How Much Do LLMs Know About Chinese Zero Pronouns?
Pith reviewed 2026-06-28 23:08 UTC · model grok-4.3
The pith
Large language models perform poorly on Chinese zero pronouns, with even advanced models correctly translating fewer than half into English.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
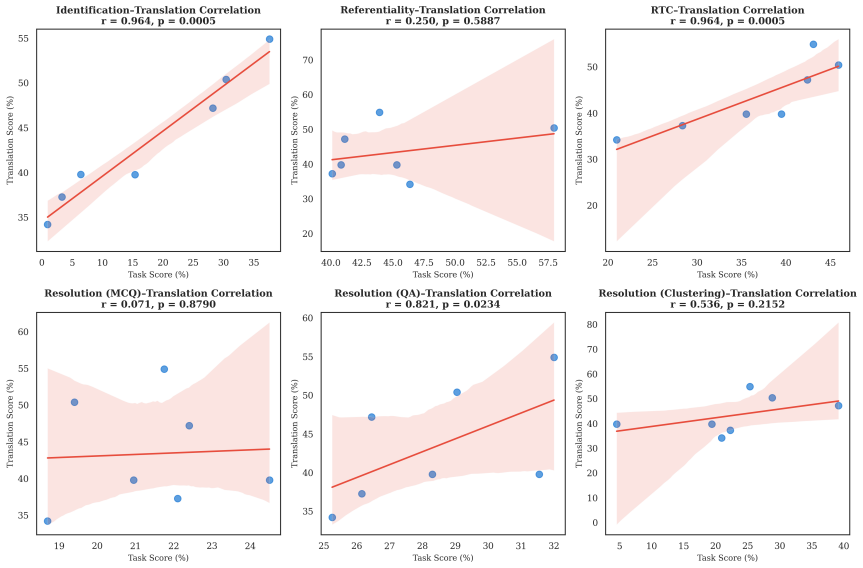
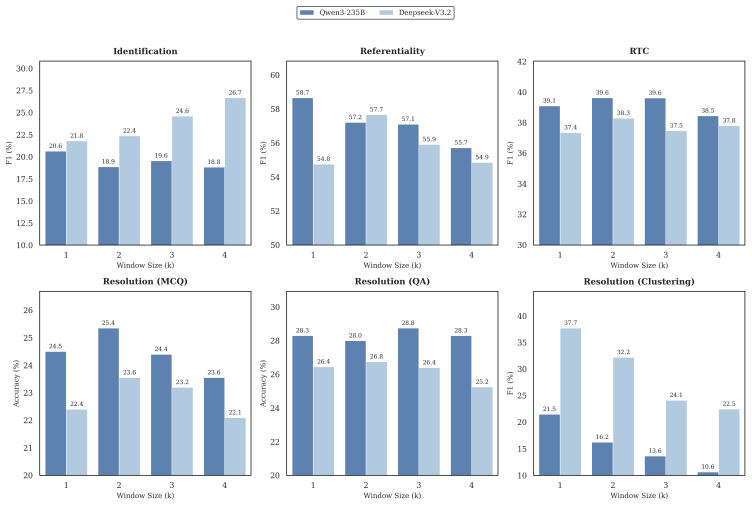
The evaluation of a diverse set of LLMs across identification, referentiality classification, referential type classification, resolution, and translation shows that Chinese ZPs remain highly challenging for current LLMs, particularly for upstream tasks such as identification and referentiality classification. Performance on downstream tasks such as ZP translation is also consistently low: even state-of-the-art reasoning-oriented LLMs correctly translate fewer than half of Chinese ZPs into English.
