Neural Autoregressive Control Variates for the Quantum Monte Carlo Sign Problem
Pith reviewed 2026-06-29 15:50 UTC · model grok-4.3
The pith
A pair of autoregressive networks supplies zero-mean control variates that cut quantum Monte Carlo sign variance by up to an order of magnitude.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
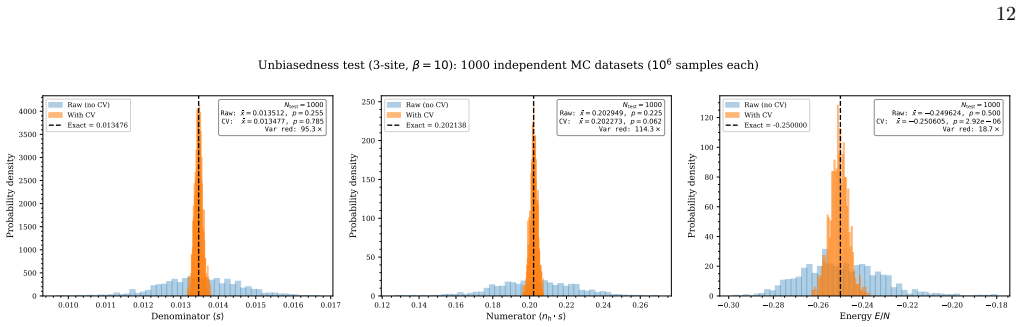
We train a pair of autoregressive models to construct zero-mean control variates to mitigate the sign problem in quantum Monte Carlo simulations. The two autoregressive networks are confined to the positive- and negative-sign sectors with strictly disjoint support, and each is exactly normalized over its sector. Their difference is therefore structurally zero-mean, providing an unbiased auxiliary observable whose correlation with the sign estimator controls the variance reduction.
What carries the argument
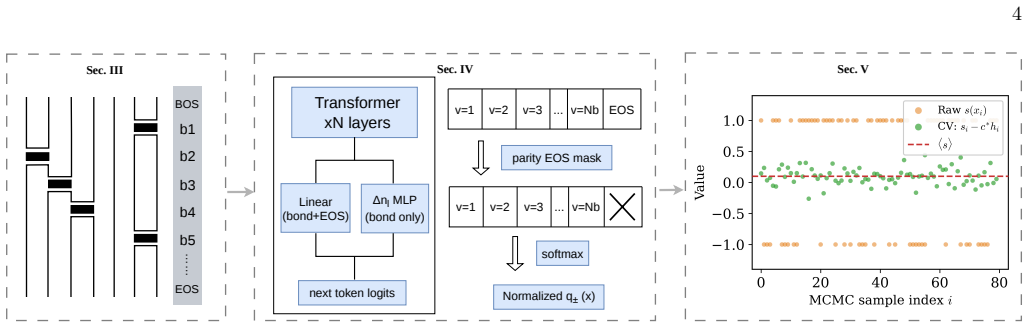
A pair of autoregressive transformers with an end-of-sequence parity mask that enforce exact sign-sector resolution and produce a structurally zero-mean control variate from their difference.
