SLAT: Segment-Level Adaptive Trimming for Efficient CoT Reasoning
Pith reviewed 2026-06-28 22:25 UTC · model grok-4.3
The pith
SLAT trims low-utility segments in chain-of-thought outputs to halve reasoning length while keeping accuracy competitive.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We demonstrate that inefficiency concentrates in high-probability segments with low marginal utility. We derive a theoretical characterization of segment suboptimality under the correctness-length trade-off objective and propose SLAT, an RL framework that selectively suppresses redundant segments based on this criterion. Empirical results indicate that SLAT establishes a superior accuracy-efficiency Pareto frontier, reducing reasoning length by 50% relative to uncompressed baselines while maintaining competitive accuracy.
What carries the argument
SLAT, the segment-level adaptive trimming RL framework that suppresses redundant reasoning segments according to a derived suboptimality criterion under the correctness-length objective.
Load-bearing premise
That inefficiency concentrates in high-probability segments with low marginal utility and that an RL policy can selectively suppress those segments without inadvertently removing useful reasoning steps.
What would settle it
A controlled comparison on the same benchmarks where SLAT produces either larger accuracy drops than uniform-penalty baselines at matched lengths or fails to achieve substantial length reduction.
Figures
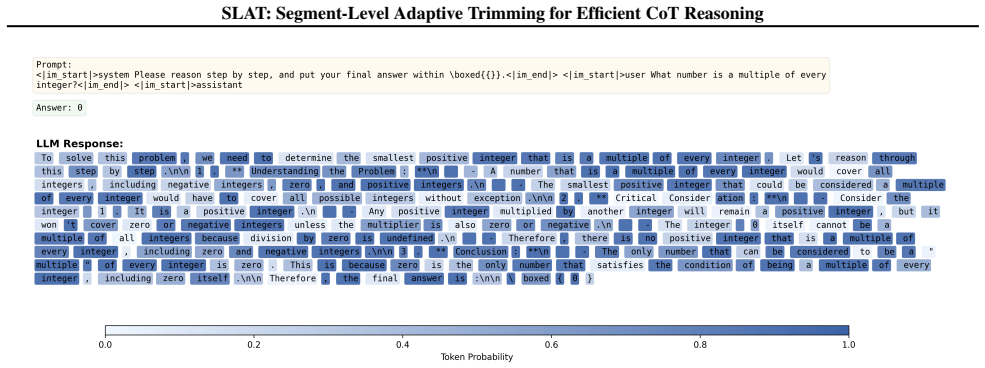
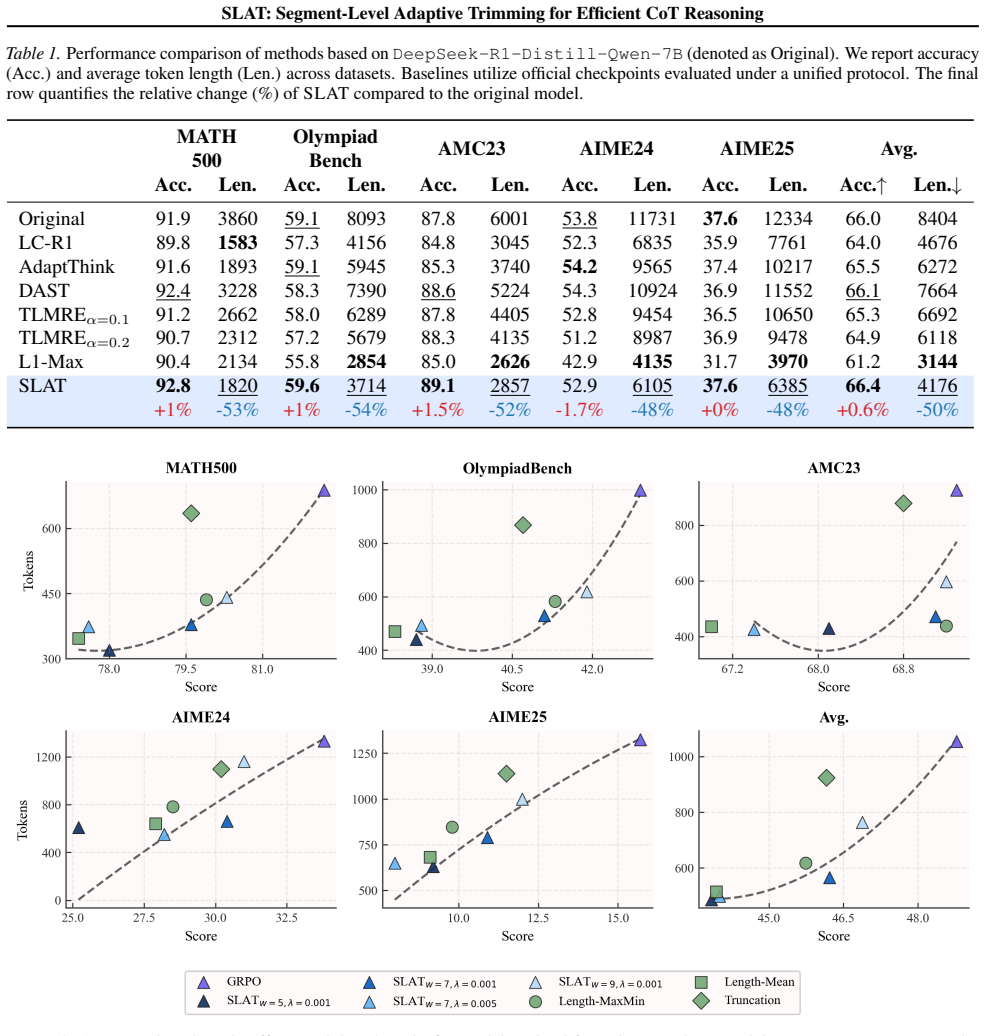
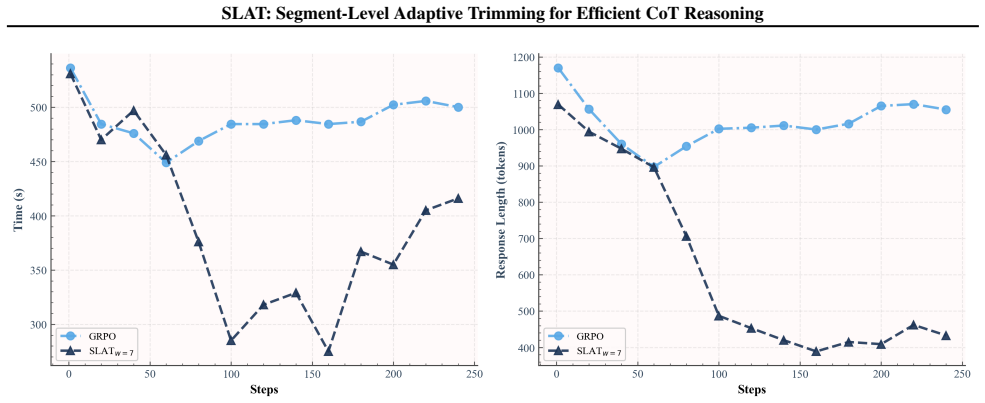

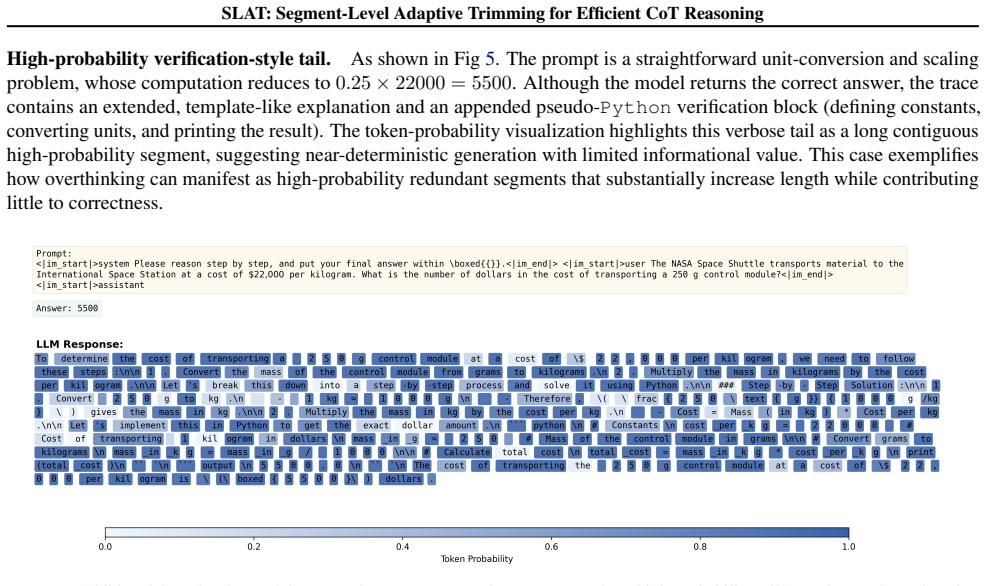
