Diagnosing Task Insensitivity in Language Agents
Pith reviewed 2026-06-26 04:56 UTC · model grok-4.3
The pith
Language agents keep repeating training actions even when task instructions are changed or corrupted.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
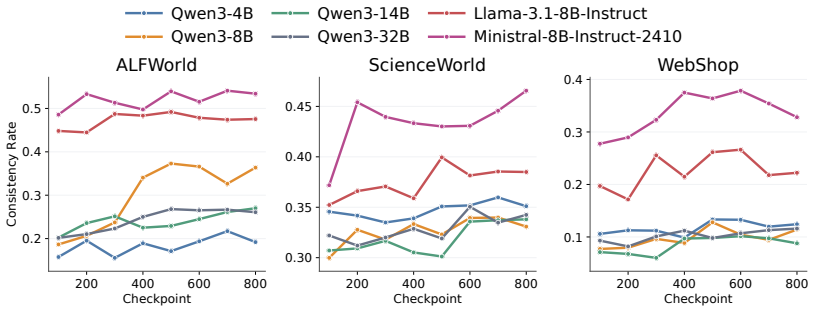
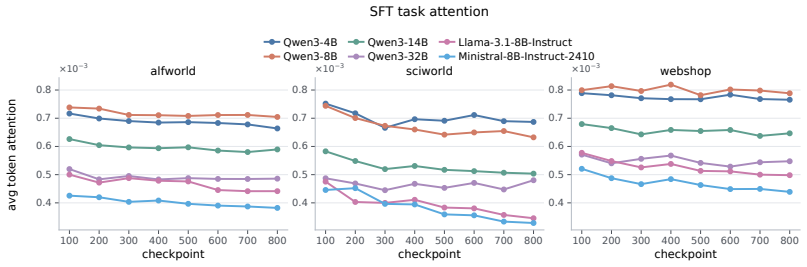
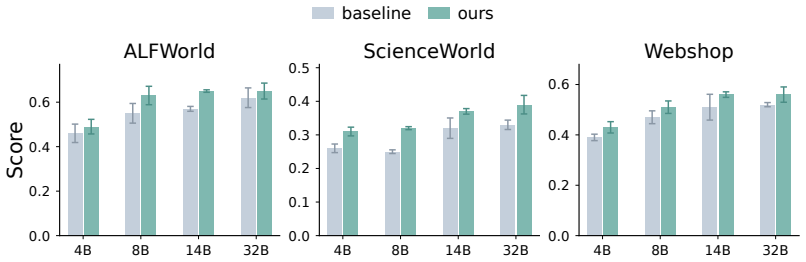
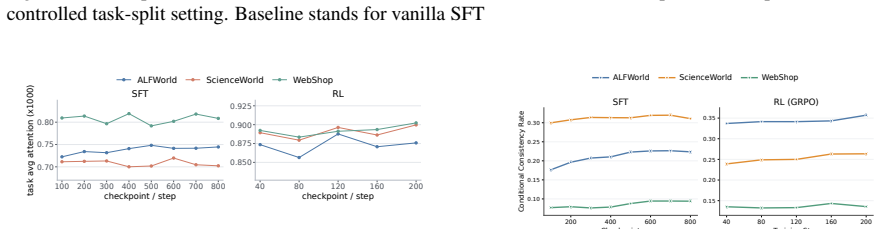
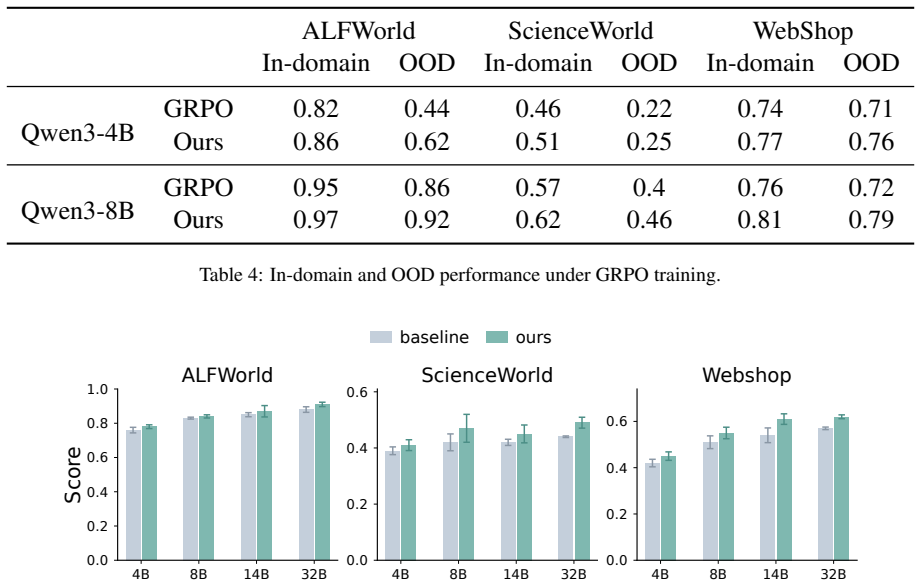
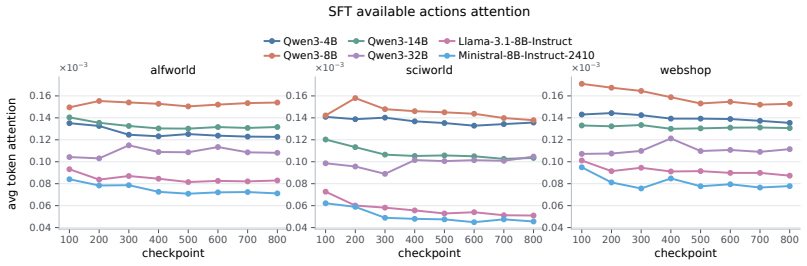
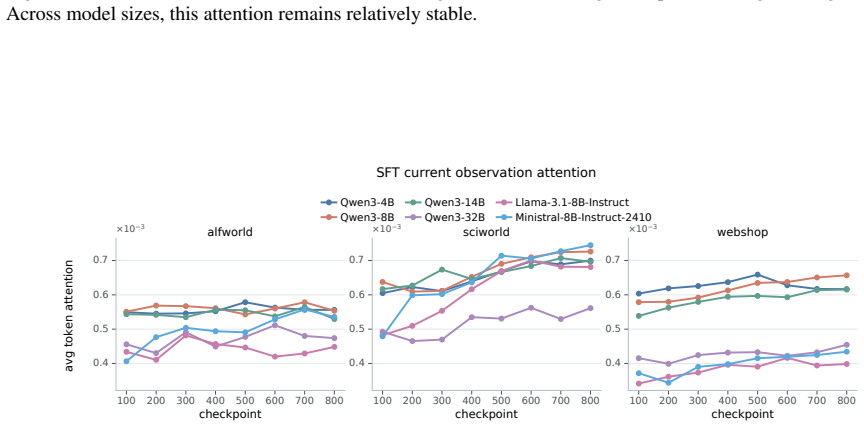
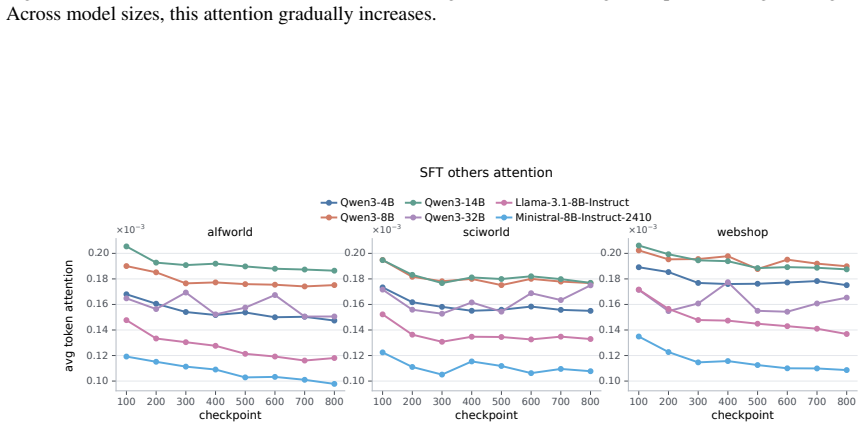
Models exhibit task insensitivity by continuing actions aligned with the original task even when the instruction is semantically corrupted and cannot be directly answered, and by outputting the same action when the task description is replaced with a similar but distinct one. This is accompanied by consistent training-time attention drift away from task tokens toward local observations. Task-Perturbed NLL Optimization, a lightweight contrastive regularizer, explicitly encourages action dependence on the task instruction and improves task sensitivity and OOD generalization while preserving more stable attention to task tokens.
