TIGER: Inverting Transformer Gradients via Embedding-Subspace Distance Optimization
Pith reviewed 2026-06-27 00:22 UTC · model grok-4.3
The pith
TIGER recovers input tokens from transformer gradients by optimizing their embeddings to the low-rank attention subspace.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
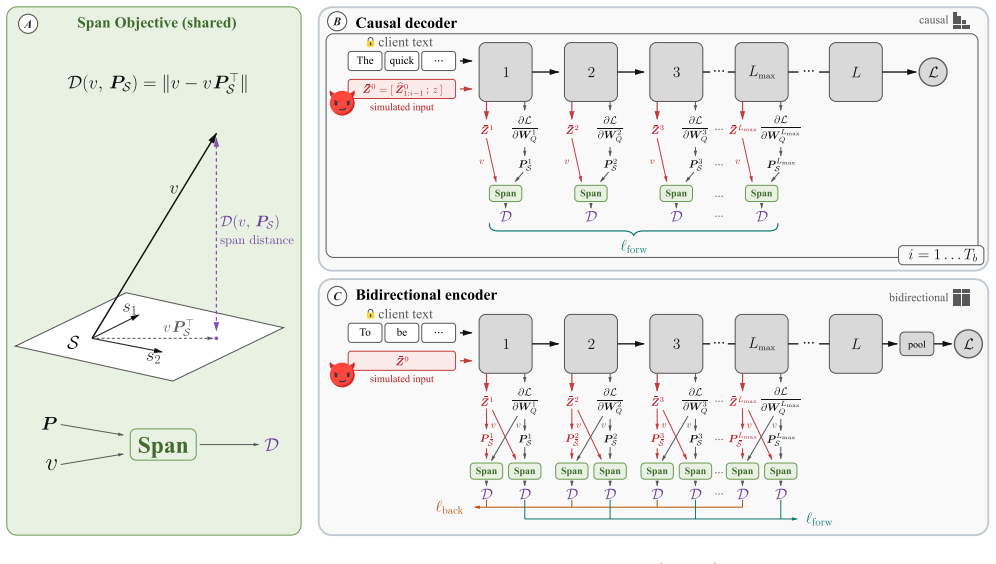
TIGER identifies the subspace spanned by the low-rank attention gradients and directly minimizes the distance of token embeddings to this subspace, converting the reconstruction task into a differentiable objective that recovers original inputs more reliably than prior discrete or full-gradient-matching attacks.
What carries the argument
Embedding-subspace distance optimization that aligns candidate token embeddings with the low-rank signal extracted from attention gradients.
If this is right
- On encoder-only models TIGER improves both reconstruction quality and runtime over existing attacks.
- On decoder models TIGER succeeds in DP-defended federated learning where prior subspace attacks fail.
- The continuous formulation avoids the instability of dummy-input optimization and the brittleness of discrete membership tests.
- The approach scales to non-causal attention without requiring per-token discrete searches.
Where Pith is reading between the lines
- The subspace signal may remain informative in other architectures that exhibit low-rank gradient structure.
- Defenses could be strengthened by specifically disrupting the low-rank component of attention gradients.
- Cumulative leakage across multiple rounds of federated updates could be quantified by repeated application of the same subspace optimization.
Load-bearing premise
The low-rank attention gradients span a subspace that contains the true token embeddings even after numerical perturbations from quantization or differential privacy.
What would settle it
An experiment in which TIGER fails to recover any correct tokens from DP-protected gradients on a decoder-only transformer where the subspace no longer contains the true embeddings.
