Y . Qin, K. Mo, Y . Xia, H. Zhu, F. Liu, M. Liu, H. Jiang, Y . Yuan, H. Wang, et al. Sapien: A simulated part-based interactive environment. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11097–11107, 2020
2020
-
[36]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[37]
Haarnoja, A
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. Pmlr, 2018
2018
-
[38]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. Rdt-1b: a diffu- sion foundation model for bimanual manipulation. InInternational Conference on Learning Representations, volume 2025, pages 29982–30009, 2025
2025
-
[40]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. De- hghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Con- ference on Learning Representations, 2021. URLhttps://openreview.net/forum?id= YicbFdNTTy. 12 Supp...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.