Counterfactual Residual Data Augmentation for Regression
Pith reviewed 2026-06-30 01:13 UTC · model grok-4.3
The pith
After modeling systematic trends in tabular data, the remaining residual noise stays stable enough under small feature changes to generate new realistic training samples that reduce prediction error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
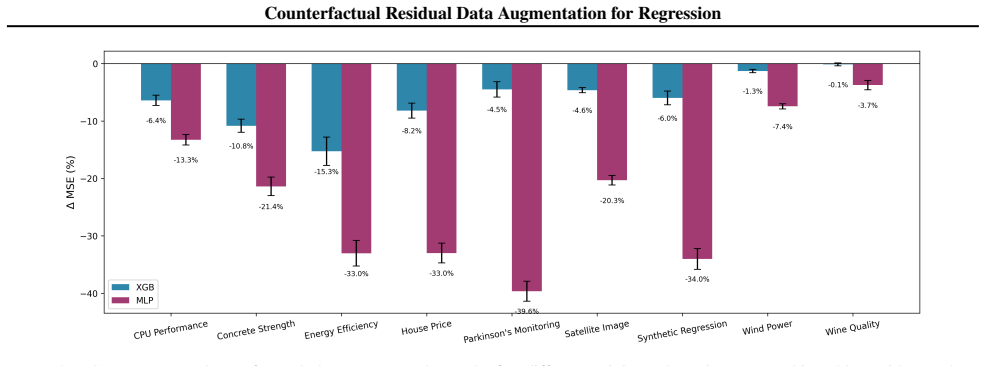
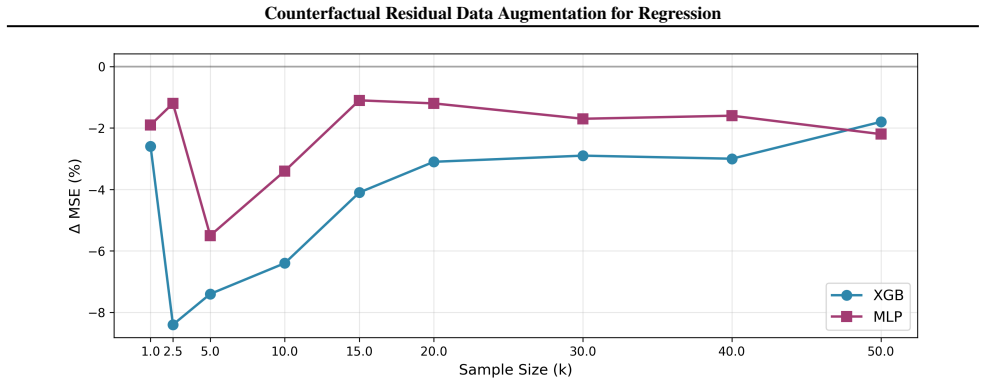
The central claim is that the residual after fitting the systematic component of the data remains stable under small perturbations of selected features. By holding this residual fixed and applying the perturbations, new training samples are synthesized that preserve the noise characteristics of the original data. When these samples are added to the training set, both MLP and XGBoost regressors achieve lower MSE, with average reductions of 22.9 percent and 6.4 percent respectively, and the method outperforms existing data generators.
