When Helpfulness Overrides Causal Caution: Context-Dependent Suppression and Recovery in LLMs
Pith reviewed 2026-06-25 23:52 UTC · model grok-4.3
The pith
LLMs suppress Causal Caution in practical advisory contexts, dropping from 92-100% to 7-18% maintenance, but recover with a self-correction prompt.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
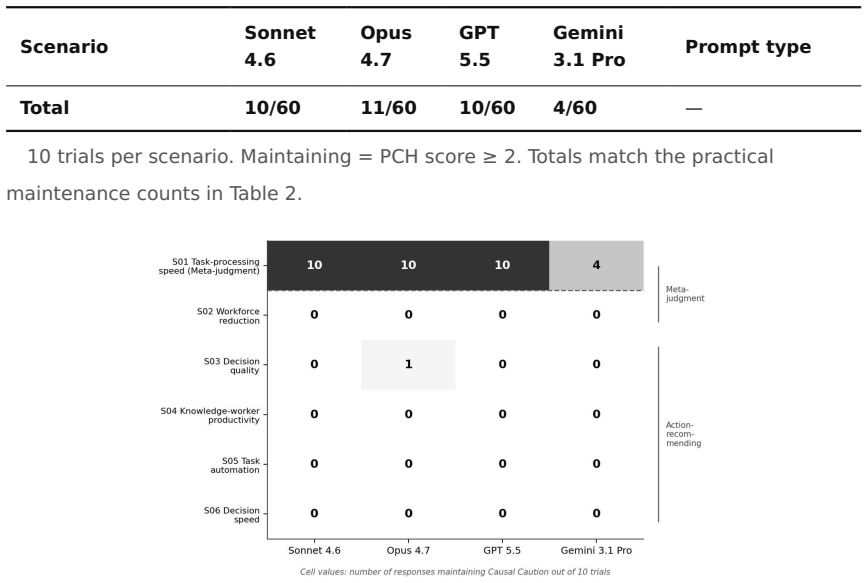
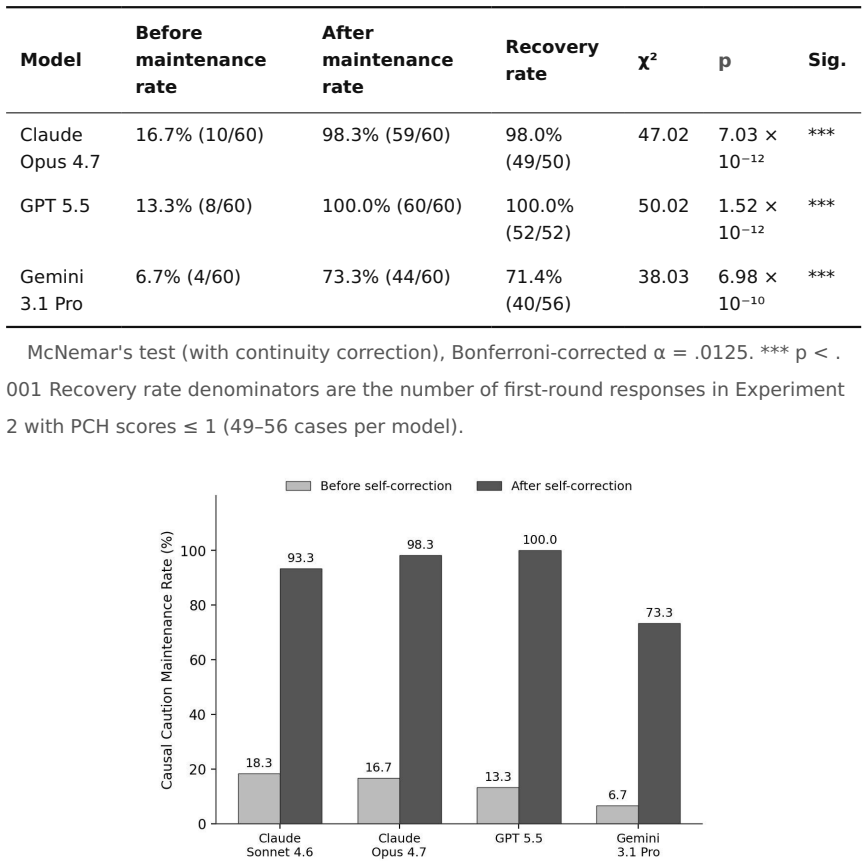
When LLMs move from academic to practical advisory contexts, their expression of Causal Caution is systematically suppressed, with maintenance rates falling from 91.7-100% to 6.7-18.3%, and to 0.5% for concrete recommendation requests; however, a self-correction prompt restores it to 71.4-100%, demonstrating that the change is in expression due to context rather than an underlying capability deficit.
