Flow-Based Generative Modeling for Optimizing Sampling Policies in Compressed Sensing Applications
Pith reviewed 2026-06-30 15:49 UTC · model grok-4.3
The pith
A flow-based generative model learns subsampling masks that improve compressed sensing for image tasks and MRI.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
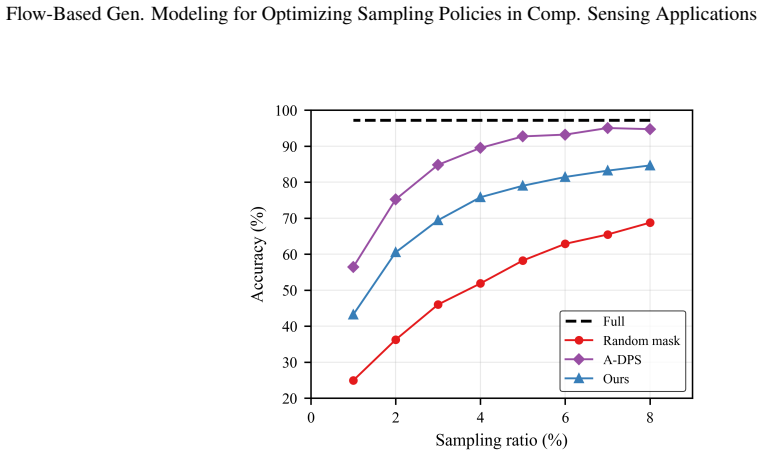
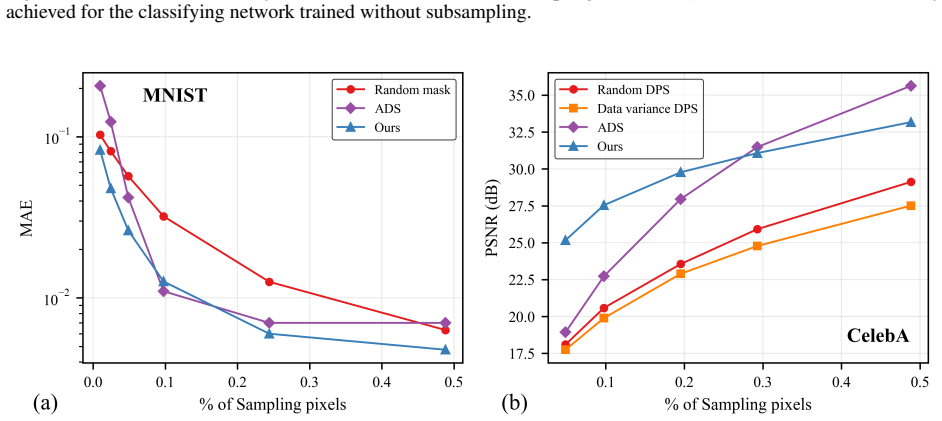
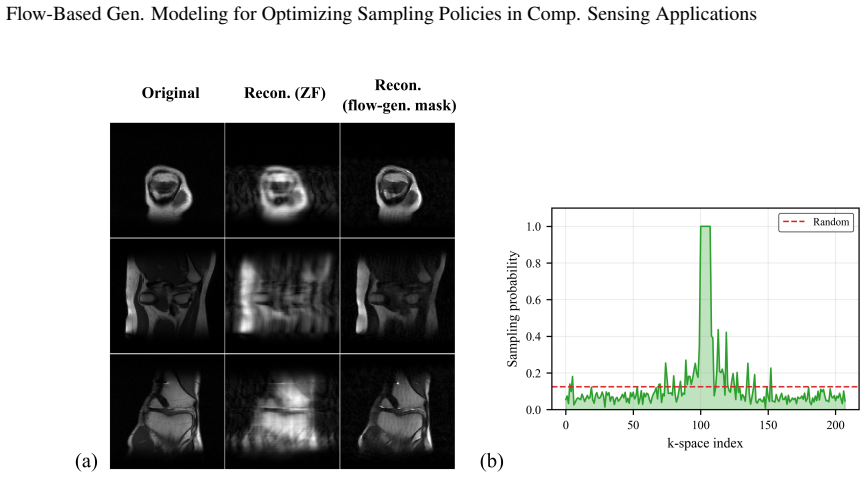
The authors claim that a reformulation of the conventional Flow Matching training paradigm allows a flow model to be trained to optimize subsampling masks, establishing the fundamental feasibility of learning masks that substantially enhance compressed sensing performance for image classification, image reconstruction, and MRI acceleration, with state-of-the-art results of 25.17 dB PSNR at 5 percent subsampling on CelebA and 29.24 dB for 8x accelerated MRI on fastMRI, all with minimal computational overhead.