What carries the argument
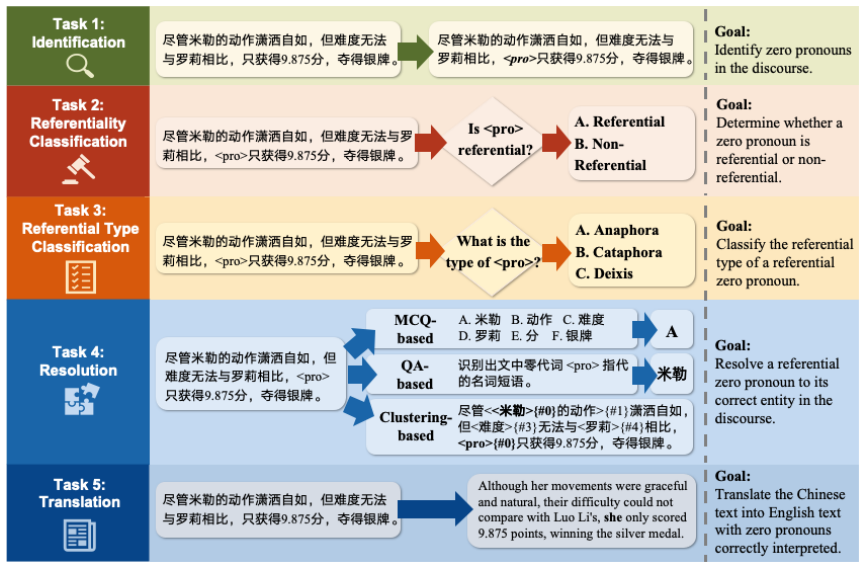
A sequence of linguistically motivated tasks (identification, referentiality classification, referential type classification, resolution, and translation) used to measure LLM handling of Chinese zero pronouns.
If this is right
- Upstream failures at identification and referentiality classification directly reduce success on resolution and translation.
- State-of-the-art reasoning models still fall short on the full chain of ZP tasks.
- Performance gaps appear across a wide range of current LLMs rather than in a few weaker ones.
- Downstream applications that rely on accurate Chinese-to-English conversion will inherit these errors.
Where Pith is reading between the lines
- Training data for LLMs may contain too few explicit examples of omitted pronouns in Chinese contexts.
- Targeted fine-tuning on zero-pronoun annotated corpora could raise performance on the upstream tasks.
- Similar evaluation pipelines could reveal comparable gaps in other pro-drop languages such as Japanese.
- Multilingual model developers would benefit from adding zero-pronoun benchmarks to standard test suites.
Load-bearing premise
The chosen sequence of linguistically motivated tasks and the test cases used provide a valid and representative measure of LLMs' knowledge about Chinese zero pronouns.
What would settle it
A follow-up run in which multiple LLMs reach above 70 percent accuracy on identification and above 50 percent accuracy on translation of the same test items would undermine the claim.
Figures
read the original abstract
Zero Pronouns (ZPs) are a pervasive linguistic phenomenon in pro-drop languages such as Chinese and have long posed a challenge for natural language processing systems. Although Large Language Models (LLMs) perform well on many Chinese language tasks, their ability to process ZPs remains poorly understood. We conduct a systematic investigation of LLMs' handling of Chinese ZPs through a sequence of linguistically motivated tasks, including identification, referentiality classification, referential type classification, resolution, and translation. A diverse set of LLMs is evaluated across all tasks. Our results show that Chinese ZPs remain highly challenging for current LLMs, particularly for upstream tasks such as identification and referentiality classification. Performance on downstream tasks, such as ZP translation, is also consistently low: even state-of-the-art reasoning-oriented LLMs correctly translate fewer than half of Chinese ZPs into English.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs struggle with Chinese zero pronouns (ZPs) across a sequence of linguistically motivated tasks (identification, referentiality classification, referential type classification, resolution, and translation). It reports particularly poor performance on upstream tasks and that even state-of-the-art reasoning-oriented LLMs correctly translate fewer than half of Chinese ZPs into English.
Significance. If the empirical results hold after proper documentation, the work would usefully document a limitation in current LLMs for pro-drop languages and provide a multi-level probe of ZP processing that could inform future modeling and evaluation in Chinese NLP.
major comments (2)
- [Abstract] Abstract: performance conclusions (e.g., 'correctly translate fewer than half') are stated without any accompanying information on datasets, model versions, metrics, statistical tests, or controls, so the data cannot be checked against the claims.
- [Experimental setup] Description of experimental setup: no details are supplied on test-case provenance, annotation protocol, inter-annotator agreement, or human baselines, which is required to establish that the task sequence isolates ZP-specific knowledge rather than general Chinese processing difficulty or prompt sensitivity.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly indicated the number of LLMs evaluated and the scale of the test sets.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and have made revisions to improve documentation and clarity while preserving the core empirical findings.
read point-by-point responses
-
Referee: [Abstract] Abstract: performance conclusions (e.g., 'correctly translate fewer than half') are stated without any accompanying information on datasets, model versions, metrics, statistical tests, or controls, so the data cannot be checked against the claims.