What carries the argument
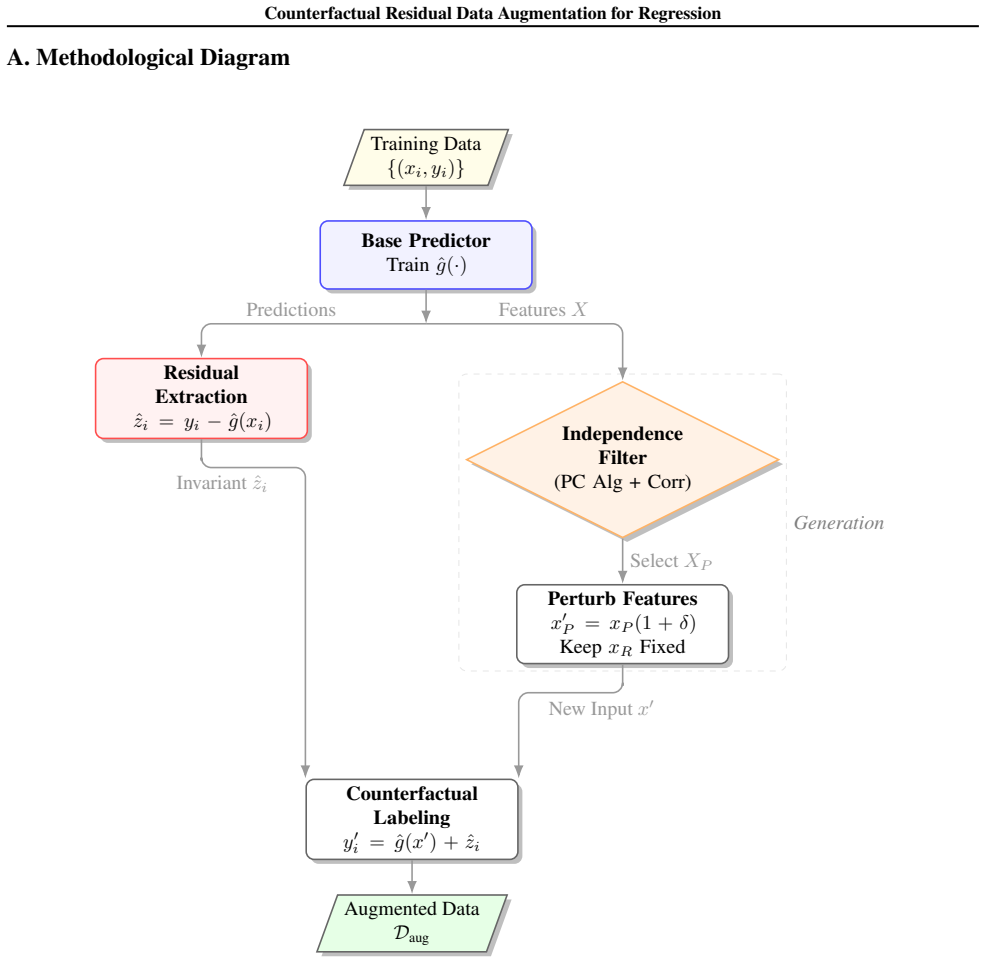
The invariant residual, obtained by subtracting the model's systematic prediction from the observed target, which is held constant while selected features are perturbed to produce counterfactual training examples.
If this is right
- The augmented training set improves test MSE for multiple regressor families without collecting new real observations.
- The technique applies across diverse tabular datasets from standard benchmark repositories.
- Performance gains hold when compared against other state-of-the-art data generators and augmentation methods.
- The method requires no change to the underlying regressor architecture or training procedure.
Where Pith is reading between the lines
- The same residual-invariance idea could be tested on time-series regression if the perturbations respect temporal structure.
- Feature selection for perturbation might itself be learned from data rather than chosen manually.
- If the invariance holds only approximately, the size of the perturbation could be tuned to balance realism against diversity.
Load-bearing premise
The residual after fitting the systematic component remains invariant under small perturbations of carefully selected features.
What would settle it
An experiment in which the generated samples, produced by the same perturbations, fail to reduce MSE or increase it on held-out test data from the same distribution.
