PMDformer: Patch-Mean Decoupling Information Transformer for Long-term Forecasting
Pith reviewed 2026-06-26 05:20 UTC · model grok-4.3
The pith
PMDformer decouples patch means to let attention focus on shape similarities for better long-term time series forecasts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
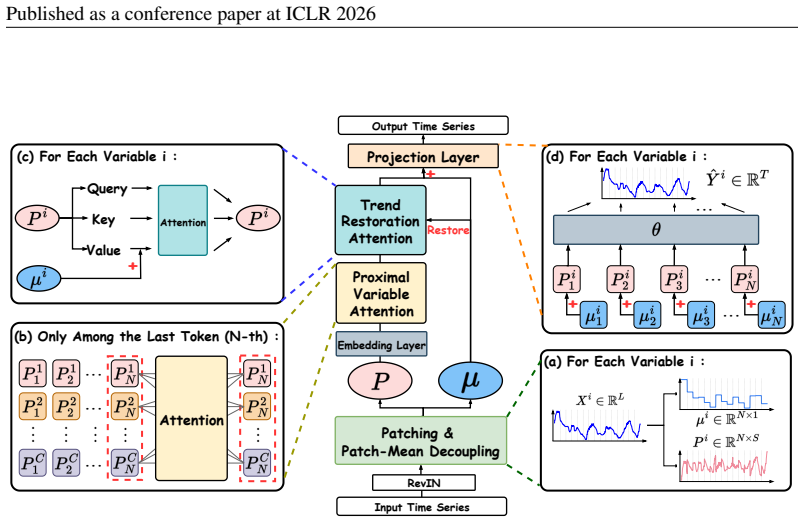
The central claim is that subtracting the mean of each patch preserves the original structure sufficiently for the attention mechanism to capture true shape similarities without scale interference, and that combining this with trend restoration attention and proximal variable attention enables effective modeling of long-range dependencies and cross-variable relationships in long-term forecasting.
What carries the argument
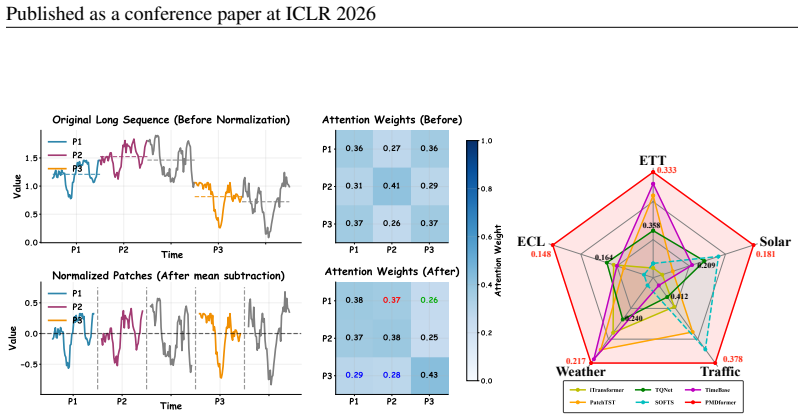
Patch-mean decoupling (PMD), which subtracts the mean value from each patch to separate trend and residual shape information so attention can focus on shape similarities.
If this is right
- Forecasting models become less sensitive to scale variations across different patches and variables.
- Trend information can be reintegrated inside the attention calculation rather than treated as a separate preprocessing step.
- Cross-variable correlations are modeled only on recent segments, limiting the influence of outdated relationships.
- Long-range dependencies are captured more reliably because shape matching operates on normalized residuals.
Where Pith is reading between the lines
- Similar mean-subtraction steps could be tested in other sequence tasks where scale differences mask pattern matches.
- The proximal attention design may prove useful in streaming or online forecasting where older data loses relevance.
- The approach could be extended to series with strong seasonality by checking whether mean subtraction interacts with periodic components.
Load-bearing premise
Subtracting the mean of each patch preserves the original structure sufficiently for the attention mechanism to capture true shape similarities without introducing artifacts or losing critical scale information.
What would settle it
If removing the mean-subtraction step from PMDformer causes it to lose its accuracy and stability gains on the same LTSF benchmarks, the decoupling step would be shown to be non-essential.
