Do LLMs Truly Generalize in the Molecular Domain? A Perturbation-Based Analysis
Pith reviewed 2026-07-03 17:14 UTC · model grok-4.3
The pith
Molecular LLMs show fragile generalization, with even single structural edits causing large performance drops on standard tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
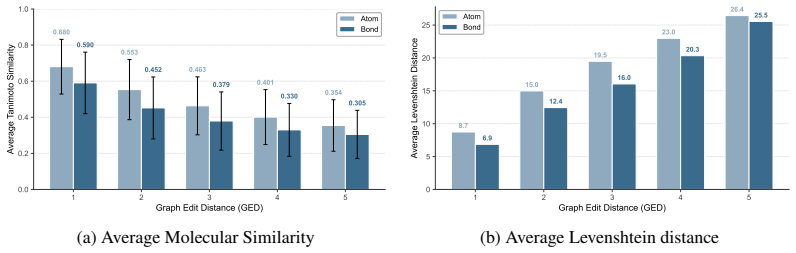
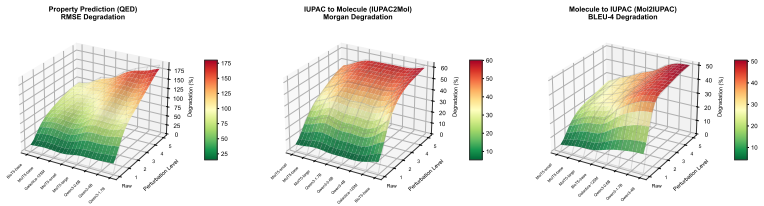
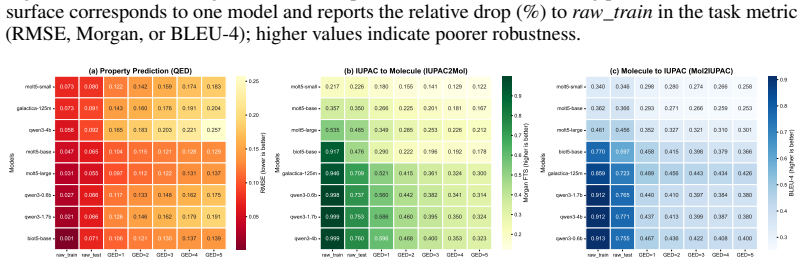
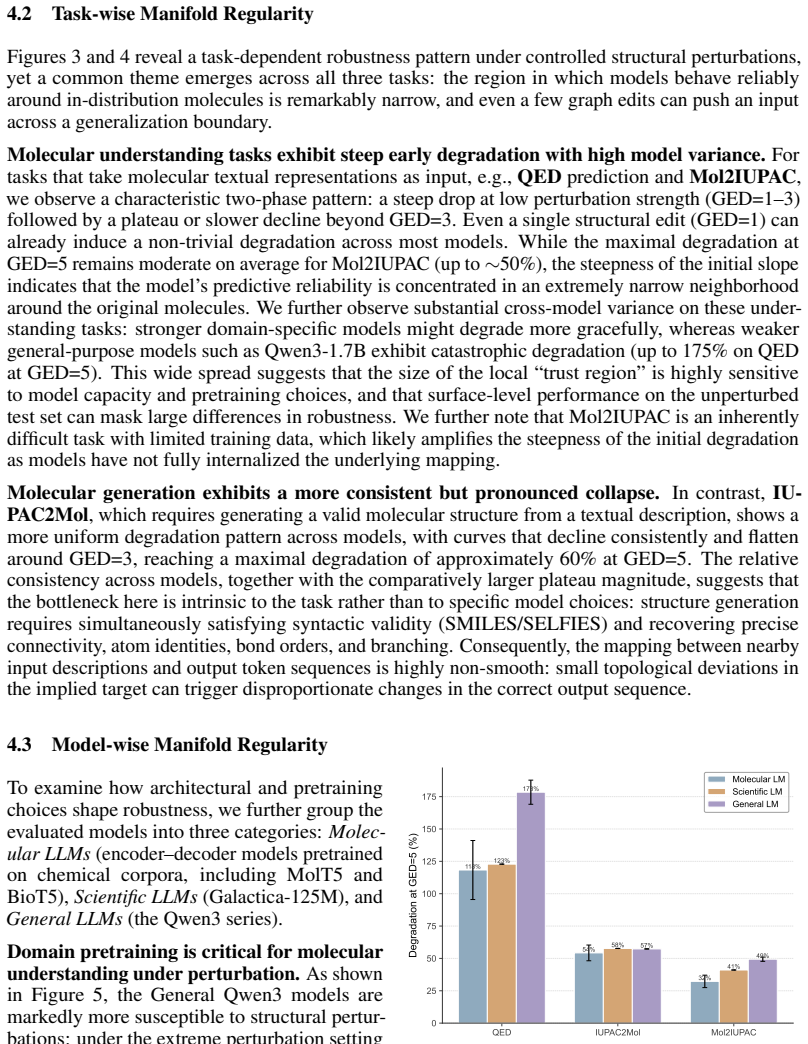
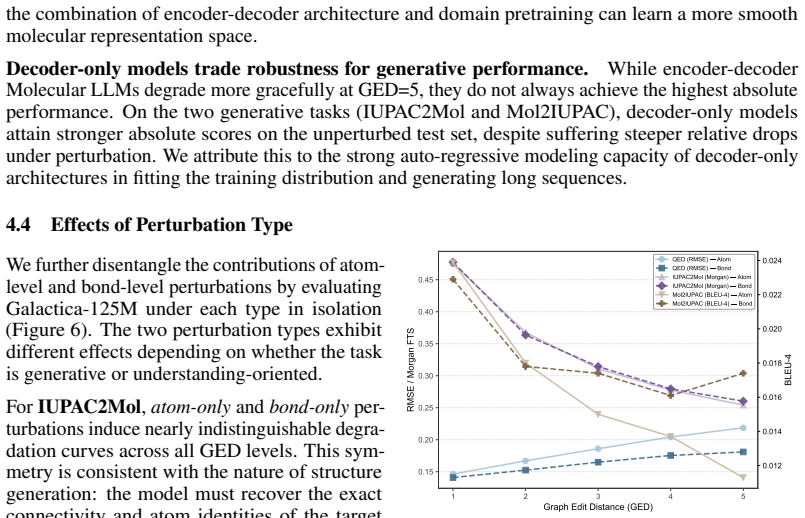
Using a Molecular Perturbation framework that produces syntax-valid structural variants under controlled Graph Edit Distance, the work shows that molecular LLMs suffer substantial performance drops even from a single edit, exposing narrow local trust regions and high sensitivity to structural variation; In-Context Tuning that anchors on similar molecules partially widens these regions.
What carries the argument
Molecular Perturbation framework that generates syntax-valid structural variants under controlled Graph Edit Distance to probe manifold regularity.
If this is right
- A single graph edit produces substantial drops on common molecular prediction tasks.
- In-Context Tuning anchors predictions on similar molecules and partially expands the local trust region.
- Sequence-based representations confine LLMs to narrow neighborhoods despite the similarity principle in chemistry.
- Stabilizing molecular LLMs against structural variation requires methods that explicitly use nearby structures.
Where Pith is reading between the lines
- The same controlled-edit test could be run on protein or materials sequences to check whether the narrow-trust-region pattern appears in other structured domains.
- Hybrid architectures that combine token-based LLMs with explicit graph encoders might enlarge the effective trust region beyond what in-context examples alone achieve.
- If the fragility scales with edit distance in a predictable way, training objectives could be modified to penalize sensitivity inside small GED neighborhoods.
Load-bearing premise