Figures
read the original abstract
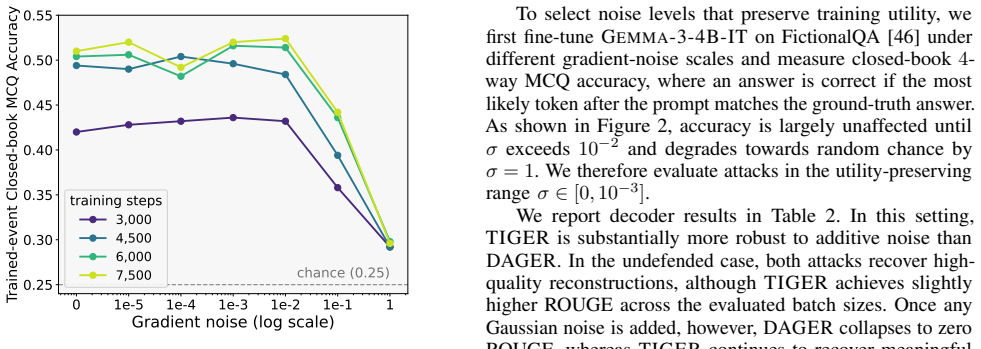
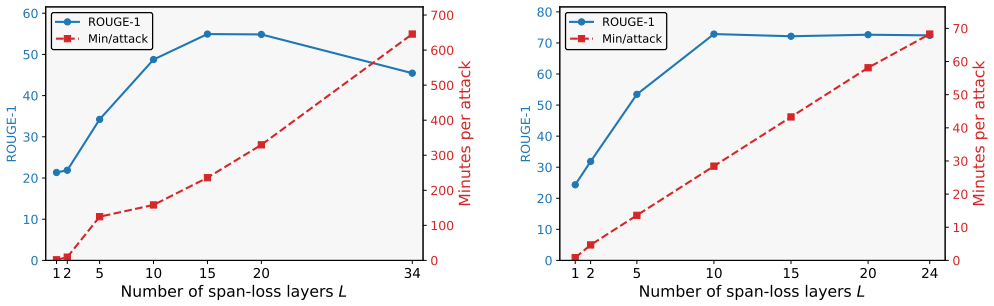
Federated learning allows multiple clients to jointly train a shared model by sending gradient updates to a central server while keeping raw inputs local. However, prior gradient inversion attacks show that these updates can reveal enough information to reconstruct client inputs. Existing attacks on transformers either optimize dummy inputs to match the true client updates, which is costly and unstable for modern models, or exploit the low rank of attention gradients to identify a subspace containing the true layer embeddings, followed by a discrete membership test for candidate tokens. However, this token test is brittle under numerical noise, i.e., from quantization or Differential Privacy (DP), and scales poorly for encoder models with non-causal attention. We introduce TIGER, a continuous gradient inversion attack that turns this subspace signal into a differentiable objective. Instead of searching over tokens or matching full gradients, TIGER directly optimizes token embeddings to minimize their distance to the subspace. Our experiments demonstrate that on encoder-only models, TIGER substantially improves both reconstruction quality and runtime over existing attacks, while on decoder models, TIGER is more robust than prior subspace-based attacks, enabling the first successful reconstructions in DP-defended federated learning settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TIGER, a continuous gradient inversion attack for transformer models in federated learning settings. It exploits the low-rank structure of attention gradients to identify an embedding subspace and formulates a differentiable objective that optimizes token embeddings to minimize their distance to this subspace, avoiding both full gradient matching and brittle discrete membership tests. The central claim is that this yields substantially better reconstruction quality and runtime on encoder-only models and greater robustness on decoder models, including the first successful reconstructions under differential privacy noise.
Significance. If the experimental results hold, TIGER provides a more stable and scalable alternative to prior subspace-based and optimization-based inversion attacks on transformers. The shift to a continuous embedding-distance objective addresses a key brittleness under numerical perturbations such as quantization or DP, which is relevant for assessing privacy leakage in federated learning deployments of modern language models.
minor comments (2)
- [Abstract] Abstract: the claim of 'substantially improves both reconstruction quality and runtime' and 'first successful reconstructions in DP-defended federated learning settings' is stated without any quantitative metrics, baseline names, or dataset sizes; the results section should be cross-referenced in the abstract or a table of key numbers added for immediate assessment.
- The description of the embedding-subspace distance objective would benefit from an explicit equation or pseudocode block showing how the low-rank attention gradient matrix is used to construct the subspace projector and how the distance is computed during optimization.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and the recommendation for minor revision. The provided summary accurately captures the core contribution of TIGER as a continuous embedding-subspace optimization approach for gradient inversion.
