UniviewVLA: A Unified Multiview Vision-Language-Action Model with World Modeling
Pith reviewed 2026-06-26 14:25 UTC · model grok-4.3
The pith
UniviewVLA uses a world model to generate multiview future views from two standard cameras, revealing occlusions and future scene changes to improve robot action prediction without added hardware or reconstruction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UniviewVLA shows that a world model generating multiview future views from only agent-view and wrist-view inputs can reveal occluded information and model scene evolution, which directly supports more accurate action prediction in manipulation tasks.
What carries the argument
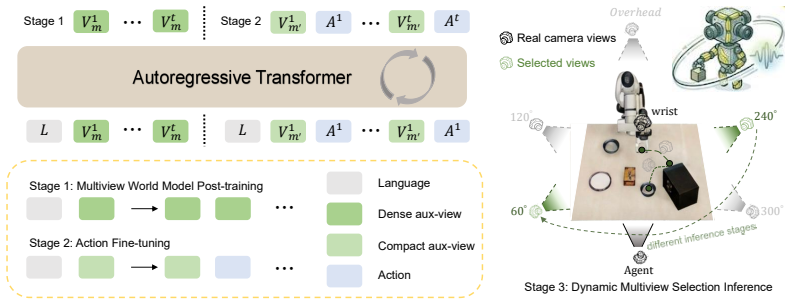
The world model that produces multiview future views from two-camera observations, combined with Motion-Informative Token Compression and Action-Entropy View Selection.
If this is right
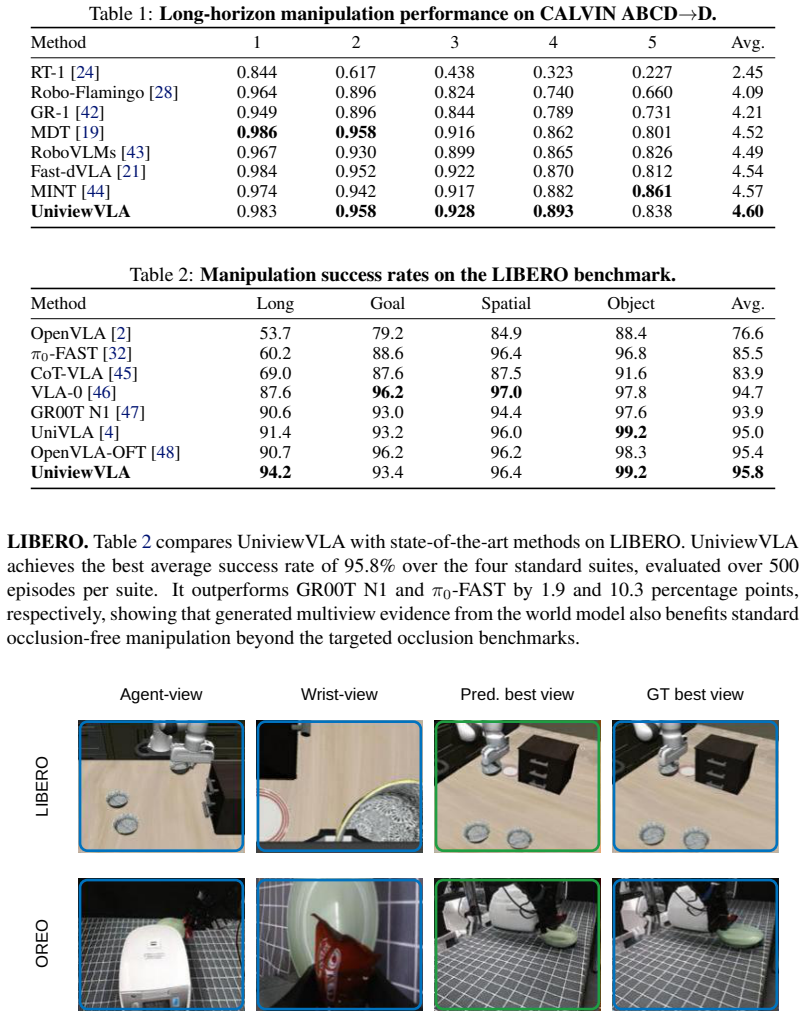
- Occlusion-task success rate increases from 40.0 percent to 73.3 percent.