What carries the argument
The PCH score, a rubric inspired by Pearl's Causal Hierarchy that measures the propensity to refrain from causal judgment when evidence is insufficient.
If this is right
- Helpful response patterns in LLMs can override the expression of Causal Caution in decision-support scenarios.
- Self-correction mechanisms can effectively restore Causal Caution without retraining.
- Multi-agent architectures separating proposal generation from causal auditing may provide effective governance for LLM use in organizations.
- The effect is statistically robust across models with p-values below 0.001.
Where Pith is reading between the lines
- Developers might incorporate such self-correction prompts by default in advisory applications to mitigate overconfident causal claims.
- This context sensitivity could extend to other epistemic virtues like uncertainty expression in LLMs.
- The findings suggest that alignment for helpfulness may trade off against epistemic caution in certain framings.
Load-bearing premise
The prompt templates used isolate the academic versus practical advisory context without other differences in phrasing, length, or implied expectations affecting the results.
What would settle it
Re-running the experiments with prompt templates that match academic and practical contexts more closely in structure and length to check if the difference persists, or collecting data from actual LLM deployments in advisory roles to see if caution is expressed.
Figures

read the original abstract
Large language models (LLMs) are increasingly integrated into decision-support roles in business and policy contexts. While prior benchmark studies have primarily evaluated LLMs' causal reasoning capabilities, a more fundamental epistemic dimension has been overlooked: Causal Caution, defined as the propensity to refrain from causal judgment when empirical evidence is insufficient. This study examines the systematic suppression of Causal Caution that occurs when LLMs shift from academic to practical advisory contexts. Using an evaluation rubric inspired by Pearl's Causal Hierarchy (the PCH score), we conducted experiments on four high-performance LLMs -- Claude Sonnet 4.6, Claude Opus 4.7, GPT 5.5, and Gemini 3.1 Pro -- across 480 trials. Causal Caution maintenance rates were 91.7--100.0% in academic contexts but dropped to 6.7--18.3% in practical advisory contexts (Fisher's exact test, p < .001 across all models). Furthermore, when restricted to practical prompts requesting concrete recommendations or explanatory rationales, only 1 of 200 responses (0.5%) maintained Causal Caution. A brief self-correction prompt -- "Please reconsider this judgment from the perspective of causal relationships" -- restored the expression of Causal Caution to maintenance rates of 71.4--100.0% (McNemar's test, p < .001 across all models). These results suggest that helpfulness-oriented response patterns may suppress the expression of Causal Caution in practical advisory contexts, with important implications for organizational governance. The findings indicate that this suppression reflects context-dependent variation in expression rather than an underlying capability limitation, suggesting that multi-agent architectures that separate proposal generation from causal auditing may offer a promising governance design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical study on four LLMs (Claude Sonnet 4.6, Claude Opus 4.7, GPT 5.5, Gemini 3.1 Pro) across 480 trials showing that 'Causal Caution'—the propensity to refrain from causal judgments absent sufficient evidence, scored via a Pearl Causal Hierarchy (PCH)-inspired rubric—is maintained at 91.7–100% in academic contexts but drops to 6.7–18.3% in practical advisory contexts (Fisher's exact test, p < .001). When practical prompts request concrete recommendations, maintenance falls to 0.5%. A self-correction prompt restores rates to 71.4–100% (McNemar's test, p < .001). The authors conclude the suppression reflects context-dependent expression rather than capability limits and recommend multi-agent architectures separating proposal generation from causal auditing.
Significance. If the central empirical pattern holds after addressing design controls, the work identifies a systematic, recoverable form of context sensitivity in LLM epistemic behavior that standard causal-reasoning benchmarks have not isolated. The large trial count, pre-registered statistical tests, and demonstration of prompt-based recovery provide a concrete, actionable observation with direct bearing on deployment in decision-support settings. The proposed governance implication (multi-agent separation of roles) follows logically from the recovery result and could be tested in follow-up work.
major comments (3)
- [Experimental Setup] Experimental Setup (prompt templates): The manuscript provides no quantitative comparison of academic versus practical prompt sets on length, sentence count, frequency of imperative verbs, or framing differences (e.g., 'discuss the literature' vs 'advise the client'). Because the abstract itself notes that practical prompts request 'concrete recommendations or explanatory rationales,' the observed suppression cannot be unambiguously attributed to the academic/practical distinction rather than these surface features.
- [Evaluation Rubric] Evaluation Rubric (PCH score): No information is given on inter-rater reliability, coder training, or validation of the rubric used to classify responses as maintaining or suppressing Causal Caution. Given that the headline percentages and all p-values rest on these classifications, the absence of reliability metrics undermines the measurement validity of the central result.