The Graph Edit Distance metric and syntax-valid perturbation procedure produce structural variants whose property changes represent real generalization failures rather than artifacts of the editing rules or chosen tasks.
What would settle it
Models that maintain stable high performance across multiple molecular tasks when tested on the single-edit perturbed molecules would contradict the reported narrow trust regions.
Figures

read the original abstract
Large Language Models (LLMs) have recently shown promise in molecular discovery, yet a gap remains between their probabilistic nature over discrete sequential tokens and the rigid topological constraints of chemical space. This raises the question of whether molecular LLMs can generalize beyond the local neighborhoods induced by their sequence-based representations. To systematically investigate this question, we introduce a Molecular Perturbation framework that generates syntax-valid structural variants of training molecules under controlled Graph Edit Distance (GED) to probe the manifold regularity of molecular LLMs. Our analysis shows that even a single edit can cause substantial performance drops on common molecular tasks, revealing a narrow local trust region and fragile sensitivity to structural changes. Since similar molecules tend to exhibit similar properties, In-Context Tuning (ICT), which anchors predictions on structurally similar molecules, offers a natural way to mitigate such fragility. Our experiments also examine whether ICT confers robustness under controlled structural perturbations, and the results suggest that it can partially expand the local trust region and offer a promising direction for stabilizing molecular LLMs against structural variation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a Molecular Perturbation framework that generates syntax-valid structural variants of molecules via controlled Graph Edit Distance (GED) edits. It reports that even single edits cause substantial performance drops on standard molecular tasks for LLMs, which the authors interpret as evidence of narrow local trust regions and fragile generalization. The work further tests In-Context Tuning (ICT) as a mitigation that partially expands the trust region.
