Automated Creativity Evaluation of Language Models Across Open-Ended Tasks
Pith reviewed 2026-06-27 09:52 UTC · model grok-4.3
The pith
An automated framework evaluates LLM creativity across any open-ended task by separating measurement from the task itself.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
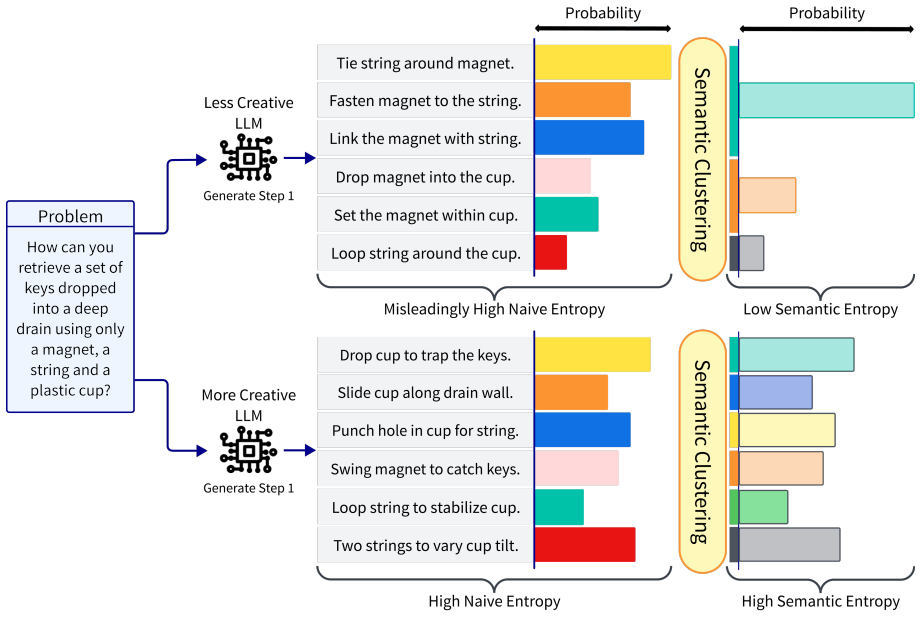
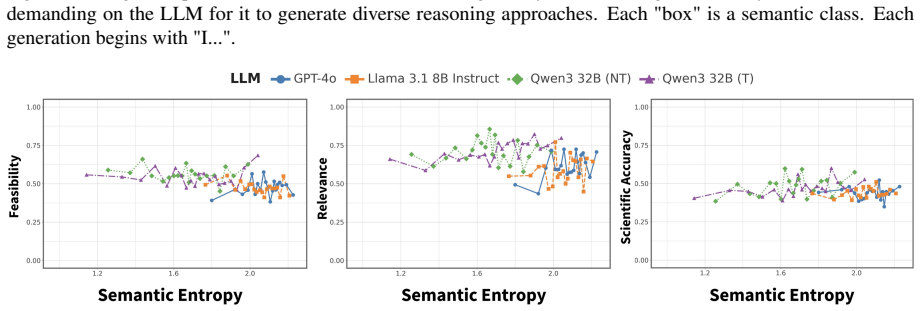
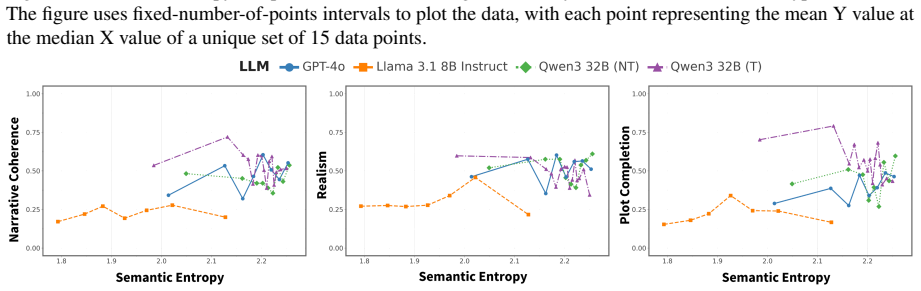
The central claim is that creativity in LLMs can be quantified in a task-agnostic way by combining semantic entropy for novelty and diversity with a retrieval-based multi-agent judge for context-sensitive task fulfilment, and that this combination reliably tracks these facets while exposing effects of model properties across problem-solving, ideation, and writing tasks.