If this is right
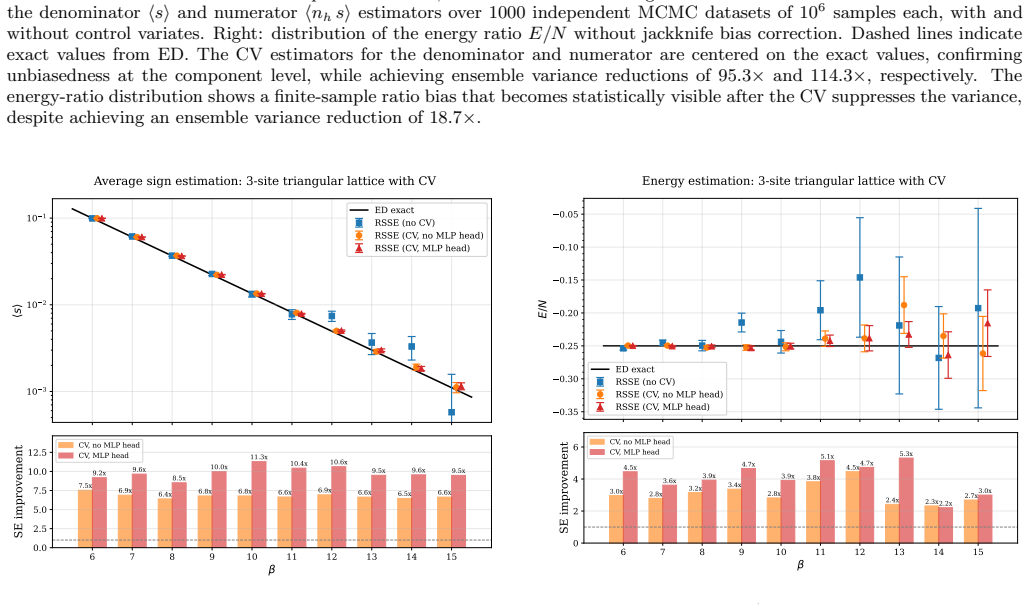
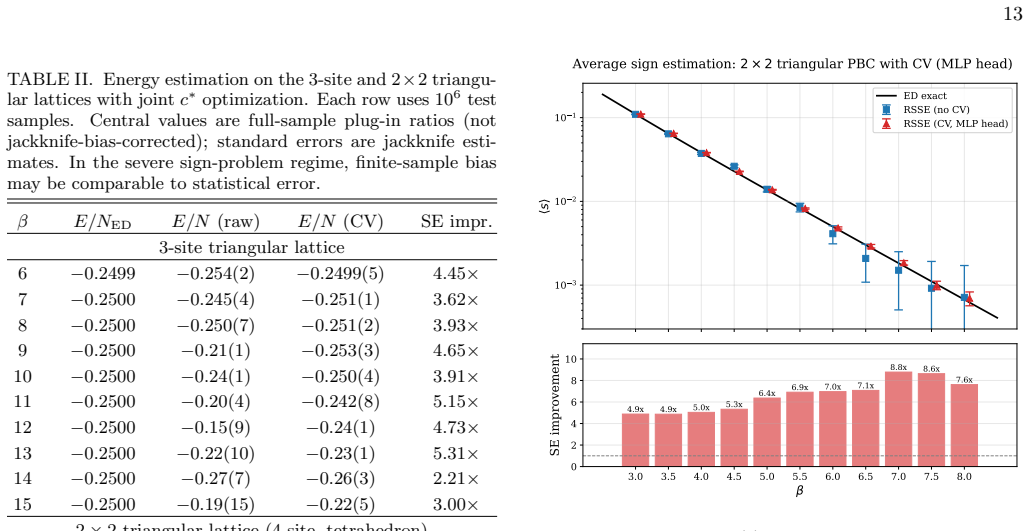
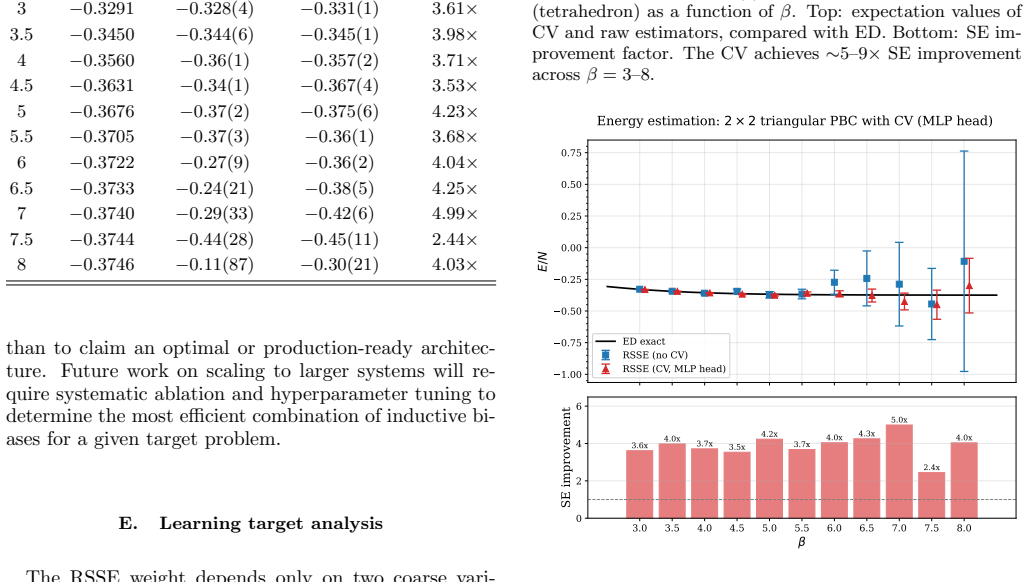
- The standard error of the average sign is reduced by up to an order of magnitude.
