ProMSA:Progressive Multimodal Search Agents for Knowledge-Based Visual Question Answering
Pith reviewed 2026-06-29 04:58 UTC · model grok-4.3
The pith
A progressive agent that iteratively chooses image search, text search, or stop improves retrieval and accuracy on knowledge-based visual question answering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ProMSA is a progressive multimodal search agent that, given an image-question pair, iteratively selects among image search, text search, or stopping, subject to explicit tool-call budgets and deduplication. It is trained first with rejection-sampling SFT for valid formats, then optimized with TN-GSPO, a sequence-level RL objective normalizing updates by generation length and tool-interaction depth. This yields consistent gains in retrieval quality and answer accuracy on the E-VQA and InfoSeek benchmarks compared to RAG and agent baselines.
What carries the argument
The progressive multimodal search agent that makes iterative decisions among image search, text search, or stop, with budgets and deduplication.
Load-bearing premise
The assumption that an iterative choice among image search, text search, or stop under tool budgets and deduplication will produce better retrieval and accuracy than fixed retrieve-then-generate pipelines.
What would settle it
An experiment on E-VQA or InfoSeek in which the ProMSA agent achieves no higher retrieval quality or end-to-end accuracy than the strongest fixed RAG baseline.
Figures
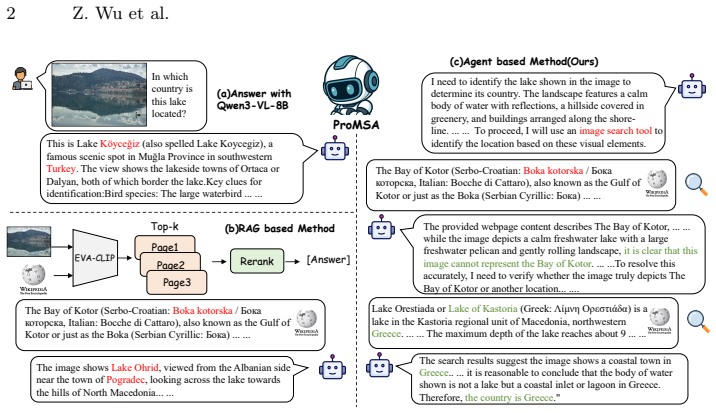
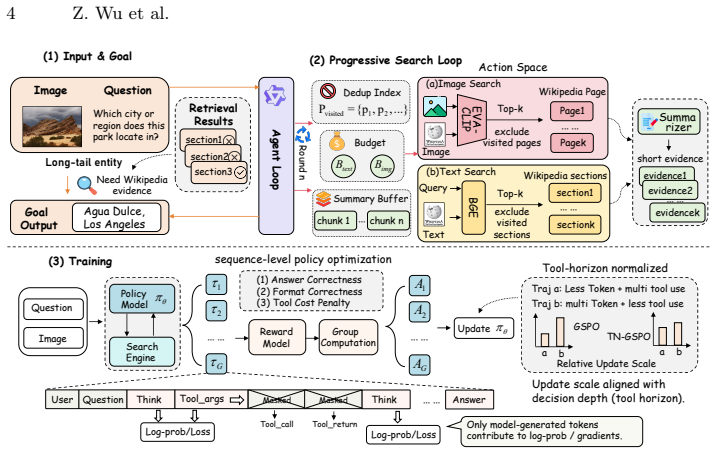
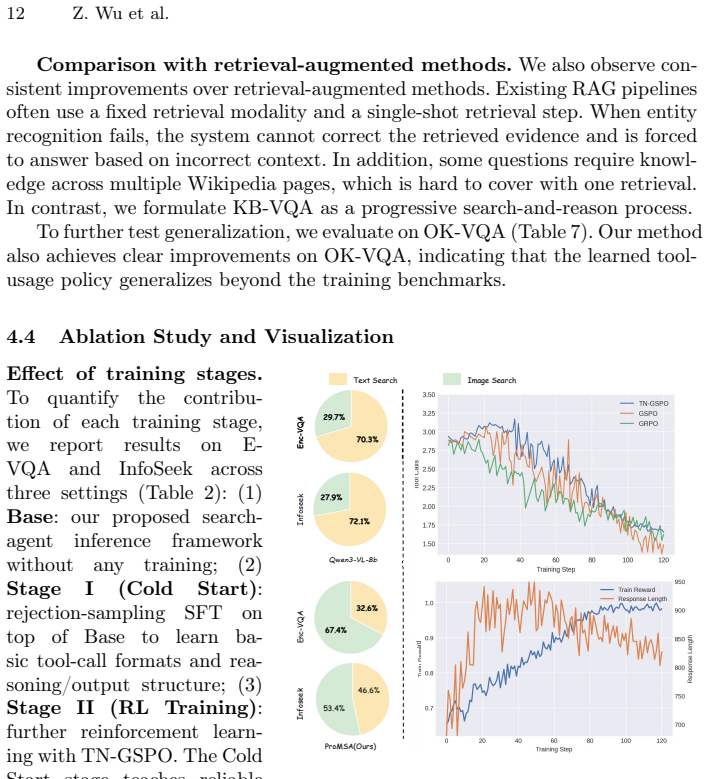

read the original abstract
Knowledge-based Visual Question Answering (KB-VQA) requires models to combine image understanding with external knowledge. Most prior methods use a fixed retrieve-then-generate pipeline with a pre-selected retriever and a static top-k setting, which is not adaptive during reasoning. We propose ProMSA, a progressive multimodal search agent for KB-VQA. Given an image-question pair, the agent iteratively chooses image search, text search, or stop, under explicit tool-call budgets and with deduplication to avoid redundant retrieval. For training, we first use rejection-sampling SFT to learn valid tool-use formats, then optimize the agent with TN-GSPO, a sequence-level RL objective that normalizes updates by both generation length and tool-interaction depth. Experiments on E-VQA and InfoSeek show consistent gains over strong RAG and agent baselines, and improved retrieval and end-to-end accuracy. The code is available at https://github.com/DingWu1021/Promsa.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ProMSA, a progressive multimodal search agent for KB-VQA. The agent iteratively selects among image search, text search, or stopping, subject to explicit tool-call budgets and deduplication to prevent redundancy. Training proceeds in two stages: rejection-sampling SFT to learn valid tool-use formats, followed by optimization using the TN-GSPO sequence-level RL objective, which normalizes updates by both generation length and tool-interaction depth. Experiments on the E-VQA and InfoSeek benchmarks report consistent improvements over strong RAG and agent baselines in retrieval and end-to-end accuracy. The code is publicly available.