Circularity Check
No significant circularity detected
full rationale
The paper's central contribution is TIGER, which converts an existing low-rank subspace signal (from prior subspace-based attacks) into a new differentiable embedding-distance optimization objective. This is presented as an independent algorithmic extension rather than a re-derivation or fit of prior results. No equations, predictions, or uniqueness claims in the provided abstract reduce by construction to fitted inputs, self-citations, or ansatzes; the method is described as building on but extending the subspace idea with continuous optimization that improves robustness under noise. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention gradients in transformers exhibit low rank, allowing identification of an embedding subspace containing true tokens.
Reference graph
Works this paper leans on
-
[1]
Communication-efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inProceedings of the 20th International Conference on Artificial Intelligence and Statistics, AISTATS 2017, 20-22 April 2017, Fort Lauderdale, FL, USA, ser. Proceedings of Machine Learning Research, A. Singh and X. J...
2017
-
[2]
T. Fan, Y . Kang, G. Ma, W. Chen, W. Wei, L. Fan, and Q. Yang, “FATE-LLM: A industrial grade federated learning framework for large language models,”CoRR, vol. abs/2310.10049, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2310.10049
-
[3]
C. Chen, X. Feng, Y . Li, L. Lyu, J. Zhou, X. Zheng, and J. Yin, “Integration of large language models and federated learning,” Patterns, vol. 5, no. 12, p. 101098, 2024. [Online]. Available: https://doi.org/10.1016/j.patter.2024.101098
-
[4]
Federated Large Language Models: Current Progress and Future Directions
Y . Yao, J. Zhang, J. Wu, C. Huang, Y . Xia, T. Yu, R. Zhang, S. Kim, R. A. Rossi, A. Li, L. Yao, J. J. McAuley, Y . Chen, and C. Joe-Wong, “Federated large language models: Current progress and future directions,”CoRR, vol. abs/2409.15723, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2409.15723
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2409.15723 2024
-
[5]
Federated large language models: Feasibility, robustness, security and future directions,
W. Jiang, Y . Luo, G. Deng, S. Chen, X. Yang, S. Wu, X. Gao, L. Liu, and S. Fu, “Federated large language models: Feasibility, robustness, security and future directions,”CoRR, vol. abs/2505.08830, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2505.08830
-
[6]
Federated multilingual models for medical transcript analysis,
A. Manoel, M. del Carmen Hipolito Garcia, T. Baumel, S. Su, J. Chen, R. Sim, D. Miller, D. Karmon, and D. Dimitriadis, “Federated multilingual models for medical transcript analysis,” inConference on Health, Inference, and Learning, CHIL 2023, Broad Institute of MIT and Harvard (Merkin Building), 415 Main Street, Cambridge, MA, USA, ser. Proceedings of Ma...
2023
-
[7]
L. Zhang and Y . Li, “Federated learning with layer skipping: Efficient training of large language models for healthcare NLP,”CoRR, vol. abs/2504.10536, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2504.10536
-
[8]
A federated and parameter-efficient framework for large language model training in medicine,
A. Li, Y . Chen, W. Long, Y . Yin, Y . Hu, H. Kim, W. Zhou, Y . Zhou, H. Peng, Y . Ren, X. Ai, Z. Qin, M. Hu, X. Li, H. Yu, Y . Tham, L. Ohno-Machado, H. Xu, and Q. Chen, “A federated and parameter-efficient framework for large language model training in medicine,”CoRR, vol. abs/2601.22124, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2601.22124
-
[9]
Privacy-first health research with federated learning,
A. Sadilek, L. Liu, D. Nguyen, M. Kamruzzaman, S. Serghiou, B. Rader, A. Ingerman, S. Mellem, P. Kairouz, E. O. Nsoesie, J. Macfarlane, A. Vullikanti, M. V . Marathe, P. Eastham, J. S. Brownstein, B. A. y Arcas, M. D. Howell, and J. Hernandez, “Privacy-first health research with federated learning,”npj Digit. Medicine, vol. 4, 2021. [Online]. Available: h...