Figures

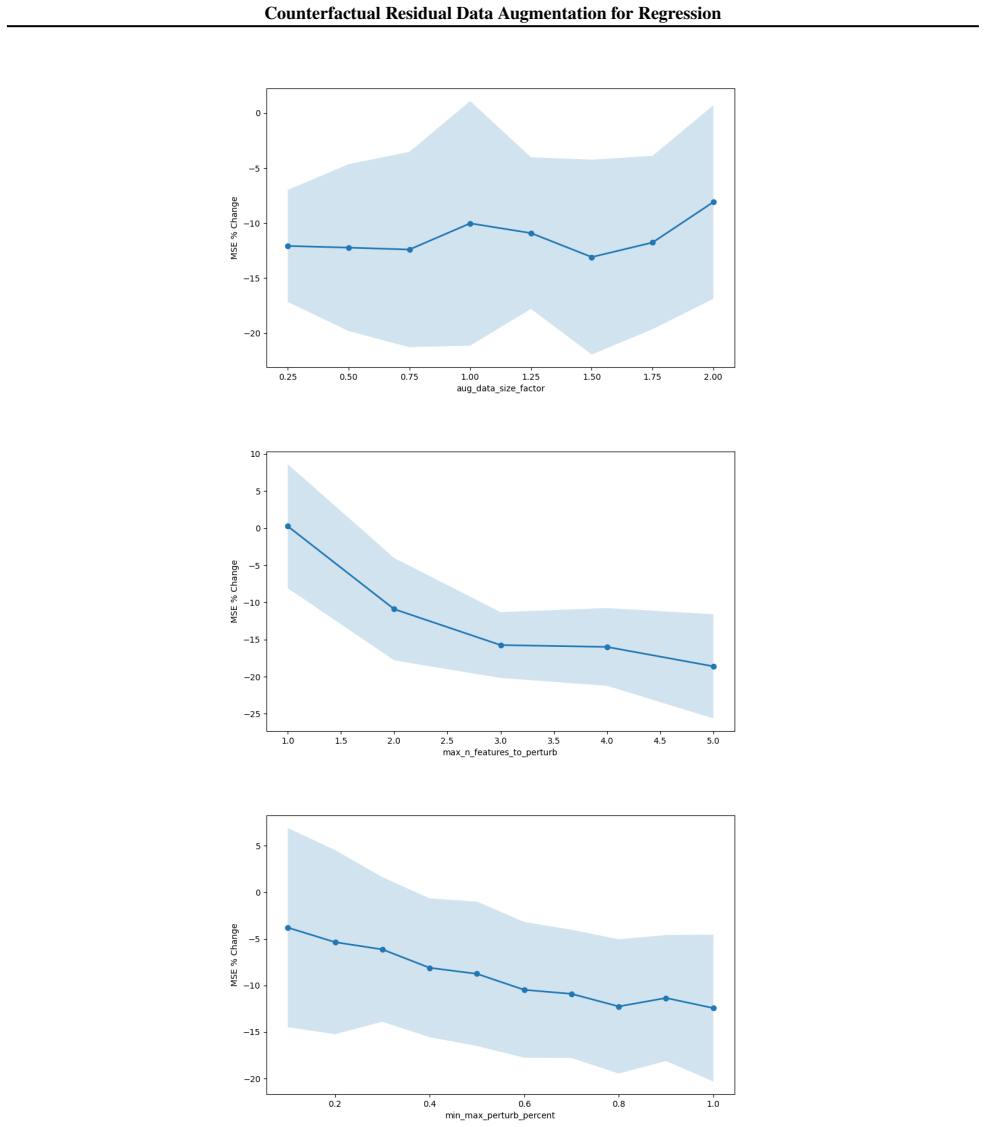
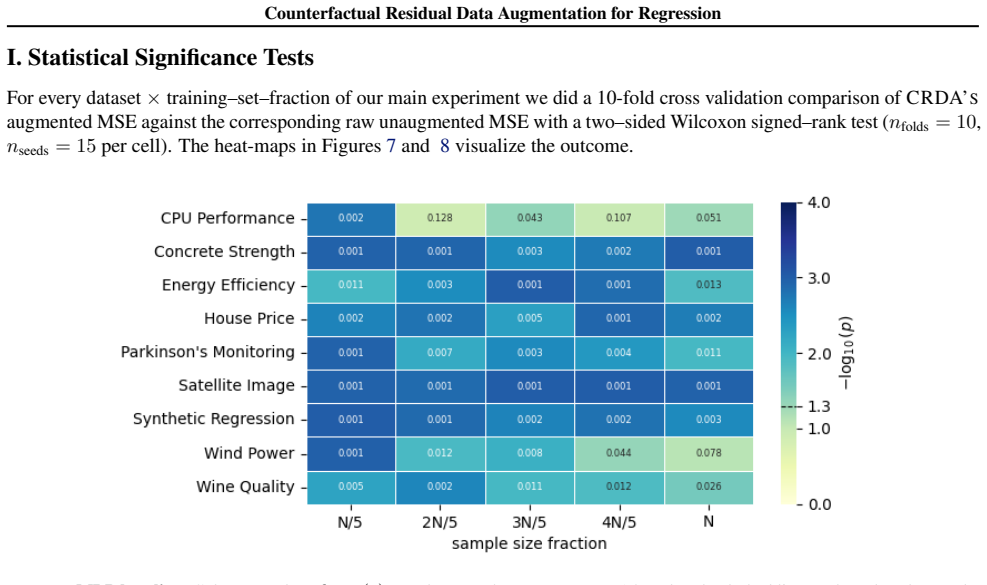
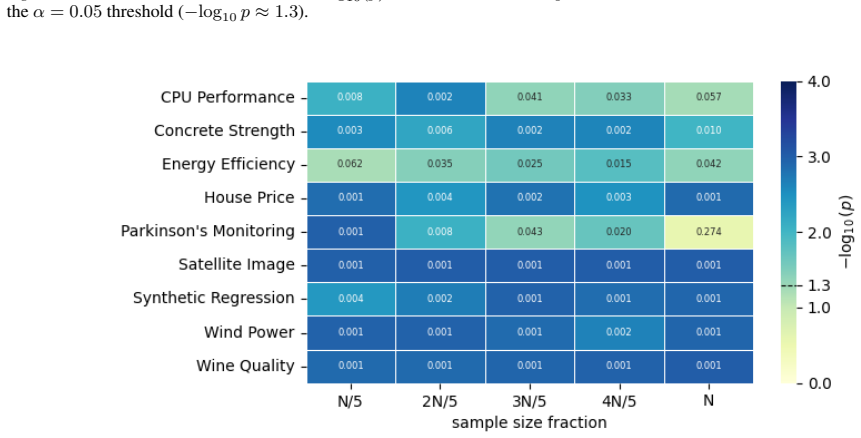
read the original abstract
Data-driven modeling in real-world regression tasks often suffers from limited training samples, high collection costs, and noisy observations. Inspired by the impact of data augmentation in vision and language, we propose a novel Counterfactual Residual Data Augmentation (CRDA) technique for tabular regression. Our key insight is that once a regressor has modeled the systematic component of the data, the remaining noise can be viewed as an invariant residual that remains stable under small perturbations of carefully selected features. We exploit this residual invariance to generate new, yet realistic, training samples, effectively expanding the dataset without requiring additional real data. Our method is model-agnostic and readily applicable to various types of regressors. In experiments across datasets from a variety of benchmark repositories, on average, CRDA reduces an MLP Regressor's MSE by 22.9% and an XGBoost Regressor's MSE by 6.4%. When compared to existing state-of-the-art data generators and augmentation techniques, CRDA consistently outperforms in MSE reduction. By adding principled counterfactual variations to the training data, our method offers a simple and efficient remedy for noise-prone, small-sample regression settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Counterfactual Residual Data Augmentation (CRDA) for tabular regression under limited samples and noise. After an initial regressor captures the systematic component, the residual is treated as invariant under small perturbations of selected features; new samples are generated by applying these perturbations to inputs while retaining the original residual, expanding the training set in a model-agnostic way. Experiments across benchmark datasets report average MSE reductions of 22.9% for MLP regressors and 6.4% for XGBoost, outperforming existing augmentation baselines.
Significance. If the residual-invariance premise holds and the generated samples remain consistent with the true conditional expectation, CRDA would offer a lightweight, model-agnostic augmentation strategy for small-sample regression without requiring additional real data collection. The empirical gains on standard benchmarks and the explicit comparison to prior generators are positive indicators of practical utility.
major comments (2)
- [Method] Method section (core procedure): the central premise that the residual after the first-stage fit is invariant under small perturbations of the selected features receives no derivation, orthogonality diagnostic, or bound on perturbation size. In the small-sample noisy regimes targeted by the paper, any unmodeled systematic structure left in the residual will be propagated to counterfactual inputs whose true expectation differs, producing inconsistent training points; this directly undermines the claim that the augmentation reduces MSE via principled residual reuse.
