Intelligent Character Recognition of Handwritten Forms with Deep Neural Networks
Pith reviewed 2026-06-27 18:27 UTC · model grok-4.3
The pith
A single deep neural network executes both detection and classification of handwritten characters on forms and reaches 88.28 percent accuracy on real exam data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors demonstrate that a deep neural network trained to carry out both detection and classification in a single task, using training data manufactured by overlaying EMNIST letters onto the underlying forms, is superior to the state-of-the-art two-task approach and attains an overall recognition rate of 88.28 percent on real handwritten exam data.
What carries the argument
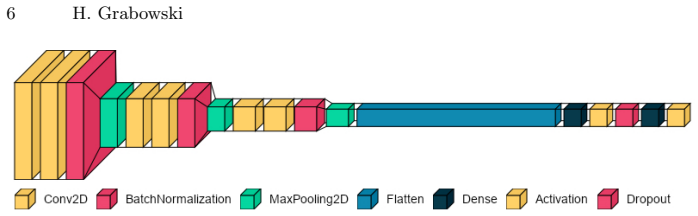
A unified deep neural network that integrates character detection and classification into one task, trained on artificially generated data.
If this is right
- The single-task network outperforms the standard two-task method on the same forms.
- An overall recognition rate of 88.28 percent is obtained on real handwritten exam data.
- The approach is applied to handwritten Latin letters using the EMNIST dataset.
- Limitations observed in the EMNIST dataset require further customization of the training data.
Where Pith is reading between the lines
- The artificial-data technique could reduce the labor required to prepare training sets for other handwritten-document tasks.
- If the unified network scales, it may allow end-to-end processing pipelines for forms without intermediate detection modules.
- The same overlay method might be tested on non-Latin scripts once suitable base datasets become available.
Load-bearing premise
Artificially manufactured training data created by overlaying EMNIST letters onto the forms accurately captures the distribution and variability of real handwritten input without introducing systematic biases.
What would settle it
Running the trained model on a fresh collection of real handwritten exam forms from different writers and institutions and checking whether the recognition rate drops substantially below 88.28 percent.
Figures
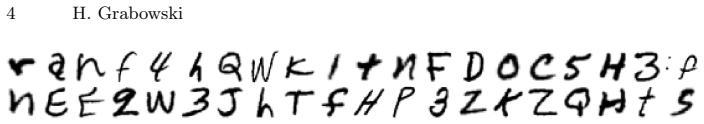


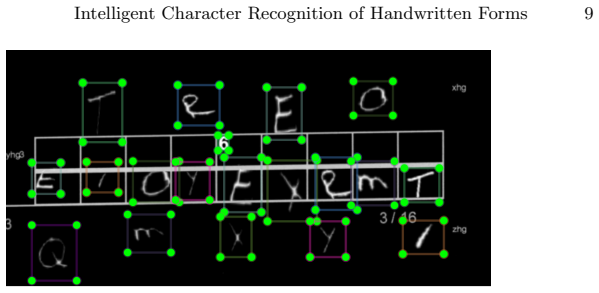
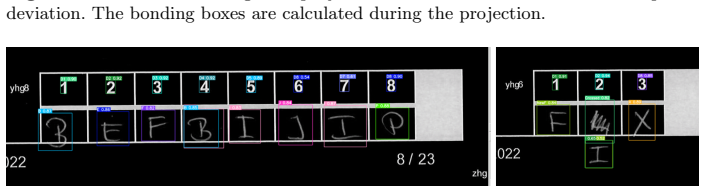



read the original abstract
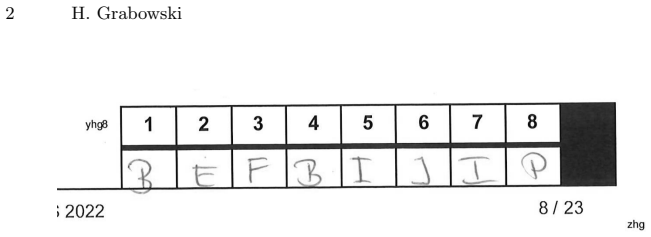
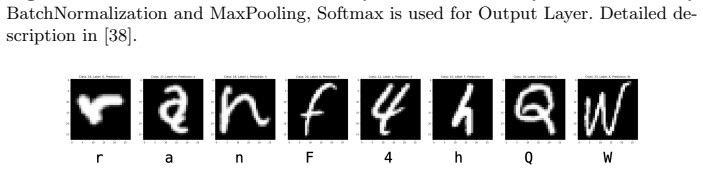
The automatic processing of handwritten forms remains a challenging task, wherein detection and subsequent classification of handwritten characters are essential steps. We describe a novel approach, in which both steps -- detection and classification -- are executed in one task through a deep neural network. Therefore, training data is not annotated by hand, but manufactured artificially from the underlying forms and yet existing datasets. It can be demonstrated that this single-task approach is superior in comparison to the state-of-the-art two-task approach. The current study focuses on hand-written Latin letters and employs the EMNIST data set. However, limitations were identified with this data set, necessitating further customization. Finally, an overall recognition rate of 88.28 percent was attained on real data obtained from a written exam.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a single deep neural network that jointly executes detection and classification of handwritten Latin letters on forms, trained on synthetically manufactured data created by overlaying EMNIST characters onto form templates rather than using manual annotations. It claims this unified approach is superior to the conventional state-of-the-art two-task pipeline and reports an overall recognition rate of 88.28% when evaluated on real handwritten exam data, while noting limitations in the EMNIST dataset that required customization.