2021
-
[10]
FEDLEGAL: the first real-world federated learning benchmark for legal NLP,
Z. Zhang, X. Hu, J. Zhang, Y . Zhang, H. Wang, L. Qu, and Z. Xu, “FEDLEGAL: the first real-world federated learning benchmark for legal NLP,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, A. Rogers, J. L. Boyd-Graber, and N. Okazaki, Eds. Assoc...
-
[11]
Fedjudge: Federated legal large language model,
L. Yue, Q. Liu, Y . Du, W. Gao, Y . Liu, and F. Yao, “Fedjudge: Federated legal large language model,” inDatabase Systems for Advanced Applications - 29th International Conference, DASFAA 2024, Gifu, Japan, July 2-5, 2024, Proceedings, Part V, ser. Lecture Notes in Computer Science, M. Onizuka, J. Lee, Y . Tong, C. Xiao, Y . Ishikawa, S. Amer-Yahia, H. V ...
-
[12]
Flowertune: A cross-domain benchmark for federated fine-tuning of large language models,
Y . Gao, M. R. Scamarcia, J. Fernández-Marqués, M. Naseri, C. S. Ng, D. Stripelis, Z. Li, T. Shen, J. Bai, D. Chen, Z. Zhang, R. Hu, I. Song, K. Lee, H. Jia, T. Dang, J. Wang, Z. Liu, D. J. Beutel, L. Lyu, and N. D. Lane, “Flowertune: A cross-domain benchmark for federated fine-tuning of large language models,”CoRR, vol. abs/2506.02961,
-
[13]
Available: https://doi.org/10.48550/arXiv.2506.02961
[Online]. Available: https://doi.org/10.48550/arXiv.2506.02961
-
[14]
D. Byrd and A. Polychroniadou, “Differentially private secure multi- party computation for federated learning in financial applications,” inICAIF ’20: The First ACM International Conference on AI in Finance, New York, NY, USA, October 15-16, 2020, T. Balch, Ed. ACM, 2020, pp. 16:1–16:9. [Online]. Available: https://doi.org/10.1145/3383455.3422562
-
[15]
Deep leakage from gradients,
L. Zhu, Z. Liu, and S. Han, “Deep leakage from gradients,” in Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, H. M. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché-Buc, E. B. Fox, and R. Garnett, Eds., 2019, pp. 14 747–14 756...
2019
-
[16]
idlg: Improved deep leakage from gradients,
B. Zhao, K. R. Mopuri, and H. Bilen, “idlg: Improved deep leakage from gradients,”CoRR, vol. abs/2001.02610, 2020. [Online]. Available: http://arxiv.org/abs/2001.02610
arXiv 2001
-
[17]
Inverting gradients - how easy is it to break privacy in federated learning?
J. Geiping, H. Bauermeister, H. Dröge, and M. Moeller, “Inverting gradients - how easy is it to break privacy in federated learning?” inAdvances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. L...
2020
-
[18]
See through gradients: Image batch recovery via gradinversion,
H. Yin, A. Mallya, A. Vahdat, J. M. Álvarez, J. Kautz, and P. Molchanov, “See through gradients: Image batch recovery via gradinversion,” inIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021. Computer Vision Foundation / IEEE, 2021, pp. 16 337–16 346. [Online]. Available: https://openaccess.thecvf.com/content/...
2021
-
[19]
Gradient inversion with generative image prior,
J. Jeon, J. Kim, K. Lee, S. Oh, and J. Ok, “Gradient inversion with generative image prior,” inAdvances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, M. Ranzato, A. Beygelzimer, Y . N. Dauphin, P. Liang, and J. W. Vaughan, Eds., 2021, pp. 29 898–29 ...