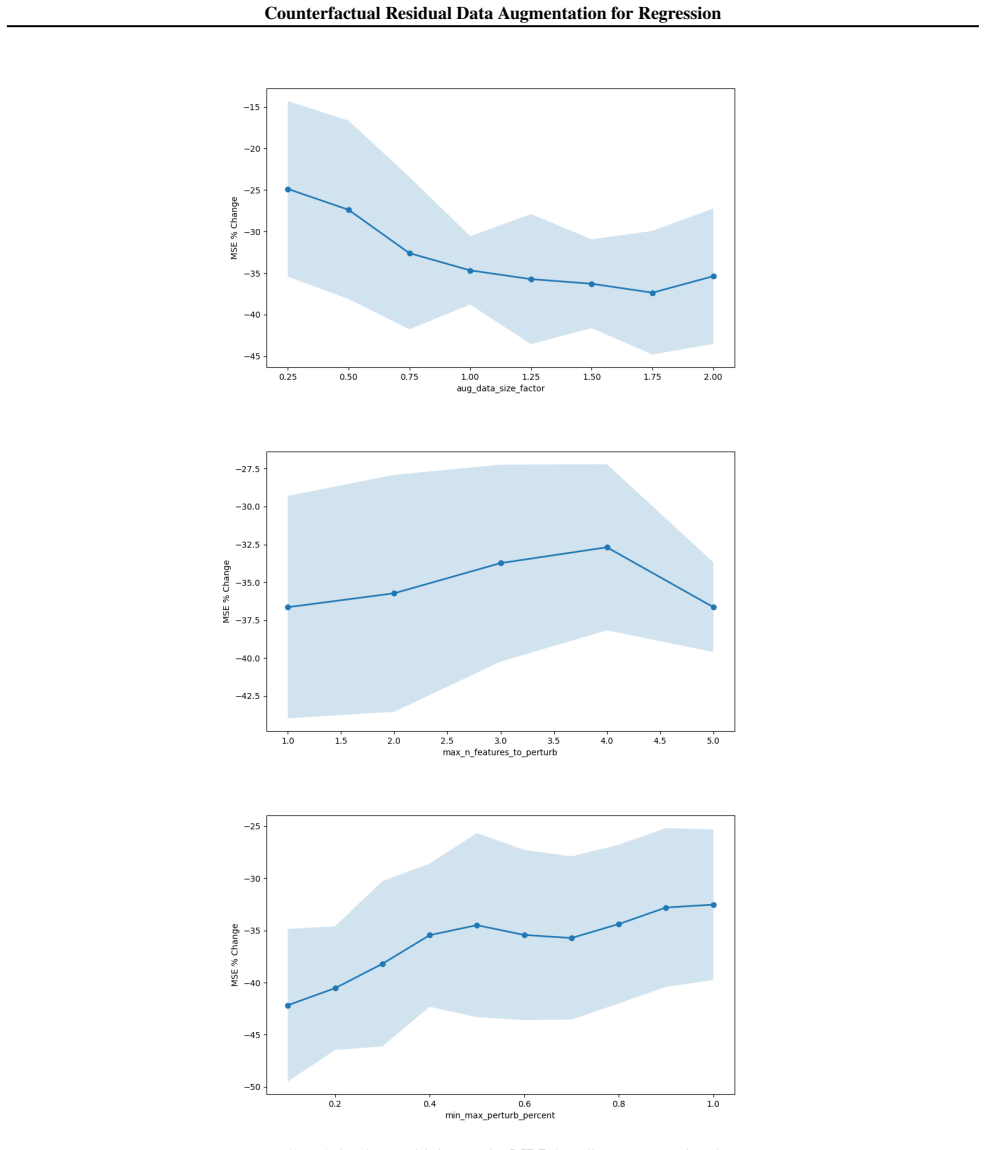
- [Experiments] Experiments section (Tables reporting MSE): the reported average reductions (22.9% MLP, 6.4% XGBoost) are given without ablation on the feature-selection criterion or perturbation magnitude, nor any diagnostic confirming that the chosen features satisfy the invariance condition. Without these controls it is impossible to attribute the gains to the proposed mechanism rather than generic regularization or noise injection.
minor comments (2)
- [Method] Notation for the residual and perturbation operator is introduced without a compact equation; adding a single displayed equation would improve clarity.
- [Abstract] The abstract states the method is 'readily applicable to various types of regressors' yet the experiments only report MLP and XGBoost; a brief statement on applicability to linear models or other tree ensembles would be useful.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Method] Method section (core procedure): the central premise that the residual after the first-stage fit is invariant under small perturbations of the selected features receives no derivation, orthogonality diagnostic, or bound on perturbation size. In the small-sample noisy regimes targeted by the paper, any unmodeled systematic structure left in the residual will be propagated to counterfactual inputs whose true expectation differs, producing inconsistent training points; this directly undermines the claim that the augmentation reduces MSE via principled residual reuse.