What carries the argument
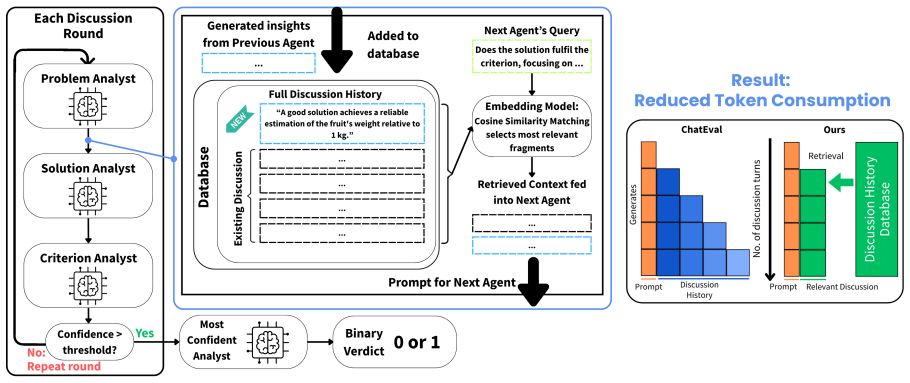
The domain-agnostic framework that decouples the measurement apparatus from the creative task, using semantic entropy to quantify divergent creativity and a retrieval-based multi-agent judge to assess convergent task fulfilment.
If this is right
- The same metrics apply to new open-ended tasks without redesign.
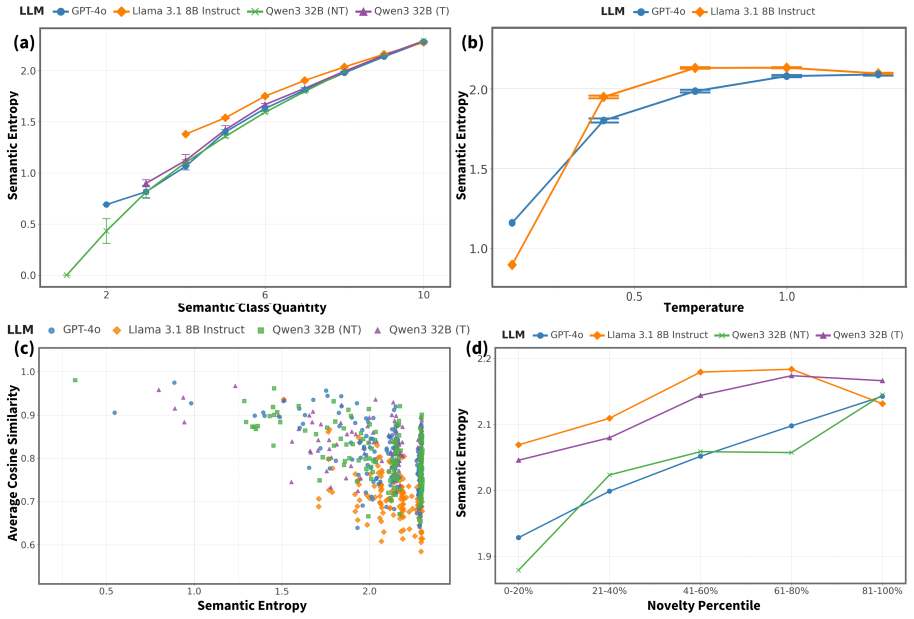
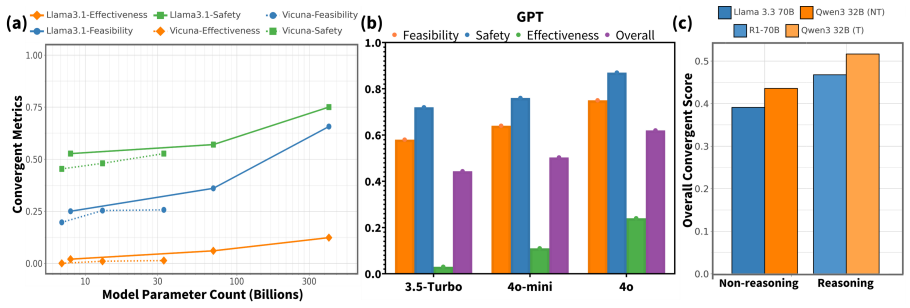
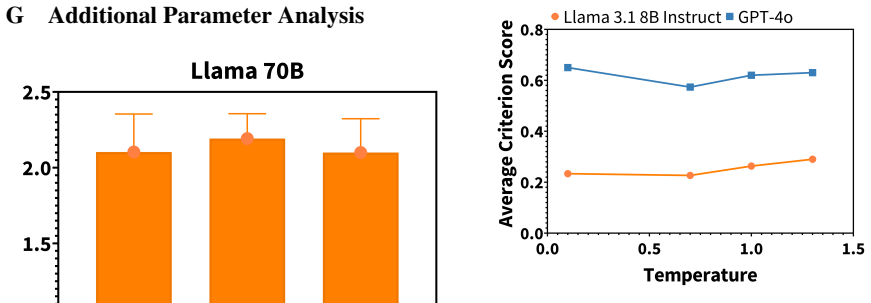
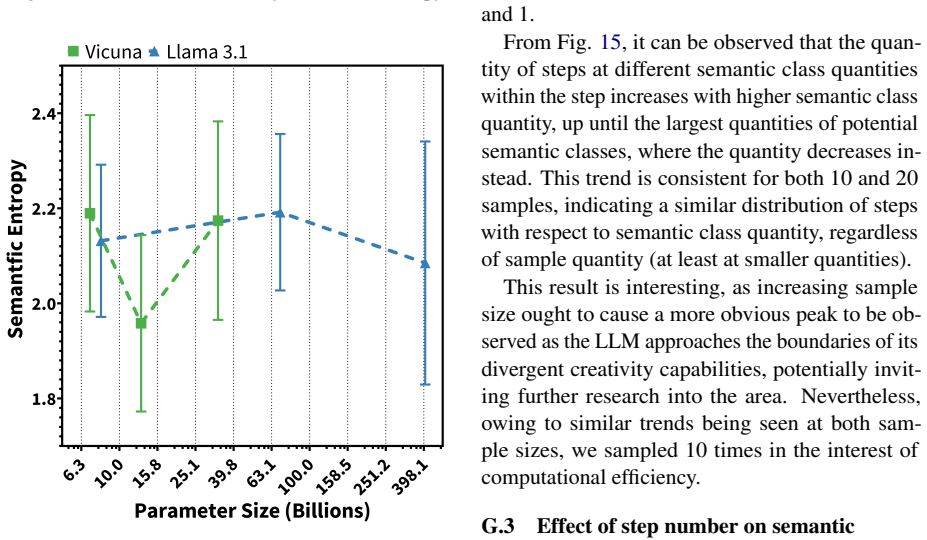
- Model size, temperature, recency, and reasoning produce measurable differences in creative performance.
