Towards Continual Motion-Language Agents: LoRA Variants for Incremental Motion Understanding and Generation
Pith reviewed 2026-06-30 07:32 UTC · model grok-4.3
The pith
Mixture-of-experts LoRA with autoencoder router achieves near-zero forgetting in motion-language continual learning
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Building on a frozen large language model backbone, we introduce low-rank adaptation (LoRA) variants designed to mitigate inter-task interference. We specifically propose mixture-of-experts architectures that utilize an autoencoder-based router to select task-specific experts at inference time, so that no task-label is needed. Our experimental results demonstrate near-zero forgetting across both M2T and T2M directions while maintaining high generation and captioning quality. Furthermore, we show that hard expert selection via routing significantly outperforms soft expert blending in quality metrics.
What carries the argument
Autoencoder-based router for selecting task-specific LoRA experts in a mixture-of-experts architecture without task labels.
If this is right
- Near-zero forgetting occurs in both motion-to-text and text-to-motion when using the proposed LoRA variants.
- Hard expert selection maintains better quality than soft blending by preserving expert isolation.
- A five-task benchmark from semantic clustering of HumanML3D enables testing of continual learning in this domain.
- Token-level accuracy may not align with downstream generation quality, suggesting need for broader evaluation.
Where Pith is reading between the lines
- The router mechanism could allow the system to handle an arbitrary number of tasks as long as the autoencoder can distinguish them.
- This setup might apply to other sequence-to-sequence continual learning problems beyond motion.
- Future work could test if the divergence in metrics appears in other modalities.
Load-bearing premise
The five tasks created by semantic clustering of motion descriptions have limited overlap, allowing sequential learning to test forgetting without major concept interference.
What would settle it
Running the same methods on a different task sequence or clustering that has more overlapping concepts and observing substantial forgetting or quality degradation would challenge the near-zero forgetting result.
Figures
read the original abstract
Motion-language agents must possess the bidirectional capability to both understand human movement (motion-to-text, M2T) and generate it from natural language (text-to-motion, T2M). While foundational models have achieved strong performance in static settings, autonomous agents operating in dynamic environments must continuously incorporate new motion concepts -- such as novel athletic styles or specialized gestures -- without catastrophic forgetting of previously acquired skills. We investigate the stability-plasticity trade-off in bidirectional motion-language learning under sequential task exposure. Building on a frozen large language model backbone, we introduce low-rank adaptation (LoRA) variants designed to mitigate inter-task interference. We specifically propose mixture-of-experts architectures that utilize an autoencoder-based router to select task-specific experts at inference time, so that no task-label is needed. To evaluate these methods, we establish a reproducible five-task benchmark derived from HumanML3D through semantic clustering of motion descriptions. Our experimental results demonstrate near-zero forgetting across both M2T and T2M directions while maintaining high generation and captioning quality. Furthermore, we show that hard expert selection via routing significantly outperforms soft expert blending in quality metrics, indicating that preserving expert isolation is critical for maintaining performance in our continual learning setting. Finally, we observe that a divergence between token-level accuracy and downstream generation quality may occur, highlighting the need for more comprehensive evaluation protocols in future research on lifelong motion-language agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LoRA variants, including a mixture-of-experts architecture with an autoencoder-based router for task-agnostic expert selection, to enable continual bidirectional learning in motion-to-text (M2T) and text-to-motion (T2M) without catastrophic forgetting. It introduces a five-task benchmark derived from HumanML3D via semantic clustering of motion descriptions and claims near-zero forgetting while preserving high generation and captioning quality, with hard routing outperforming soft blending and a noted divergence between token-level and downstream metrics.
Significance. If the central results hold, the work would contribute to continual learning for multimodal agents by demonstrating parameter-efficient methods that balance stability and plasticity in sequential motion-language tasks without requiring task labels at inference. The reproducible benchmark and the distinction between hard and soft routing are positive elements that could guide future lifelong learning research in this domain.
major comments (2)
- [Abstract] Abstract: The claim of near-zero forgetting in both M2T and T2M rests on the assumption that semantic clustering yields five tasks with limited overlap. No inter-cluster similarity metrics, cross-task zero-shot performance, or control experiment (e.g., naive fine-tuning exhibiting forgetting) are reported, so it remains possible that limited interference rather than the LoRA-MoE method explains the stability.
- [Abstract] Abstract: The experimental claims are stated without any quantitative metrics, equations for the router or experts, training details, or tables of results, preventing verification of the 'near-zero forgetting' or quality maintenance assertions from the provided text.
minor comments (1)
- [Abstract] The abstract mentions a divergence between token-level accuracy and generation quality but does not elaborate on how this affects the evaluation protocol; a brief clarification would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of near-zero forgetting in both M2T and T2M rests on the assumption that semantic clustering yields five tasks with limited overlap. No inter-cluster similarity metrics, cross-task zero-shot performance, or control experiment (e.g., naive fine-tuning exhibiting forgetting) are reported, so it remains possible that limited interference rather than the LoRA-MoE method explains the stability.
