When Is Emergent Consensus Real? A Measured Coupling Gain and a Validity Diagnostic for LLM Agent Societies
Pith reviewed 2026-06-26 11:40 UTC · model grok-4.3
The pith
A measured coupling gain gamma and randomized diagnostic separate genuine consensus from artifacts in LLM agent societies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
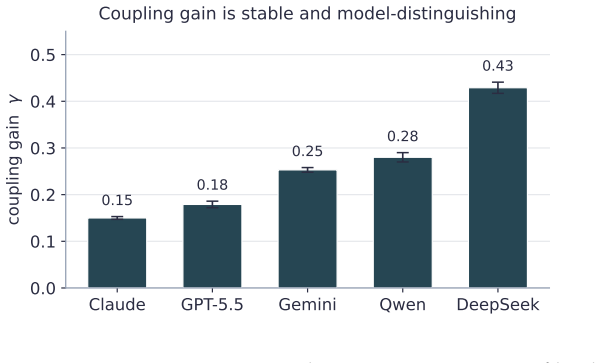
The paper claims that without a measurable control parameter, demonstrations of emergent consensus in LLM societies cannot be distinguished from model artifacts. By introducing the per-agent coupling gain gamma via counterfactual perturbation, it shows gamma is stable and model-distinguishing, that classical opinion dynamics with measured coefficients organize consensus or polarization regimes, that LLMs lack spontaneous backfire, and that a slope-bias diagnostic on randomized initials reveals whether an outcome is genuine averaging or prior artifact. It further shows that regime laws require modality-matched group coupling rather than pairwise gamma.
What carries the argument
The coupling gain gamma, a per-agent coefficient measured by counterfactually perturbing a neighbour's opinion and observing the response agent's change.
If this is right
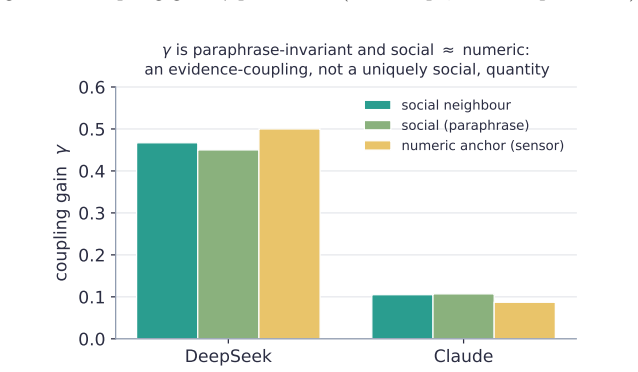
- Gamma remains stable under paraphrasing and equals numeric-anchor coupling.
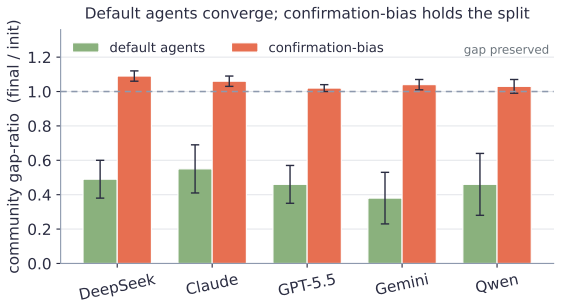
- Frontier LLMs exhibit beta less than or equal to zero, preventing spontaneous polarization.
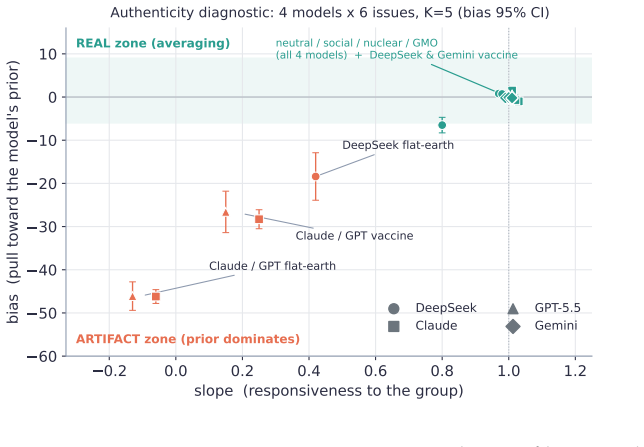
- The randomized initial condition diagnostic identifies model-prior artifacts on settled facts.
- Modality-matched group coupling predicts multi-neighbour outcomes with correlation -0.70.
- Pairwise gamma fails to predict group outcomes and can even reverse the order.
Where Pith is reading between the lines
- Applying this protocol to other published LLM society experiments could reclassify many consensus claims as artifacts.