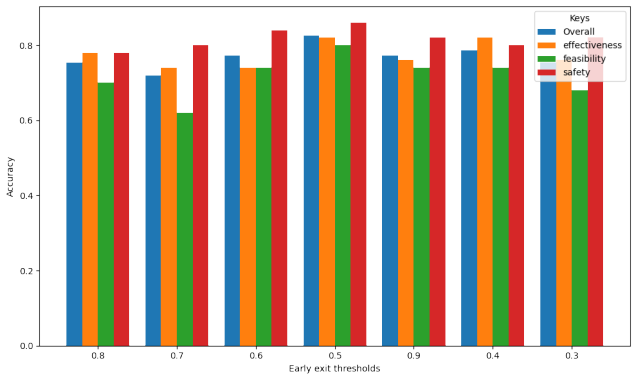
- The multi-agent judge reduces evaluation time by over 60 percent compared with prior methods.
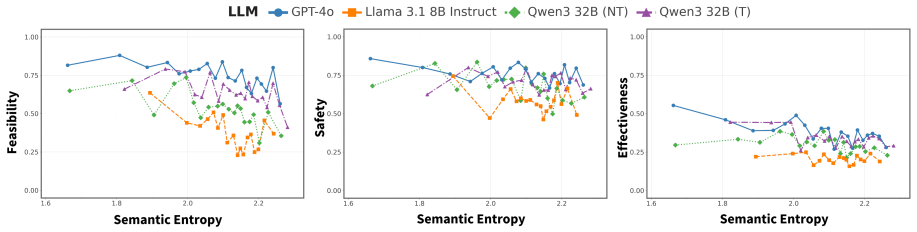
- Semantic entropy aligns with human annotations and existing diversity baselines.
- The approach supports reproducible benchmarking of creative capabilities across models.
Where Pith is reading between the lines
- The separation of measurement from task could extend the same metrics to evaluate creativity in code generation or image captioning without new tuning.