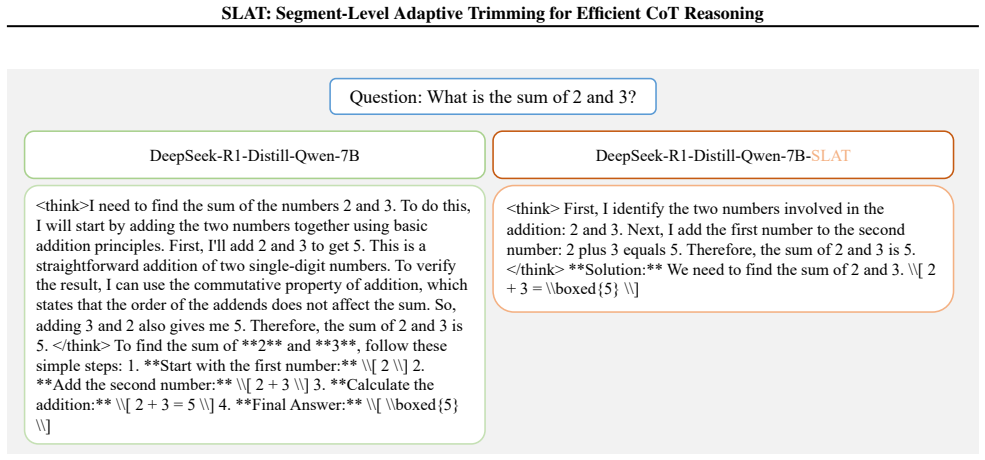

read the original abstract
Recent advances in Large Reasoning Models have significantly improved chain-of-thought (CoT) capabilities via reinforcement learning (RL). However, generated reasoning chains frequently suffer from structural redundancy (i.e., \emph{overthinking}), incurring high computational overhead without improving answer correctness. Existing mitigation strategies typically rely on token-uniform length penalties, which provide coarse, segment-agnostic pressure toward shorter outputs and can inadvertently suppress useful reasoning alongside redundancy. To address this, we demonstrate that inefficiency concentrates in high-probability segments with low marginal utility. We derive a theoretical characterization of segment suboptimality under the correctness-length trade-off objective and propose \textsc{SLAT} (Segment-Level Adaptive Trimming), an RL framework that selectively suppresses redundant segments based on this criterion. Empirical results on standard benchmarks indicate that \textsc{SLAT} establishes a superior accuracy-efficiency Pareto frontier, reducing reasoning length by $50\%$ relative to uncompressed baselines while maintaining competitive accuracy. Overall, our results suggest that theoretically grounded, segment-aware trimming is a promising direction for efficient CoT reasoning in large language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SLAT, an RL-based framework for segment-level adaptive trimming of chain-of-thought (CoT) reasoning in large reasoning models. It claims that inefficiency concentrates in high-probability segments with low marginal