Significance. If the central claims are substantiated with full methodological details and validation, the work could offer a practical simplification for handwritten form processing by collapsing separate detection and classification stages into one model, with the synthetic data generation method providing a scalable alternative to manual labeling. This would be relevant for applications such as automated exam grading, though the result's impact depends on demonstrating that the performance gain is not an artifact of the training distribution.
major comments (2)
- [Abstract] Abstract and results description: the superiority claim over the two-task baseline and the specific 88.28% recognition rate are presented without any architecture details, training protocol, baseline implementations, error analysis, or statistical tests, rendering the central performance and superiority assertions unverifiable from the manuscript.
- [Data generation / methods] Data generation section: the claim that artificially overlaid EMNIST characters suffice for training a model that generalizes to real exam forms rests on the untested assumption that this synthetic distribution matches real handwriting variability (slant, pressure, connected strokes, form noise); no quantitative checks such as feature histograms, domain-adaptation metrics, or ablation on real vs. synthetic test sets are reported, which directly undermines the generalization and superiority conclusions.
minor comments (1)
- [Abstract] The abstract mentions EMNIST limitations requiring customization but provides no description of the specific modifications made or their impact on the final model.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and indicate planned revisions to improve verifiability and support for the generalization claims.
read point-by-point responses
-
Referee: [Abstract] Abstract and results description: the superiority claim over the two-task baseline and the specific 88.28% recognition rate are presented without any architecture details, training protocol, baseline implementations, error analysis, or statistical tests, rendering the central performance and superiority assertions unverifiable from the manuscript.
Authors: The full manuscript provides architecture details (Section 3), training protocol (Section 4), baseline comparisons (Section 5.2), and error analysis (Section 5.3). The abstract is intentionally concise per journal norms but we agree it should be expanded for standalone clarity. We will revise the abstract to summarize key architecture elements, training protocol, and include the 88.28% result with context. Statistical significance tests comparing the single-task and two-task approaches will be added to the results section. revision: partial
-
Referee: [Data generation / methods] Data generation section: the claim that artificially overlaid EMNIST characters suffice for training a model that generalizes to real exam forms rests on the untested assumption that this synthetic distribution matches real handwriting variability (slant, pressure, connected strokes, form noise); no quantitative checks such as feature histograms, domain-adaptation metrics, or ablation on real vs. synthetic test sets are reported, which directly undermines the generalization and superiority conclusions.
Authors: The manuscript evaluates the model directly on real exam forms and explicitly notes EMNIST limitations plus required customizations. We agree that explicit domain-gap quantification would strengthen the generalization argument. In revision we will add feature histogram comparisons between synthetic and real data plus an ablation study reporting performance on held-out real versus synthetic test sets. revision: yes
Circularity Check
No circularity: empirical claim with no derivation chain or self-referential fitting
full rationale
The paper describes an empirical deep-learning pipeline that trains a single network on synthetically overlaid EMNIST data and reports 88.28 % recognition on held-out real exam forms. No equations, fitted parameters, or mathematical derivations are present that could reduce to self-definition, fitted-input-as-prediction, or self-citation load-bearing. The superiority claim is an experimental comparison against a two-task baseline; it does not rely on any internal construction that forces the outcome. The distribution-match assumption between synthetic and real handwriting is a standard generalization risk, not a circularity in any derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Image classification on emnist-letters.https://paperswithcode.com/sota/ image-classification-on-emnist-letters, last accessed 2023/04/05
2023
-
[2]
Adriano, J.E.M., Calma, K.A.S., Lopez, N.T., Parado, J.A., Rabago, L.W., Cabardo, J.M.: Digital conversion model for hand-filled forms using optical char- acter recognition (ocr). IOP Conf. Ser.: Mater. Sci. Eng.482, 012049 (2019). https://doi.org/10.1088/1757-899X/482/1/012049
-
[3]
In: Couprie, M., Cousty, J., Kenmochi, Y., Mustafa, N
Alh´ eriti` ere, H., Ama¨ ıeur, W., Cloppet, F., Kurtz, C., Ogier, J.M., Vincent, N.: Straight line reconstruction for fully materialized table extraction in degraded document images. In: Couprie, M., Cousty, J., Kenmochi, Y., Mustafa, N. (eds.) Discrete Geometry for Computer Imagery, pp. 317–329. Springer International Publishing, Cham (2019).https://doi...