What carries the argument
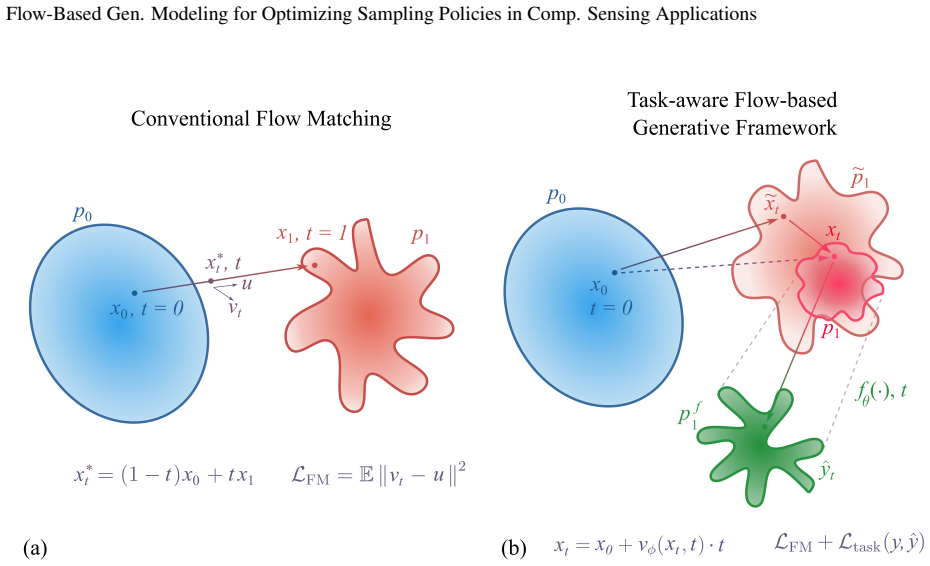
The task-aware flow-based generative framework, a reformulation of the Flow Matching training paradigm that conditions the model on the downstream task to produce subsampling masks.
If this is right
- Subsampling masks generated by the framework enhance compressed sensing performance on image classification, reconstruction, and MRI acceleration.
- The method reaches state-of-the-art PSNR values on CelebA at 5 percent subsampling and on fastMRI for 8x acceleration.
- Task-conditioning inside generative flow models is effective for designing sensing schemes.
- The framework supplies a unified, flexible route to data- and task-driven sensing that can extend to other inverse problems.
Where Pith is reading between the lines
- If the masks transfer across domains, the same training procedure could be reused for audio or video signals without redesigning the mask generator.
- Task conditioning may allow a single model to switch between reconstruction and classification objectives by changing only the conditioning input.
- The low overhead suggests the learned masks could be precomputed once and then applied in real-time acquisition hardware.
Load-bearing premise
The reformulated flow-matching objective trains subsampling masks whose performance gains hold for the claimed tasks and datasets without task-specific overfitting or post-hoc selection.
What would settle it
Retraining the model on CelebA and evaluating the resulting masks on a held-out medical imaging dataset would show whether the reported PSNR gains persist or collapse to the level of random masks.