Significance. If the reported gains hold under scrutiny, the work provides empirical support for adaptive iterative search over fixed retrieve-then-generate pipelines in multimodal KB-VQA. The public code release supports reproducibility. The TN-GSPO objective is a contribution to sequence-level RL for agents with variable tool-interaction depths. This advances agentic approaches in vision-language reasoning.
minor comments (2)
- [Experiments] The abstract states that experiments show 'consistent gains' and 'improved retrieval and end-to-end accuracy' but provides no numerical values, error bars, or statistical tests; the results section should include these to allow assessment of the central claim.
- [4] The motivation highlights the limitation of static top-k settings, yet the paper should include an explicit ablation comparing the learned iterative policy against a fixed-budget non-adaptive variant to isolate the benefit of adaptivity.
Simulated Author's Rebuttal
We thank the referee for their positive summary, recognition of the work's significance, and recommendation of minor revision. No specific major comments are listed in the report.
Circularity Check
No significant circularity detected
full rationale
The paper is an empirical proposal of an iterative multimodal search agent (ProMSA) for KB-VQA. It describes a training pipeline using rejection-sampling SFT followed by the TN-GSPO sequence-level RL objective, then reports experimental gains on E-VQA and InfoSeek over RAG and agent baselines. No equations, fitted parameters, or first-principles derivations appear in the abstract or described method that reduce any claimed result to a definition or self-referential input. The central claim rests on external benchmark comparisons rather than any internal reduction or self-citation chain. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2303.08774 (2023)
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
Pith/arXiv arXiv 2023
-
[2]
arXiv preprint arXiv:2511.21631 (2025)
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
Pith/arXiv arXiv 2025
-
[3]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report (2025),https://arxiv.org/abs/2502.13923
Pith/arXiv arXiv 2025
-
[4]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Caffagni,D.,Cocchi,F.,Moratelli,N.,Sarto,S.,Cornia,M.,Baraldi,L.,Cucchiara, R.: Wiki-llava: Hierarchical retrieval-augmented generation for multimodal llms. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1818–1826 (2024)
2024
-
[5]
In: Findings of the association for computational linguistics: ACL 2024
Chen, J., Xiao, S., Zhang, P., Luo, K., Lian, D., Liu, Z.: M3-embedding: Multi- linguality, multi-functionality, multi-granularity text embeddings through self- knowledge distillation. In: Findings of the association for computational linguistics: ACL 2024. pp. 2318–2335 (2024)
2024
-
[6]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Chen, X., Shukla, S.N., Azab, M., Singh, A., Wang, Q., Yang, D., Peng, S., Yu, H., Yan, S., Zhang, X., et al.: Compcap: Improving multimodal large language models with composite captions. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 23582–23592 (2025)
2025
-
[7]
Chen, Y., Hu, H., Luan, Y., Sun, H., Changpinyo, S., Ritter, A., Chang, M.W.: Can pre-trained vision and language models answer visual information-seeking ques- tions? In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 14948–14968 (2023)
2023
-
[8]
arXiv preprint arXiv:2512.24330 (2025)