- Average real-robot success rate rises by 33.4 points.
- Performance on standard benchmarks reaches 95.8 percent on LIBERO and 4.60 on CALVIN ABCD to D.
- Per-view inference latency drops from 6-7 seconds to 0.2-0.3 seconds via token compression.
Where Pith is reading between the lines
- The same generated-view approach might apply to navigation or assembly tasks where cameras are similarly limited.
- If the world model generalizes across robot platforms, it could reduce the need for custom multiview hardware in industrial deployments.
- Further tests on longer-horizon tasks could reveal whether the future-view predictions remain reliable beyond short manipulation sequences.
Load-bearing premise
The generated multiview future views must accurately show occluded areas and future changes without errors that would reduce the accuracy of the action predictions.
What would settle it
Compare success rates on the customized occlusion tasks when the world model is disabled versus when it is active; if rates do not rise from 40.0 percent to 73.3 percent or higher, the core claim fails.
Figures







read the original abstract
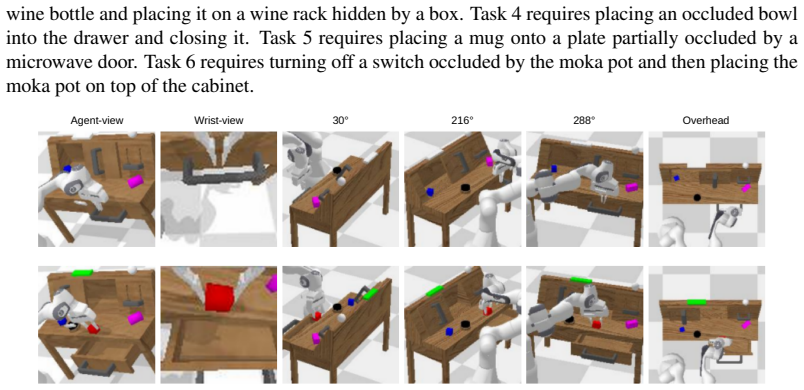
Occluded tasks remain a bottleneck in robot manipulation. Existing solutions either deploy additional physical cameras requiring training-inference camera parity, or rely on explicit 3D reconstruction with high computational cost. Moreover, both approaches rely on standard agent-view and wrist-view observations, while failing to capture occlusion information and future scene evolution. To this end, we propose UniviewVLA, a unified multiview Vision-Language-Action model with world modeling, which infers multiview scene evolution for action prediction from only standard two-camera observations. We demonstrate that by leveraging generated multiview future views from the world model, UniviewVLA reveals occluded cues and models future scene evolution, improving action prediction and removing the need for extra hardware or explicit reconstruction. Besides, to accelerate inference while preserving prediction accuracy, UniviewVLA develops Motion-Informative Token Compression, which compresses each generated view from 625 to 16 tokens and reduces per-view latency from 6-7s to 0.2-0.3s. UniviewVLA also proposes training-free Action-Entropy View Selection, which dynamically identifies the most action-informative view at different inference stages. Extensive experiments show that UniviewVLA achieves 95.8% on LIBERO and 4.60 on CALVIN ABCD to D, both standard occlusion-free benchmarks. On customized occlusion-focused tasks, it improves success rate from 40.0% to 73.3%, and average real-robot success rate by 33.4 points, demonstrating stronger occlusion-focused performance without sacrificing standard occlusion-free benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UniviewVLA, a unified multiview Vision-Language-Action model augmented with a world model. From only standard two-camera (agent and wrist) observations, the world model generates multiview future scene views to reveal occluded information and model future evolution for improved action prediction, eliminating the need for extra cameras or explicit 3D reconstruction. It further introduces Motion-Informative Token Compression (reducing each view from 625 to 16 tokens) for faster inference and training-free Action-Entropy View Selection to pick the most informative view. Reported results include 95.8% success on LIBERO, 4.60 on CALVIN ABCD o D, occlusion-task success rising from 40.0% to 73.3%, and +33.4 points on real-robot tasks.