What carries the argument
Task-Perturbed NLL Optimization, a contrastive regularizer added to training that perturbs the task description to force the model's actions to depend on the current instruction rather than on learned shortcuts.
If this is right
- Agents will change their actions when the task instruction changes, rather than defaulting to training patterns.
- Attention weights will remain higher on task tokens throughout training and inference.
- Out-of-distribution performance on related but non-identical tasks will rise while in-distribution performance stays stable.
- Shortcut learning that ignores instruction semantics will decrease in long-horizon agent settings.
Where Pith is reading between the lines
- The same attention-drift pattern may appear in other instruction-following domains such as code generation or tool use when prompts are varied.
- Tracking attention on instruction tokens during training could provide an early diagnostic for generalization risk before deployment.
- Applying similar perturbations to other prompt sections, such as history or observations, might further reduce reliance on local cues.
Load-bearing premise
The observed attention drift is the direct cause of task insensitivity, and adding the contrastive regularizer will increase dependence on task tokens without creating new failure modes.
What would settle it
A controlled test in which the regularizer is applied but task sensitivity on held-out similar tasks does not increase or attention on task tokens decreases further.
Figures

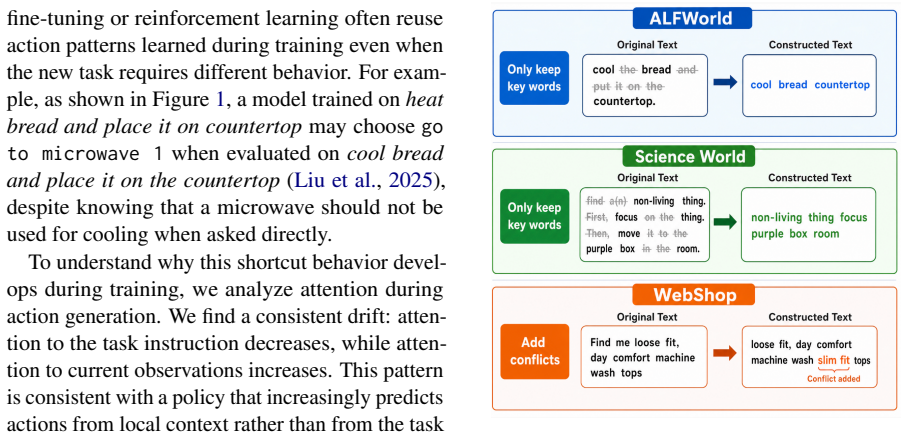
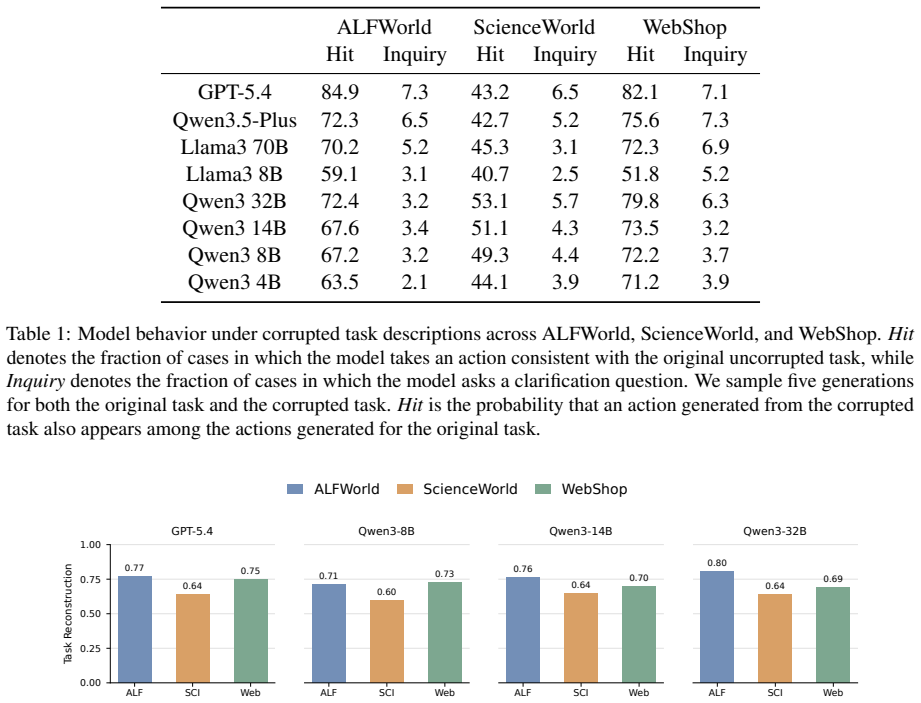
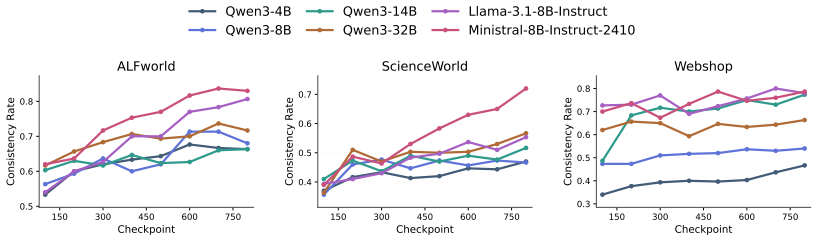
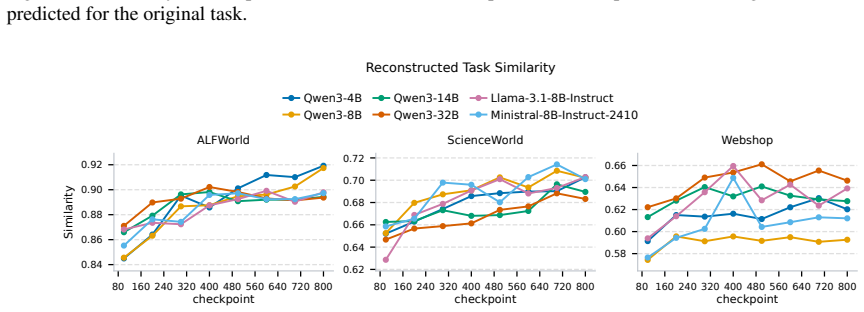
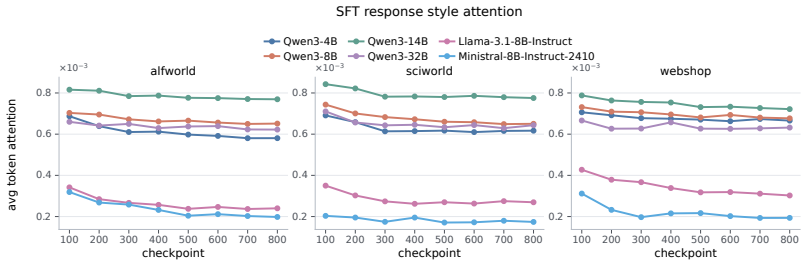
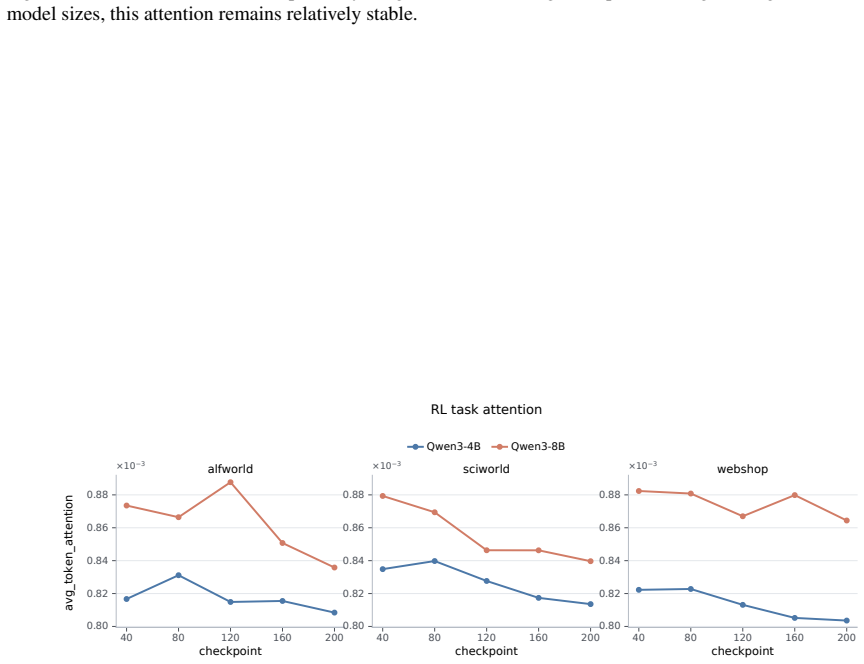
read the original abstract