Significance. If the perturbations preserve ground-truth task labels, the controlled GED analysis supplies a useful diagnostic for evaluating whether sequence-based LLMs respect the similarity principle in chemical space, and the ICT results point to a concrete inference-time remedy. The framework itself could serve as a reusable evaluation tool for molecular models.
major comments (1)
- [Abstract and perturbation framework description] The central claim that observed accuracy drops demonstrate model fragility (rather than correct adaptation to changed properties) rests on the unverified premise that syntax-valid GED edits leave task labels (solubility, binding affinity, etc.) essentially unchanged. The abstract invokes the similarity principle but supplies no explicit check—such as property-value histograms or label-consistency statistics before versus after perturbation—that the editing rules preserve the relevant distributions. This assumption is load-bearing for both the fragility diagnosis and the ICT experiments.
minor comments (2)
- [Methods] Define 'syntax-valid' more precisely and state whether additional chemical-validity filters (valence, ring strain, etc.) are applied beyond token-level syntax.
- [Experiments] Report the exact dataset sizes, number of perturbations per molecule, and statistical tests used to establish that the performance drops are significant rather than within noise.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The concern about verifying label preservation under GED perturbations is valid and will be addressed in revision.
read point-by-point responses
-
Referee: The central claim that observed accuracy drops demonstrate model fragility (rather than correct adaptation to changed properties) rests on the unverified premise that syntax-valid GED edits leave task labels (solubility, binding affinity, etc.) essentially unchanged. The abstract invokes the similarity principle but supplies no explicit check—such as property-value histograms or label-consistency statistics before versus after perturbation—that the editing rules preserve the relevant distributions. This assumption is load-bearing for both the fragility diagnosis and the ICT experiments.
Authors: We agree that explicit verification would strengthen the paper. The framework is grounded in the standard similarity principle of cheminformatics, but the current version provides no direct statistical confirmation. In revision we will add (i) property-value histograms for key tasks (solubility, binding affinity) comparing originals to perturbed molecules at GED=1 and higher, and (ii) label-consistency statistics (fraction of cases where ground-truth label is unchanged or changes by less than a task-specific threshold). These will appear in the perturbation framework section and will be used to qualify both the fragility claims and ICT results. With this addition the interpretation that small structural edits should not produce large label shifts (hence performance drops indicate fragility) becomes empirically supported rather than assumed. revision: yes
Circularity Check
No circularity; purely empirical perturbation study
full rationale
The paper introduces a Molecular Perturbation framework and reports experimental performance drops under GED edits on molecular tasks, followed by ICT mitigation tests. No equations, parameter fits, or derivations are present that could reduce claims to inputs by construction. The similarity principle is invoked as standard domain knowledge rather than derived or self-cited in a load-bearing way. All central claims rest on direct measurements, so the work is self-contained with no reduction to fitted quantities or self-referential definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Edwards Carl, Lai Tuan, Ros Kevin, Honke Garrett, Cho Kyunghyun, Ji Heng