-
[4]
Computers in Human Behavior 27, 1834–1839 (2011).https://doi.org/10.1016/j.chb.2011.04.004
Barchard, K.A., Pace, L.A.: Preventing human error: The impact of data entry methods on data accuracy and statistical results. Computers in Human Behavior 27, 1834–1839 (2011).https://doi.org/10.1016/j.chb.2011.04.004
-
[5]
Ciresan, D.C., Meier, U., Gambardella, L.M., Schmidhuber, J.: Convolutional neu- ral network committees for handwritten character classification. In: 2011 Int. Conf. on Document Analysis and Recognition. pp. 1135–1139. IEEE, Beijing, China (2011).https://doi.org/10.1109/ICDAR.2011.229
-
[6]
Cohen, G., Afshar, S., Tapson, J., van Schaik, A.: Emnist: an extension of mnist to handwritten letters.http://arxiv.org/abs/1702.05373(2017)
Pith/arXiv arXiv 2017
-
[7]
Cohen, G., Afshar, S., Tapson, J., van Schaik, A.: Emnist: Extending mnist to handwritten letters. In: 2017 Int. Joint Conf. on Neural Networks (IJCNN). pp. 2921–2926. IEEE, Anchorage, AK, USA (2017).https://doi.org/10.1109/ IJCNN.2017.7966217
arXiv 2017
-
[8]
Computer Science (2005)
Deodhare, D., Suri, N.R., Amit, R.: Preprocessing and image enhancement algo- rithms for a form-based intelligent character recognition system. Computer Science (2005)
2005
-
[9]
In: Singh, S., Singh, M., Apte, C., Perner, P
Gatos, B., Danatsas, D., Pratikakis, I., Perantonis, S.J.: Automatic table detection in document images. In: Singh, S., Singh, M., Apte, C., Perner, P. (eds.) Pattern Recognition and Data Mining, pp. 609–618. Springer Berlin Heidelberg (2005). https://doi.org/10.1007/11551188_67
-
[10]
Gesmundo, A.: A continual development methodology for large-scale multitask dynamic ml systems.http://arxiv.org/abs/2209.07326(2022)
arXiv 2022
-
[11]
Girshick, R.: Fast r-cnn.http://arxiv.org/abs/1504.08083(2015)
Pith/arXiv arXiv 2015
-
[12]
Girshick, R., Donahue, J., Darrell, T., Malik, J.: Rich feature hierarchies for ac- curate object detection and semantic segmentation. In: 2014 IEEE Conf. on Com- puter Vision and Pattern Recognition. pp. 580–587. IEEE, Columbus, OH, USA (2014).https://doi.org/10.1109/CVPR.2014.81
-
[13]
Goswami, R., Sharma, O.P.: A review on character recognition techniques. Int. J. Computer Applications83, 18–23 (2013).https://doi.org/10.5120/14460-2737
-
[14]
Green, E., Krishnamoorthy, M.: Model-based analysis of printed tables. In: Proc. 3rd Int. Conf. on Document Analysis and Recognition. pp. 214–217. IEEE Comput. Soc. Press, Montreal, Canada (1995).https://doi.org/10.1109/ICDAR.1995. 598979
-
[15]
Journal of Information10(2016)
Islam, N., Islam, Z., Noor, N.: A survey on optical character recognition system. Journal of Information10(2016)
2016
-
[16]
Intelligent Character Recognition of Handwritten Forms 13 In: 2019 IEEE Winter Conf
Jayasundara, V., Jayasekara, S., Jayasekara, H., Rajasegaran, J., Seneviratne, S., Rodrigo, R.: Textcaps: Handwritten character recognition with very small datasets. Intelligent Character Recognition of Handwritten Forms 13 In: 2019 IEEE Winter Conf. on Applications of Computer Vision (WACV). pp. 254–262 (2019).https://doi.org/10.1109/WACV.2019.00033
-
[17]
Jeevan, P., Viswanathan, K., Anand, A.S., Sethi, A.: Wavemix: A resource-efficient neural network for image analysis.http://arxiv.org/abs/2205.14375(2023)
arXiv 2023
-
[18]
Jha, M., Kabra, M., Jobanputra, S., Sawant, R.: Automation of cheque transaction using deep learning and optical character recognition. In: 2019 Int. Conf. on Smart Systems and Inventive Technology (ICSSIT). pp. 309–312. IEEE, Tirunelveli, India (2019).https://doi.org/10.1109/ICSSIT46314.2019.8987925