2021
-
[20]
A. Hatamizadeh, H. Yin, H. Roth, W. Li, J. Kautz, D. Xu, and P. Molchanov, “Gradvit: Gradient inversion of vision transformers,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18- 24, 2022. IEEE, 2022, pp. 10 011–10 020. [Online]. Available: https://doi.org/10.1109/CVPR52688.2022.00978
-
[21]
Cocktail party attack: Breaking aggregation-based privacy in federated learning using independent component analysis,
S. Kariyappa, C. Guo, K. Maeng, W. Xiong, G. E. Suh, M. K. Qureshi, and H. S. Lee, “Cocktail party attack: Breaking aggregation-based privacy in federated learning using independent component analysis,” inInternational Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, ser. Proceedings of Machine Learning Research, A. Kraus...
2023
-
[22]
TAG: gradient attack on transformer-based language models,
J. Deng, Y . Wang, J. Li, C. Wang, C. Shang, H. Liu, S. Rajasekaran, and C. Ding, “TAG: gradient attack on transformer-based language models,” inFindings of the Association for Computational Linguistics: EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 16-20 November, 2021, ser. Findings of ACL, M. Moens, X. Huang, L. Specia, and S. W. Yih, Eds...
-
[23]
LAMP: extracting text from gradients with language model priors,
M. Balunovic, D. I. Dimitrov, N. Jovanovic, and M. T. Vechev, “LAMP: extracting text from gradients with language model priors,” inAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, S. Koyejo, S. Mohamed, A. Agarwal, D. B...
2022
-
[24]
Recovering private text in federated learning of language models,
S. Gupta, Y . Huang, Z. Zhong, T. Gao, K. Li, and D. Chen, “Recovering private text in federated learning of language models,” inAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, S. Koyejo, S. Mohamed, A. Agarwal, D. Bel...
2022
-
[25]
Available: http://papers.nips.cc/paper_files/paper/2022/ hash/35b5c175e139bff5f22a5361270fce87-Abstract-Conference.html
[Online]. Available: http://papers.nips.cc/paper_files/paper/2022/ hash/35b5c175e139bff5f22a5361270fce87-Abstract-Conference.html
2022
-
[26]
J. Li, S. Liu, and Q. Lei, “Beyond gradient and priors in privacy attacks: Leveraging pooler layer inputs of language models in federated learning,”CoRR, vol. abs/2312.05720, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2312.05720
-
[27]
DAGER: exact gradient inversion for large language models,
I. Petrov, D. I. Dimitrov, M. Baader, M. N. Müller, and M. T. Vechev, “DAGER: exact gradient inversion for large language models,” inAdvances in Neural Information Processing Systems 37: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, A. Globersons, L. Mackey, D. Belgrave, A. Fa...
2024
-
[28]
Gemma Team, “Gemma 3,” 2025. [Online]. Available: https: //arxiv.org/abs/2503.19786
Pith/arXiv arXiv 2025
-
[29]
Embeddinggemma: Powerful and lightweight text representations,
H. Schechter Vera, S. Dua, and EmbeddingGemma Team, “Embeddinggemma: Powerful and lightweight text representations,”
-
[30]
Available: https://arxiv.org/abs/2509.20354
[Online]. Available: https://arxiv.org/abs/2509.20354
-
[31]
Google Research and Google DeepMind, “Medgemma technical report,”CoRR, vol. abs/2507.05201, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2507.05201
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.05201 2025
-
[32]
A. Sellergren, C. Gao, F. Mahvar, T. Kohlberger, F. Jamil, M. Traverse, A. Tono, B. Sadjad, L. Yang, C. Lau, L. Yatziv, T. L. Chen, B. Sterling, K. Philbrick, R. Tiwari, Y . Liu, M. Jajoo, C. Sankarapu, S. Vispute, H. Purandare, A. B. Mishra, S. Schmidgall, T. Tu, A. Palepu, C. Park, T. Strother, R. Thapa, Y . Cheng, P. Singh, K. Black, Y . Matias, K. Cho...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.05081 2026
-
[33]