- The standard error of the energy estimator is reduced by a factor of three to five.
- The error reduction persists when the average sign drops below 10^{-3}.
- Sign-ergodic sampling on frustrated lattices is achieved by adding a twist channel as the unique sign-changing mechanism.
Where Pith is reading between the lines
- If the correlation between control variate and sign estimator remains high on larger systems, the same architecture could extend the reachable size of sign-problematic simulations by one or two lattice sizes.
- Incorporating additional topological or symmetry features into the autoregressive input could further tighten the correlation without changing the zero-mean property.
- The same disjoint-sector normalization trick may transfer to other Monte Carlo estimators that suffer from phase cancellations rather than pure sign changes.
Load-bearing premise
Autoregressive transformers can be trained to achieve sufficiently high correlation with the sign estimator while preserving exact normalization and strictly disjoint support on each sign sector.
What would settle it
On a lattice larger than the small-N benchmarks, train the networks to the same protocol; if the resulting control variate yields no net reduction in the measured standard error of the average sign or energy, the variance-reduction claim does not hold.
Figures
read the original abstract
We train a pair of autoregressive models to construct zero-mean control variates to mitigate the sign problem in quantum Monte Carlo simulations. The two autoregressive networks are confined to the positive- and negative-sign sectors with strictly disjoint support, and each is exactly normalized over its sector. Their difference is therefore structurally zero-mean, providing an unbiased auxiliary observable whose correlation with the sign estimator controls the variance reduction. We implement the method within the stochastic series expansion framework, which we extend to frustrated lattices by developing an incremental loop-topology update. Sign-ergodic sampling is achieved through a twist channel, which is the unique sign-changing mechanism on non-bipartite lattices. We implement the control variates as autoregressive transformers with an end-of-sequence parity mask that enforces exact sign-sector resolution, while the incremental loop-count change and cumulative frustration parity are incorporated as topological features. On the triangular-lattice Heisenberg antiferromagnet, we benchmark the method in the small-$N$ limit. The control variate reduces the standard error of the average sign by up to an order of magnitude and that of the energy estimator by a factor of three to five, remaining effective even when the average sign drops below $10^{-3}$. This work lays out the framework and provides a proof-of-principle demonstration that autoregressive control variates can effectively mitigate the sign problem. Scaling to larger systems with physics-informed architectures is the subject of future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a pair of autoregressive transformer networks as control variates to reduce variance in the sign problem for quantum Monte Carlo (specifically SSE) simulations on frustrated lattices. The networks are restricted to strictly disjoint positive- and negative-sign sectors with exact normalization over each sector, so their difference is zero-mean by construction and provides an unbiased auxiliary observable. Topological features (incremental loop-count change and cumulative frustration parity) plus an end-of-sequence parity mask are incorporated to enforce sign-sector resolution. On small-N triangular-lattice Heisenberg antiferromagnet clusters the method is reported to reduce the standard error of the average sign by up to an order of magnitude and the energy estimator error by a factor of 3–5, remaining effective below average sign 10^{-3}. Scaling to larger systems is left for future work.
Significance. The structural guarantee of unbiasedness (disjoint support plus exact normalization) is a clear strength and avoids circularity. If the reported correlations can be maintained at larger sizes where the sign problem is severe, the approach could meaningfully extend the reach of QMC on non-bipartite systems. The work supplies a concrete proof-of-principle framework together with the necessary SSE extensions (incremental loop-topology update and twist-channel sampling), which are useful contributions even if the variance-reduction factors remain modest on the presented clusters.
major comments (2)
- [Abstract / numerical results] Abstract and numerical-results section: the concrete error-reduction factors (order-of-magnitude on the sign, 3–5× on energy) are presented without any description of the loss function, optimizer, training schedule, or achieved Pearson correlation values on the held-out configurations. Because the variance reduction is controlled entirely by this correlation, the absence of these details leaves the central numerical claim only weakly supported.