- Large-scale comparisons of creative output across dozens of models become feasible if the metrics remain stable.
- Training objectives might target the specific facets tracked by entropy and the judge to improve selected aspects of creativity.
Load-bearing premise
Semantic entropy supplies a robust reference-free metric for novelty and diversity that matches human judgments, and the retrieval-based multi-agent judge accurately evaluates task fulfilment.
What would settle it
Human raters show low correlation with semantic entropy scores on novelty for a new collection of model outputs, or expert assessments of task fulfilment diverge from the multi-agent judge scores in an additional domain.
Figures

read the original abstract
Large language models (LLMs) have achieved remarkable progress in language understanding, reasoning, and generation, sparking growing interest in their creative potential. Realizing this potential requires systematic and scalable methods for evaluating creativity across diverse tasks. However, most existing creativity metrics are tightly coupled to specific tasks, embedding domain assumptions into the evaluation process, and limiting scalability and generality. To address this gap, we introduce an automated, domain-agnostic framework for quantifying LLM creativity across open-ended tasks. Our approach separates the measurement apparatus from the creative task itself, enabling scalable, task-agnostic assessment. Divergent creativity is measured using semantic entropy, a reference-free and robust metric for novelty and diversity, validated against human annotations, LLM-based novelty judgments and baseline diversity measures. Convergent creativity is assessed via a novel retrieval-based multi-agent judge framework that delivers context-sensitive evaluation of task fulfilment with over 60% improved efficiency. We validate our framework in three qualitatively distinct domains: problem-solving (MacGyver), research ideation (HypoGen), and creative writing (BookMIA), using a broad suite of LLMs. Empirical results show that our framework reliably captures key facets of creativity, including novelty, diversity, and task fulfilment, and reveal how model properties, such as size, temperature, recency, and reasoning, impact creative performance. Our work establishes a reproducible and generalizable standard for automated LLM creativity evaluation, paving the way for scalable benchmarking and accelerating progress in creative AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
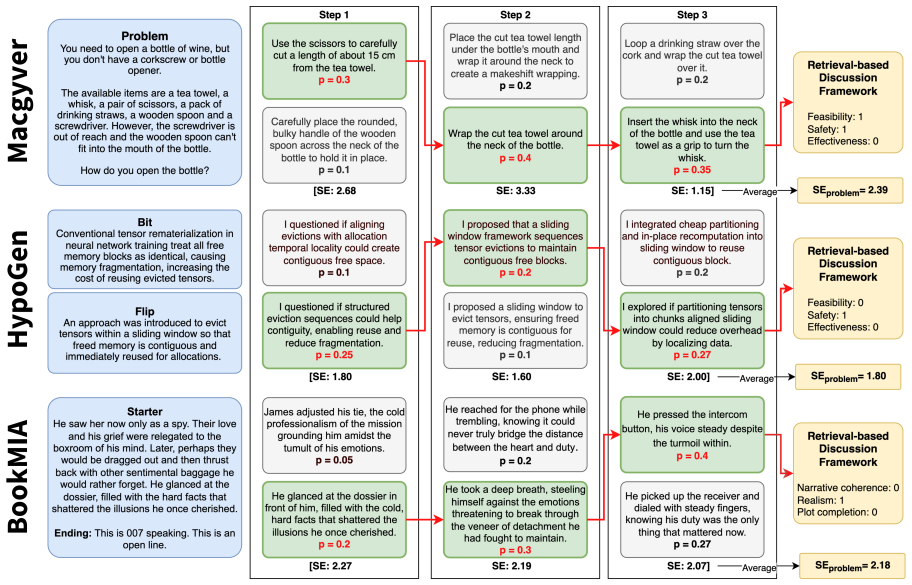
Summary. The manuscript introduces an automated, domain-agnostic framework for quantifying LLM creativity across open-ended tasks. Divergent creativity is measured via semantic entropy as a reference-free metric for novelty and diversity, validated against human annotations, LLM novelty judgments, and baseline diversity measures. Convergent creativity is assessed with a retrieval-based multi-agent judge for context-sensitive task fulfilment, claiming over 60% efficiency gains. The framework is validated across three domains (MacGyver for problem-solving, HypoGen for research ideation, BookMIA for creative writing) using multiple LLMs, with results on how model size, temperature, recency, and reasoning affect performance. The work positions itself as establishing a reproducible, generalizable standard for automated creativity evaluation.