Large language models can serve as capable long-horizon agents, but their out-of-distribution (OOD) generalization remains weak. We identify a key source of this failure as task insensitivity: when faced with similar but distinct tasks, models might apply patterns learned during training and fail to solve the task at hand. We show that models often continue with actions aligned with the original task even when the instruction is semantically corrupted and cannot be directly answered. We further find that, when we replace the task description in a trained prompt with another similar but distinct task, the model may still output the same action. This behavior is accompanied by a consistent training-time attention drift away from task tokens and toward local observations, suggesting an optimization bias toward shortcuts. To mitigate this problem, we propose Task-Perturbed NLL Optimization, a lightweight contrastive regularizer that explicitly encourages action dependence on the task instruction. Extensive evaluations show that our intervention improves task sensitivity and OOD generalization while preserving more stable attention to task tokens.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that task insensitivity—persistent execution of training-task actions despite semantically corrupted or swapped instructions—is a key driver of weak OOD generalization in LLM agents. It reports that this behavior co-occurs with training-time attention drift away from task tokens toward local observations, interprets the drift as evidence of an optimization bias toward shortcuts, and introduces Task-Perturbed NLL Optimization (a contrastive regularizer) to enforce action dependence on the task description. The abstract states that extensive evaluations demonstrate improved task sensitivity, OOD generalization, and more stable task-token attention.
Significance. If the quantitative results and controls hold, the work supplies a concrete diagnostic lens and a lightweight mitigation for shortcut learning in long-horizon agents, an issue that limits deployment reliability. The explicit linkage of attention patterns to behavioral failure modes and the proposal of a contrastive regularizer that can be added to existing NLL training are potentially useful contributions.
major comments (3)