- [Method / architecture description] Method section on autoregressive architecture: while the end-of-sequence parity mask and topological features are described, there is no quantitative analysis showing that the learned correlation remains high once the sign structure becomes more intricate (e.g., when average sign < 10^{-3} on larger clusters). The paper correctly notes that scaling is future work, but the load-bearing assumption that sufficient correlation will persist is not tested or bounded.
minor comments (2)
- [Abstract] The abstract states that the control variate “remains effective even when the average sign drops below 10^{-3}”; a table or figure explicitly showing the correlation coefficient versus average sign would make this claim easier to evaluate.
- [Method] Notation for the two autoregressive models (positive- and negative-sector) should be introduced once with a clear equation rather than described only in prose.
Simulated Author's Rebuttal
We thank the referee for the constructive report and for recognizing the structural guarantee of unbiasedness as a strength. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Abstract / numerical results] Abstract and numerical-results section: the concrete error-reduction factors (order-of-magnitude on the sign, 3–5× on energy) are presented without any description of the loss function, optimizer, training schedule, or achieved Pearson correlation values on the held-out configurations. Because the variance reduction is controlled entirely by this correlation, the absence of these details leaves the central numerical claim only weakly supported.
Authors: We agree that the training details and correlation values are necessary to substantiate the reported variance reductions. In the revised manuscript we will insert a new subsection (or expanded paragraph) in the numerical-results section that specifies the loss function (negative log-likelihood for autoregressive density estimation), the optimizer and hyperparameters (Adam with learning-rate schedule), the training schedule (epochs, batch size, early stopping), and the Pearson correlation coefficients measured on held-out configurations. These correlations were high in the small-N regime and directly account for the observed error reductions. revision: yes
-
Referee: [Method / architecture description] Method section on autoregressive architecture: while the end-of-sequence parity mask and topological features are described, there is no quantitative analysis showing that the learned correlation remains high once the sign structure becomes more intricate (e.g., when average sign < 10^{-3} on larger clusters). The paper correctly notes that scaling is future work, but the load-bearing assumption that sufficient correlation will persist is not tested or bounded.
Authors: The manuscript is explicitly framed as a proof-of-principle study on small-N clusters; we therefore do not claim or test persistence of correlation on larger systems. The load-bearing assumption for future scaling is acknowledged as untested in the present work and is stated as the subject of ongoing research with physics-informed architectures. No additional quantitative analysis on larger clusters can be supplied at this time. revision: no
- Quantitative demonstration that the learned correlation remains high on larger clusters where the sign structure is more intricate (average sign < 10^{-3})
Circularity Check
No circularity; unbiasedness by explicit construction, reductions from benchmarks
full rationale
The paper constructs the control variates with strictly disjoint support on sign sectors and exact normalization, making the zero-mean property a direct structural consequence rather than a derived or fitted result. Reported variance reductions (order-of-magnitude on sign, 3-5x on energy) are presented as numerical outcomes from small-N benchmarks on the triangular lattice, explicitly labeled as proof-of-principle with larger scaling as future work. No self-citations, uniqueness theorems imported from prior author work, ansatzes smuggled via citation, or renaming of known results appear in the provided text. The derivation chain is self-contained and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Autoregressive models can be exactly normalized over each sign sector separately.
Reference graph
Works this paper leans on
-
[1]
(7) takes the sectorwise-constant form h(x) = ( 1/Z+, s(x) = +1, −1/Z−, s(x) =−1
Denominator: exact zero variance In the perfect-model limit, the control variateh(x) de- fined in Eq. (7) takes the sectorwise-constant form h(x) = ( 1/Z+, s(x) = +1, −1/Z−, s(x) =−1. (A1) Definingp ± =Z ±/Z, one has⟨s⟩=p +−p− and Var(s) = 4p+p−. The second moment ofhis ⟨h2⟩=p + 1 Z2 + +p − 1 Z2 − = 1 ZZ+ + 1 ZZ − = 1 Z+Z− ,(A2) so Var(h) = 1/(Z +Z−) (sin...