Authors: We agree the abstract is concise and omits methodological specifics, which is typical due to length limits. The full manuscript details the datasets (custom ZP-annotated corpus derived from OntoNotes and news texts), models (including GPT-4o, Claude-3, Llama-3-70B), metrics (accuracy/F1 for classification tasks, exact match for translation), and significance testing (paired t-tests). We will revise the abstract to incorporate a short clause referencing the evaluation framework and main dataset size. revision: yes
-
Referee: [Experimental setup] Description of experimental setup: no details are supplied on test-case provenance, annotation protocol, inter-annotator agreement, or human baselines, which is required to establish that the task sequence isolates ZP-specific knowledge rather than general Chinese processing difficulty or prompt sensitivity.
Authors: Sections 3 and 4 of the manuscript describe task construction, data sources, and evaluation protocols. Test cases originate from established Chinese corpora with manual ZP markup; annotation followed a two-annotator protocol by native linguists (IAA reported via Cohen's kappa); human performance baselines appear in the results tables; and prompt robustness is tested via multiple templates. To strengthen the isolation argument, we will add an explicit subsection discussing controls for general Chinese processing difficulty and prompt sensitivity. revision: partial
Circularity Check
No circularity: purely empirical task evaluation with no derivations or fitted parameters
full rationale
The paper reports results from running LLMs on a sequence of defined tasks (identification, referentiality classification, etc.) and measuring performance. No equations, derivations, parameter fitting, or self-citation chains appear in the abstract or described structure. The central claims rest on direct empirical outputs rather than any reduction to prior inputs by construction, satisfying the default expectation of no significant circularity for non-theoretical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selected tasks accurately reflect LLMs' handling of Chinese zero pronouns.
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Modelling pro-drop with the rational speech acts model. InProceedings of the 11th International Conference on Natural Language Generation, pages 159–164, Tilburg University, The Netherlands. Asso- ciation for Computational Linguistics. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shi- rong Ma, Peiyi Wang, Xiao Bi, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Qingyu Yin, Yu Zhang, Wei-Nan Zhang, Ting Liu, and William Yang Wang. 2018a. Deep reinforcement learning for Chinese zero pronoun resolution. In Proceedings of the 56th Annual Meeting of the As- sociation for Computational Linguistics (Volume 1: Long Papers), pages 569–578, Melbourne, Australia. Asso...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
InProceedings of the 2017 Con- ference on Empirical Methods in Natural Language Processing, pages 1309–1318, Copenhagen, Den- mark
Chinese zero pronoun resolution with deep memory network. InProceedings of the 2017 Con- ference on Empirical Methods in Natural Language Processing, pages 1309–1318, Copenhagen, Den- mark. Association for Computational Linguistics. Qingyu Yin, Yu Zhang, Weinan Zhang, Ting Liu, and William Yang Wang. 2018b. Zero pronoun resolu- tion with attention-based n...
2017
-
[4]
试图近距离去开始于两年前的二零零三年,但是在迪斯尼的任何标志都还没有进入我 们的视线时,车子就在去往迪斯尼的岔路口被保安人员拦了下来,
Neural recovery machine for chinese dropped pronoun.Frontiers of Computer Science, 13(5):1023– 1033. A Data Preprocessing This appendix details how we extract labels from the OntoNotes dataset for the five tasks considered in this study. In OntoNotes, Zero Pronouns (ZPs) are marked using the token ‘*pro*’, and annota- tions of coreference chains and refer...