Figures
read the original abstract
Long-term time series forecasting (LTSF) plays a crucial role in fields such as energy management, finance, and traffic prediction. Transformer-based models have adopted patch-based strategies to capture long-range dependencies, but accurately modeling shape similarities across patches and variables remains challenging due to scale differences. To address this, we introduce patch-mean decoupling (PMD), which separates the trend and residual shape information by subtracting the mean of each patch, preserving the original structure and ensuring that the attention mechanism captures true shape similarities. Futhermore, to more effectively model long-range dependencies and capture cross-variable relationships, we propose Trend Restoration Attention (TRA) and Proximal Variable Attention (PVA). The former module reintegrates the decoupled trend from PMD while calculating attention output. And the latter focuses cross-variable attention on the most relevant, recent time segments to avoid overfitting on outdated correlations. Combining these components, we propose PMDformer, a model designed to effectively capture shape similarity in long-term forecasting scenarios. Extensive experiments indicate that PMDformer outperforms existing state-of-the-art methods in stability and accuracy across multiple LTSF benchmarks. The code is available at https://github.com/aohu1105/PMDformer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PMDformer, a Transformer architecture for long-term time series forecasting. It introduces patch-mean decoupling (PMD) that subtracts the per-patch mean to separate trend from residual shape information so that attention can focus on shape similarity independent of scale; Trend Restoration Attention (TRA) that reintegrates the removed means during attention computation; and Proximal Variable Attention (PVA) that restricts cross-variable attention to the most recent segments. The central empirical claim is that the resulting model outperforms prior state-of-the-art methods in both accuracy and stability across standard LTSF benchmarks, with code released at the cited GitHub repository.
Significance. If the reported gains prove robust, the work offers a lightweight, interpretable mechanism for handling scale mismatches that commonly degrade patch-based attention in non-stationary series. The public code release is a clear positive for reproducibility. The significance is tempered by the absence of any analytic or synthetic validation that the mean-subtraction step preserves diagnostically relevant shape information.
major comments (2)
- [§3.2] §3.2 (PMD definition): the claim that subtracting the patch mean 'preserves the original structure' and lets attention capture 'true shape similarities' is load-bearing for the outperformance narrative, yet the manuscript supplies neither a frequency-domain comparison, an information-loss bound, nor a controlled synthetic experiment showing that zero-crossing patterns, relative amplitudes, and trend slopes remain invariant under this non-linear per-patch operation.
- [§4] §4 (experimental validation): the abstract asserts that 'extensive experiments indicate … outperformance … in stability and accuracy,' but the manuscript does not report ablation results that isolate the contribution of PMD versus TRA versus PVA, nor does it provide error bars or statistical significance tests on the benchmark tables; without these, it is impossible to determine whether the claimed gains are attributable to the proposed decoupling or to other modeling choices.
minor comments (1)
- [Abstract] Abstract: 'Futhermore' is a typographical error.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [§3.2] §3.2 (PMD definition): the claim that subtracting the patch mean 'preserves the original structure' and lets attention capture 'true shape similarities' is load-bearing for the outperformance narrative, yet the manuscript supplies neither a frequency-domain comparison, an information-loss bound, nor a controlled synthetic experiment showing that zero-crossing patterns, relative amplitudes, and trend slopes remain invariant under this non-linear per-patch operation.
Authors: We agree that additional validation would strengthen the justification. Mean subtraction is a linear operation that removes the DC component per patch. In the revision we will add a controlled synthetic experiment demonstrating preservation of zero-crossings, relative amplitudes, and local slopes. We will also include a frequency-domain discussion showing retention of higher-frequency shape information. A formal analytic bound for the full attention pipeline is non-trivial to derive, but the synthetic results will directly address the core empirical concern. revision: yes
-
Referee: [§4] §4 (experimental validation): the abstract asserts that 'extensive experiments indicate … outperformance … in stability and accuracy,' but the manuscript does not report ablation results that isolate the contribution of PMD versus TRA versus PVA, nor does it provide error bars or statistical significance tests on the benchmark tables; without these, it is impossible to determine whether the claimed gains are attributable to the proposed decoupling or to other modeling choices.
Authors: We acknowledge that isolating component contributions and providing statistical support are necessary. In the revised manuscript we will add ablation studies that remove PMD, TRA, and PVA individually while keeping other elements fixed. We will also rerun all benchmarks with multiple random seeds, report means and standard deviations as error bars, and include paired statistical significance tests on the main results. revision: yes
Circularity Check
No circularity detected; claims rest on external benchmarks
full rationale
The paper presents PMD, TRA, and PVA as novel architectural modules whose motivation is stated in prose without equations. The performance claim is supported solely by comparisons to external SOTA methods on LTSF benchmarks. No derivation, fitted parameter, or self-citation is shown to reduce any reported result to an input quantity defined by the model itself. The central argument therefore remains independent of the patterns that would trigger a circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transformer attention mechanisms can capture shape similarities once scale differences are removed by mean subtraction.