-
[2]
The target observ- able isy(x) =n h(x)s(x)
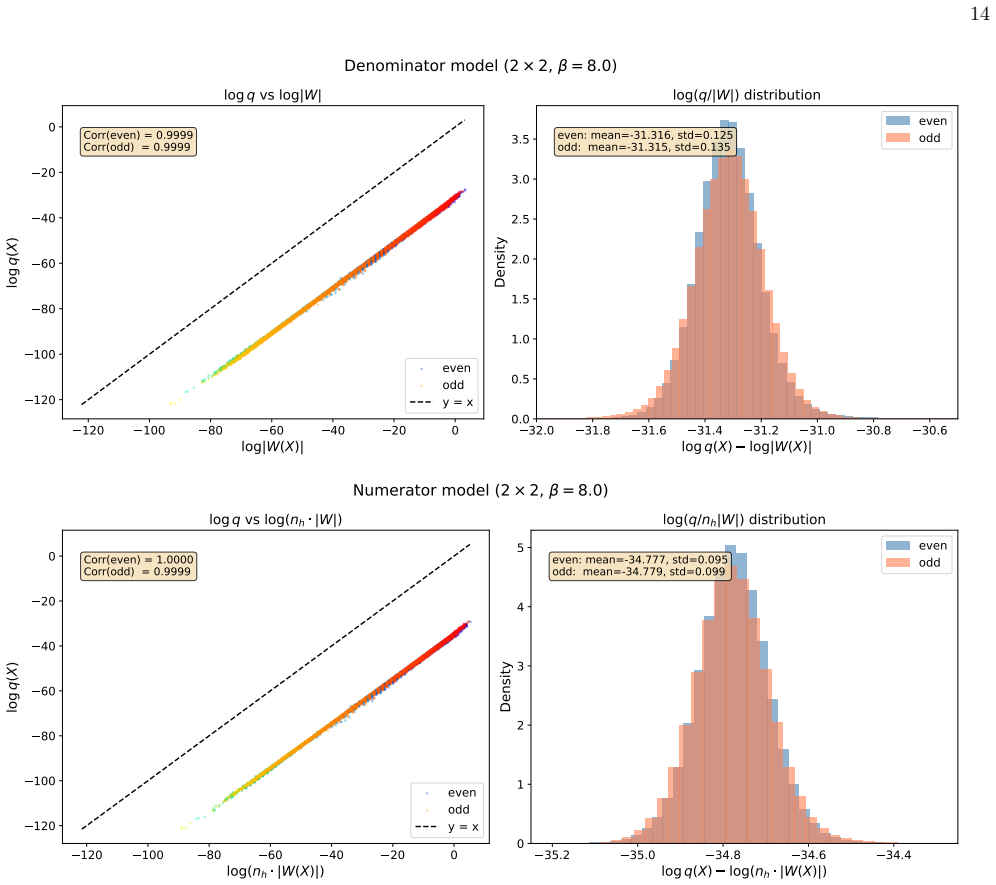
Numerator: approximate cancellation For the numerator⟨nh s⟩, then h-weighted models yield in the perfect limit hO(x) = ( nh(x)/Z(O) + , s(x) = +1, −nh(x)/Z(O) − , s(x) =−1, (A8) whereZ (O) ± =P x:s=±1 nh(x)|W(x)|. The target observ- able isy(x) =n h(x)s(x). For exact zero variance one would need a constantλsuch that y(x)−λ h O(x) = const (A9) for every co...
