Convex--Concave Quadratic Spectral Filtering for Graph Neural Networks
Pith reviewed 2026-06-26 00:47 UTC · model grok-4.3
The pith
DCQ-GNN achieves high spectral selectivity on heterophilic graphs by fusing a bank of order-two convex-concave quadratic filters through node-adaptive gating.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
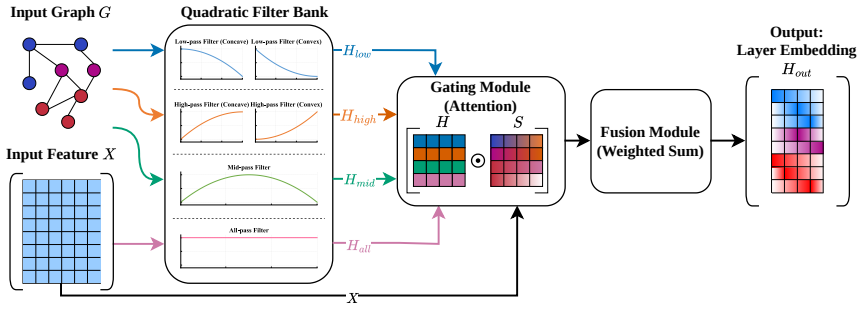
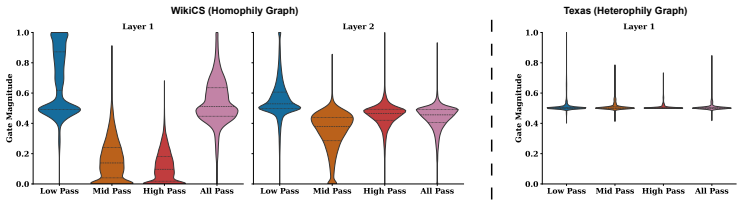
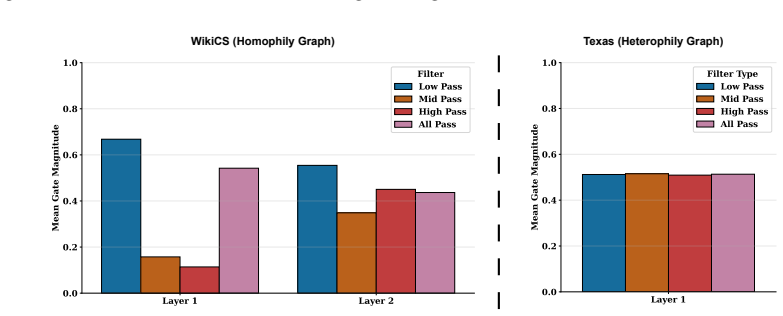
DCQ-GNN is a spectral GNN based on a compact bank of adaptive convex-concave quadratic filters. By restricting the filter order to two while explicitly exploiting complementary curvature, DCQ-GNN improves spectral selectivity as quantified by Dirichlet energy and entropy measures without resorting to high-order polynomial expansions. The model fuses filter outputs through a node-adaptive gating mechanism to enable node-wise structure-aware spectral selection. Formal analysis grounded in Dirichlet energy attenuation, von Neumann entropy, and curvature polarity derives explicit characterizations of filter behavior across varying homophily levels and structural perturbations. Benchmarks on ten
What carries the argument
A compact bank of adaptive convex-concave quadratic filters fused by node-adaptive gating that exploits complementary curvature for selectivity at fixed order two.
If this is right
- Ties for the top average rank (3.0) among compared models on heterophilic graphs.
- Obtains the second-best rank (4.2) on homophilic graphs.
- Exhibits substantially smaller performance degradation than both first-order and high-order baselines under strong structural perturbations.
- Improves spectral selectivity metrics without increasing filter order or optimization difficulty.
- Remains competitive with representative high-order polynomial spectral filters while preserving stability and efficiency.
Where Pith is reading between the lines
- The same curvature-polarity idea could be tested on temporal or dynamic graphs to see whether node gating still selects useful frequencies when edges change over time.
- If the quadratic bank generalizes, it may reduce the incentive to stack many layers or high-order terms in production graph models, lowering memory use during inference.
- The explicit characterizations of filter response across homophily levels suggest a way to diagnose when a given graph would benefit from this filter type before training.
Load-bearing premise
The node-adaptive gating mechanism combined with the quadratic filter bank enables effective structure-aware spectral selection that generalizes across varying homophily levels and perturbations.