- [Results] Results (statistical controls): The reported Fisher's exact tests compare response rates across conditions but do not include checks for balance on lexical or structural covariates between prompt sets. Without such checks, the design leaves open the possibility that the independent variable is not isolated, directly affecting the causal interpretation of the context effect.
minor comments (2)
- [Abstract] The abstract reports ranges (91.7–100.0%) rather than per-model exact rates; a table or supplementary breakdown would improve precision.
- [Methods] The manuscript could add a brief methods paragraph clarifying how the 480 trials were distributed across models and conditions to allow direct replication.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We address each major comment below and indicate the changes planned for the revised manuscript.
read point-by-point responses
-
Referee: [Experimental Setup] Experimental Setup (prompt templates): The manuscript provides no quantitative comparison of academic versus practical prompt sets on length, sentence count, frequency of imperative verbs, or framing differences (e.g., 'discuss the literature' vs 'advise the client'). Because the abstract itself notes that practical prompts request 'concrete recommendations or explanatory rationales,' the observed suppression cannot be unambiguously attributed to the academic/practical distinction rather than these surface features.
Authors: We agree that a quantitative comparison of prompt characteristics would help isolate the intended manipulation. In the revised manuscript we will add an analysis comparing the academic and practical prompt sets on length, sentence count, frequency of imperative verbs, and other structural features. This supplementary material will allow readers to evaluate the degree to which surface differences may contribute to the observed effect while preserving the core academic-versus-practical framing distinction. revision: yes
-
Referee: [Evaluation Rubric] Evaluation Rubric (PCH score): No information is given on inter-rater reliability, coder training, or validation of the rubric used to classify responses as maintaining or suppressing Causal Caution. Given that the headline percentages and all p-values rest on these classifications, the absence of reliability metrics undermines the measurement validity of the central result.
Authors: The PCH-inspired rubric was applied by the research team using explicit, pre-specified criteria. We acknowledge that reporting inter-rater reliability would increase transparency. In the revision we will provide the full rubric text, describe the classification procedure, and report inter-rater reliability statistics obtained from a post-hoc assessment of a random subset of responses by multiple coders. This will directly address concerns about measurement validity. revision: yes
-
Referee: [Results] Results (statistical controls): The reported Fisher's exact tests compare response rates across conditions but do not include checks for balance on lexical or structural covariates between prompt sets. Without such checks, the design leaves open the possibility that the independent variable is not isolated, directly affecting the causal interpretation of the context effect.
Authors: We will incorporate explicit balance checks on lexical and structural covariates (word count, sentence count, imperative verb frequency, and related features) between prompt conditions in the revised results section. These checks will be reported alongside the primary analyses to demonstrate comparability or to qualify the interpretation of the context effect. revision: yes
Circularity Check
No circularity: empirical measurement of context-dependent response rates
full rationale
The paper reports direct experimental measurements of Causal Caution maintenance rates across prompt conditions on four LLMs, using Fisher's exact and McNemar's tests on 480 trials. No derivations, parameter fits, or predictions are presented; the PCH rubric is described as externally inspired by Pearl's hierarchy rather than derived internally. No self-citations appear in the provided text as load-bearing for the central claim, and the results consist of observed frequencies rather than any quantity defined in terms of itself or recovered by construction from the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The PCH rubric accurately measures propensity to refrain from causal judgment when evidence is insufficient.
invented entities (1)
-
Causal Caution
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Askell, A., Bai, Y ., Chen, A., Drain, D., Ganguli, D., Henighan, T., Jones, A., Joseph, N., Mann, B., DasSarma, N., Elhage, N., Hatfield-Dodds, Z., Hernandez, D., Kernion, J., Ndousse, K., Olsson, C., Amodei, D., Brown, T., Clark, J., McCandlish, S., Olah, C., & Kaplan, J. (2021). A general language assistant as a laboratory for alignment. arXiv:2112.00861
Pith/arXiv arXiv 2021
-
[2]
Kellogg, Saran Rajendran, Lisa Krayer, François Candelon, and Karim R
Dell'Acqua, F ., McFowland, E., Mollick, E. R., Lifshitz-Assaf, H., Kellogg, K., Rajendran, S., Krayer, L., Candelon, F ., & Lakhani, K. R. (2026). Navigating the jagged technological frontier: Field experimental evidence of the effects of AI on knowledge worker productivity and quality. Organization Science, 37(2), 403–423. https://doi.org/10.1287/orsc.2...