Significance. If the described validations hold, the work is significant for advancing scalable creativity assessment in LLMs by decoupling the measurement apparatus from specific tasks, a clear strength that addresses limitations of prior task-coupled metrics. The multi-domain empirical results and analysis of model properties add value for understanding creative performance. The emphasis on reference-free metrics and reproducibility through validation protocols is a positive contribution to the field.
minor comments (2)
- [Abstract] Abstract: the claim of 'over 60% improved efficiency' for the multi-agent judge requires an explicit statement of the baseline comparator and measurement protocol (e.g., wall-clock time or token count) to allow readers to assess the figure.
- [Abstract] Abstract: the three domains are described as 'qualitatively distinct' without a short justification of the dimensions of distinctness (e.g., convergent vs. divergent demands or output modalities); adding one sentence would strengthen the generality argument.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our manuscript and the recommendation for minor revision. We are encouraged by the recognition that the domain-agnostic framework, reference-free metrics, and multi-domain validations represent a meaningful contribution to scalable LLM creativity assessment.
Circularity Check
No significant circularity in derivation chain
full rationale
The abstract and provided text describe a framework using semantic entropy for divergent creativity (validated externally against human annotations, LLM judgments, and baseline diversity measures) and a retrieval-based multi-agent judge for convergent creativity. No equations, fitted parameters renamed as predictions, or self-citation chains are shown that reduce any claimed result to its inputs by construction. The separation of measurement from task and empirical validations across domains (MacGyver, HypoGen, BookMIA) stand as independent content without load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Creativity can be meaningfully separated into divergent (novelty/diversity) and convergent (task fulfilment) components for automated evaluation.
Reference graph
Works this paper leans on
-
[1]
Cheng-Han Chiang and Hung-yi Lee
Do language models enjoy their own stories? prompting large language models for automatic story evaluation.Transactions of the Association for Com- putational Linguistics, 12:1122–1142. Cheng-Han Chiang and Hung-yi Lee. 2023. Can large language models be an alternative to human evalua- tions? InProceedings of the 61st Annual Meeting of the Association for...
2023
-
[2]
Matthew DeLorenzo, Vasudev Gohil, and Jeyavijayan Rajendran
Deepseek-r1: Incentivizing reasoning capa- bility in llms via reinforcement learning.Preprint, arXiv:2501.12948. Matthew DeLorenzo, Vasudev Gohil, and Jeyavijayan Rajendran. 2024. Creativeval: Evaluating creativity of llm-based hardware code generation.2024 IEEE LLM Aided Design Workshop (LAD), pages 1–5. Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, an...
Pith/arXiv arXiv 2024
-
[3]
Fangrui Lv, Kaixiong Gong, Jian Liang, Xinyu Pang, and Changshui Zhang
Chatgpt as a factual inconsistency evaluator for text summarization.Preprint, arXiv:2303.15621. Fangrui Lv, Kaixiong Gong, Jian Liang, Xinyu Pang, and Changshui Zhang. 2024. Subjective topic meets LLMs: Unleashing comprehensive, reflective and creative thinking through the negation of negation. InProceedings of the 2024 Conference on Empiri- cal Methods i...
arXiv 2024
-
[4]
Remote associates test, college, adult, form 1 and examiner’s manual, remote associates test, col- lege and adult forms 1 and 2. Behnam Mohammadi. 2024. Creativity has left the chat: The price of debiasing language models.Preprint, arXiv:2406.05587. Charles O’Neill, Tirthankar Ghosal, Roberta R˘aileanu, Mike Walmsley, Thang Bui, Kevin Schawinski, and Ioan...
arXiv 2024
-
[5]
11 Max Peeperkorn, Tom Kouwenhoven, Dan Brown, and Anna Jordanous
Automatic scoring of metaphor creativity with large language models.Creativity Research Journal, 0(0):1–15. 11 Max Peeperkorn, Tom Kouwenhoven, Dan Brown, and Anna Jordanous. 2024. Is temperature the creativ- ity parameter of large language models?Preprint, arXiv:2405.00492. Kai Ruan, Xuan Wang, Jixiang Hong, and Hao Sun
arXiv 2024
-
[6]
Liveideabench: Evaluating llms’ scientific creativity and idea generation with minimal context. Preprint, arXiv:2412.17596. Mark A. Runco and Garrett J. Jaeger. 2012. The stan- dard definition of creativity.Creativity Research Journal, 24(1):92–96. Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zet...