What would settle it
A controlled experiment on additional heterophilic graphs where the quadratic bank shows no improvement in Dirichlet energy attenuation or entropy relative to a plain first-order filter would falsify the selectivity claim.
Figures

read the original abstract
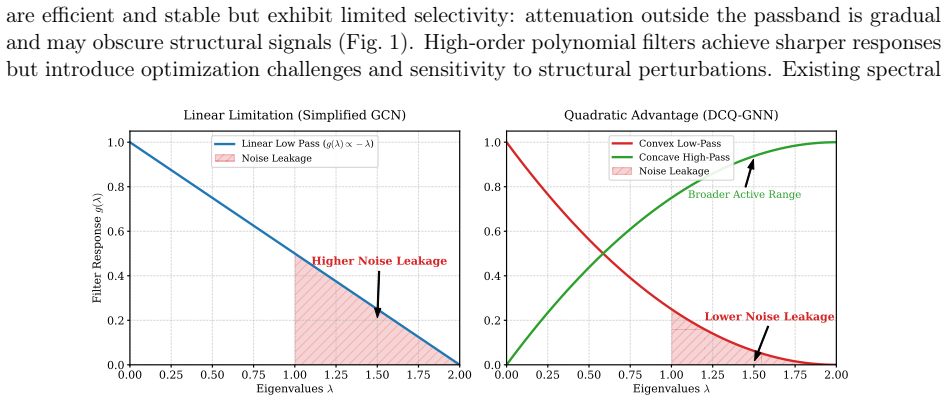
Spectral graph neural networks (GNNs) interpret message passing as frequency-selective filtering. While low-order spectral filters are efficient, their limited selectivity often leads to weak attenuation outside the passband, whereas high-order alternatives introduce optimization challenges. We propose DCQ-GNN, a spectral GNN based on a compact bank of adaptive convex--concave quadratic filters. By restricting the filter order to two while explicitly exploiting complementary curvature, DCQ-GNN improves spectral selectivity as quantified by Dirichlet energy and entropy measures without resorting to high-order polynomial expansions. The model fuses filter outputs through a node-adaptive gating mechanism to enable node-wise structure-aware spectral selection. We provide a formal spectral analysis grounded in Dirichlet energy attenuation, von Neumann entropy, and curvature polarity, and derive explicit characterizations of filter behavior across varying levels of homophily and structural perturbations. Extensive benchmarks on 10 datasets show that DCQ-GNN ties for the top average rank (3.0) on heterophilic graphs and obtains the second-best rank (4.2) on homophilic graphs, remaining competitive with representative high-order polynomial spectral filters. Furthermore, under strong structural perturbations, DCQ-GNN exhibits substantially smaller performance degradation compared to both first-order and high-order baselines. These results demonstrate that curvature-aware quadratic banks provide a robust and efficient alternative to high-order spectral models while preserving optimization stability and computational efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DCQ-GNN, a spectral GNN using a bank of adaptive convex-concave quadratic filters restricted to order two that exploits complementary curvature for improved selectivity (measured via Dirichlet energy attenuation and von Neumann entropy). A node-adaptive gating mechanism fuses the filter outputs to enable node-wise structure-aware selection. The work provides formal spectral analysis characterizing behavior across homophily levels and structural perturbations, and reports competitive benchmark performance (top average rank 3.0 on heterophilic graphs, second-best 4.2 on homophilic graphs across 10 datasets) with reduced degradation under perturbations relative to first- and high-order baselines.
Significance. If the formal analysis and empirical claims hold, the result offers an efficient low-order alternative to high-order polynomial spectral filters while preserving optimization stability. Strengths include the explicit curvature-based design, the formal characterizations grounded in Dirichlet energy, entropy, and curvature polarity, and the extensive benchmark evaluation on 10 datasets with perturbation robustness tests.
major comments (2)
- [§3.2] §3.2 (node-adaptive gating mechanism): The claim that the gating 'enables node-wise structure-aware spectral selection' and that the formal analysis derives explicit characterizations across homophily levels requires showing that the gating is a direct function of the convex-concave filter curvatures rather than a learned feature-dependent module; otherwise the analysis describes filter properties without establishing generalization of the selection step on unseen graphs.