utility, derives a theoretical characterization of segment suboptimality under a correctness-length objective, and uses this to selectively suppress redundant segments. Empirical results on standard benchmarks are said to show a superior accuracy-efficiency Pareto frontier, with 50% reduction in reasoning length relative to baselines while maintaining competitive accuracy.
Significance. If the theoretical derivation is valid, non-circular, and the RL policy demonstrably preserves correctness while trimming only low-utility segments, the work would offer a principled alternative to token-uniform length penalties for efficient CoT. The segment-aware approach could meaningfully advance efficiency in reasoning models if the marginal-utility criterion generalizes beyond the evaluated settings.
major comments (3)
- [Abstract / theoretical derivation] Abstract and theoretical section: the manuscript states that a 'theoretical characterization of segment suboptimality' is derived under the correctness-length objective, yet provides no equations, proof steps, or explicit definition of marginal utility. Without these, it is impossible to verify whether the criterion accounts for sequential dependencies between segments or reduces to a fitted proxy (e.g., high probability alone).
- [Abstract] Abstract: the central empirical claim of a 'superior accuracy-efficiency Pareto frontier' with 50% length reduction is asserted, but the abstract supplies no details on how marginal utility is measured, which baselines are used, or any validation that the trimming rule preserves answer correctness on cases where early segments affect later utility.