Authors: We agree that the residual-invariance premise is an assumption rather than a derived result and that additional justification would strengthen the presentation. In the revised manuscript we will add a dedicated subsection discussing the modeling assumption, including (i) an orthogonality diagnostic (Pearson correlation between residuals and the selected features) computed on the training data and (ii) practical guidance for choosing perturbation magnitudes based on feature standard deviations. We will also explicitly note that the first-stage regressor is selected to capture systematic variation and that the method is intended for regimes in which residuals are approximately unstructured; the potential for residual structure to produce inconsistent points will be listed as a limitation. revision: yes
-
Referee: [Experiments] Experiments section (Tables reporting MSE): the reported average reductions (22.9% MLP, 6.4% XGBoost) are given without ablation on the feature-selection criterion or perturbation magnitude, nor any diagnostic confirming that the chosen features satisfy the invariance condition. Without these controls it is impossible to attribute the gains to the proposed mechanism rather than generic regularization or noise injection.
Authors: We acknowledge that the current experiments lack the requested ablations and diagnostics. In the revision we will add (i) an ablation table varying the feature-selection criterion (correlation-based vs. importance-based), (ii) results for a range of perturbation magnitudes, and (iii) the invariance diagnostic (residual-feature correlations) for each dataset. These additions will allow readers to assess whether the observed MSE reductions are attributable to the residual-invariance mechanism. revision: yes
Circularity Check
No circularity; procedural method with no derivation chain or self-referential reductions.
full rationale
The paper introduces CRDA as a data augmentation procedure relying on the modeling assumption that post-fit residuals remain invariant to small perturbations of selected features. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claim is an empirical modeling choice evaluated externally on benchmark datasets rather than a mathematical derivation that reduces to its own inputs by construction. This is the expected non-finding for a purely algorithmic contribution without claimed first-principles derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
An analysis of causal effect estimation using outcome invariant data augmentation
Akbar, U., Kilbertus, N., Shen, H., Muandet, K., and Dai, B. An analysis of causal effect estimation using outcome invariant data augmentation. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=C1LVIInfZO
2025
-
[2]
Optuna: A next-generation hyperparameter optimization framework
Akiba, T., Sano, S., Yanase, T., Ohta, T., and Koyama, M. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, pp.\ 2623--2631, 2019
2019
-
[3]
Arjovsky, M., Bottou, L., Gulrajani, I., and Lopez-Paz, D. Invariant risk minimization. arXiv preprint arXiv:1907.02893, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[4]
F., Candes, E
Barber, R. F., Candes, E. J., Ramdas, A., and Tibshirani, R. J. Predictive inference with the jackknife+. The Annals of Statistics, 49 0 (1): 0 486--507, 2021
2021
-
[5]
Branco, P., Torgo, L., and Ribeiro, R. P. SMOGN : a pre-processing approach for imbalanced regression. In First international workshop on learning with imbalanced domains: Theory and applications, pp.\ 36--50. PMLR, 2017
2017
-
[6]
V., Bowyer, K
Chawla, N. V., Bowyer, K. W., Hall, L. O., and Kegelmeyer, W. P. SMOTE : synthetic minority over-sampling technique. Journal of artificial intelligence research, 16: 0 321--357, 2002
2002
-
[7]
and Guestrin, C