Figures

read the original abstract
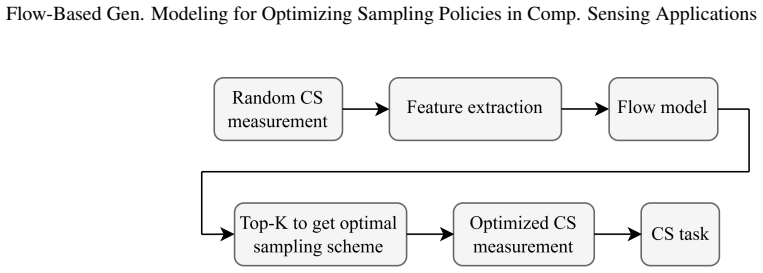
Numerous modern applications in signal processing and medical imaging necessitate acquiring high-dimensional signals under tight resource constraints. Traditional sampling theory suggests that accurate signal reconstruction requires a number of measurements proportional to the signal's ambient dimension, a requirement often too expensive or impractical. Compressed sensing challenges this notion by demonstrating that sparse signals can be recovered with fewer measurements, provided the measurement operator meets certain conditions. This proof-of-concept study presents a task-aware flow-based generative framework -- a reformulation of the conventional Flow Matching training paradigm with a flow model trained to optimize subsampling in compressed sensing applications. We establish the fundamental feasibility of the proposed framework of learning subsampling masks that substantially enhance the performance of compressed sensing for image classification, image reconstruction, and MRI acceleration. For the image reconstruction task, our method demonstrated state-of-the-art performance, achieving Peak Signal-to-Noise Ratio of 25.17 dB at the subsampling rate of 5\% on the CelebA dataset and 29.24 dB when reconstructing $8\times$ accelerated MRI measurements (fastMRI dataset) with the minimal computational overhead. These results highlight the effectiveness of task-conditioning within generative flow models and reveal a promising direction for representation learning strategies. Overall, the proposed framework offers a unified, flexible approach to designing data- and task-driven sensing schemes that can be potentially adapted to a broad range of inverse problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a task-aware flow-based generative framework as a reformulation of conventional flow matching to learn subsampling masks for compressed sensing. It claims this enables substantial performance gains for image classification, reconstruction, and MRI acceleration, with reported results of 25.17 dB PSNR at 5% subsampling on CelebA and 29.24 dB PSNR for 8x accelerated MRI on fastMRI, while emphasizing minimal computational overhead and a unified approach to data- and task-driven sensing.
Significance. If the central claims hold with proper validation, the work could demonstrate a viable path for using generative flow models to optimize sampling policies in inverse problems, potentially extending representation learning techniques to sensing design. The reported numerical results on standard datasets like CelebA and fastMRI would indicate practical utility if shown to arise from the proposed reformulation rather than auxiliary factors.
major comments (2)
- [Abstract] Abstract: The headline performance claims (25.17 dB PSNR at 5% subsampling on CelebA; 29.24 dB at 8x on fastMRI) are presented without any description of the flow-matching reformulation, the continuous vs. discrete mask parameterization, the task-conditioning terms in the objective, or ablations that isolate the flow model's contribution from the downstream reconstruction network. This prevents verification that the gains are attributable to the proposed framework rather than post-hoc mask selection or dataset-specific tuning.
- [Abstract] Abstract: No evidence is supplied that the learned masks generalize beyond the training tasks/datasets or outperform standard CS patterns (e.g., random, variable-density) on the same downstream classification/reconstruction metrics without overfitting. The stress-test concern about task-specific overfitting therefore remains unaddressed and is load-bearing for the claim of a 'unified, flexible approach'.
minor comments (1)
- [Abstract] Abstract: The phrase 'state-of-the-art performance' is used for the reconstruction task but no baselines or prior methods are named for comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the importance of methodological transparency and generalization evidence. We agree that the current abstract is too result-focused and will revise it to provide necessary context. We also acknowledge the need for explicit generalization tests and will incorporate additional experiments and comparisons in the revision to address concerns about task-specific overfitting.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline performance claims (25.17 dB PSNR at 5% subsampling on CelebA; 29.24 dB at 8x on fastMRI) are presented without any description of the flow-matching reformulation, the continuous vs. discrete mask parameterization, the task-conditioning terms in the objective, or ablations that isolate the flow model's contribution from the downstream reconstruction network. This prevents verification that the gains are attributable to the proposed framework rather than post-hoc mask selection or dataset-specific tuning.
Authors: We agree that the abstract lacks sufficient methodological detail to contextualize the claims. In the revised version, we will expand the abstract to concisely describe the flow-matching reformulation for subsampling optimization, the continuous mask parameterization, the task-conditioning terms in the objective, and reference the ablations (in the main text) that isolate the flow model's contribution. This revision will help readers verify the source of the reported gains. revision: yes
-
Referee: [Abstract] Abstract: No evidence is supplied that the learned masks generalize beyond the training tasks/datasets or outperform standard CS patterns (e.g., random, variable-density) on the same downstream classification/reconstruction metrics without overfitting. The stress-test concern about task-specific overfitting therefore remains unaddressed and is load-bearing for the claim of a 'unified, flexible approach'.