Authors: We agree that additional evidence would strengthen the interpretation. Section 3.2 of the manuscript details the semantic clustering of HumanML3D motion descriptions via sentence embeddings, and Section 4 reports that our method achieves near-zero forgetting while preserving quality. However, inter-cluster similarity metrics, explicit cross-task zero-shot results, and a naive fine-tuning control are not included. We will add these analyses (including centroid cosine similarities and a standard fine-tuning baseline demonstrating forgetting) to Section 4 and a supplementary figure in the revision. revision: yes
-
Referee: [Abstract] Abstract: The experimental claims are stated without any quantitative metrics, equations for the router or experts, training details, or tables of results, preventing verification of the 'near-zero forgetting' or quality maintenance assertions from the provided text.
Authors: The abstract is a high-level summary; the full manuscript provides the requested details. Section 3 derives the autoencoder router and LoRA expert equations, Section 4 reports quantitative metrics (e.g., forgetting rates, R-Precision, FID) with tables, and the appendix contains training hyperparameters. To improve immediate verifiability, we will revise the abstract to include key numerical highlights such as the reported forgetting rates and performance values. revision: partial
Circularity Check
No circularity in experimental claims or benchmark construction
full rationale
The paper reports empirical results on a five-task continual learning benchmark derived from HumanML3D via semantic clustering of motion descriptions, using LoRA variants and an autoencoder router for M2T/T2M tasks. No equations, derivations, or predictions are presented that reduce by construction to fitted inputs, self-definitions, or self-citation chains. The central claims rest on measured forgetting metrics and quality scores rather than tautological constructions, and the benchmark creation is an independent data-processing step without load-bearing self-referential justification. This is a standard experimental paper whose evaluation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rahaf Aljundi, Klaas Kelchtermans, and Tinne Tuytelaars. Task-free continual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 11254–11263, June 2019a. doi: 10.1109/CVPR.2019.01151. Rahaf Aljundi, Min Lin, Baptiste Goujaud, and Yoshua Bengio. Gradient based sample selection for online continual learn...
-
[2]
URLhttp://arxiv.org/ abs/2504.13822. arXiv:2504.13822 [cs]. Jhair Gallardo, Tyler L. Hayes, and Christopher Kanan. Self-supervised training enhances online continual learning. arXiv preprint arXiv:2103.14010,
-
[3]
URLhttps://arxiv. org/abs/2506.11672. Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, and Yizhou Ji. Generating diverse and natural 3d human motions from text. InCVPR,
-
[4]
URLhttp://arxiv.org/abs/2506.13045. arXiv:2506.13045 [cs]. Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, et al. Parameter-efficient transfer learning for nlp. InICML,
-
[5]
URLhttp://arxiv.org/abs/2306.14795. arXiv:2306.14795 [cs]. Aliasghar Khani, Arianna Rampini, Bruno Roy, Larasika Nadela, Noa Kaplan, Evan Atherton, Derek Cheung, and Jacky Bibliowicz. Motion Generation: A Survey of Generative Approaches and Benchmarks,
- [6]
-
[7]
Towards General Text Embeddings with Multi-stage Contrastive Learning
URLhttps://arxiv.org/abs/2308.03281. Yan-Shuo Liang and Wu-Jun Li. InfLoRA: Interference-Free Low-Rank Adaptation for Continual Learning, April
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
URLhttp://arxiv.org/abs/2404.00228. arXiv:2404.00228 [cs]. Michael McCloskey and Neal J. Cohen. Catastrophic Interference in Connectionist Networks: The Sequential Learn- ing Problem. volume 24 ofPsychology of Learning and Motivation, pp. 109 –
-
[9]
URLhttp://www.sciencedirect.com/science/article/pii/ S0079742108605368
doi: 10.1016/S0079-7421(08)60536-8. URLhttp://www.sciencedirect.com/science/article/pii/ S0079742108605368. ISSN: 0079-7421. Sanket Vaibhav Mehta, Darshan Patil, Sarath Chandar, and Emma Strubell. An empirical investigation of the role of pre-training in lifelong learning.arXiv preprint arXiv:2112.09153,
-
[10]
doi: 10.1038/s42256-025-00983-2. 11 Preprint. German I. Parisi, Ronald Kemker, Jose L. Part, Christopher Kanan, and Stefan Wermter. Continual lifelong learn- ing with neural networks: A review.Neural Networks, 113:54 – 71,
-
[11]
doi: https: //doi.org/10.1016/j.neunet.2019.01.012
ISSN 0893-6080. doi: https: //doi.org/10.1016/j.neunet.2019.01.012. URLhttp://www.sciencedirect.com/science/article/ pii/S0893608019300231. Mathis Petrovich, Michael J. Black, and G ¨ul Varol. Temos: Generating diverse human motions from textual descrip- tions. InECCV,
-
[12]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivi`ere, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A Comprehensive Survey of Continual Learning: Theory, Method and Application.IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–20, 2024a. ISSN 0162-8828, 2160-9292, 1939-3539. doi: 10.1109/TPAMI.2024.3367329. URLhttps://ieeexplore.ieee. org/document/10444954/. Yuan Wang, Di Huang, Yaqi...