Significance. If the generated multiview views prove faithful, the approach would address a practical bottleneck in robot manipulation by leveraging world modeling for occlusion handling without hardware or reconstruction overhead, while the token-compression technique offers a concrete efficiency gain. The dual evaluation on both standard benchmarks and custom occlusion/real-robot settings is a positive framing, but the absence of independent validation for the core world-model output weakens the ability to attribute gains specifically to accurate cue revelation.
major comments (3)
- [§4 (World Model and Experiments)] §4 (World Model and Experiments): The central claim that generated multiview future views 'reveal occluded cues' and improve action prediction rests on the assumption that these views are sufficiently accurate in occluded regions. However, the manuscript supplies no independent quantitative validation of generation fidelity—no pixel-level metrics (PSNR/SSIM/LPIPS), no consistency checks against the two input streams on held-out future frames, and no ablation that isolates the contribution of the generated views from token compression or view selection.
- [Table 2 / occlusion-task results] Table 2 / occlusion-task results: Success rate improves from 40.0% to 73.3% on the custom occlusion tasks, yet no ablation table or controlled comparison is presented that removes the world-model component while keeping all other modules fixed; without this, it is impossible to confirm that the reported delta arises from faithful occluded-content generation rather than other architectural choices or training distribution effects.
- [§5 (Real-robot experiments)] §5 (Real-robot experiments): The +33.4 point average success improvement is presented as a single aggregate figure with no per-task breakdown, no error bars across multiple runs, and no baseline that uses the same two-camera setup plus a non-generative multiview module; this makes the attribution to the world-model-generated views load-bearing but unverified.
minor comments (2)
- [Abstract] Abstract: The phrase 'extensive experiments' is used, yet the text provides no information on training dataset size, model parameter count, or optimizer settings, which are standard for reproducibility in VLA papers.
- [Notation] Notation: 'Motion-Informative Token Compression' and 'Action-Entropy View Selection' are named without an accompanying equation or pseudocode definition in the early sections, forcing the reader to infer their mechanics from later prose.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, clarifying the evidence provided in the manuscript and indicating where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: The central claim that generated multiview future views 'reveal occluded cues' and improve action prediction rests on the assumption that these views are sufficiently accurate in occluded regions. However, the manuscript supplies no independent quantitative validation of generation fidelity—no pixel-level metrics (PSNR/SSIM/LPIPS), no consistency checks against the two input streams on held-out future frames, and no ablation that isolates the contribution of the generated views from token compression or view selection.
Authors: We agree that direct pixel-level fidelity metrics on the generated views would provide stronger support for the claim. The current manuscript relies on downstream task performance (particularly the 33.3-point gain on custom occlusion tasks) as evidence of utility. We will add qualitative examples of generated multiview frames highlighting occluded regions and quantitative metrics (e.g., LPIPS on held-out frames) in the revision. The occlusion-task results already serve as an indirect isolation of the world-model contribution; we will further clarify this in §4. revision: partial
-
Referee: Success rate improves from 40.0% to 73.3% on the custom occlusion tasks, yet no ablation table or controlled comparison is presented that removes the world-model component while keeping all other modules fixed; without this, it is impossible to confirm that the reported delta arises from faithful occluded-content generation rather than other architectural choices or training distribution effects.