Authors: We acknowledge that the current manuscript does not present explicit cross-task or cross-dataset generalization experiments, nor direct comparisons demonstrating that the learned masks outperform standard patterns (random, variable-density) on held-out metrics without overfitting. To address this, the revision will include additional experiments with stress-tests for task-specific overfitting and comparisons against standard CS patterns on the same downstream tasks, strengthening support for the unified approach claim. revision: yes
Circularity Check
No derivation chain or self-referential steps visible
full rationale
The abstract and provided text describe a reformulation of flow matching for subsampling masks but supply no equations, training objectives, mask parameterizations, or citations. No load-bearing steps can be inspected for reduction to inputs by construction, self-definition, or self-citation chains. The central feasibility claim therefore stands as self-contained against external benchmarks with no detectable circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Compressed sensing.IEEE Transactions on information theory, 52(4):1289–1306, 2006
David L Donoho. Compressed sensing.IEEE Transactions on information theory, 52(4):1289–1306, 2006. 10 Flow-Based Gen. Modeling for Optimizing Sampling Policies in Comp. Sensing Applications
2006
-
[2]
An introduction to compressive sampling.IEEE signal processing magazine, 25(2):21–30, 2008
Emmanuel J Candès and Michael B Wakin. An introduction to compressive sampling.IEEE signal processing magazine, 25(2):21–30, 2008
2008
-
[3]
Springer Science & Business Media, 1996
Heinz Werner Engl, Martin Hanke, and Andreas Neubauer.Regularization of inverse problems, volume 375. Springer Science & Business Media, 1996
1996
-
[4]
Cambridge University Press, 2021
Ben Adcock and Anders C Hansen.Compressive imaging: structure, sampling, learning. Cambridge University Press, 2021
2021
-
[5]
Data-driven sparse sensor placement for reconstruction: Demonstrating the benefits of exploiting known patterns.IEEE Control Systems Magazine, 38(3):63–86, 2018
Krithika Manohar, Bingni W Brunton, J Nathan Kutz, and Steven L Brunton. Data-driven sparse sensor placement for reconstruction: Demonstrating the benefits of exploiting known patterns.IEEE Control Systems Magazine, 38(3):63–86, 2018
2018
-
[6]
Deep compressed sensing
Yan Wu, Mihaela Rosca, and Timothy Lillicrap. Deep compressed sensing. pages 6850–6860. PMLR, 2019
2019
-
[7]
Deep probabilistic subsampling for task-adaptive compressed sensing
Iris AM Huijben, Bastiaan S Veeling, and Ruud JG van Sloun. Deep probabilistic subsampling for task-adaptive compressed sensing. 2019
2019
-
[8]
Active deep probabilistic subsampling
Hans Van Gorp, Iris Huijben, Bastiaan S Veeling, Nicola Pezzotti, and Ruud JG Van Sloun. Active deep probabilistic subsampling. pages 10509–10518. PMLR, 2021
2021
-
[9]
Oisín Nolan, Tristan SW Stevens, Wessel L van Nierop, and Ruud JG van Sloun. Active diffusion subsampling. arXiv preprint arXiv:2406.14388, 2024
-
[10]
Diffusion models: A comprehensive survey of methods and applications.ACM computing surveys, 56(4):1–39, 2023
Ling Yang, Zhilong Zhang, Yang Song, Shenda Hong, Runsheng Xu, Yue Zhao, Wentao Zhang, Bin Cui, and Ming-Hsuan Yang. Diffusion models: A comprehensive survey of methods and applications.ACM computing surveys, 56(4):1–39, 2023
2023
-
[11]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
A Survey on Diffusion Models for Inverse Problems