Reference graph
Works this paper leans on
-
[1]
Peng Chen, Yingying Zhang, Yunyao Cheng, Yang Shu, Yihang Wang, Qingsong Wen, Bin Yang, and Chenjuan Guo. Pathformer: Multi-scale transformers with adaptive pathways for time series forecasting.arXiv preprint arXiv:2402.05956,
-
[2]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[3]
Emadeldeen Eldele, Mohamed Ragab, Zhenghua Chen, Min Wu, and Xiaoli Li. Tslanet: Rethinking transformers for time series representation learning.arXiv preprint arXiv:2404.08472,
-
[4]
Zeying Gong, Yujin Tang, and Junwei Liang. Patchmixer: A patch-mixing architecture for long-term time series forecasting.arXiv preprint arXiv:2310.00655,
-
[5]
Attention based spatial- temporal graph convolutional networks for traffic flow forecasting.Proceedings of the AAAI Conference on Artificial Intelligence,
10 Published as a conference paper at ICLR 2026 Shengnan Guo, Youfang Lin, Ning Feng, Chao Song, and Huaiyu Wan. Attention based spatial- temporal graph convolutional networks for traffic flow forecasting.Proceedings of the AAAI Conference on Artificial Intelligence,
2026
-
[6]
Lu Han, Xu-Yang Chen, Han-Jia Ye, and De-Chuan Zhan. Softs: Efficient multivariate time series forecasting with series-core fusion.arXiv preprint arXiv:2404.14197, 2024a. Lu Han, Han-Jia Ye, and De-Chuan Zhan. Sin: Selective and interpretable normalization for long- term time series forecasting. InForty-first International Conference on Machine Learning, ...
-
[7]
FinTSB: A Comprehensive and Practical Benchmark for Financial Time Series Forecasting
Ao Hu, Liangjian Wen, Yong Dai, Shiyi Qi, Jun Wang, Zhi Chen, Xun Zhou, Dongkai Wang, Zenglin Xu, and Jiang Duan. Timecnn: Refining cross-variable interaction on time point for time series forecasting.Neural Networks, 2025a. Ao Hu, Liangjian Wen, Jiang Duan, Yong Dai, Dongkai Wang, Shudong Huang, Jun Wang, and Zenglin Xu. Fdnet: High-frequency disentangle...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Y Zhang, Xiaoming Shi, Pin-Yu Chen, Yux- uan Liang, Yuan-Fang Li, Shirui Pan, et al. Time-llm: Time series forecasting by reprogramming large language models.arXiv preprint arXiv:2310.01728,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Revisiting Long-term Time Series Forecasting: An Investigation on Linear Mapping
Zhe Li, Shiyi Qi, Yiduo Li, and Zenglin Xu. Revisiting long-term time series forecasting: An investigation on linear mapping.arXiv preprint arXiv:2305.10721,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Pyraformer: Low-complexity pyramidal attention for long-range time series modeling and fore- casting
11 Published as a conference paper at ICLR 2026 Shizhan Liu, Hang Yu, Cong Liao, Jianguo Li, Weiyao Lin, Alex X Liu, and Schahram Dustdar. Pyraformer: Low-complexity pyramidal attention for long-range time series modeling and fore- casting. InICLR, 2022a. Xu Liu, Yutong Xia, Yuxuan Liang, Junfeng Hu, Yiwei Wang, Lei Bai, Chao Huang, Zhenguang Liu, Bryan H...