-
[14]
Motion-Agent: A Conversa- tional Framework for Human Motion Generation with LLMs, October 2024a
Qi Wu, Yubo Zhao, Yifan Wang, Xinhang Liu, Yu-Wing Tai, and Chi-Keung Tang. Motion-Agent: A Conversa- tional Framework for Human Motion Generation with LLMs, October 2024a. URLhttp://arxiv.org/abs/ 2405.17013. arXiv:2405.17013 [cs]. Xun Wu, Shaohan Huang, and Furu Wei. Mixture of loRA experts. InThe Twelfth International Conference on Learning Representat...
-
[15]
URLhttp://arxiv.org/ abs/2501.07278. arXiv:2501.07278 [cs]. Zexin Zheng, Jia-Feng Cai, Xiao-Ming Wu, Yi-Lin Wei, Yu-Ming Tang, and Wei-Shi Zheng. imanip: Skill- incremental learning for robotic manipulation.arXiv preprint arXiv:2503.07087,
-
[16]
URLhttp://arxiv.org/abs/2506.24086. arXiv:2506.24086 [cs]. Wentao Zhu, Xiaoxuan Ma, Dongwoo Ro, Hai Ci, Jinlu Zhang, Jiaxin Shi, Feng Gao, Qi Tian, and Yizhou Wang. Human motion generation: A survey.IEEE Trans. Pattern Anal. Mach. Intell., 46(4):2430–2449, April
-
[17]
doi: 10.1109/TPAMI.2023.3330935
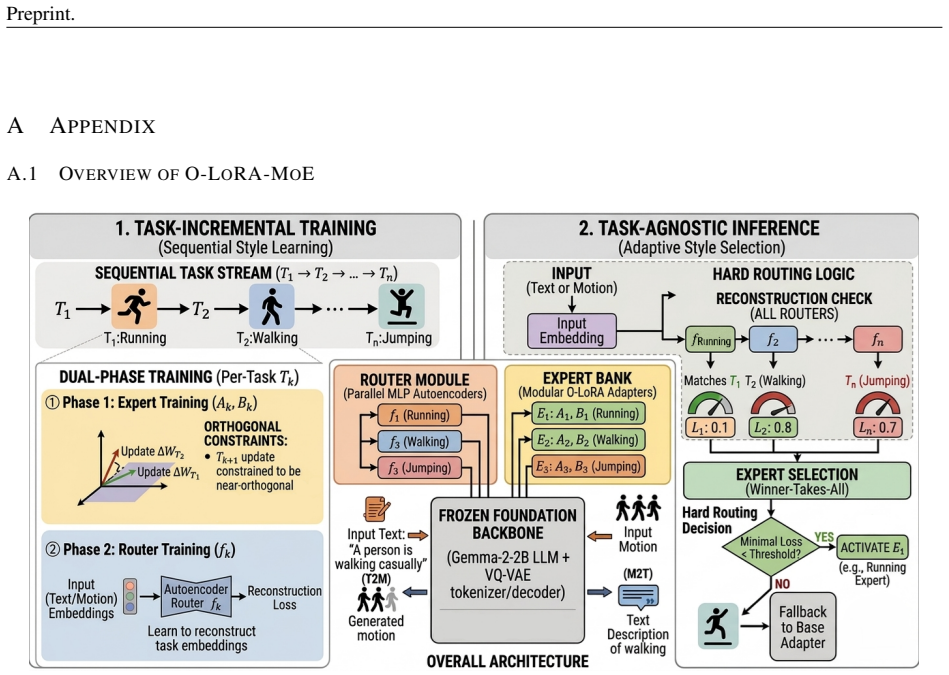
ISSN 0162-8828. doi: 10.1109/TPAMI.2023.3330935. URLhttps://doi.org/10.1109/TPAMI.2023. 3330935. 12 Preprint. A APPENDIX A.1 OVERVIEW OFO-LORA-MOE Figure 1: Overview of the proposed method O-LORA-MOE. The O-LoRA-MoE architecture as illustrated in Figure 1 for bidirectional motion-language learning, consists of task- incremental training and task-agnostic ...
-
[18]
Hard Routing Decision:If the minimal loss is below a learned thresholdτ k =µ k + 2σk, the corresponding orthogonal expert is activated
Expert Selection (Winner-Takes-All): The system identifies the expertˆkcorresponding to the router with the minimal reconstruction loss. Hard Routing Decision:If the minimal loss is below a learned thresholdτ k =µ k + 2σk, the corresponding orthogonal expert is activated. If the loss exceeds the threshold for all routers, the system identifies the input a...
2023
-
[19]
The LoRA adapters targeted the attention Table 6: Shared training hyperparameters across all methods. Parameter Value Learning rate10 −4 Epochs per task 20 Micro-batch size 8 per GPU Gradient accumulation 4 steps Effective batch size8×4×4GPUs= 128 Optimiser AdamW (β 1=0.9,β 2=0.999) Mixed precision bfloat16 projection layers with dropout 0.05, rank/alpha ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.