Giannis Daras, Hyungjin Chung, Chieh-Hsin Lai, Yuki Mitsufuji, Jong Chul Ye, Peyman Milanfar, Alexan- dros G Dimakis, and Mauricio Delbracio. A survey on diffusion models for inverse problems.arXiv preprint arXiv:2410.00083, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Inpaint anything: Segment anything meets image inpainting,
Tao Yu, Runseng Feng, Ruoyu Feng, Jinming Liu, Xin Jin, Wenjun Zeng, and Zhibo Chen. Inpaint anything: Segment anything meets image inpainting.arXiv preprint arXiv:2304.06790, 2023
-
[14]
Litu Rout, Advait Parulekar, Constantine Caramanis, and Sanjay Shakkottai. A theoretical justification for image inpainting using denoising diffusion probabilistic models.arXiv preprint arXiv:2302.01217, 2023
-
[15]
Hierarchical integration diffusion model for realistic image deblurring.Advances in neural information processing systems, 36:29114–29125, 2023
Zheng Chen, Yulun Zhang, Ding Liu, Jinjin Gu, Linghe Kong, and Xin Yuan. Hierarchical integration diffusion model for realistic image deblurring.Advances in neural information processing systems, 36:29114–29125, 2023
2023
-
[16]
DeblurDiff: Real-Word Image Deblurring with Generative Diffusion Models
Lingshun Kong, Dongqing Zou, Fu Lee Wang, Jimmy Ren, Xiaohe Wu, Jiangxin Dong, and Jinshan Pan. DeblurDiff: Real-Word Image Deblurring with Generative Diffusion Models. 2025
2025
-
[17]
Exploiting diffusion prior for real-world image super-resolution.International Journal of Computer Vision, 132(12):5929–5949, 2024
Jianyi Wang, Zongsheng Yue, Shangchen Zhou, Kelvin CK Chan, and Chen Change Loy. Exploiting diffusion prior for real-world image super-resolution.International Journal of Computer Vision, 132(12):5929–5949, 2024
2024
-
[18]
Diffusion Posterior Sampling for General Noisy Inverse Problems
Hyungjin Chung, Jeongsol Kim, Michael T Mccann, Marc L Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems.arXiv preprint arXiv:2209.14687, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
JointDiffusion: Joint representation learning for generative, predictive, and self-explainable AI in healthcare.Computerized Medical Imaging and Graphics, page 102619, 2025
Joanna Kaleta, Paweł Skier´s, Jan Dubi´nski, Przemysław Korzeniowski, Tomasz Trzci´nski, Jakub M Tomczak, and Kamil Deja. JointDiffusion: Joint representation learning for generative, predictive, and self-explainable AI in healthcare.Computerized Medical Imaging and Graphics, page 102619, 2025
2025
-
[20]
Compressed sensing MRI.IEEE signal processing magazine, 25(2):72–82, 2008
Michael Lustig, David L Donoho, Juan M Santos, and John M Pauly. Compressed sensing MRI.IEEE signal processing magazine, 25(2):72–82, 2008
2008
-
[21]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. pages 234–241. Springer, 2015
2015
-
[22]
The MNIST database of handwritten digits.http://yann
Yann LeCun. The MNIST database of handwritten digits.http://yann. lecun. com/exdb/mnist/, 1998
1998
-
[23]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. pages 3730–3738, 2015
2015
-
[24]
fastMRI: An Open Dataset and Benchmarks for Accelerated MRI
Jure Zbontar, Florian Knoll, Anuroop Sriram, Tullie Murrell, Zhengnan Huang, Matthew J Muckley, Aaron Defazio, Ruben Stern, Patricia Johnson, and Mary Bruno. fastMRI: An open dataset and benchmarks for accelerated MRI.arXiv preprint arXiv:1811.08839, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[25]
Compressed sensing MRI: a review.Critical Reviews™ in Biomedical Engineering, 41(3), 2013
Sairam Geethanath, Rashmi Reddy, Amaresha Shridhar Konar, Shaikh Imam, Rajagopalan Sundaresan, Ramesh Babu DR, and Ramesh Venkatesan. Compressed sensing MRI: a review.Critical Reviews™ in Biomedical Engineering, 41(3), 2013. 11 Flow-Based Gen. Modeling for Optimizing Sampling Policies in Comp. Sensing Applications