-
[12]
Xiangfei Qiu, Jilin Hu, Lekui Zhou, Xingjian Wu, Junyang Du, Buang Zhang, Chenjuan Guo, Aoy- ing Zhou, Christian S Jensen, Zhenli Sheng, et al. Tfb: Towards comprehensive and fair bench- marking of time series forecasting methods.arXiv preprint arXiv:2403.20150,
-
[13]
Deep Time Series Models: A Comprehensive Survey and Benchmark
Shiyu Wang, Haixu Wu, Xiaoming Shi, Tengge Hu, Huakun Luo, Lintao Ma, James Y Zhang, and JUN ZHOU. Timemixer: Decomposable multiscale mixing for time series forecasting. In International Conference on Learning Representations (ICLR), 2024a. Yuxuan Wang, Haixu Wu, Jiaxiang Dong, Yong Liu, Mingsheng Long, and Jianmin Wang. Deep time series models: A compreh...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Unified training of universal time series forecasting transformers
12 Published as a conference paper at ICLR 2026 Gerald Woo, Chenghao Liu, Akshat Kumar, Caiming Xiong, Silvio Savarese, and Doyen Sahoo. Unified training of universal time series forecasting transformers. InICML,
2026
-
[15]
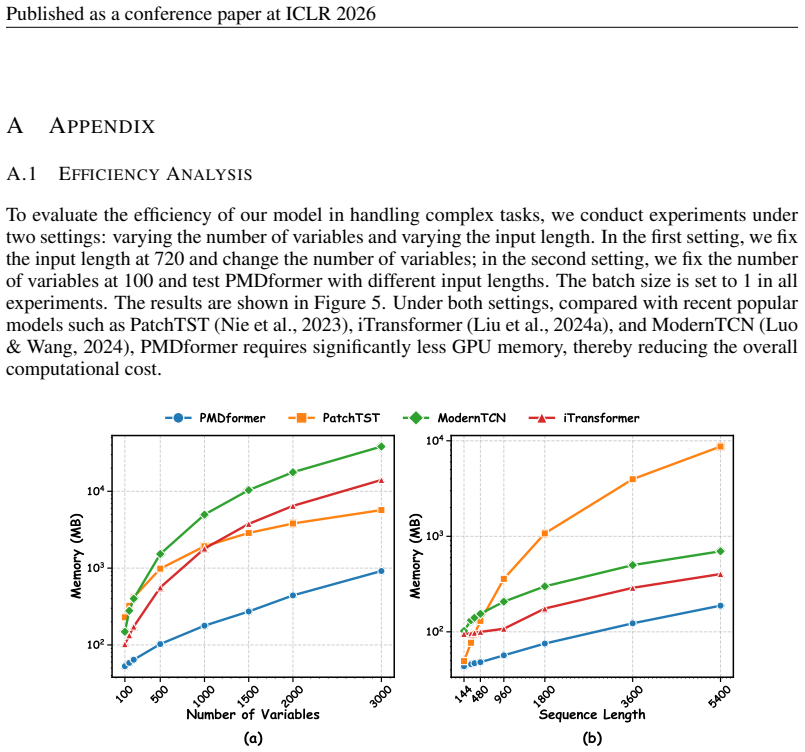
13 Published as a conference paper at ICLR 2026 A APPENDIX A.1 EFFICIENCYANALYSIS To evaluate the efficiency of our model in handling complex tasks, we conduct experiments under two settings: varying the number of variables and varying the input length. In the first setting, we fix the input length at 720 and change the number of variables; in the second ...
2026
-
[16]
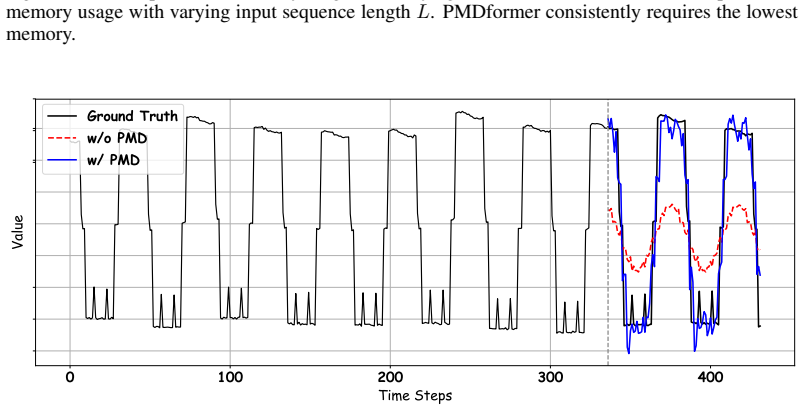
Under both settings, compared with recent popular models such as PatchTST (Nie et al., 2023), iTransformer (Liu et al., 2024a), and ModernTCN (Luo & Wang, 2024), PMDformer requires significantly less GPU memory, thereby reducing the overall computational cost. /uni00000014/uni00000013/uni00000013/uni00000018/uni00000013/uni00000013/uni00000014/uni00000013...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.