-
[19]
Kabir, H.M.D., Abdar, M., Jalali, S.M.J., Khosravi, A., Atiya, A.F., Nahavandi, S., Srinivasan, D.: Spinalnet: Deep neural network with gradual input.http:// arxiv.org/abs/2007.03347(2022)
arXiv 2007
-
[20]
In: Zhang, Y.D., Mandal, J.K., So-In, C., Thakur, N.V
Khobragade, R.N., Koli, N.A., Lanjewar, V.T.: Challenges in recognition of on- line and off-line compound handwritten characters: A review. In: Zhang, Y.D., Mandal, J.K., So-In, C., Thakur, N.V. (eds.) Smart Trends in Computing and Communications, pp. 375–383. Springer Singapore (2020).https://doi.org/10. 1007/978-981-15-0077-0_38
2020
-
[21]
Khobragade, R.N., Koli, N.A., Makesar, M.S.: A survey on recognition of devnagari script. Int. J. Computer Applications (2013)
2013
-
[22]
Pattern Analysis and Applications5, 31–45 (2002).https://doi.org/10.1007/s100440200004
Khorsheed, M.S.: Off-line arabic character recognition – a review. Pattern Analysis and Applications5, 31–45 (2002).https://doi.org/10.1007/s100440200004
-
[23]
Kumar Shrivastava, S., Chaurasia, P.: Handwritten devanagari lipi using support vector machine. Int. J. Computer Applications43, 20–25 (2012).https://doi. org/10.5120/6220-8785
-
[24]
Li, M., Cui, L., Huang, S., Wei, F., Zhou, M., Li, Z.: Tablebank: A benchmark dataset for table detection and recognition (2019).https://doi.org/10.48550/ ARXIV.1903.01949
arXiv 2019
-
[25]
Li, W., Feng, X.S., Zha, K., Li, S., Zhu, H.S.: Summary of target detection al- gorithms. J. Phys.: Conf. Ser.1757, 012003 (2021).https://doi.org/10.1088/ 1742-6596/1757/1/012003
2021
-
[26]
IEEE Access8, 142642–142668 (2020).https://doi.org/10.1109/ACCESS.2020.3012542
Memon, J., Sami, M., Khan, R.A., Uddin, M.: Handwritten optical character recog- nition (ocr): A comprehensive systematic literature review (slr). IEEE Access8, 142642–142668 (2020).https://doi.org/10.1109/ACCESS.2020.3012542
-
[27]
In: 8th Int
Nath, G.: Isolated ocr for handwritten forms: An application in the education domain. In: 8th Int. Conf. of Business Analytics (2022)
2022
-
[28]
In: Sclaroff, S., Distante, C., Leo, M., Farinella, G.M., Tombari, F
Ngo, P.: Digital line segment detection for table reconstruction in document im- ages. In: Sclaroff, S., Distante, C., Leo, M., Farinella, G.M., Tombari, F. (eds.) Image Analysis and Processing – ICIAP 2022, pp. 211–224. Springer International Publishing, Cham (2022).https://doi.org/10.1007/978-3-031-06430-2_18
-
[29]
Pad, P., Narduzzi, S., Kundig, C., Turetken, E., Bigdeli, S.A., Dunbar, L.A.: Efficient neural vision systems based on convolutional image acquisition. In: 2020 IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR). pp. 12282–12291. IEEE, Seattle, WA, USA (2020).https://doi.org/10.1109/ CVPR42600.2020.01230
arXiv 2020
-
[30]
Pal, A., Singh, D.: Handwritten english character recognition using neural network. Int. J. Computer Science and Communication (2010)
2010
-
[31]
Pattern Recognition40, 2110–2117 (2007).https://doi.org/10.1016/j.patcog
Patil, P.M., Sontakke, T.R.: Rotation, scale and translation invariant handwrit- ten devanagari numeral character recognition using general fuzzy neural network. Pattern Recognition40, 2110–2117 (2007).https://doi.org/10.1016/j.patcog. 2006.12.018 14 H. Grabowski
-
[32]