- [Abstract] Abstract: the central diagnosis treats the observed attention drift as evidence of a causal optimization bias toward shortcuts, yet the text only describes the drift as 'consistent' and 'suggesting' bias. No intervention (e.g., attention masking or forced re-weighting of task tokens) is reported that would test whether preventing the drift reduces task insensitivity, leaving the causal claim unsupported.
- [Experiments section] Experiments / evaluation section: the claim that Task-Perturbed NLL Optimization improves OOD generalization rests on the assumption that explicitly increasing task-token dependence fixes the root cause without new failure modes. No ablations are described that compare against other regularizers, measure side effects on in-distribution performance, or test whether the regularizer merely masks symptoms rather than addressing the underlying insensitivity.
- [Abstract] Abstract and method description: the paper asserts 'extensive evaluations' but supplies no quantitative metrics, dataset sizes, baseline comparisons, error bars, or statistical tests in the provided summary. Without these details it is impossible to assess whether the reported improvements in task sensitivity are robust or merely consistent with the untested causality assumption.
minor comments (1)
- [Method] Notation for the contrastive regularizer (Task-Perturbed NLL) should be defined with an explicit loss equation rather than described only in prose.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below with honest responses based on the current manuscript and indicate planned revisions where the concerns are valid.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central diagnosis treats the observed attention drift as evidence of a causal optimization bias toward shortcuts, yet the text only describes the drift as 'consistent' and 'suggesting' bias. No intervention (e.g., attention masking or forced re-weighting of task tokens) is reported that would test whether preventing the drift reduces task insensitivity, leaving the causal claim unsupported.