-
[3]
J. E. Y. Loh, J. E. Gubernatis, R. T. Scalettar, S. R. White, D. J. Scalapino, and R. L. Sugar, Sign problem in the numerical simulation of many-electron systems, 18 Phys. Rev. B41, 9301 (1990)
1990
-
[4]
Dornheim, Fermion sign problem in path integral Monte Carlo simulations: quantum dots, ultracold atoms, and warm dense matter, Phys
T. Dornheim, Fermion sign problem in path integral Monte Carlo simulations: quantum dots, ultracold atoms, and warm dense matter, Phys. Rev. E100, 023307 (2019)
2019
-
[5]
Nagata, Finite-density lattice QCD and sign prob- lem: current status and open problems, Prog
K. Nagata, Finite-density lattice QCD and sign prob- lem: current status and open problems, Prog. Part. Nucl. Phys.127, 103991 (2022)
2022
-
[6]
Alhassid, D
Y. Alhassid, D. J. Dean, S. E. Koonin, G. Lang, and W. E. Ormand, Practical solution to the Monte Carlo sign problem: realistic calculations of 54fe, Phys. Rev. Lett.72, 613 (1994)
1994
-
[7]
Henelius and A
P. Henelius and A. W. Sandvik, Sign problem in Monte Carlo simulations of frustrated quantum spin systems, Phys. Rev. B62, 1102 (2000)
2000
-
[8]
Wu and S.-C
C. Wu and S.-C. Zhang, Sufficient condition for absence of the sign problem in the fermionic quantum Monte Carlo algorithm, Phys. Rev. B71, 155115 (2005)
2005
-
[9]
Z.-C. Wei, C. Wu, Y. Li, S. Zhang, and T. Xiang, Majo- rana positivity and the fermion sign problem of quantum Monte Carlo simulations, Phys. Rev. Lett.116, 250601 (2016)
2016
-
[10]
Li, Y.-F
Z.-X. Li, Y.-F. Jiang, and H. Yao, Majorana-time- reversal symmetries: a fundamental principle for sign- problem-free quantum Monte Carlo simulations, Phys. Rev. Lett.117, 267002 (2016)
2016
-
[11]
Li and H
Z.-X. Li and H. Yao, Sign-problem-free fermionic quan- tum Monte Carlo: Developments and applications, Annu. Rev. Condens. Matter Phys.10, 337 (2019)
2019
-
[12]
F. Alet, K. Damle, and S. Pujari, Sign-problem-free Monte Carlo simulation of certain frustrated quantum magnets, Phys. Rev. Lett.117, 197203 (2016)
2016
-
[13]
Wessel, B
S. Wessel, B. Normand, F. Mila, and A. Honecker, Ef- ficient quantum Monte Carlo simulations of highly frus- trated magnets: the frustrated spin-1/2 ladder, SciPost Phys.3, 005 (2017)
2017
-
[14]
Wessel, I
S. Wessel, I. Niesen, J. Stapmanns, B. Normand, F. Mila, P. Corboz, and A. Honecker, Thermodynamic properties of the Shastry-Sutherland model from quantum Monte Carlo simulations, Phys. Rev. B98, 174432 (2018)
2018
-
[15]
Shinaoka, Y
H. Shinaoka, Y. Nomura, S. Biermann, M. Troyer, and P. Werner, Negative sign problem in continuous-time quantum Monte Carlo: optimal choice of single-particle basis for impurity problems, Phys. Rev. B92, 195126 (2015)
2015
-
[16]
Levy and B
R. Levy and B. K. Clark, Mitigating the sign problem through basis rotations, Phys. Rev. Lett.126, 216401 (2021)
2021
-
[17]
Hangleiter, I
D. Hangleiter, I. Roth, D. Nagaj, and J. Eisert, Easing the Monte Carlo sign problem, Sci. Adv.6, eabb8341 (2020)
2020
-
[18]
Xiong and H
Y. Xiong and H. Xiong, On the thermodynamic prop- erties of fictitious identical particles and the application to fermion sign problem, J. Chem. Phys.157, 094112 (2022)
2022
-
[19]
Dornheim, P
T. Dornheim, P. Tolias, S. Groth, Z. A. Moldabekov, J. Vorberger, and B. Hirshberg, Fermionic physics from ab initio path integral Monte Carlo simulations of fic- titious identical particles, J. Chem. Phys.159, 164113 (2023)
2023
-
[20]
Z. Fan, T. Xiao, and Y. Deng, Quantum path-integral method for the fictitious-particle Hubbard model, Phys. Rev. B113, 115123 (2026)
2026
-
[21]
Morresi and G