- Agent society design might benefit from selecting models with higher gamma for stronger social dynamics.
- Extending the diagnostic to non-opinion tasks could test if similar artifacts appear in other emergent behaviors.
- The finding that group coupling differs from pairwise suggests interaction structure matters more than individual links.
Load-bearing premise
Counterfactual perturbation of one neighbour's opinion isolates a stable per-agent coupling coefficient without confounding changes to the LLM's generation process.
What would settle it
Re-running the gamma measurement protocol with different perturbation magnitudes or additional context changes and finding that gamma values shift beyond the reported confidence intervals would falsify the stability claim.
Figures
read the original abstract
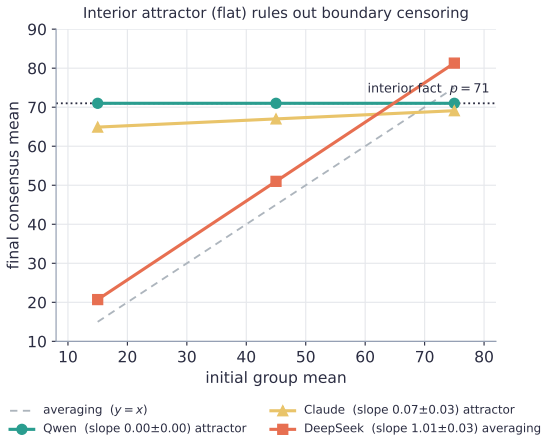
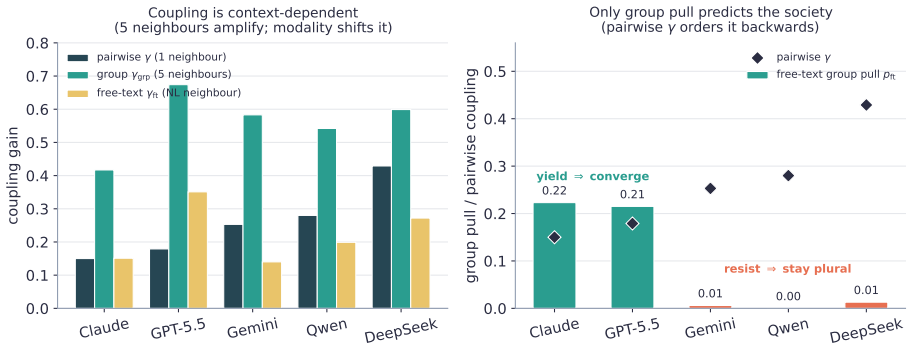
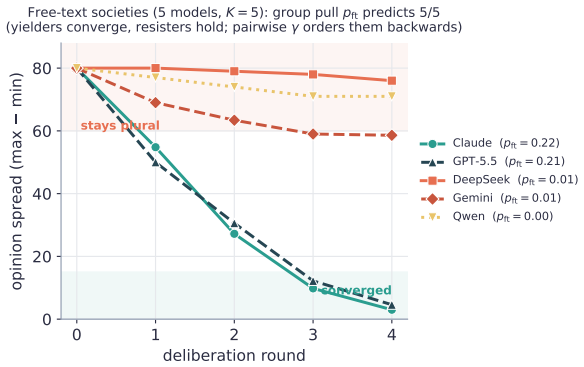
LLM "agent societies" are studied via demonstrations of emergent consensus or polarization -- with no measurable control parameter, no theory of when each regime appears, and no test of whether an outcome is a genuine social dynamic or a model artifact. We introduce the coupling gain gamma, measured per-agent by counterfactually perturbing a neighbour's stated opinion. (i) gamma is stable and model-distinguishing -- across five frontier models it spans 0.15-0.43 (n=20, 95% CIs <= 0.025), paraphrase-invariant; social-neighbour gamma roughly equals numeric-anchor gamma, so gamma is evidence-coupling, not uniquely social. (ii) Classical dynamics with measured (not assumed) coefficients organise the regime: Friedkin-Johnsen for consensus/pluralism, signed-Laplacian/structural-balance for polarization. (iii) Frontier LLMs do not spontaneously backfire (beta <= 0), so default societies do not self-polarize -- polarization is always induced; the beta>0 branch arises only in the FJ surrogate, never in the agents. (iv) A randomized-initial-condition diagnostic -- the (slope, bias) of final vs. initial opinion -- separates genuine averaging from model-prior artifacts (boundary-censoring ruled out by construction via interior-valued facts); applied to a published "emergent consensus" result (Chuang et al. 2023) it reveals a model-specific conflation: averaging on debatable claims, prior-artifact on settled facts. (v) Coupling is context-dependent: pairwise gamma does not predict multi-neighbour outcomes -- it can order them backwards -- whereas a modality-matched group coupling does (sixteen closed+open models, Pearson r=-0.70, permutation p=0.008). The regime laws take this matched coupling, not the single-neighbour gamma: emergent consensus must be read from coupling in the target interaction. We contribute a measurement protocol and a validity instrument, not new theory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a coupling gain γ measured per-agent via counterfactual perturbation of a single neighbor's stated opinion in LLM agent societies. It reports that γ is stable and model-distinguishing (0.15-0.43 across five frontier models, n=20, 95% CIs ≤0.025), paraphrase-invariant, and equivalent between social-neighbor and numeric-anchor conditions; that frontier LLMs show no spontaneous backfire (β≤0); that a randomized-initial-condition (slope, bias) diagnostic distinguishes genuine averaging from model-prior artifacts and re-analyzes a prior result (Chuang et al. 2023); and that modality-matched group coupling predicts multi-neighbor outcomes (r=-0.70) while pairwise γ does not. Classical dynamics (Friedkin-Johnsen, signed-Laplacian) are used to organize observed regimes with these measured coefficients.