Authors: The manuscript uses 'suggesting' and 'consistent with' precisely to avoid claiming direct causality; the drift is reported as an observed co-occurrence with task insensitivity. No attention-level intervention (such as masking) was performed, as the work centers on behavioral diagnosis and a training-time regularizer rather than mechanistic interventions on attention. We agree this leaves the causal interpretation open and will revise the abstract and discussion to explicitly label the link as correlational, adding a limitations paragraph noting the absence of such interventions. revision: partial
-
Referee: [Experiments section] Experiments / evaluation section: the claim that Task-Perturbed NLL Optimization improves OOD generalization rests on the assumption that explicitly increasing task-token dependence fixes the root cause without new failure modes. No ablations are described that compare against other regularizers, measure side effects on in-distribution performance, or test whether the regularizer merely masks symptoms rather than addressing the underlying insensitivity.
Authors: The current experiments compare the proposed regularizer only against standard NLL training and do not include ablations against alternative regularizers, in-distribution side-effect measurements, or explicit tests for symptom masking versus root-cause mitigation. These omissions constitute a genuine gap. We will add the requested ablations in revision, including comparisons to other contrastive losses, in-distribution performance tables, and controls that vary task perturbation strength. revision: yes
-
Referee: [Abstract] Abstract and method description: the paper asserts 'extensive evaluations' but supplies no quantitative metrics, dataset sizes, baseline comparisons, error bars, or statistical tests in the provided summary. Without these details it is impossible to assess whether the reported improvements in task sensitivity are robust or merely consistent with the untested causality assumption.
Authors: The abstract is intentionally high-level; the full manuscript contains the quantitative results, dataset sizes, baselines, error bars, and statistical tests in the experiments section. To address the concern, we will expand the abstract with key numerical results (e.g., task-sensitivity deltas and OOD gains) while keeping it concise. revision: yes
Circularity Check
No circularity; empirical observations and regularizer proposal are independent of inputs
full rationale
The paper's core argument rests on empirical demonstrations of task insensitivity (persistent actions under corrupted/swapped instructions) and observed attention drift during training, followed by introduction of a contrastive regularizer (Task-Perturbed NLL Optimization) motivated by those observations and supported by reported evaluations. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the abstract or described content. The derivation chain does not reduce any claim to its own inputs by construction; the diagnosis and mitigation are presented as data-driven rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
GPT-4 techni- cal report.arXiv preprint arXiv:2303.08774. Hao Bai, Yifei Zhou, Jiayi Pan, Mert Cemri, Alane Suhr, Sergey Levine, and Aviral Kumar
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Qwen technical report. arXiv preprint arXiv:2309.16609. Kevin Chen, Marco Cusumano-Towner, Brody Hu- val, Aleksei Petrenko, Jackson Hamburger, Vladlen Koltun, and Philipp Krähenbühl
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
arXiv preprint arXiv:2502.01600
Reinforce- ment learning for long-horizon interactive llm agents. arXiv preprint arXiv:2502.01600. Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma
-
[4]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
SFT mem- orizes, RL generalizes: A comparative study of foundation model post-training.arXiv preprint arXiv:2501.17161. Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A. Wichmann
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948. Divyansh Kaushik, Eduard Hovy, and Zachary C. Lip- ton
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Gra- dient coupling: The hidden barrier to generalization in agentic reinforcement learning.arXiv preprint arXiv:2509.23870. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and 1 others
-
[7]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300. Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
ALFWorld: Aligning text and em- bodied environments for interactive learning.arXiv preprint arXiv:2010.03768. Rui Song, Yingji Li, Lida Shi, Fausto Giunchiglia, and Hao Xu
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[9]
Zechen Sun, Yisheng Xiao, Juntao Li, Yixin Ji, Wen- liang Chen, and Min Zhang
Shortcut learning in in-context learn- ing: a survey.arXiv preprint arXiv:2411.02018. Zechen Sun, Yisheng Xiao, Juntao Li, Yixin Ji, Wen- liang Chen, and Min Zhang
-
[10]
InProceedings of the 2024 joint in- ternational conference on computational linguistics, language resources and evaluation (LREC-COLING 2024), pages 6883–6893
Exploring and mitigating shortcut learning for generative large lan- guage models. InProceedings of the 2024 joint in- ternational conference on computational linguistics, language resources and evaluation (LREC-COLING 2024), pages 6883–6893. Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, ...