- [§4] §4 (formal spectral analysis): The derivations of Dirichlet energy attenuation and curvature polarity for the quadratic bank plus gating must include the explicit interaction equations between the node-adaptive weights and the quadratic coefficients; without these steps the downstream benchmark ranks and perturbation robustness cannot be directly attributed to the claimed structure-aware selection.
minor comments (2)
- [Abstract] Abstract: the reported average ranks (3.0 and 4.2) should be accompanied by the number of datasets per category and a brief note on variance or error bars to allow immediate assessment of the competitiveness claim.
- [Figures] Figure captions for the energy/entropy plots should specify the exact homophily ranges and perturbation strengths used so that the visual comparisons can be reproduced from the text alone.
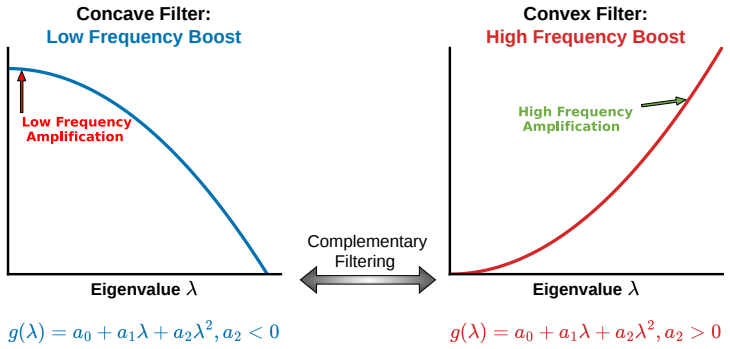
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below.
read point-by-point responses
-
Referee: [§3.2] §3.2 (node-adaptive gating mechanism): The claim that the gating 'enables node-wise structure-aware spectral selection' and that the formal analysis derives explicit characterizations across homophily levels requires showing that the gating is a direct function of the convex-concave filter curvatures rather than a learned feature-dependent module; otherwise the analysis describes filter properties without establishing generalization of the selection step on unseen graphs.
Authors: The gating is implemented as a learned module that produces node-specific fusion weights from features. The formal analysis characterizes the quadratic filters' spectral properties (Dirichlet energy, entropy, curvature polarity) across homophily levels; the gating enables practical node-wise selection but is not derived solely from curvatures. We will revise §3.2 to clarify this distinction and discuss how the learned weights interact with the curvature-aware filters to support the claimed generalization. revision: partial
-
Referee: [§4] §4 (formal spectral analysis): The derivations of Dirichlet energy attenuation and curvature polarity for the quadratic bank plus gating must include the explicit interaction equations between the node-adaptive weights and the quadratic coefficients; without these steps the downstream benchmark ranks and perturbation robustness cannot be directly attributed to the claimed structure-aware selection.
Authors: We agree that explicit equations showing how node-adaptive weights combine with the quadratic coefficients are needed to rigorously attribute performance to structure-aware selection. The current §4 derives filter-level characterizations but omits these interaction steps. We will add the required equations in the revision. revision: yes
Circularity Check
No circularity: claims rest on external benchmarks and independent formal analysis
full rationale
The paper presents DCQ-GNN via a quadratic filter bank and node-adaptive gating, with spectral selectivity quantified by Dirichlet energy, entropy, and curvature polarity. Performance is evaluated on 10 external datasets with reported ranks and perturbation robustness. No equations, self-citations, or definitions are exhibited that reduce the claimed improvements, selectivity, or generalization to fitted inputs or prior self-work by construction. The derivation chain remains self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Optuna: A next-generation hyperparameter optimization framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 3023–3031, 2019
2019
-
[2]
On the bottleneck of graph neural networks and its practical implications
Uri Alon and Eran Yahav. On the bottleneck of graph neural networks and its practical implications. InInternational Conference on Learning Representations, 2021
2021
-
[3]
Analyzing the expressive power of graph neural networks in a spectral perspec- tive
Muhammet Balcilar, Guillaume Renton, Pierre Héroux, Benoit Gaüzère, Sébastien Adam, and Paul Honeine. Analyzing the expressive power of graph neural networks in a spectral perspec- tive. InInternational Conference on Learning Representations, 2021
2021
-
[4]
Beyond low-frequency information in graph convolutional networks
Deyu Bo, Xiao Wang, Chuan Shi, and Huawei Shen. Beyond low-frequency information in graph convolutional networks. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 3950–3957, 2021