Authors: We will include a dedicated ablation in the revised manuscript that removes only the world-model component (while retaining token compression and view selection) and reports the resulting success rates on the occlusion tasks. This will directly address attribution of the observed gains. revision: yes
-
Referee: The +33.4 point average success improvement is presented as a single aggregate figure with no per-task breakdown, no error bars across multiple runs, and no baseline that uses the same two-camera setup plus a non-generative multiview module; this makes the attribution to the world-model-generated views load-bearing but unverified.
Authors: We will expand §5 to include per-task success rates, standard deviations across runs, and explicit comparison against the two-camera baseline without the generative component. The non-generative multiview baseline is already implicit in the standard two-camera results reported; we will make this comparison explicit in the revision. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes an architectural model (UniviewVLA) that combines a world model for generating multiview future views with action prediction, reporting empirical gains on LIBERO, CALVIN, custom occlusion tasks, and real-robot evaluations. No equations or sections exhibit self-definitional reductions, fitted parameters renamed as predictions, or load-bearing self-citations that collapse the central claim to unverified inputs. The world-model generation and token-compression modules are presented as trained components whose value is assessed via downstream task metrics on established external benchmarks, with no mathematical derivation chain that reduces by construction to the training data or prior self-citations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[2]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, et al. Openvla: An open-source vision-language-action model. InConference on Robot Learning, pages 2679–2713. PMLR, 2025
2025
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [4]
- [5]
-
[6]
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
C.-L. Cheang, G. Chen, Y . Jing, T. Kong, H. Li, Y . Li, Y . Liu, H. Wu, J. Xu, Y . Yang, et al. Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation. arXiv preprint arXiv:2410.06158, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
P. Li, Y . Chen, Y . Xu, J. Yang, X. Wu, J. Guo, N. Sun, L. Qian, X. Li, X. Xiao, et al. Multi- view video diffusion policy: A 3d spatio-temporal-aware video action model.arXiv preprint arXiv:2604.03181, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [8]
-
[9]
J. Wen, Y . Zhu, J. Li, Z. Tang, C. Shen, and F. Feng. Dexvla: Vision-language model with plug-in diffusion expert for general robot control. InConference on Robot Learning, pages 3094–3114. PMLR, 2025
2025
- [10]
-
[11]
Goyal, J
A. Goyal, J. Xu, Y . Guo, V . Blukis, Y .-W. Chao, and D. Fox. Rvt: Robotic view transformer for 3d object manipulation. InConference on Robot Learning, pages 694–710. PMLR, 2023
2023
-
[12]
Shridhar, L
M. Shridhar, L. Manuelli, and D. Fox. Perceiver-actor: A multi-task transformer for robotic manipulation. InConference on Robot Learning, pages 785–799. PMLR, 2023
2023
-
[13]
Dream to Control: Learning Behaviors by Latent Imagination
D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[14]
P. Wu, A. Escontrela, D. Hafner, P. Abbeel, and K. Goldberg. Daydreamer: World models for physical robot learning. InConference on robot learning, pages 2226–2240. PMLR, 2023
2023
-
[15]
F. Yang, D. Di, L. Tang, X. Zhang, L. Fan, H. Li, W. Chen, T. Su, and B. Ma. Chain of world: World model thinking in latent motion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6675–6684, 2026
2026
- [16]
- [17]
- [18]
- [19]
-
[20]
Huang, C
Z. Huang, C. Feng, F. Yan, B. Xiao, Z. Jie, Y . Zhong, X. Liang, and L. Ma. Robotron-drive: All-in-one large multimodal model for autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8011–8021, 2025
2025
-
[21]
W. Song, J. Chen, S. Chen, J. Wang, P. Ding, H. Zhao, Y . Qin, X. Zheng, D. Wang, Y . Wang, et al. Fast-dvla: Accelerating discrete diffusion vla to real-time performance.arXiv preprint arXiv:2603.25661, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InICML Workshop on New Frontiers in Learning, Control, and Dynamical Systems