-
[5]
标注方式:仅在文本中插入 <pro>,不得添加、删除或修改任何除 <pro>以外的多余内容,保持原句的换 行、空格、顺序、标点和其他字符不变。
-
[6]
检测范围:只分析和标注标准目标中文文本实例中的中文部分,忽略其中出现的英文、数字、符号或无意 义空白等内容。
-
[7]
判定标准:判断该分句是否省略了必需的主语或宾语等成分。若该成分缺失但原本在语义或句法结构上 应当出现,则确认为零代词。即使无法从上下文中明确推断出 “谁”或“什么”,也需要在省略的地方标注零代 词。
-
[8]
张三是一名学生,学习很努力。
输出格式:最终输出只包含标注后的目标文本,不包含任何解释、分析或多余说明。同时保持与原始文本 相同的行、段落结构,只在零代词缺失处插入<pro>标记。 #示例 以下展示三个常见的零代词场景作为你标注时的重要参考: 1.省略主语 原句:“张三是一名学生,学习很努力。” 标注后:“张三是一名学生,<pro>学习很努力。”(第二个分句缺少对“张三”的指代。) 2.省略主语(不明确) 原句:“明天去爬山吗?” 标注后: “<pro>明天去爬山吗? ”(句首省略了 主语,即使不确定到底是 “你”“我们 ”或其他,也要插 入<pro>。) 3.省略宾语 原句:“我吃完了。 ”(若为完整表达,但想突出 “吃完了什么 ”则需要信息判断;如果明确有缺省内容则标 注) 如果上文语境明确省略了“苹果”等代词位置,则可在动词后插...
-
[9]
明确零代词定义:句子中语义或句法结构上必需的代词(主语或宾语等)被省略,但该成分在语义或句法 上应当出现,则为零代词。
-
[10]
张三是一名学生,<pro>学习很努力。
明确零代词可指性定义:若目标零代词在所给上下文语境中有实际指代的内容,那么无论该指代内容在文 中是否显式出现,都称该零代词可指。 #示例 以下展示零代词的可指性作为你标注时的重要参考: 1.可指 (I)前指: 原句:“张三是一名学生,<pro>学习很努力。” 结论:T 分析:第二个分句缺少对“张三”的指代,而“张三”作为先行词显性地出现在零代词之前,故<pro>可指。 (II)后指: 原句:“<pro>明天去爬山吗?我们明天都没课诶!” 结论:T 分析:句首零代词 <pro>指代出现在第二个分句中的 “我们”,即<pro>的指代内容显性地出现了,故 <pro>可 指。 (III)指别: 原句:“如果<pro>不是的话<pro>全部都不可以进入,尤其是<pro>不可以摄录机拍摄。” 结论:T 分析:两个分句...
-
[11]
你的输出必须且只能是A、B、C三个字符之一,严禁在你的输出中复述题目、分析推理、添加标点或者换 行。
-
[12]
A" "B" "C
划定检测范围:仅分析目标文本中的汉语以判断零代词 <pro>的指代类型,忽略英文、数字、符号等无关 内容。 #示例 以下展示零代词各指代类型的示例作为你标注时的重要参考: A 前指:指某一语言成分的语义依赖于前置表达的表达方式,指代内容为上文中已出现过的另一语言成 分。 输入:张三是一名学生,<pro>学习很努力。 输出: A B后指:指某一语言成分的语义依赖于后置表达的表达方式,预先指代下文中即将出现的另一语言成分。 输入:<pro>明天去爬山吗?我们明天都没课诶! 输出: B C 指别:指描述词语或表达必须依赖具体语境或说话者、时间、地点、手势等现实情境才能确定其含义的 现象。 输入:今天天气真好,<pro>可以在公园野餐放松放松。 输出: C #输出格式:请以"A" "B" "C"的格式回答,不要添...
-
[13]
谁”或“什么”被省略,只要存在必要成分的省略,就视为 零代词。请阅读下方文段,识别出文中零代词 <pro>指代的名词短语(名词短语指示性成分,如 “张三
输出仅为候选项字母(大写),若有多个,用单个空格分隔;例如: A B C 。不允许输出任何解释、标 点、注释或多余文字。 2.若判断有多个可能先行词,请把所有可能项列出。 #示例 文段:小明去了商店,<pro>买了很多水果。 选项:A.小明B.商店C.水果 输出:A #文段: #选项: #输出: QA-based Resolution # 任务说明:零代词指在语篇中本应出现(通常是主语或宾语等)的代词却被省略,但从语义或句法结构上 看,该代词对表意是必需的。即使无法准确推断出 “谁”或“什么”被省略,只要存在必要成分的省略,就视为 零代词。请阅读下方文段,识别出文中零代词 <pro>指代的名词短语(名词短语指示性成分,如 “张三”“那辆 车”“美国总统”等)。 #任务要求
-
[14]
输出仅包含所有可能的名词短语,若有多个答案,用单个空格分隔;不允许输出序号、标签、解释或任何 多余文字。 2.若出现指代模糊且多个短语均合理,则列出所有合理短语;尽量按在原文中出现的先后顺序给出。 3.名词短语应与原词一致(不进行同义替换或改写)。 #输出格式 只返回词,不要返回括号、引号或注释。正确输出示例:张三李四(多个答案用空格分隔) #示例 1.单一先行词 文段:张三去了学校,<pro>在教室等他。 输出:张三 2.多个可能先行词: 文段:张三和李四来了,<pro>都很高兴。 输出:张三李四 #文段: #输出: Clustering-based Resolution # 任务说明:零代词指在语篇中本应出现(通常是主语或宾语等)的代词却被省略 ,但从语义或句法结构上 看,该代词对表意是必需的。即使无...