2024
-
[11]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530. Victor Veitch, Alexander D’Amour, Steve Yadlowsky, and Jacob Eisenstein
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Ruoyao Wang, Peter Jansen, Marc-Alexandre Côté, and Prithviraj Ammanabrolu
RLVer: Reinforcement learning with verifiable emo- tion rewards for empathetic agents.arXiv preprint arXiv:2507.03112. Ruoyao Wang, Peter Jansen, Marc-Alexandre Côté, and Prithviraj Ammanabrolu
-
[13]
ScienceWorld: Is your agent smarter than a 5th grader?arXiv preprint arXiv:2203.07540. 9 Shuai Wang, Weiwen Liu, Jingxuan Chen, Yuqi Zhou, Weinan Gan, Xingshan Zeng, Yuhan Che, Shuai Yu, Xinlong Hao, Kun Shao, and 1 others
-
[14]
arXiv preprint arXiv:2411.04890 , year=
GUI agents with foundation models: A comprehensive survey.arXiv preprint arXiv:2411.04890. Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi
-
[15]
WebAgent-R1: Training web agents via end-to-end multi-turn reinforcement learning.arXiv preprint arXiv:2505.16421. Tianyi Yan, Fei Wang, James Y Huang, Wenxuan Zhou, Fan Yin, Aram Galstyan, Wenpeng Yin, and Muhao Chen
-
[16]
InFind- ings of the Association for Computational Linguistics: ACL 2024, pages 10288–10302
Contrastive instruction tuning. InFind- ings of the Association for Computational Linguistics: ACL 2024, pages 10288–10302. Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan
2024
-
[17]
arXiv preprint arXiv:2207.01206
WebShop: Towards scalable real- world web interaction with grounded language agents. arXiv preprint arXiv:2207.01206. Aohan Zeng, Mingdao Liu, Rui Lu, Bowen Wang, Xiao Liu, Yuxiao Dong, and Jie Tang
-
[18]
AgentTuning : Enabling generalized agent abilities for LLMs
AgentTuning: Enabling generalized agent abilities for LLMs.arXiv preprint arXiv:2310.12823. Kechi Zhang, Jia Li, Ge Li, Xianjie Shi, and Zhi Jin
-
[19]
Zijing Zhang, Ziyang Chen, Mingxiao Li, Zhaopeng Tu, and Xiaolong Li
CodeAgent: Enhancing code gener- ation with tool-integrated agent systems for real- world repo-level coding challenges.arXiv preprint arXiv:2401.07339. Zijing Zhang, Ziyang Chen, Mingxiao Li, Zhaopeng Tu, and Xiaolong Li
-
[20]
Yifei Zhou, Andrea Zanette, Jiayi Pan, Sergey Levine, and Aviral Kumar
RLVMR: Reinforce- ment learning with verifiable meta-reasoning re- wards for robust long-horizon agents.arXiv preprint arXiv:2507.22844. Yifei Zhou, Andrea Zanette, Jiayi Pan, Sergey Levine, and Aviral Kumar
-
[21]
10 LLM usage We use LLMs to polish the paper and help create figures
Archer: Training language model agents via hierarchical multi-turn rl.arXiv preprint arXiv:2402.19446. 10 LLM usage We use LLMs to polish the paper and help create figures. A Additional Experimental Details This appendix is organized into four parts. We first summarize additional experimental details, then provide supplementary theoretical analysis, imple...
-
[22]
reconstruction_label
For ALFWorld and Science- World, we follow the OOD splits of Zhang et al. (2025). In ALFWorld, we designate Cool & Place and Pick Two & Place as held-out task types. In ScienceWorld, we reserve the final task type of each topic for OOD evaluation. For WebShop, we treat product categories as task types and randomly designate 30% of the categories as OOD, u...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.