D. Huang, T. Drietomsky, B. Barrett, and Z. Wang, “How small can you go? lora fine-tuning 270m-8b models for merchant information extraction in financial transactions,” 2026. [Online]. Available: https://arxiv.org/abs/2606.08051
Pith/arXiv arXiv 2026
-
[34]
An extended annotation scheme for personal-fact classification in dialogue,
K. Zaitsev, “An extended annotation scheme for personal-fact classification in dialogue,” 2026, model: https://huggingface.co/adugeen/personal- facts-classifier-embeddinggemma-300m; Dataset: https://huggingface.co/datasets/adugeen/personal-facts-msc
2026
-
[35]
Pointer sentinel mixture models,
S. Merity, C. Xiong, J. Bradbury, and R. Socher, “Pointer sentinel mixture models,” 2016
2016
-
[36]
ROUGE: A package for automatic evaluation of summaries,
C.-Y . Lin, “ROUGE: A package for automatic evaluation of summaries,” inText Summarization Branches Out. Barcelona, Spain: Association for Computational Linguistics, Jul. 2004, pp. 74–81. [Online]. Available: https://aclanthology.org/W04-1013/
2004
-
[37]
R-GAP: recursive gradient attack on privacy,
J. Zhu and M. B. Blaschko, “R-GAP: recursive gradient attack on privacy,” in9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3- 7, 2021. OpenReview.net, 2021. [Online]. Available: https: //openreview.net/forum?id=RSU17UoKfJF
2021
-
[38]
Towards general deep leakage in federated learning,
J. Geng, Y . Mou, F. Li, Q. Li, O. Beyan, S. Decker, and C. Rong, “Towards general deep leakage in federated learning,”CoRR, vol. abs/2110.09074, 2021. [Online]. Available: https://arxiv.org/abs/2110.09074
arXiv 2021
-
[39]
SPEAR: exact gradient inversion of batches in federated learning,
D. I. Dimitrov, M. Baader, M. N. Müller, and M. T. Vechev, “SPEAR: exact gradient inversion of batches in federated learning,” inAdvances in Neural Information Processing Systems 37: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, A. Globersons, L. Mackey, D. Belgrave, A. Fan, U...
2024
-
[40]
SPEAR++: scaling gradient inversion via sparsely-used dictionary learning,
A. Bakarsky, D. I. Dimitrov, M. Baader, and M. T. Vechev, “SPEAR++: scaling gradient inversion via sparsely-used dictionary learning,”CoRR, vol. abs/2510.24200, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2510.24200
-
[41]
Robbing the fed: Directly obtaining private data in federated learning with modified models,
L. H. Fowl, J. Geiping, W. Czaja, M. Goldblum, and T. Goldstein, “Robbing the fed: Directly obtaining private data in federated learning with modified models,” inThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022. [Online]. Available: https://openreview.net/forum?id=fwzUgo0FM9v
2022
-
[42]
Fishing for user data in large-batch federated learning via gradient magnification,
Y . Wen, J. Geiping, L. Fowl, M. Goldblum, and T. Goldstein, “Fishing for user data in large-batch federated learning via gradient magnification,” inInternational Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, ser. Proceedings of Machine Learning Research, K. Chaudhuri, S. Jegelka, L. Song, C. Szepesvári, G. Niu, and...
2022
-
[43]
Decepticons: Corrupted transformers breach privacy in federated learning for language models,
L. H. Fowl, J. Geiping, S. Reich, Y . Wen, W. Czaja, M. Goldblum, and T. Goldstein, “Decepticons: Corrupted transformers breach privacy in federated learning for language models,” inThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. [Online]. Available: https://openreview.net/...
2023
-
[44]
Panning for gold in federated learning: Targeted text extraction under arbitrarily large-scale aggregation,
H. Chu, J. Geiping, L. H. Fowl, M. Goldblum, and T. Goldstein, “Panning for gold in federated learning: Targeted text extraction under arbitrarily large-scale aggregation,” inThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. [Online]. Available: https://openreview.net/forum?i...