Chen, T. and Guestrin, C. XGBoost : A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, pp.\ 785--794, 2016
2016
-
[8]
Wine Quality , 2009
Cortez, P., Cerdeira, A., Almeida, F., Matos, T., and Reis, J. Wine Quality , 2009. URL https://archive.ics.uci.edu/dataset/186/wine UCI Machine Learning Repository
2009
-
[9]
D., Zoph, B., Mané, D., Vasudevan, V., and Le, Q
Cubuk, E. D., Zoph, B., Mané, D., Vasudevan, V., and Le, Q. V. Autoaugment: Learning augmentation strategies from data. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 113--123, 2019. doi:10.1109/CVPR.2019.00020
-
[10]
Bootstrap methods: another look at the jackknife
Efron, B. Bootstrap methods: another look at the jackknife. In Breakthroughs in statistics: Methodology and distribution, pp.\ 569--593. Springer, 1992
1992
-
[11]
Do we need hundreds of classifiers to solve real world classification problems? The journal of machine learning research, 15 0 (1): 0 3133--3181, 2014
Fern \'a ndez-Delgado, M., Cernadas, E., Barro, S., and Amorim, D. Do we need hundreds of classifiers to solve real world classification problems? The journal of machine learning research, 15 0 (1): 0 3133--3181, 2014
2014
-
[12]
Deep Learning
Goodfellow, I., Bengio, Y., and Courville, A. Deep Learning. MIT Press, 2016. http://www.deeplearningbook.org
2016
-
[13]
and Raftery, A
Haslett, J. and Raftery, A. E. Irish Wind Speed (Malin Head, 1961–1978) , 1989. URL https://www.rdocumentation.org/packages/gstat/topics/wind. Daily average wind speeds at 12 Irish stations
1961
-
[14]
Hwang, S.-H. and Whang, S. E. RegMix : Data mixing augmentation for regression. arXiv preprint arXiv:2106.03374, 2021
-
[15]
and B \"u hlmann, P
Kalisch, M. and B \"u hlmann, P. Estimating high-dimensional directed acyclic graphs with the PC -algorithm. Journal of Machine Learning Research, 8 0 (22), 2007
2007
-
[16]
G., and Vishwanath, S
Kocaoglu, M., Snyder, C., Dimakis, A. G., and Vishwanath, S. Causal GAN : Learning causal implicit generative models with adversarial training. In International Conference on Learning Representations, 2018. URL https://openreview.net/forum?id=BJE-4xW0W
2018
-
[17]
TabDDPM : Modelling tabular data with diffusion models
Kotelnikov, A., Baranchuk, D., Rubachev, I., and Babenko, A. TabDDPM : Modelling tabular data with diffusion models. In International conference on machine learning, pp.\ 17564--17579. PMLR, 2023
2023
-
[18]
Estimating mutual information
Kraskov, A., St \"o gbauer, H., and Grassberger, P. Estimating mutual information. Physical Review E-Statistical, Nonlinear, and Soft Matter Physics, 69 0 (6): 0 066138, 2004
2004
-
[19]
M., Zhang, K., and Sch \"o lkopf, B
Lu, C., Huang, B., Wang, K., Hern \'a ndez-Lobato, J. M., Zhang, K., and Sch \"o lkopf, B. Sample-efficient reinforcement learning via counterfactual-based data augmentation. CoRR, abs/2012.09092, 2020. URL https://arxiv.org/abs/2012.09092
-
[20]
and DataCanary
Montoya, A. and DataCanary. House prices - advanced regression techniques, 2016. URL https://www.kaggle.com/competitions/house-prices-advanced-regression-techniques. Kaggle
2016
-
[21]
S., Cava, W
Olson, R. S., Cava, W. L., Orzechowski, P., Urbanowicz, R. J., and Moore, J. H. PMLB Dataset 227\_cpu\_small , 2017 a . URL https://github.com/EpistasisLab/pmlb. Penn Machine Learning Benchmarks, version 2025-05-16
2017
-
[22]
S., Cava, W
Olson, R. S., Cava, W. L., Orzechowski, P., Urbanowicz, R. J., and Moore, J. H. PMLB Dataset 294\_satellite\_image , 2017 b . URL https://github.com/EpistasisLab/pmlb. Penn Machine Learning Benchmarks, version 2025-05-16
2017
-
[23]
S., Cava, W
Olson, R. S., Cava, W. L., Orzechowski, P., Urbanowicz, R. J., and Moore, J. H. PMLB Dataset 623\_fri\_c4\_1000\_10 , 2017 c . URL https://github.com/EpistasisLab/pmlb. Synthetic Friedman \#4 variant; Penn Machine Learning Benchmarks
2017
-
[24]
Causality: Models, Reasoning, and Inference