- [Abstract / method overview] The assumption that inefficiency concentrates in high-probability segments with low marginal utility is load-bearing for the RL policy design; if segments are interdependent, the policy could suppress necessary steps. No evidence or counter-example analysis is referenced to address this risk.
minor comments (2)
- Notation for 'marginal utility' and 'segment suboptimality' should be defined explicitly with symbols before use in the derivation.
- [Abstract] The abstract would benefit from a brief statement of the objective function (correctness-length trade-off) to make the theoretical claim self-contained.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to improve clarity. We respond to each major comment below. Where details are missing from the abstract due to space limits, we will revise the manuscript to include them.
read point-by-point responses
-
Referee: [Abstract / theoretical derivation] Abstract and theoretical section: the manuscript states that a 'theoretical characterization of segment suboptimality' is derived under the correctness-length objective, yet provides no equations, proof steps, or explicit definition of marginal utility. Without these, it is impossible to verify whether the criterion accounts for sequential dependencies between segments or reduces to a fitted proxy (e.g., high probability alone).
Authors: The derivation appears in Section 3, where marginal utility is defined as the expected incremental contribution to the joint correctness-length objective and the proof shows that the segment-level value function accounts for sequential dependencies (via conditioning on prior segments). The abstract summarizes without equations for brevity. We will add a concise equation outline to the abstract and expand the proof sketch in Section 3 for verifiability. revision: yes
-
Referee: [Abstract] Abstract: the central empirical claim of a 'superior accuracy-efficiency Pareto frontier' with 50% length reduction is asserted, but the abstract supplies no details on how marginal utility is measured, which baselines are used, or any validation that the trimming rule preserves answer correctness on cases where early segments affect later utility.
Authors: Marginal utility is measured via the learned segment-level reward in the RL objective (Section 4.2); baselines include token-uniform length penalties and prior CoT compression methods (Section 5.1); correctness preservation is validated via per-benchmark accuracy and early-segment ablation (Section 5.3). We will revise the abstract to reference these elements briefly. revision: yes
-
Referee: [Abstract / method overview] The assumption that inefficiency concentrates in high-probability segments with low marginal utility is load-bearing for the RL policy design; if segments are interdependent, the policy could suppress necessary steps. No evidence or counter-example analysis is referenced to address this risk.
Authors: Section 3 derives that the objective penalizes only low-marginal-utility segments while preserving dependencies through the policy's value estimation. Experiments in Section 5 demonstrate maintained accuracy on sequential tasks, serving as evidence. We will add an explicit counter-example analysis subsection in the revision. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract states that a theoretical characterization of segment suboptimality is derived under the correctness-length objective, followed by an RL framework based on that criterion. No equations, self-citations, or fitted parameters are quoted in the provided text that would reduce the characterization or trimming rule to its own inputs by construction. The derivation is presented as independent content supporting the empirical Pareto frontier claim, with no load-bearing self-citation chains or renaming of known results evident. This qualifies as a standard non-finding under the rules requiring explicit quotes of reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
L1: Controlling How Long A Reasoning Model Thinks With Reinforcement Learning
Aggarwal, P. and Welleck, S. L1: Controlling how long a reasoning model thinks with reinforcement learning. arXiv preprint arXiv:2503.04697,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Arora, D. and Zanette, A. Training language models to rea- son efficiently.arXiv preprint arXiv:2502.04463,