2021
-
[5]
The anatomy of a large-scale hypertextual web search engine
Sergey Brin and Lawrence Page. The anatomy of a large-scale hypertextual web search engine. Computer Networks and ISDN Systems, 30(1-7):107–117, 1998
1998
-
[6]
Spectral networks and locally connected networks on graphs
Joan Bruna, Wojciech Zaremba, Arthur Szlam, and Yann LeCun. Spectral networks and locally connected networks on graphs. InInternational Conference on Learning Representations, 2014
2014
-
[7]
Bronstein, Stefan Webb, and Emanuele Rossi
Ben Chamberlain, James Rowbottom, Maria I Gorinova, Michael M. Bronstein, Stefan Webb, and Emanuele Rossi. Grand: Graph neural diffusion. InInternational Conference on Machine Learning, pages 1407–1418, 2021
2021
-
[8]
Simple and deep graph convolutional networks
Ming Chen, Zhewei Wei, Zengfeng Huang, Bolin Ding, and Yaliang Li. Simple and deep graph convolutional networks. InInternational Conference on Machine Learning, pages 1725–1735, 2020
2020
-
[9]
Adaptive universal generalized pager- ank graph neural network
Eli Chien, Jianhao Peng, Pan Li, and Olgica Milenkovic. Adaptive universal generalized pager- ank graph neural network. InInternational Conference on Learning Representations, 2021. 14
2021
-
[10]
Convolutional neural networks on graphs with fast localized spectral filtering
Michaël Defferrard, Xavier Bresson, and Pierre Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. InAdvances in Neural Information Processing Systems, volume 29, pages 3844–3852, 2016
2016
-
[11]
Inductive representation learning on large graphs
Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. InAdvances in Neural Information Processing Systems, volume 30, pages 1024–1034, 2017
2017
-
[12]
Bernnet: Learning arbitrary graph spectral filters via bernstein approximation
Mingguo He, Zhewei Wei, Hongteng Xu, Zuozhu Liu, Wei Ju, Xiaofei Zhang, and Chang-Tsun Li. Bernnet: Learning arbitrary graph spectral filters via bernstein approximation. InAdvances in Neural Information Processing Systems, volume 34, pages 14239–14251, 2021
2021
-
[13]
Robust mid- pass filtering graph convolutional networks
Jincheng Huang, Lun Du, Xu Chen, Qiang Fu, Shi Han, and Dongmei Zhang. Robust mid- pass filtering graph convolutional networks. InProceedings of the ACM Web Conference, pages 328–338, 2023
2023
-
[14]
How universal polynomial bases enhance spectral graph neural networks: Heterophily, over-smoothing, and over-squashing
Keke Huang, Yu Guang Wang, Ming Li, and Pietro Lio. How universal polynomial bases enhance spectral graph neural networks: Heterophily, over-smoothing, and over-squashing. In International Conference on Machine Learning, pages 20310–20330, 2024
2024
-
[15]
Semi-supervised classification with graph convolutional networks
Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. InInternational Conference on Learning Representations, 2017
2017
-
[16]
Evennet: Ignoring odd-hop neighbors improves robustness of graph neural networks
Runlin Lei, Zhen Wang, Yaliang Li, Bolin Ding, and Zhewei Wei. Evennet: Ignoring odd-hop neighbors improves robustness of graph neural networks. InAdvances in Neural Information Processing Systems, volume 35, pages 4694–4706, 2022
2022
-
[17]
Cayleynets: Graph convolutional neural networks with complex rational spectral filters.IEEE Transactions on Signal Processing, 67(1):97–109, 2019
Ron Levie, Federico Monti, Xavier Bresson, and Michael M Bronstein. Cayleynets: Graph convolutional neural networks with complex rational spectral filters.IEEE Transactions on Signal Processing, 67(1):97–109, 2019
2019
-
[18]
Revisiting heterophily for graph neural networks
Sitao Luan, Chenqing hugging Hua, Qincheng Lu, Jiaqi Zhu, Mingde Zhao, Shuyuan Zhang, Xiao-Wen Chang, and Doina Precup. Revisiting heterophily for graph neural networks. In Advances in Neural Information Processing Systems, volume 35, pages 1362–1375, 2022
2022
-
[19]
Wiki-cs: A wikipedia-based benchmark for graph neural networks.arXiv preprint arXiv:2007.02901, 2020
Péter Mernyei and Cătălina Cangea. Wiki-cs: A wikipedia-based benchmark for graph neural networks.arXiv preprint arXiv:2007.02901, 2020
arXiv 2007
-
[20]
Autosgnn: automatic prop- agation mechanism discovery for spectral graph neural networks
Shibing Mo, Kai Wu, Qixuan Gao, Xiangyi Teng, and Jing Liu. Autosgnn: automatic prop- agation mechanism discovery for spectral graph neural networks. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 19493–19502, 2025