2023
-
[45]
Minegrad: Gradient inversion attacks on loRA fine-tuning,
H. U. Sami, S. Sen, and B. Guler, “Minegrad: Gradient inversion attacks on loRA fine-tuning,” inThe 29th International Conference on Artificial Intelligence and Statistics, 2026. [Online]. Available: https://openreview.net/forum?id=dD9XOZUpNc
2026
-
[46]
J. Lu, X. S. Zhang, T. Zhao, X. He, and J. Cheng, “APRIL: finding the achilles’ heel on privacy for vision transformers,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18- 24, 2022. IEEE, 2022, pp. 10 041–10 050. [Online]. Available: https://doi.org/10.1109/CVPR52688.2022.00981
-
[47]
GRAIN: exact graph reconstruction from gradients,
M. Drencheva, I. Petrov, M. Baader, D. I. Dimitrov, and M. T. Vechev, “GRAIN: exact graph reconstruction from gradients,” inThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. [Online]. Available: https://openreview.net/forum?id=7bAjVh3CG3
2025
-
[48]
In: Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, pp
M. Abadi, A. Chu, I. J. Goodfellow, H. B. McMahan, I. Mironov, K. Talwar, and L. Zhang, “Deep learning with differential privacy,” inProceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, October 24-28, 2016, E. R. Weippl, S. Katzenbeisser, C. Kruegel, A. C. Myers, and S. Halevi, Eds. ACM, 2016, pp. 308–318...
-
[49]
A fictional q&a dataset for studying memorization and knowledge acquisition,
J. Kirchenbauer, J. Mongkolsupawan, Y . Wen, T. Goldstein, and D. Ippolito, “A fictional q&a dataset for studying memorization and knowledge acquisition,”CoRR, vol. abs/2506.05639, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2506.05639
-
[50]
Learning word vectors for sentiment analysis,
A. L. Maas, R. E. Daly, P. T. Pham, D. Huang, A. Y . Ng, and C. Potts, “Learning word vectors for sentiment analysis,” inProceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Portland, Oregon, USA: Association for Computational Linguistics, June 2011, pp. 142–150. [Online]. Available: http://...
2011
-
[52]
Available: http://arxiv.org/abs/1712.07557
[Online]. Available: http://arxiv.org/abs/1712.07557
-
[53]
Differentially private learning with adaptive clipping,
G. Andrew, O. Thakkar, B. McMahan, and S. Ramaswamy, “Differentially private learning with adaptive clipping,” inAdvances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, M. Ranzato, A. Beygelzimer, Y . N. Dauphin, P. Liang, and J. W. Vaughan, Eds., 20...
2021
-
[54]
Differentially private learning with per-sample adaptive clipping,
T. Xia, S. Shen, S. Yao, X. Fu, K. Xu, X. Xu, and X. Fu, “Differentially private learning with per-sample adaptive clipping,” inThirty-Seventh AAAI Conference on Artificial Intelligence, AAAI 2023, Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence, IAAI 2023, Thirteenth Symposium on Educational Advances in Artificial Intelligen...
-
[55]
Federated learning: Strategies for improving communication efficiency,
J. Kone ˇcný, H. B. McMahan, F. X. Yu, P. Richtárik, A. T. Suresh, and D. Bacon, “Federated learning: Strategies for improving communication efficiency,”CoRR, vol. abs/1610.05492, 2016. [Online]. Available: http://arxiv.org/abs/1610.05492
Pith/arXiv arXiv 2016
-
[56]
Brendan and Patel, Sarvar and Ramage, Daniel and Segal, Aaron and Seth, Karn , title =
K. A. Bonawitz, V . Ivanov, B. Kreuter, A. Marcedone, H. B. McMahan, S. Patel, D. Ramage, A. Segal, and K. Seth, “Practical secure aggregation for privacy-preserving machine learning,” in Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, CCS 2017, Dallas, TX, USA, October 30 - November 03, 2017, B. Thuraisingham, D. Ev...
-
[57]
Deep gradient compression: Reducing the communication bandwidth for distributed training,
Y . Lin, S. Han, H. Mao, Y . Wang, and B. Dally, “Deep gradient compression: Reducing the communication bandwidth for distributed training,” in6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net, 2018. [Online]. Available: https://openreview.net/fo...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.