-
[15]
cluster_id从0开始连续编号,相同指代实体使用相同编号。
-
[16]
文段中出现的<pro>都必须被视为一个实体,并必须在其后加上#cluster_id,任何情况下都不允许遗漏、跳过、 忽略<pro>的标注。 4.只用输出标注后的文本,输出必须保持原文顺序,不得删词、改词、增词。 #示例 原文:«张三><李四»去了学校,<pro>见到了<王五>。 标注:«张三>#0<李四>#1>#2去了学校,<pro>#2见到了<王五>#3。 #文段: #输出: ZP-Unaware Translation # 任务说明:请将给出的文本直接翻译成英文。输入为一行中文,输出仅一行译文即可,不添加任何注释说 明。 #待翻译文本: ZP-Aware Translation # 任务说明:零代词指在语篇中本应出现(通常是主语或宾语等)的代词却被省略,但从语义或句法结构上 看,该代词对表意是必需的。...
-
[17]
学习”一词前缺少主语,存在零代词<pro>。 2.联系上下文,判断出<pro>为可指零代词且指代内容即为上文的“张三
译文在词级上需能和原文词对译,句级上需保留完整结构和原有语序,语义上需完整体现中文原文中的所 有显性与隐性信息不得有任何省略。 2.为追求译文的精确,翻译之前通过语法分析潜在零代词的位置、可指性、类型与指代内容是被鼓励的。 3.若被找出的零代词不可指,则不需要强行译出。 #输出格式:输出一行英文译文,不包含任何解释、注释或中间推理。 #示例 中文输入:张三是一名学生,学习很努力。 ##步骤: 1.通过寻找发现“学习”一词前缺少主语,存在零代词<pro>。 2.联系上下文,判断出<pro>为可指零代词且指代内容即为上文的“张三”。
-
[18]
he"或者"Zhang San
恢复零代词主语的指代内容"he"或者"Zhang San",并在译文中显式表达如下:Zhang San is a student and he studies very hard. #待翻译文本: Oracle Translation # 任务说明:零代词指在语篇中本应出现(通常是主语或宾语等)的代词却被省略,但从语义或句法结构 上看,该代词对表意是必需的。在输入文本中,标记 <pro>仅作为零代词占位符,表示该位置存在一个被省 略、但必须在英文中显式表达的指代成分。你的任务是,将一行包含 <pro>标记的中文文本翻译成英文,并 在译文中用合适的英文代词或名词短语替换每一个<pro>。 #任务要求 1.每一个<pro>必须在英文译文中被显式替换为具体的指代形式,严禁保留、照抄或省略<pro>。
-
[19]
#待翻译文本: Table 11: Prompt templates for all evaluation tasks related to Zero Pronoun processing
若指代对象明确,使用文中的人称代词或名词进行翻译;若无法唯一确定指代对象,必须使用语义合理的 泛指表达。 3.译文需在词级和句级结构上与原文保持对应,完整表达原文中所有显性与隐性信息。 4.输出前请进行自检,若译文中仍出现<pro>,请重新生成译文。 #输出格式 仅输出一行英文译文。不得包含<pro>、中文、解释、注释或中间推理。 #示例 中文输入:张三是一名学生,<pro>学习很努力。 英文输出:Zhang San is a student, he studies very hard. #待翻译文本: Table 11: Prompt templates for all evaluation tasks related to Zero Pronoun processing
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.