Prasad, D., Gadpal, A., Kapadni, K., Visave, M., Sultanpure, K.: Cascadetabnet: An approach for end to end table detection and structure recognition from image- based documents (2020).https://doi.org/10.48550/ARXIV.2004.12629
-
[33]
Priya, A., Mishra, S., Raj, S., Mandal, S., Datta, S.: Online and offline character recognition: A survey. In: 2016 Int. Conf. on Communication and Signal Processing (ICCSP). pp. 0967–0970. IEEE (2016).https://doi.org/10.1109/ICCSP.2016. 7754291
-
[34]
Raj, S., Gupta, Y., Malhotra, R.: License plate recognition system using yolov5 and cnn. In: 2022 8th Int. Conf. on Advanced Computing and Communication Systems (ICACCS). pp. 372–377. IEEE, Coimbatore, India (2022).https://doi. org/10.1109/ICACCS54159.2022.9784966
-
[35]
Rao, N.V., Sastry, A.S.C.S., Chakravarthy, A.S.N., Kalyanchakravarthi, P.: Optical character recognition technique algorithms. J. Theoretical and Applied Information Technology83(2016)
2016
-
[36]
Rasmussen, L.V., Peissig, P.L., McCarty, C.A., Starren, J.: Development of an optical character recognition pipeline for handwritten form fields from an electronic health record. J. Am. Med. Inform. Assoc.19, e90–e95 (2012).https://doi.org/ 10.1136/amiajnl-2011-000182
-
[37]
Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: Towards real-time object de- tection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39, 1137–1149 (2017).https://doi.org/10.1109/TPAMI.2016.2577031
-
[38]
Shawon, A., Rahman, M.J.U., Mahmud, F., Zaman, M.M.A.: Bangla handwritten digit recognition using deep cnn for large and unbiased dataset. In: 2018 Int. Conf. on Bangla Speech and Language Processing (ICBSLP). pp. 1–6. IEEE, Sylhet (2018).https://doi.org/10.1109/ICBSLP.2018.8554900
-
[39]
Imbalanced data problem in machine learning: A review,
Shi, H., Zhao, D.: License plate recognition system based on improved yolov5 and gru. IEEE Access11, 10429–10439 (2023).https://doi.org/10.1109/ACCESS. 2023.3240439
-
[40]
Singh, S., Tiwari, S.: Application of image processing and convolution networks in intelligent character recognition for digitized forms processing. Int. J. Computer Applications179, 7–13 (2018).https://doi.org/10.5120/ijca2018915460
-
[41]
Smith, R.: An overview of the tesseract ocr engine. In: Ninth Int. Conf. on Docu- ment Analysis and Recognition (ICDAR 2007). vol. 2, pp. 629–633. IEEE, Curitiba, Parana, Brazil (2007).https://doi.org/10.1109/ICDAR.2007.4376991
-
[42]
Somashekar, T.: A survey on handwritten character recognition using machine learning technique. J. Univ. Shanghai Sci. Technol.23, 1019–1024 (2021).https: //doi.org/10.51201/JUSST/21/05304
-
[43]
Suriya, S., Dhivya, S., Balaji, M.: Intelligent character recognition system us- ing convolutional neural network. EAI Endorsed Trans. Cloud Systems6, 166659 (2020).https://doi.org/10.4108/eai.16-10-2020.166659
-
[44]
Applied Sciences 12, 5361 (2022).https://doi.org/10.3390/app12115361
Tang, M., Xie, S., He, M., Liu, X.: Character recognition in endangered archives: Shui manuscripts dataset, detection and application realization. Applied Sciences 12, 5361 (2022).https://doi.org/10.3390/app12115361
-
[45]
02696(2022)
Wang, C.Y., Bochkovskiy, A., Liao, H.Y.M.: Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors.http://arxiv.org/abs/2207. 02696(2022)
2022
-
[46]
Wu, Y., Kirillov, A., Massa, F., Lo, W.Y., Girshick, R.: Detectron2.https:// github.com/facebookresearch/detectron2, last accessed 2023/04/05
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.