84–92. Edwards Carl, Lai Tuan, Ros Kevin, Honke Garrett, Cho Kyunghyun, Ji Heng. Translation between Molecules and Natural Language // Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing
2022
-
[2]
Edwards Carl, Zhai ChengXiang, Ji Heng
375–413. Edwards Carl, Zhai ChengXiang, Ji Heng. Text2mol: Cross-modal molecule retrieval with natural language queries // Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing
2021
-
[3]
Reasoning robustness of llms to adversarial typographical errors // Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Gan Esther, Zhao Yiran, Cheng Liying, Yancan Mao, Goyal Anirudh, Kawaguchi Kenji, Kan Min-Yen, Shieh Michael. Reasoning robustness of llms to adversarial typographical errors // Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
2024
-
[4]
Kumar Pankaj, Mishra Subhankar
045024. Kumar Pankaj, Mishra Subhankar. Robustness in large language models: A survey of mitigation strategies and evaluation metrics // arXiv preprint arXiv:2505.18658
-
[5]
Li Hao, Cao He, Feng Bin, Shao Yanjun, Tang Xiangru, Yan Zhiyuan, Yuan Li, Tian Yonghong, Li Yu. Beyond Chemical QA: Evaluating LLM’s Chemical Reasoning with Modular Chemical Operations // arXiv preprint arXiv:2505.21318
-
[6]
Speak-to-Structure: Evaluating LLMs in Open-domain Natural Language-Driven Molecule Generation
Li Jiatong, Li Junxian, Wang Weida, Liu Yunqing, Zheng Changmeng, Zhou Dongzhan, Wei Xiao- yong, Li Qing. Speak-to-Structure: Evaluating LLMs in Open-domain Natural Language-Driven Molecule Generation // arXiv preprint arXiv:2412.14642. 2024a. Li Jiatong, Liu Yunqing, Fan Wenqi, Wei Xiao-Yong, Liu Hui, Tang Jiliang, Li Qing. Empowering molecule discovery ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
10 Liu Zequn, Zhang Wei, Xia Yingce, Wu Lijun, Xie Shufang, Qin Tao, Zhang Ming, Liu Tie-Yan
6071–6083. 10 Liu Zequn, Zhang Wei, Xia Yingce, Wu Lijun, Xie Shufang, Qin Tao, Zhang Ming, Liu Tie-Yan. MolXPT: Wrapping Molecules with Text for Generative Pre-training // Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (V olume 2: Short Papers). 2023a. 1606–1616. Liu Zhiyuan, Li Sihang, Luo Yanchen, Fei Hao, Cao Y...
2023
-
[8]
Pei Qizhi, Zhang Wei, Zhu Jinhua, Wu Kehan, Gao Kaiyuan, Wu Lijun, Xia Yingce, Yan Rui
9863–9875. Pei Qizhi, Zhang Wei, Zhu Jinhua, Wu Kehan, Gao Kaiyuan, Wu Lijun, Xia Yingce, Yan Rui. BioT5: Enriching Cross-modal Integration in Biology with Chemical Knowledge and Natural Language Associations // Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
2023
-
[9]
Galactica: A Large Language Model for Science
Taylor Ross, Kardas Marcin, Cucurull Guillem, Scialom Thomas, Hartshorn Anthony, Saravia Elvis, Poulton Andrew, Kerkez Viktor, Stojnic Robert. Galactica: A large language model for science // arXiv preprint arXiv:2211.09085
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Yang An, Li Anfeng, Yang Baosong, Zhang Beichen, Hui Binyuan, Zheng Bo, Yu Bowen, Gao Chang, Huang Chengen, Lv Chenxu, others. Qwen3 technical report // arXiv preprint arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Yang Zeyu, Meng Zhao, Zheng Xiaochen, Wattenhofer Roger. Assessing adversarial robustness of large language models: An empirical study // arXiv preprint arXiv:2405.02764
-
[12]
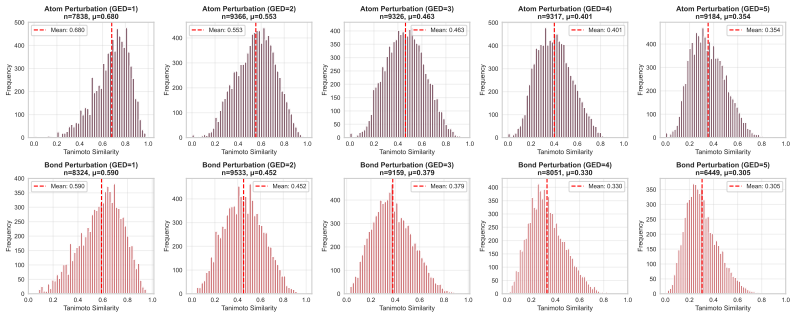
The two distributions are highly consistent: carbon and oxygen, which together account for over 90% of all atoms in the raw data, remain the dominant elements after perturbation, with only a marginal −3.8% shift in carbon frequency. Other common organic atoms (N, S, P, Cl, F) see small absolute increases 12 Dataset Total Samples Atom-only PerturbationsBon...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.