Significance. If the perturbation protocol cleanly isolates a stable per-agent coupling coefficient, the work supplies a measurable control parameter and validity instrument for studying emergent consensus/polarization in LLM societies, enabling distinction between genuine social dynamics and model artifacts. Strengths include the empirical measurement of coefficients rather than assumption, the provision of numerical ranges with CIs, the re-analysis of a published result using the new diagnostic, and the demonstration that context-matched group coupling (not pairwise γ) is the relevant quantity for regime prediction.
major comments (3)
- [Abstract] Abstract (gamma measurement protocol): the central claim that γ isolates a stable, model-distinguishing coupling coefficient (and is 'evidence-coupling, not uniquely social') rests on the assumption that counterfactually changing only one neighbor's opinion leaves the LLM's prompt encoding, attention allocation, and sampling process unchanged except for the intended effect; no controls or ablation results are described to rule out confounds such as altered context length or attention shifts, which directly undermines the reported stability, CIs, and cross-model distinguishability.
- [Abstract] Abstract (re-analysis of Chuang et al. 2023): the (slope, bias) diagnostic is presented as separating genuine averaging from model-prior artifacts on the prior result, but the manuscript provides neither the exact computation of slope/bias, the subset of claims classified as 'debatable' vs. 'settled,' nor the raw data or code, making it impossible to verify that the re-analysis supports the claim of model-specific conflation.
- [Abstract] Abstract (group coupling result): the claim that modality-matched group coupling predicts multi-neighbor outcomes (Pearson r=-0.70, p=0.008) while pairwise γ does not is load-bearing for the conclusion that 'emergent consensus must be read from coupling in the target interaction'; however, the definition of the modality-matched group coupling, the exact set of 16 models, and the permutation test procedure are not specified, preventing assessment of whether the correlation is robust or an artifact of how the group measure was constructed.
minor comments (2)
- [Abstract] Notation for β (backfire coefficient) and its relation to the signed-Laplacian dynamics is introduced without an explicit equation linking the measured β≤0 to the polarization regime.
- [Abstract] The abstract states 'n=20' and '95% CIs ≤0.025' for the γ ranges but does not indicate whether these are per-model or aggregated, or how the CIs were computed (bootstrap, analytic, etc.).
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which identify areas where greater methodological transparency will strengthen the manuscript. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract (gamma measurement protocol): the central claim that γ isolates a stable, model-distinguishing coupling coefficient (and is 'evidence-coupling, not uniquely social') rests on the assumption that counterfactually changing only one neighbor's opinion leaves the LLM's prompt encoding, attention allocation, and sampling process unchanged except for the intended effect; no controls or ablation results are described to rule out confounds such as altered context length or attention shifts, which directly undermines the reported stability, CIs, and cross-model distinguishability.
Authors: The perturbation protocol replaces only the neighbor's opinion statement while preserving prompt structure, token count, and all other content exactly. Paraphrase invariance of γ across rewordings that alter surface form but not length already supplies indirect robustness evidence. We nevertheless agree that explicit controls would be stronger; the revised manuscript will add an ablation that independently varies context length and attention-head masking while holding the opinion perturbation fixed, reporting the resulting change in measured γ. revision: yes
-
Referee: [Abstract] Abstract (re-analysis of Chuang et al. 2023): the (slope, bias) diagnostic is presented as separating genuine averaging from model-prior artifacts on the prior result, but the manuscript provides neither the exact computation of slope/bias, the subset of claims classified as 'debatable' vs. 'settled,' nor the raw data or code, making it impossible to verify that the re-analysis supports the claim of model-specific conflation.