2025
-
[21]
Geom-gcn: Geo- metric graph convolutional networks
Hongbin Pei, Bingzhe Wei, Kevin Chen Chuan Chang, Yu Lei, and Bo Yang. Geom-gcn: Geo- metric graph convolutional networks. InInternational Conference on Learning Representations, 2020
2020
-
[22]
Localized heat kernel for graph neural networks
Taoyang Qin, Ke-Jia Chen, and Zheng Liu. Localized heat kernel for graph neural networks. In European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD), pages 457–473, 2025
2025
-
[23]
Recipe for a general, powerful, scalable graph transformer
Ladislav Rampášek, Mikhail Galkin, Vijay Prakash Dwivedi, Anh Tuan Luu, Guy Wolf, and Dominique Beaini. Recipe for a general, powerful, scalable graph transformer. InAdvances in Neural Information Processing Systems, volume 35, pages 14712–14725, 2022. 15
2022
-
[24]
Multi-scale attributed node embedding
Benedek Rozemberczki, Carl Allen, and Rik Sarkar. Multi-scale attributed node embedding. Journal of Complex Networks, 9(2):cnab014, 2021
2021
-
[25]
Konstantin Rusch, Ben P
T. Konstantin Rusch, Ben P. Chamberlain, James Rowbottom, Siddhartha Mishra, and Michael M. Bronstein. Graph-coupled oscillator networks. InInternational Conference on Machine Learning, pages 18881–18909, 2022
2022
-
[26]
Pitfalls of graph neural network evaluation
Oleksandr Shchur, Maximilian Mumme, Aleksandar Bojchevski, and Stephan Günnemann. Pitfalls of graph neural network evaluation. 2018
2018
-
[27]
David I Shuman, Sunil K Narang, Pascal Frossard, Antonio Ortega, and Pierre Vandergheynst. The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains.IEEE Signal Processing Magazine, 30(3):83–98, 2013
2013
-
[28]
Graph attention networks
Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. Graph attention networks. InInternational Conference on Learning Rep- resentations, 2018
2018
-
[29]
How powerful are spectral graph neural networks
Xiyuan Wang and Muhan Zhang. How powerful are spectral graph neural networks. InInter- national Conference on Machine Learning, pages 23341–23362, 2022
2022
-
[30]
Beyond low-pass filtering: Graph convolutional networks with automatic filtering.IEEE Transactions on Knowl- edge and Data Engineering, 35(7):6687–6697, 2022
Zonghan Wu, Shirui Pan, Guodong Long, Jing Jiang, and Chengqi Zhang. Beyond low-pass filtering: Graph convolutional networks with automatic filtering.IEEE Transactions on Knowl- edge and Data Engineering, 35(7):6687–6697, 2022
2022
-
[31]
Representation learning on graphs with jumping knowledge networks
Keyulu Xu, Chengtao Li, Yonglong Tian, Tomohiro Sonobe, Ken-ichi Kawarabayashi, and Stefanie Jegelka. Representation learning on graphs with jumping knowledge networks. In International Conference on Machine Learning, pages 5453–5462, 2018
2018
-
[32]
Revisiting semi-supervised learning with graph embeddings
Zhilin Yang, William Cohen, and Ruslan Salakhutdinov. Revisiting semi-supervised learning with graph embeddings. InInternational Conference on Machine Learning, pages 40–48, 2016
2016
-
[33]
Do transformers really perform bad for graph representation? InAdvances in Neural Information Processing Systems, volume 34, pages 28877–28888, 2021
Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, and Tie-Yan Liu. Do transformers really perform bad for graph representation? InAdvances in Neural Information Processing Systems, volume 34, pages 28877–28888, 2021
2021
-
[34]
How framelets enhance graph neural networks
Xuebin Zheng, Bingxin Zhou, Junbin Gao, Yuguang Wang, Pietro Lió, Ming Li, and Guido Montufar. How framelets enhance graph neural networks. InInternational Conference on Machine Learning, pages 12761–12771, 2021
2021
-
[35]
Beyond homophily in graph neural networks: Current limitations and effective designs
Jiong Zhu, Yujun Yan, Lingxiao Zhao, Mark Heimann, Leman Akoglu, and Danai Koutra. Beyond homophily in graph neural networks: Current limitations and effective designs. In Advances in Neural Information Processing Systems, volume 33, pages 7793–7804, 2020
2020
-
[36]
roll-off
Daniel Zügner, Amir Akbarnejad, and Stephan Günnemann. Adversarial attacks on neural networks for graph data. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 2847–2856, 2018. 16 Appendices A Notation Table 6 summarizes the key notations and symbols used throughout this paper. Table 6: Key notations...