arXiv 2012
-
[7]
Score: Story coherence and retrieval enhance- ment for ai narratives.Preprint, arXiv:2503.23512. Tianhang Zhang, Lin Qiu, Qipeng Guo, Cheng Deng, Yue Zhang, Zheng Zhang, Chenghu Zhou, Xinbing Wang, and Luoyi Fu. 2023. Enhancing uncertainty- based hallucination detection with stronger focus. Preprint, arXiv:2311.13230. Lianmin Zheng, Wei-Lin Chiang, Ying S...
arXiv 2023
-
[8]
Yaoming Zhu, Sidi Lu, Lei Zheng, Jiaxian Guo, Weinan Zhang, Jun Wang, and Yong Yu
Judgelm: Fine-tuned large language models are scalable judges.Preprint, arXiv:2310.17631. Yaoming Zhu, Sidi Lu, Lei Zheng, Jiaxian Guo, Weinan Zhang, Jun Wang, and Yong Yu. 2018. Texygen: A benchmarking platform for text generation models. Preprint, arXiv:1802.01886. 12 Appendix A Model Selection Our framework encompasses models of varying sizes, ages, an...
arXiv 2018
-
[9]
Answers to questions from other analysts Rresponse a
-
[10]
General opinionsR opinion a
-
[11]
bit" and
Clarifying questions to other analystsq new a . (Rquestions a , Ropinion a , qnew a ) =J a(qothers a ,GET(Q a ⊕q others a , k), Inf o). (7) The analysts extract relevant fragments using prede- fined role-specific queries Qa, and questions from other analysts. Their generated insights are stored in the database. Confidence Scoring.At the end of each round ...
2023
-
[12]
Stand-out original - Tools used in a way you’d never imagine: Toothbrush bristles spun in a drill to make an instant micro-sander for polishing scratched eyeglass lenses
-
[13]
Clearly novel - Clear twist or clever combo beyond common hacks: Coat-hanger bent into a crank to link two broken fan blades
-
[14]
Slight twist - Mostly normal; one small inventive tweak: Duct-tape a flashlight to a roller handle for ceiling painting
-
[15]
You may also find it helpful to judge using this way:
Conventional - Straight, textbook use of the tool: Knife simply cuts rope to length. You may also find it helpful to judge using this way:
-
[16]
Skim question and answer to get rough idea of main goals
-
[17]
Scan answer more closely; identify uses/combinations of tools(verbs, can ignore the elaboration)
-
[18]
Pick out 1-2 uses that seem the most unconventional, novel
-
[19]
If torn between two levels, drop down to lower tier
Using these 1-2 uses, tier list. If torn between two levels, drop down to lower tier
-
[20]
28 In the following sections, italicised text in the prompts refers to variables
Rank individual solutions within each tier with gut feeling I guess. 28 In the following sections, italicised text in the prompts refers to variables. K Prompt for Novelty Judge Novelty Judge Prompts System Prompt Template: You are an expert judge. Your task is to compare two Question/Answer (Q/A) pairs based on a specific definition of novelty provided i...
-
[23]
**Queries for other agents: (format in this way:To <analyst name>: <query>...)** Begin each part of your response with [[label of part]]. E.g. [[Answering questions from other agents]]: <part of response> Relevant discussion is below:relevantdiscussion 32 Solution Analyst Discussion Prompt You are an impartial but critical ’solution analyst’, partaking in...
-
[26]
**Queries for other agents: (format in this way:To <analyst name>: <query>...)** Begin each part of your response with [[label of part]]. E.g. [[Answering questions from other agents]]: <part of response> Relevant discussion is below:relevantdiscussion 33 Criterion Analyst Discussion Prompt You are an impartial but critical ’criterion analyst’, partaking ...
-
[27]
**Clearly answering all questions/uncertainties from other agents in the discussion history, IF ANY: (format STRICTLY in this way: To <analyst name>’s question about <topic>: <answer>...)**
-
[28]
your main responsibility, with reference to the criterion definition:**
**General thoughts/opinion on whether the solution fulfils the criterion criterion (succinctly) w.r.t. your main responsibility, with reference to the criterion definition:**
-
[29]
**Queries for other agents: (format in this way:To <analyst name>: <query>...)** Begin each part of your response with [[label of part]]. E.g. [[Answering questions from other agents]]: <part of response> Relevant discussion is below:relevantdiscussion 34 Confidence Prompt You are the impartial but critical role in the discussion provided,rolef ocus. Prob...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.