Chng, Y.X., Hu, T., Tong, W., Li, X., Chen, J., Yu, H., Lu, J., Guo, H., Deng, H., Xie, C., et al.: Sensenova-mars: Empowering multimodal agentic reasoning and search via reinforcement learning. arXiv preprint arXiv:2512.24330 (2025)
arXiv 2025
-
[9]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Cocchi, F., Moratelli, N., Cornia, M., Baraldi, L., Cucchiara, R.: Augmenting mul- timodal llms with self-reflective tokens for knowledge-based visual question answer- ing. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 9199–9209 (2025) 16 Z. Wu et al
2025
-
[10]
arXiv preprint arXiv:2511.22715 (2025)
Compagnoni, A., Morini, M., Sarto, S., Cocchi, F., Caffagni, D., Cornia, M., Baraldi, L., Cucchiara, R.: Reag: Reasoning-augmented generation for knowledge- based visual question answering. arXiv preprint arXiv:2511.22715 (2025)
arXiv 2025
-
[11]
arXiv preprint arXiv:2511.05271 (2025)
Hong, J., Zhao, C., Zhu, C., Lu, W., Xu, G., Yu, X.: Deepeyesv2: Toward agentic multimodal model. arXiv preprint arXiv:2511.05271 (2025)
Pith/arXiv arXiv 2025
-
[12]
arXiv preprint arXiv:2602.23952 (2026)
Hong, Y., Gu, J., Lou, Y., Fan, L., Yang, Q., Wang, Y., Ding, K., Wu, Y., Xiang, S., Ye, J.: Cc-vqa: Conflict-and correlation-aware method for mitigating knowledge conflict in knowledge-based visual question answering. arXiv preprint arXiv:2602.23952 (2026)
arXiv 2026
-
[13]
arXiv preprint arXiv:2510.14605 (2025)
Hong, Y., Gu, J., Yang, Q., Fan, L., Wu, Y., Wang, Y., Ding, K., Xiang, S., Ye, J.: Knowledge-based visual question answer with multimodal processing, retrieval and filtering. arXiv preprint arXiv:2510.14605 (2025)
arXiv 2025
-
[14]
arXiv preprint arXiv:2503.09516 (2025)
Jin, B., Zeng, H., Yue, Z., Yoon, J., Arik, S., Wang, D., Zamani, H., Han, J.: Search-r1: Training llms to reason and leverage search engines with reinforcement learning. arXiv preprint arXiv:2503.09516 (2025)
Pith/arXiv arXiv 2025
-
[15]
In: International conference on machine learning
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International conference on machine learning. pp. 19730–19742. PMLR (2023)
2023
-
[16]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Li, X., Dong, G., Jin, J., Zhang, Y., Zhou, Y., Zhu, Y., Zhang, P., Dou, Z.: Search- o1: Agentic search-enhanced large reasoning models. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 5420–5438 (2025)
2025
-
[17]
arXiv preprint arXiv:2504.10074 (2025)
Ling, Z., Guo, Z., Huang, Y., An, Y., Xiao, S., Lan, J., Zhu, X., Zheng, B.: Mmkb- rag: A multi-modal knowledge-based retrieval-augmented generation framework. arXiv preprint arXiv:2504.10074 (2025)
arXiv 2025
-
[18]
arXiv preprint arXiv:2602.15915 (2026)
Mao, X., Ye, K., Zhou, S., Zhang, N., Huang, H., Li, B., Bu, J.: Mas-vqa: A mask-and-select framework for knowledge-based visual question answering. arXiv preprint arXiv:2602.15915 (2026)
arXiv 2026
-
[19]
In: Proceedings of the IEEE/cvf conference on computer vision and pattern recognition
Marino,K.,Rastegari,M.,Farhadi,A.,Mottaghi,R.:Ok-vqa:Avisualquestionan- swering benchmark requiring external knowledge. In: Proceedings of the IEEE/cvf conference on computer vision and pattern recognition. pp. 3195–3204 (2019)
2019
-
[20]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Mensink, T., Uijlings, J., Castrejon, L., Goel, A., Cadar, F., Zhou, H., Sha, F., Araujo, A., Ferrari, V.: Encyclopedic vqa: Visual questions about detailed prop- erties of fine-grained categories. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3113–3124 (2023)