-
[3]
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
Chen, X., Xu, J., Liang, T., He, Z., Pang, J., Yu, D., Song, L., Liu, Q., Zhou, M., Zhang, Z., et al. Do not think that much for 2+ 3=? on the overthinking of o1-like llms. arXiv preprint arXiv:2412.21187,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Optimizing length compression in large reasoning models.arXiv preprint arXiv:2506.14755,
Cheng, Z., Chen, D., Fu, M., and Zhou, T. Optimizing length compression in large reasoning models.arXiv preprint arXiv:2506.14755,
-
[5]
Efficient reasoning models: A survey.arXiv preprint arXiv:2504.10903, 2025
Feng, S., Fang, G., Ma, X., and Wang, X. Efficient reasoning models: A survey.arXiv preprint arXiv:2504.10903,
-
[6]
He, C., Luo, R., Bai, Y ., Hu, S., Thai, Z. L., Shen, J., Hu, J., Han, X., Huang, Y ., Zhang, Y ., et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad- level bilingual multimodal scientific problems.arXiv preprint arXiv:2402.14008,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
He, Q., Yuan, S., Li, X., Wang, M., and Chen, J. Thinkdial: An open recipe for controlling reasoning effort in large language models.arXiv preprint arXiv:2508.18773,
-
[8]
Measuring Massive Multitask Language Understanding
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring mas- sive multitask language understanding.arXiv preprint arXiv:2009.03300,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[9]
Measuring Mathematical Problem Solving With the MATH Dataset
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring math- ematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
ThinkPrune: Pruning Long Chain-of-Thought of LLMs via Reinforcement Learning
Hou, B., Zhang, Y ., Ji, J., Liu, Y ., Qian, K., Andreas, J., and Chang, S. Thinkprune: Pruning long chain-of- thought of llms via reinforcement learning.arXiv preprint arXiv:2504.01296,
work page internal anchor Pith review Pith/arXiv arXiv
- [11]
-
[12]
Halt-cot: Model-agnostic early stopping for chain-of-thought reasoning via answer entropy
Laaouach, Y . Halt-cot: Model-agnostic early stopping for chain-of-thought reasoning via answer entropy. In4th Muslims in ML Workshop co-located with ICML 2025,
2025
-
[13]
How well do llms compress their own chain-of-thought? a token complexity approach
Lee, A., Che, E., and Peng, T. How well do llms compress their own chain-of-thought? a token complexity approach. arXiv preprint arXiv:2503.01141,
-
[14]
Compressing chain-of-thought in llms via step entropy.arXiv preprint arXiv:2508.03346,
Li, Z., Zhong, J., Zheng, Z., Wen, X., Xu, Z., Cheng, Y ., Zhang, F., and Xu, Q. Compressing chain-of-thought in llms via step entropy.arXiv preprint arXiv:2508.03346,
-
[15]
Ling, Z., Chen, D., Zhang, H., Jiao, Y ., Guo, X., and Cheng, Y . Fast on the easy, deep on the hard: Efficient reasoning via powered length penalty.arXiv preprint arXiv:2506.10446,
-
[16]
Liu, W., Zhou, R., Deng, Y ., Huang, Y ., Liu, J., Deng, Y ., Zhang, Y ., and He, J. Learn to reason efficiently with adaptive length-based reward shaping.arXiv preprint arXiv:2505.15612, 2025a. Liu, Z., Chen, C., Li, W., Qi, P., Pang, T., Du, C., Lee, W. S., and Lin, M. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503...
- [17]
-
[18]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Push- ing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Dast: Difficulty- adaptive slow-thinking for large reasoning models.arXiv preprint arXiv:2503.04472,
Shen, Y ., Zhang, J., Huang, J., Shi, S., Zhang, W., Yan, J., Wang, N., Wang, K., Liu, Z., and Lian, S. Dast: Difficulty- adaptive slow-thinking for large reasoning models.arXiv preprint arXiv:2503.04472,
-
[20]
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
Sui, Y ., Chuang, Y .-N., Wang, G., Zhang, J., Zhang, T., Yuan, J., Liu, H., Wen, A., Zhong, S., Zou, N., et al. Stop overthinking: A survey on efficient reasoning for large language models.arXiv preprint arXiv:2503.16419,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Team, G., Kamath, A., Ferret, J., Pathak, S., Vieillard, N., Merhej, R., Perrin, S., Matejovicova, T., Ram ´e, A., Rivi`ere, M., et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025a. Team, K., Du, A., Gao, B., Xing, B., Jiang, C., Chen, C., Li, C., Xiao, C., Du, C., Liao, C., et al. Kimi k1.5: Scaling reinforcement learning with llms.arX...