-
[23]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[24]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. Robotics: Science and Systems XIX, 2023
2023
-
[25]
Huang, T
Z. Huang, T. Tang, S. Chen, S. Lin, Z. Jie, L. Ma, G. Wang, and X. Liang. Making large language models better planners with reasoning-decision alignment. InEuropean Conference on Computer Vision, pages 73–90. Springer, 2024
2024
-
[26]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakr- ishnan, K. Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Driess, F
D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, et al. Palm-e: an embodied multimodal language model. InProceedings of the 40th International Conference on Machine Learning, pages 8469–8488, 2023
2023
-
[28]
X. Li, M. Liu, H. Zhang, C. Yu, J. Xu, H. Wu, C. Cheang, Y . Jing, W. Zhang, H. Liu, et al. Vision-language foundation models as effective robot imitators. InInternational Conference on Learning Representations, volume 2024, pages 26703–26721, 2024
2024
-
[29]
O. Mees, D. Ghosh, K. Pertsch, K. Black, H. R. Walke, S. Dasari, J. Hejna, T. Kreiman, C. Xu, J. Luo, et al. Octo: An open-source generalist robot policy. InFirst Workshop on Vision- Language Models for Navigation and Manipulation at ICRA 2024, 2024
2024
-
[30]
K. Bousmalis, G. Vezzani, D. Rao, C. Devin, A. X. Lee, M. Bauzá, T. Davchev, Y . Zhou, A. Gupta, A. Raju, et al. Robocat: A self-improving generalist agent for robotic manipulation. arXiv preprint arXiv:2306.11706, 2023
-
[31]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[32]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
James, Z
S. James, Z. Ma, D. R. Arrojo, and A. J. Davison. Rlbench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020
2020
-
[34]
A. Zeng, P. Florence, J. Tompson, S. Welker, J. Chien, M. Attarian, T. Armstrong, I. Krasin, D. Duong, V . Sindhwani, et al. Transporter networks: Rearranging the visual world for robotic manipulation. InConference on Robot Learning, pages 726–747. PMLR, 2021
2021
-
[35]
Shridhar, L
M. Shridhar, L. Manuelli, and D. Fox. Cliport: What and where pathways for robotic manipu- lation. InConference on robot learning, pages 894–906. PMLR, 2022
2022
-
[36]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei. V oxposer: Composable 3d value maps for robotic manipulation with language models.arXiv preprint arXiv:2307.05973, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
T.-W. Ke, N. Gkanatsios, and K. Fragkiadaki. 3d diffuser actor: Policy diffusion with 3d scene representations. InConference on Robot Learning, pages 1949–1974. PMLR, 2025
1949
- [38]
-
[39]
C. E. Shannon. A mathematical theory of communication.The Bell system technical journal, 27(3):379–423, 1948
1948
-
[40]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[41]
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard. Calvin: A benchmark for language- conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
2022
-
[42]
H. Wu, Y . Jing, C. Cheang, G. Chen, J. Xu, X. Li, M. Liu, H. Li, and T. Kong. Unleashing large- scale video generative pre-training for visual robot manipulation. InInternational Conference on Learning Representations, volume 2024, pages 10641–10662, 2024
2024
-
[43]
H. Liu, X. Li, P. Li, M. Liu, D. Wang, J. Liu, B. Kang, X. Ma, T. Kong, and H. Zhang. Towards generalist robot policies: What matters in building vision-language-action models. 2025
2025
- [44]
-
[45]
Q. Zhao, Y . Lu, M. J. Kim, Z. Fu, Z. Zhang, Y . Wu, Z. Li, Q. Ma, S. Han, C. Finn, et al. Cot- vla: Visual chain-of-thought reasoning for vision-language-action models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1702–1713, 2025
2025
- [46]
-
[47]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorck, F. Castañeda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025. 11 A Implementation details Stage 1: multiview world-model post-training.All UniviewVLA experiments use models trained on 8 NVIDIA H-series GPUs with bf16 and DeepSpeed ZeRO-3. We use the same Emu3- based autoreg...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.