2023
-
[21]
arXiv preprint arXiv:2402.03300 (2024)
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024)
Pith/arXiv arXiv 2024
-
[22]
arXiv preprint arXiv: 2409.19256 (2024)
Sheng, G., Zhang, C., Ye, Z., Wu, X., Zhang, W., Zhang, R., Peng, Y., Lin, H., Wu, C.: Hybridflow: A flexible and efficient rlhf framework. arXiv preprint arXiv: 2409.19256 (2024)
Pith/arXiv arXiv 2024
-
[23]
arXiv preprint arXiv:2303.15389 (2023)
Sun, Q., Fang, Y., Wu, L., Wang, X., Cao, Y.: Eva-clip: Improved training tech- niques for clip at scale. arXiv preprint arXiv:2303.15389 (2023)
Pith/arXiv arXiv 2023
-
[24]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, P., Li, Z.Z., Yin, F., Ran, D., Liu, C.L.: Mv-math: Evaluating multimodal math reasoning in multi-visual contexts. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 19541–19551 (2025)
2025
-
[25]
arXiv preprint arXiv:2503.10042 (2025)
Wang, Z., Dong, Y., Luo, F., Ruan, M., Cheng, Z., Chen, C., Li, P., Liu, Y.: Escapecraft: A 3d room escape environment for benchmarking complex multimodal reasoning ability. arXiv preprint arXiv:2503.10042 (2025)
arXiv 2025
-
[26]
arXiv preprint arXiv:2506.20670 (2025) Title Suppressed Due to Excessive Length 17
Wu, J., Deng, Z., Li, W., Liu, Y., You, B., Li, B., Ma, Z., Liu, Z.: Mmsearch-r1: Incentivizing lmms to search. arXiv preprint arXiv:2506.20670 (2025) Title Suppressed Due to Excessive Length 17
Pith/arXiv arXiv 2025
-
[27]
In: Findings of the Association for Computational Linguistics: EMNLP 2024
Yan, Y., Xie, W.: Echosight: Advancing visual-language models with wiki knowl- edge. In: Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 1538–1551 (2024)
2024
-
[28]
In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers)
Yang, W., Fu, J., Wang, R., Wang, J., Song, L., Bian, J.: Omgm: Orchestrate mul- tiple granularities and modalities for efficient multimodal retrieval. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers). pp. 24545–24563 (2025)
2025
-
[29]
arXiv preprint arXiv:2602.14065 (2026)
Ye, K., Mao, X., Zhou, S., Shao, Z., Mo, Y., Liu, L., Huang, H., Li, B., Bu, J.: Real: Resolving knowledge conflicts in knowledge-intensive visual question answering via reasoning-pivot alignment. arXiv preprint arXiv:2602.14065 (2026)
Pith/arXiv arXiv 2026
-
[30]
Ye,W.,Su,Y.,Chen,Y.,Gao,L.,Li,J.,Li,R.,Zhang,R.:Qkvqa:Question-focused filtering for knowledge-based vqa (2026),https://arxiv.org/abs/2601.13856
Pith/arXiv arXiv 2026
-
[31]
National Science Review11(12), nwae403 (2024)
Yin, S., Fu, C., Zhao, S., Li, K., Sun, X., Xu, T., Chen, E.: A survey on multimodal large language models. National Science Review11(12), nwae403 (2024)
2024
-
[32]
arXiv preprint arXiv:2507.18071 (2025)
Zheng, C., Liu, S., Li, M., Chen, X.H., Yu, B., Gao, C., Dang, K., Liu, Y., Men, R., Yang, A., et al.: Group sequence policy optimization. arXiv preprint arXiv:2507.18071 (2025)
Pith/arXiv arXiv 2025
-
[33]
Zheng, Y., Zhang, R., Zhang, J., Ye, Y., Luo, Z., Feng, Z., Ma, Y.: Llamafac- tory: Unified efficient fine-tuning of 100+ language models. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations). Association for Computational Linguistics, Bangkok, Thailand (2024),http://arxiv.org/abs/2403.13372
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.