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Wei, Z., Pang, L., Liu, J., Deng, J., Xu, S., Duan, Z., Wang, J., Sun, F., Cai, X., Shen, H., et al. Stop spinning wheels: Mitigating llm overthinking via mining patterns for early reasoning exit.arXiv preprint arXiv:2508.17627,
-
[23]
Arm: Adaptive reasoning model.arXiv preprint arXiv:2505.20258,
10 SLAT: Segment-Level Adaptive Trimming for Efficient CoT Reasoning Wu, S., Xie, J., Zhang, Y ., Chen, A., Zhang, K., Su, Y ., and Xiao, Y . Arm: Adaptive reasoning model.arXiv preprint arXiv:2505.20258,
-
[24]
Xia, H., Leong, C. T., Wang, W., Li, Y ., and Li, W. Token- skip: Controllable chain-of-thought compression in llms. arXiv preprint arXiv:2502.12067,
-
[25]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
Yang, A., Zhang, B., Hui, B., Gao, B., Yu, B., Li, C., Liu, D., Tu, J., Zhou, J., Lin, J., Lu, K., Xue, M., Lin, R., Liu, T., Ren, X., and Zhang, Z. Qwen2.5-math technical report: Toward mathematical expert model via self-improvement. arXiv preprint arXiv:2409.12122,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025a. Yang, E., Shen, L., Guo, G., Wang, X., Cao, X., Zhang, J., and Tao, D. Model merging in llms, mllms, and beyond: Methods, theories, applications, and opportunities.ACM Computing Surveys, 58(8):1–41,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Think when you need: Self-adaptive chain-of-thought learning.arXiv preprint arXiv:2504.03234, 2025b
Yang, J., Lin, K., and Yu, X. Think when you need: Self-adaptive chain-of-thought learning.arXiv preprint arXiv:2504.03234, 2025b. Yao, J., Liu, W., Fu, H., Yang, Y ., McAleer, S., Fu, Q., and Yang, W. Policy space diversity for non-transitive games. Advances in Neural Information Processing Systems, 36: 67771–67793,
- [28]
-
[29]
Demystifying Long Chain-of-Thought Reasoning in LLMs
Yeo, E., Tong, Y ., Niu, M., Neubig, G., and Yue, X. Demys- tifying long chain-of-thought reasoning in llms.arXiv preprint arXiv:2502.03373,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Yu, Q., Zhang, Z., Zhu, R., Yuan, Y ., Zuo, X., Yue, Y ., Dai, W., Fan, T., Liu, G., Liu, L., et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Zeng, A., Lv, X., Zheng, Q., Hou, Z., Chen, B., Xie, C., Wang, C., Yin, D., Zeng, H., Zhang, J., et al. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models. arXiv preprint arXiv:2508.06471, 2025a. Zeng, W., Huang, Y ., Liu, Q., Liu, W., He, K., Ma, Z., and He, J. Simplerl-zoo: Investigating and taming zero reinforcement learning for open base ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
= Pθ(A, z1 |x) πθ(z1 |x) ≤ Pθ(A |x) πθ(z1 |x) ,(23) hence, Pθ(A |x, z 1)−P θ(A |x)−λL(z 1)−λE z2∼πθ(z2|x,z1)[L(z2)] +λE z′∼πθ(z′|x)[L(z′)] ≤ 1−π θ(z1|x) πθ(z1|x) Pθ(A |x)−λL(z 1)−λE z2∼πθ(z2|x,z1)[L(z2)] +λE z′∼πθ(z′|x)[L(z′)].(24) Therefore, it suffices to enforce a stronger condition that guarantees Eq. (22). Specifically, whenever L(z1) +E z2∼πθ(·|x,z1...
2023
-
[33]
For GRPO, we follow the standard recipe, except that we use a larger clipping ratio and eliminate the kl loss as suggested in DAPO (Yu et al., 2025)
as the training dataset. For GRPO, we follow the standard recipe, except that we use a larger clipping ratio and eliminate the kl loss as suggested in DAPO (Yu et al., 2025). For SLAT, we adopt the same GRPO recipe and additionally incorporate the efficient-reasoning reward defined in Section 3.2. For length-objective baselines, we follow our GRPO recipe ...
2025
-
[34]
For evaluation, we mainly focus on mathematical reasoning and use five benchmarks: MATH500 (Hendrycks et al., 2021), OlympiadBench (He et al., 2024), AMC23 (MAA, 2023), and AIME24/25 (MAA). For all models, we sample with 14 SLAT: Segment-Level Adaptive Trimming for Efficient CoT Reasoning Table 3.Hyperparameter settings in training Hyperparameter Value Ge...
2021
-
[35]
The problem requires us to group 3 men and 4 women into three groups with at least one man and one woman in each group,
and GPQA (Rein et al., 2024). We follow the same evaluation protocol and report both accuracy and reasoning length using avg@4. Table 4.Hyperparameter settings in evaluation Hyperparameter Value General settings temperature 0.7 top p 1.0 number of sampling 4 (16 for AMC23 and AIME24&25) use vllm true vllm gpu memory utilization 0.6 D. Additional Results D...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.