T. Morresi and G. Garberoglio, Normal liquid 3He stud- ied by path-integral Monte Carlo with a parametrized partition function, Phys. Rev. B111, 014521 (2025)
2025
-
[22]
He, J.-X
R.-C. He, J.-X. Zeng, S. Yang, C. Wang, Q.-J. Ye, and X.-Z. Li, Fermion sign problem and the structure of Lee- Yang zeros: The form of the partition function for indis- tinguishable particles and its zeros at 0 K, Phys. Rev. E 113, 024115 (2026)
2026
-
[23]
Bhattacharya, S
T. Bhattacharya, S. Lawrence, and J.-S. Yoo, Con- trol variates for lattice field theory, Phys. Rev. D109, L031505 (2024)
2024
-
[24]
S. Lawrence, Schwinger-Dyson control variates for lattice fermions, arXiv:2404.10707 (2024), arXiv:2404.10707
-
[25]
P. F. Bedaque and H. Oh, Leveraging neural control vari- ates for enhanced precision in lattice field theory, Phys. Rev. D109, 094519 (2024)
2024
-
[26]
S. Lawrence and Y. Yamauchi, Mitigating a dis- crete sign problem with extreme learning machines, arXiv:2312.12636 (2023), arXiv:2312.12636
-
[27]
M¨ uller, F
T. M¨ uller, F. Rousselle, A. Keller, and J. Nov´ ak, Neural control variates, ACM Trans. Graph.39, 243:1 (2020)
2020
-
[28]
P. W. Glynn and R. Szechtman, Some new perspectives on the method of control variates, inMonte Carlo and Quasi-Monte Carlo Methods 2000, edited by K.-T. Fang, F. J. Hickernell, and H. Niederreiter (Springer, Berlin,
2000
-
[29]
P. Shyamsundar, J. L. Scott, S. Mrenna, K. T. Matchev, and K. Kong, Variance reduction via simultaneous im- portance sampling and control variates techniques using vegas, SciPost Phys. Codebases28, 10.21468/SciPost- PhysCodeb.28 (2024)
-
[30]
Assaraf and M
R. Assaraf and M. Caffarel, Zero-variance principle for Monte Carlo algorithms, Phys. Rev. Lett.83, 4682 (1999)
1999
-
[31]
W. G. Cochran,Sampling Techniques, 3rd ed. (Wiley, New York, 1977)
1977
-
[32]
A. W. Sandvik, Stochastic series expansion method with operator-loop update, Phys. Rev. B59, R14157 (1999)
1999
-
[33]
O. F. Sylju˚ asen and A. W. Sandvik, Quantum Monte Carlo with directed loops, Phys. Rev. E66, 046701 (2002)
2002
-
[34]
R. G. Melko, Simulations of quantum XXZ models on two-dimensional frustrated lattices, J. Phys.: Condens. Matter19, 145203 (2007)
2007
-
[35]
Desai and S
N. Desai and S. Pujari, Resummation-based quantum Monte Carlo for quantum paramagnetic phases, Phys. Rev. B104, L060406 (2021)
2021
-
[36]
R. K. Kaul, R. G. Melko, and A. W. Sandvik, Bridg- ing lattice-scale physics and continuum field theory with quantum Monte Carlo simulations, Annu. Rev. Condens. Matter Phys.4, 179 (2013)
2013
-
[37]
S. Geng, M. Josifoski, M. Peyrard, and R. West, Grammar-constrained decoding for structured NLP tasks without finetuning, inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (Association for Computational Linguistics, Singapore,
2023
-
[38]
B. T. Willard and R. Louf, Efficient guided genera- tion for large language models, arXiv preprint (2023), arXiv:2307.09702
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, Attention is all you need, Adv. Neural Inf. Process. Syst. 30, 5998 (2017)
2017
-
[40]
Radford, J
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and 19 I. Sutskever, Language models are unsupervised multi- task learners, OpenAI Technical Report (2019)
2019
-
[41]
D. P. Kingma and J. Ba, Adam: A method for stochas- tic optimization, inInternational Conference on Learning Representations(2015)
2015
-
[42]
Weigel and W
M. Weigel and W. Janke, Error estimation and reduction with cross correlations, Phys. Rev. E81, 066701 (2010)
2010
-
[43]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, Scaling laws for neural language models, arXiv preprint (2020), arXiv:2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.