Authors: The abstract is concise; the full text defines the diagnostic as ordinary-least-squares slope and intercept of final versus randomized initial opinions. Claim classification follows the original paper's debatable/settled partition. To permit verification we will insert the exact regression equations, enumerate the claims retained, and commit to releasing the analysis scripts and data files with the revision. revision: yes
-
Referee: [Abstract] Abstract (group coupling result): the claim that modality-matched group coupling predicts multi-neighbor outcomes (Pearson r=-0.70, p=0.008) while pairwise γ does not is load-bearing for the conclusion that 'emergent consensus must be read from coupling in the target interaction'; however, the definition of the modality-matched group coupling, the exact set of 16 models, and the permutation test procedure are not specified, preventing assessment of whether the correlation is robust or an artifact of how the group measure was constructed.
Authors: The abstract omits these operational details. Modality-matched group coupling is the per-agent γ obtained when all neighbors employ the identical modality (textual statements or numeric anchors) as the eventual multi-neighbor trial. The 16 models are the five frontier models plus eleven additional open- and closed-source models. The permutation test randomly reassigns the group-coupling values across models 10,000 times while preserving the outcome vector. The revised methods section will state these definitions explicitly, list every model, and supply pseudocode for the permutation procedure. revision: yes
Circularity Check
No significant circularity: gamma measured directly via perturbation
full rationale
The paper's core quantity gamma is obtained by direct counterfactual single-neighbor perturbation experiments on LLM outputs, not by fitting any model whose parameters already encode the target consensus or polarization regimes. Classical dynamics (Friedkin-Johnsen, signed-Laplacian) are invoked only after measurement to classify observed outcomes, not to derive or constrain the gamma values themselves. The randomized-initial-condition diagnostic is applied to external published results rather than to the paper's own data. No self-citation chains, ansatzes smuggled via citation, or uniqueness theorems imported from prior author work appear in the derivation. The central claims therefore rest on experimental isolation rather than on any reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Classical opinion dynamics (Friedkin-Johnsen, signed Laplacian) organise the observed consensus/polarization regimes once coefficients are measured rather than assumed
invented entities (1)
-
coupling gain gamma
no independent evidence
Reference graph
Works this paper leans on
-
[1]
J. S. Park et al. Generative Agents: Interactive Simulacra of Human Behavior. UIST 2023. arXiv:2304.03442
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [2]
-
[3]
J. Piao et al. AgentSociety: Large-Scale Simulation of LLM-Driven Generative Agents Advances Un- derstanding of Human Behaviors and Society. arXiv:2502.08691
work page internal anchor Pith review Pith/arXiv arXiv
- [4]
-
[5]
The PIMMUR Principles: Ensuring Validity in Collective Behavior of LLM Societies
J. Zhou et al. The PIMMUR Principles: Ensuring Validity in Collective Behavior of LLM Societies. arXiv:2509.18052
work page internal anchor Pith review Pith/arXiv arXiv
- [6]
-
[7]
Y.-S. Chuang et al. Simulating Opinion Dynamics with Networks of LLM-based Agents. arXiv:2311.09618
-
[8]
M. H. DeGroot. Reaching a Consensus. JASA, 1974
1974
-
[9]
N. E. Friedkin, E. C. Johnsen. Social influence and opinions. J. Math. Sociology, 1990
1990
-
[10]
Altafini
C. Altafini. Consensus problems on networks with antagonistic interactions. IEEE TAC, 2013
2013
-
[11]
A. Sinha et al. The Illusion of Diminishing Returns: Measuring Long Horizon Execution in LLMs. arXiv:2509.09677. 12
- [12]
-
[13]
H. Zhong et al. Disentangling the Drivers of LLM Social Conformity: An Uncertainty-Moderated Dual- Process Mechanism. arXiv:2508.14918
-
[14]
P. Cisneros-Velarde. Large Language Models can Achieve Social Balance. arXiv:2410.04054
-
[15]
Stable Personas: Dual-Assessment of Temporal Stability in LLM-Based Human Simulation
J. Gonnermann-Müller et al. Stable Personas: Dual-Assessment of Temporal Stability in LLM-Based Human Simulation. arXiv:2601.22812
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
A. Tomašević et al. Towards Operational Validation of LLM-Agent Social Simulations: A Replicated Study of a Reddit-like Technology Forum. arXiv:2508.21740
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
P. Cisneros-Velarde et al. On the Principles behind Opinion Dynamics in Multi-Agent Systems of Large Language Models. arXiv:2406.15492. 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.