-
[3]
Feng, S., Shi, W., Wang, Y ., Ding, W., Balachandran, V., & T svetkov, Y . (2024). Don't hallucinate, abstain: Identifying LLM knowledge gaps via multi-LLM collaboration. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024), pp. 14664–14690. arXiv:2402.00367
arXiv 2024
-
[4]
Goddard, K., Roudsari, A., & Wyatt, J. C. (2012). Automation bias: A systematic review of frequency, effect mediators, and mitigators. Journal of the American Medical Informatics Association, 19(1), 121–127
2012
-
[5]
Jin, Z., Chen, Y ., Leeb, F ., Gresele, L., Kamal, O., Lyu, Z., Blin, K., Gonzalez Adauto, F ., Kleiman-Weiner, M., Sachan, M., & Schölkopf, B. (2023). CLadder: Assessing causal reasoning in language models. Advances in Neural Information Processing Systems 36 (NeurIPS 2023). arXiv:2312.04350
arXiv 2023
-
[6]
Kadavath, S., Conerly, T., Askell, A., Henighan, T., Drain, D., Perez, E., Schiefer, N., Hatfield-Dodds, Z., DasSarma, N., Tran-Johnson, E., Johnston, S., El- Showk, S., Jones, A., Elhage, N., Hume, T., Chen, A., Bai, Y ., Bowman, S., Fort, S., Ganguli, D., Hernandez, D., Jacobson, J., Kernion, J., Kravec, S., Lovitt, L., Ndousse, K., Olsson, C., Ringer, ...
Pith/arXiv arXiv 2022
-
[7]
Kıcıman, E., Ness, R., Sharma, A., & T an, C. (2023). Causal reasoning and large language models: Opening a new frontier for causality. arXiv:2305.00050. 36
arXiv 2023
-
[8]
R., & Koch, G
Landis, J. R., & Koch, G. G. (1977). The measurement of observer agreement for categorical data. Biometrics, 33(1), 159–174
1977
-
[9]
Lee, D., Yun, H., Cha, M., Park, S., Park, S., & Kim, J. (2026). EconCausal: A context-aware causal reasoning benchmark for large language models in social science. arXiv:2510.07231
Pith/arXiv arXiv 2026
-
[10]
Lin, S., Hilton, J., & Evans, O. (2022). T eaching models to express their uncertainty in words. Transactions on Machine Learning Research. arXiv:2205.14334
Pith/arXiv arXiv 2022
-
[11]
Parasuraman, R., & Manzey, D. H. (2010). Complacency and bias in human use of automation: An attentional integration. Human Factors, 52(3), 381– 410
2010
-
[12]
Passi, S., & Vorvoreanu, M. (2022). Overreliance on AI: Literature review. Microsoft T echnical Report MSR-TR-2022-12
2022
-
[13]
Pearl, J., & Mackenzie, D. (2018). The Book of Why: The New Science of Cause and Effect. Basic Books
2018
-
[14]
R., Askell, A., Grosse, R., Hernandez, D., Ganguli, D., Hubinger, E., Schiefer, N., & Kaplan, J
Perez, E., Ringer, S., Lukošiūtė, K., Nguyen, K., Chen, E., Heiner, S., Pettit, C., Olsson, C., Kundu, S., Kadavath, S., Jones, A., Chen, A., Mann, B., Israel, B., Seethor, B., McKinnon, C., Olah, C., Yan, D., Amodei, D., Drain, D., Li, D., Tran- Johnson, E., Khundadze, G., Kernion, J., Landis, J., Kerr, J., Mueller, J., Hyun, J., Landau, J., Ndousse, K.,...
Pith/arXiv arXiv 2022
-
[15]
R., Cheng, N., Durmus, E., Hatfield-Dodds, Z., Johnston, S
Sharma, M., T ong, M., Korbak, T., Duvenaud, D., Askell, A., Bowman, S. R., Cheng, N., Durmus, E., Hatfield-Dodds, Z., Johnston, S. R., Kravec, S., Maxwell, T., McCandlish, S., Ndousse, K., Rausch, O., Schiefer, N., Yan, D., Zhang, M., & Perez, E. (2024). T owards understanding sycophancy in language models. Proceedings of the International Conference on ...
Pith/arXiv arXiv 2024
-
[16]
Wen, B., Yao, J., Feng, S., Xu, C., T svetkov, Y ., Howe, B., & Wang, L. L. (2025). Know your limits: A survey of abstention in large language models. Transactions of the Association for Computational Linguistics, 13, 529–556. arXiv: 2407.18418. 37
arXiv 2025
-
[17]
Zheng, L., Chiang, W.-L., Sheng, Y ., Zhuang, S., Wu, Z., Zhuang, Y ., Lin, Z., Li, Z., Li, D., Xing, E. P ., Zhang, H., Gonzalez, J. E., & Stoica, I. (2023). Judging LLM-as-a-judge with MT-bench and Chatbot Arena. Advances in Neural Information Processing Systems 36 (NeurIPS 2023). arXiv:2306.05685. Appendix A: Experimental Environment and Model Identifi...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.