Pearl, J. Causality: Models, Reasoning, and Inference. Cambridge University Press, 2 edition, 2009
2009
-
[25]
Scikit-learn: Machine learning in python
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., et al. Scikit-learn: Machine learning in python. Journal of Machine Learning Research, 12: 0 2825--2830, 2011
2011
-
[26]
Elements of Causal Inference: Foundations and Learning Algorithms
Peters, J., Janzing, D., and Schölkopf, B. Elements of Causal Inference: Foundations and Learning Algorithms. The MIT Press, 2017
2017
-
[27]
P., Khatami, S
Prashant, P. P., Khatami, S. B., Ribeiro, B., and Salimi, B. Scalable out-of-distribution robustness in the presence of unobserved confounders. In The 28th International Conference on Artificial Intelligence and Statistics, 2025. URL https://openreview.net/forum?id=eIyOtZ9tgl
2025
-
[28]
V., and Gulin, A
Prokhorenkova, L., Gusev, G., Vorobev, A., Dorogush, A. V., and Gulin, A. CatBoost : unbiased boosting with categorical features. Advances in Neural Information Processing Systems, 31, 2018. URL https://papers.nips.cc/paper/7898-catboost-unbiased-boosting-with-categorical-features
2018
-
[29]
G., Rubio-Madrigal, C., Burkholz, R., and Muandet, K
Reddy, A. G., Rubio-Madrigal, C., Burkholz, R., and Muandet, K. When shift happens - confounding is to blame. In The Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=sFjxg8cyJS
2026
-
[30]
Anchor data augmentation
Schneider, N., Goshtasbpour, S., and Perez-Cruz, F. Anchor data augmentation. Advances in Neural Information Processing Systems, 36: 0 74890--74902, 2023
2023
-
[31]
Causation, Prediction, and Search
Spirtes, P., Glymour, C., and Scheines, R. Causation, Prediction, and Search. Adaptive Computation and Machine Learning. MIT Press, Cambridge, MA, 2nd edition, 2000
2000
-
[32]
and Schulte, O
Sun, X. and Schulte, O. Cause-effect inference in location-scale noise models: Maximum likelihood vs. independence testing. Advances in Neural Information Processing Systems, 36: 0 5447--5483, 2023
2023
-
[33]
J., Rizzo, M
Sz \'e kely, G. J., Rizzo, M. L., and Bakirov, N. K. Measuring and testing dependence by correlation of distances. The Annals of Statistics, 35 0 (6): 0 2769--2794, 2007
2007
-
[34]
and Little, M
Tsanas, A. and Little, M. A. Parkinsons Telemonitoring , 2009. URL https://archive.ics.uci.edu/ml/datasets/parkinsons UCI Machine Learning Repository
2009
-
[35]
and Xifara, A
Tsanas, A. and Xifara, A. Energy Efficiency , 2012. URL https://archive.ics.uci.edu/ml/datasets/energy UCI Machine Learning Repository
2012
-
[36]
Individual comparisons by ranking methods
Wilcoxon, F. Individual comparisons by ranking methods. Biometrics bulletin, 1 0 (6): 0 80--83, 1945
1945
-
[37]
Modeling tabular data using conditional GAN
Xu, L., Skoularidou, M., Cuesta-Infante, A., and Veeramachaneni, K. Modeling tabular data using conditional GAN . Advances in Neural Information Processing Systems, 32, 2019
2019
-
[38]
Y., and Finn, C
Yao, H., Wang, Y., Zhang, L., Zou, J. Y., and Finn, C. C-Mixup : Improving generalization in regression. Advances in Neural Information Processing Systems, 35: 0 3361--3376, 2022
2022
-
[39]
Concrete Compressive Strength , 1998
Yeh, I. Concrete Compressive Strength , 1998. URL https://archive.ics.uci.edu/ml/datasets/concrete UCI Machine Learning Repository
1998
-
[40]
J., Chun, S., Choe, J., and Yoo, Y
Yun, S., Han, D., Oh, S. J., Chun, S., Choe, J., and Yoo, Y. CutMix : Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF international conference on computer vision, pp.\ 6023--6032, 2019
2019
-
[41]
N., and Lopez-Paz, D
Zhang, H., Cisse, M., Dauphin, Y. N., and Lopez-Paz, D. mixup: Beyond empirical risk minimization. In International Conference on Learning Representations, 2018. URL https://openreview.net/forum?id=r1Ddp1-Rb
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.