2013
-
[26]
Learning fast approximations of sparse coding
Karol Gregor and Yann LeCun. Learning fast approximations of sparse coding. pages 399–406, 2010
2010
-
[27]
MoDL: Model-based deep learning architecture for inverse problems.IEEE transactions on medical imaging, 38(2):394–405, 2018
Hemant K Aggarwal, Merry P Mani, and Mathews Jacob. MoDL: Model-based deep learning architecture for inverse problems.IEEE transactions on medical imaging, 38(2):394–405, 2018
2018
-
[28]
End-to-end variational networks for accelerated MRI reconstruction
Anuroop Sriram, Jure Zbontar, Tullie Murrell, Aaron Defazio, C Lawrence Zitnick, Nafissa Yakubova, Florian Knoll, and Patricia Johnson. End-to-end variational networks for accelerated MRI reconstruction. pages 64–73. Springer, 2020
2020
-
[29]
Plug-and-play methods provably converge with properly trained denoisers
Ernest Ryu, Jialin Liu, Sicheng Wang, Xiaohan Chen, Zhangyang Wang, and Wotao Yin. Plug-and-play methods provably converge with properly trained denoisers. pages 5546–5557. PMLR, 2019
2019
-
[30]
Pseudoinverse-guided diffusion models for inverse problems
Jiaming Song, Arash Vahdat, Morteza Mardani, and Jan Kautz. Pseudoinverse-guided diffusion models for inverse problems. 2023
2023
-
[31]
Learning-based optimization of the under-sampling pattern in MRI
Cagla Deniz Bahadir, Adrian V Dalca, and Mert R Sabuncu. Learning-based optimization of the under-sampling pattern in MRI. pages 780–792. Springer, 2019
2019
-
[32]
Categorical Reparameterization with Gumbel-Softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax.arXiv preprint arXiv:1611.01144, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[33]
The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables
Chris J Maddison, Andriy Mnih, and Yee Whye Teh. The concrete distribution: A continuous relaxation of discrete random variables.arXiv preprint arXiv:1611.00712, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[34]
Chieh-Hsin Lai, Yang Song, Dongjun Kim, Yuki Mitsufuji, and Stefano Ermon.The Principles of Diffusion Models. 2025
2025
-
[35]
Multi-task learning using uncertainty to weigh losses for scene geometry and semantics
Alex Kendall, Yarin Gal, and Roberto Cipolla. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. pages 7482–7491, 2018
2018
-
[36]
Yanjie Zhu, Zhen Zhang, Yunli Wang, Zhiqiang Wang, Yu Li, Rufan Zhou, Shiyang Wen, Peng Jiang, Chenhao Lin, and Jian Yang. Differentiable Fast Top-K Selection for Large-Scale Recommendation.arXiv preprint arXiv:2510.11472, 2025
-
[37]
arXiv preprint arXiv:1903.05662 (2019)
Penghang Yin, Jiancheng Lyu, Shuai Zhang, Stanley Osher, Yingyong Qi, and Jack Xin. Understanding straight- through estimator in training activation quantized neural nets.arXiv preprint arXiv:1903.05662, 2019
-
[38]
Iris AM Huijben, Wouter Kool, Max B Paulus, and Ruud JG Van Sloun. A review of the gumbel-max trick and its extensions for discrete stochasticity in machine learning.IEEE transactions on pattern analysis and machine intelligence, 45(2):1353–1371, 2022
2022
-
[39]
unrolled
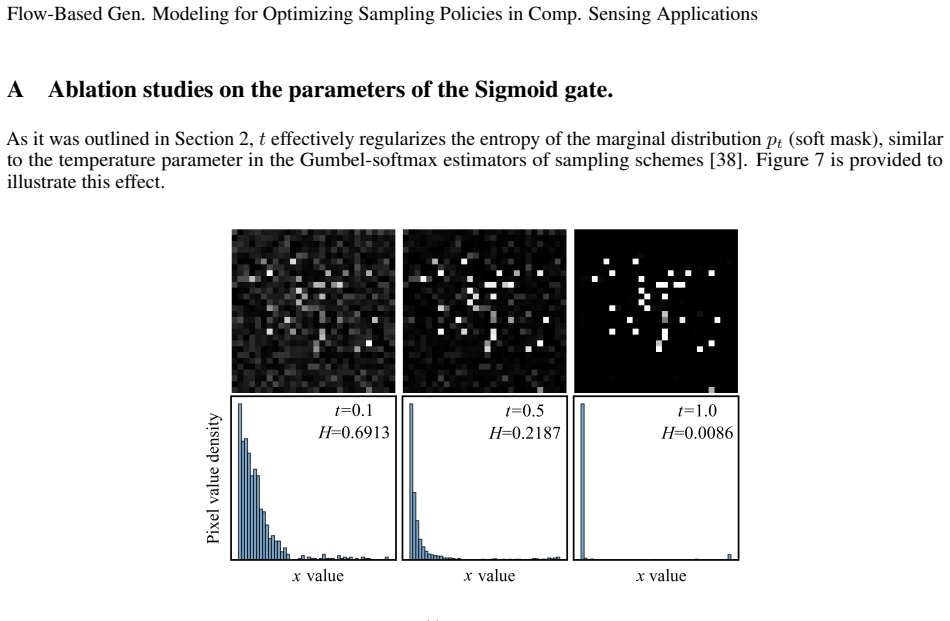
Bernd André Jung and Matthias Weigel. Spin echo magnetic resonance imaging.Journal of Magnetic Resonance Imaging, 37(4):805–817, 2013. 12 Flow-Based Gen. Modeling for Optimizing Sampling Policies in Comp. Sensing Applications A Ablation studies on the parameters of the Sigmoid gate. As it was outlined in Section 2, t effectively regularizes the entropy of...
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.