2018
-
[37]
For any pair of non-trivial frequencies such that sgn(a1) =sgn(a 2(λ1 +λ 2)), the absolute difference satisfies: |gq(λ1)−g q(λ2)|=|(λ 1 −λ 2)| · |a1 +a 2(λ1 +λ 2)|>|a 1(λ1 −λ 2)|
= (λ1 −λ 2) [a1 +a 2(λ1 +λ 2)]. For any pair of non-trivial frequencies such that sgn(a1) =sgn(a 2(λ1 +λ 2)), the absolute difference satisfies: |gq(λ1)−g q(λ2)|=|(λ 1 −λ 2)| · |a1 +a 2(λ1 +λ 2)|>|a 1(λ1 −λ 2)|. This amplification of the spectral distance confirms that the quadratic terma 2λ2 increases the filter’s sensitivity to frequency variations, par...
-
[38]
dense split
= (λ2 −λ 1) [a1 +a 2(λ1 +λ 2)]. Sinceλ 1 +λ 2 >0for all non-trivial eigenvalues, the sign of the second-order coefficienta2 governs the monotonicity of the gain relative to the frequency magnitude. Specifically,a2 >0induces a positive curvature that scales the gain withλ, whereasa2 <0imposes a concave penalty on higher frequencies. This proves that curvat...
1961
-
[39]
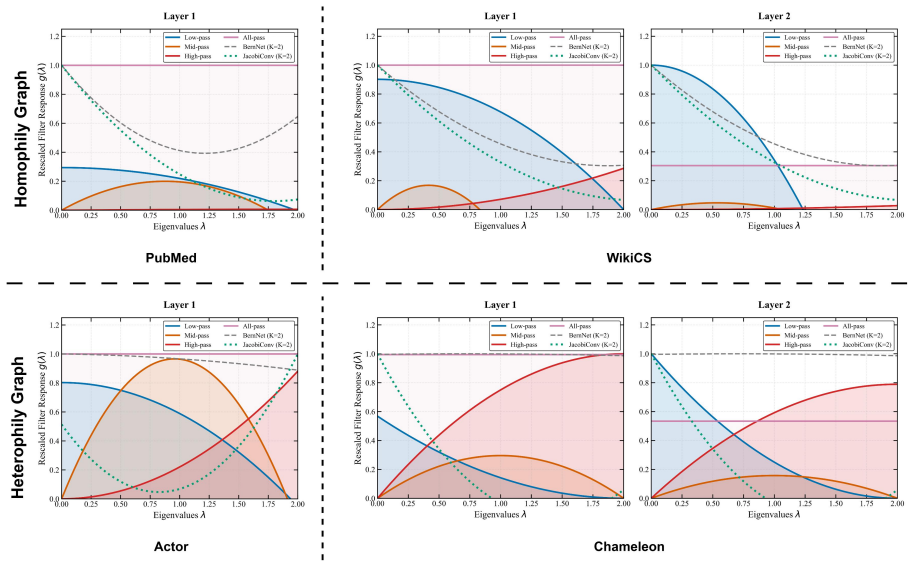
Shaded regions denote the explicit frequency channels learned by DCQ-GNN
polynomial baselines on homophilic (PubMed, WikiCS) and heterophilic (Actor, Chameleon) graphs. Shaded regions denote the explicit frequency channels learned by DCQ-GNN. nodes per class). Although this protocol modifies the inherent class imbalance, it is widely adopted in contemporary spectral GNN literature. For completeness, we include two recent basel...
-
[40]
GCN [15] further simplifies this formulation to a first-order polynomial approximation, resulting in an efficient and widely adopted low-pass operator
alleviates this issue by approximating spectral filters using Chebyshev polynomials, enabling localized and efficient propagation without explicit eigenvectors. GCN [15] further simplifies this formulation to a first-order polynomial approximation, resulting in an efficient and widely adopted low-pass operator. Many spatial GNN architectures can be interp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.