CAPED: Context-Aware Privacy Exposure Defense for Mobile GUI Agents
Pith reviewed 2026-06-27 08:58 UTC · model grok-4.3
The pith
CAPED reduces incidental privacy leakage in mobile GUI agent screenshots from 0.766 to 0.268 by selectively exposing only task-relevant UI content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
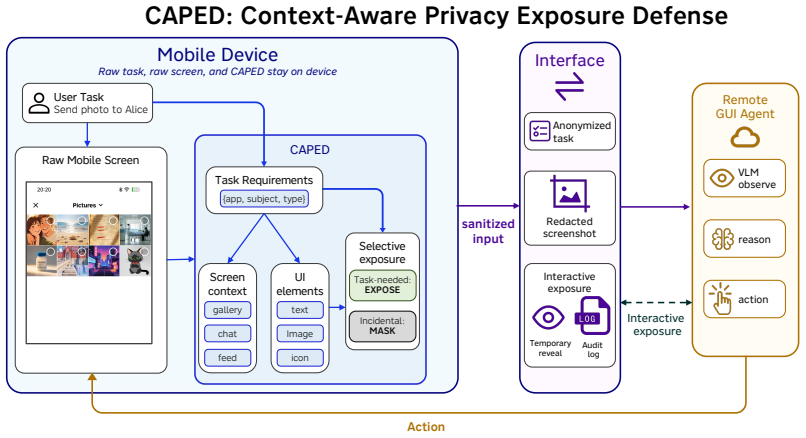
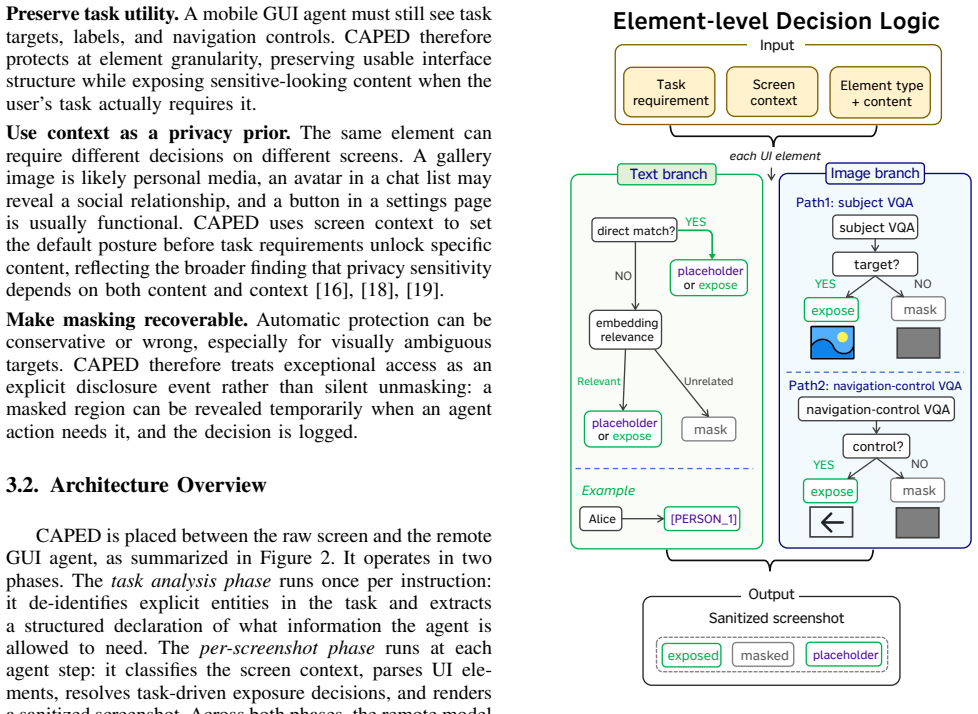
CAPED is a context-aware pre-upload exposure control layer that extracts task requirements from the user request, uses screen context as a privacy prior, parses visible UI elements, and selectively exposes only the content required for the current task while masking incidental private content. In controlled evaluation on AndroidWorld, full CAPED lowers success-conditioned weighted seeded leakage from 0.766 on raw screenshots to 0.268 while keeping high task utility; a wider AndroidWorld run shows a remaining prototype-level utility cost but confirms that task-driven selective exposure can reduce incidental visual leakage before screenshots leave the device.
What carries the argument
The context-aware pre-upload exposure control layer that parses UI elements against extracted task requirements and a screen-derived privacy prior to decide per-element exposure.
If this is right
- Task-conditioned masking can be applied before any remote multimodal model sees the screenshot.
- Existing text anonymization and generic masking approaches leave measurable incidental leakage that selective exposure reduces.
- Privacy utility trade-offs can be measured at the trajectory level using seeded private elements.
- The same selective-exposure logic can be re-used across different remote GUI agents without retraining them.
Where Pith is reading between the lines
- Phone-side filtering layers could become a standard sandbox component for any visual agent that receives live screenshots.
- If the task-extraction step can be made more robust, the same approach might extend to voice or text-only agents that request screen captures.
- Regulators interested in data-minimization rules for AI agents could point to selective exposure as one concrete technical mechanism.
- The seeded-leakage measurement instrument itself could be reused to compare future privacy layers on the same 28-task suite.
Load-bearing premise
The system can reliably extract task requirements from the user request and treat screen context as an accurate prior for distinguishing incidental private content from content the agent must see.
What would settle it
A test set of tasks in which the agent needs a private element that CAPED has classified as incidental, causing either a sharp rise in measured leakage or a measurable drop in task success rate.
Figures


read the original abstract
Screenshot-based mobile GUI agents can operate ordinary smartphone apps through the same visual interface as a human user, but this capability also turns every screen observation into a privacy boundary. During normal task execution, screenshots may expose contacts, messages, photos, files, recommendations, health cues, and other sensitive context that is unrelated to the user's request. We call this problem incidental visual privacy exposure. It is difficult to address with existing defenses: text anonymization misses many visual and inferential cues, while generic privacy masking can remove the evidence and controls that a GUI agent needs to complete the task. This paper presents CAPED, a context-aware pre-upload exposure control layer for mobile GUI agents. CAPED is designed as a phone-side protection layer: before screenshots are released to a remote multimodal agent, it extracts task requirements, uses screen context as a privacy prior, parses visible UI elements, and selectively exposes only content needed for the current task while masking incidental private content. We evaluate CAPED on AndroidWorld for broad task utility and with a controlled 28-task seeded privacy evaluation used as a measurement instrument for trajectory-level incidental leakage. In this seeded evaluation, Full CAPED reduces success-conditioned weighted seeded leakage from 0.766 under raw screenshots to 0.268 while preserving high task utility. A broader AndroidWorld run shows a remaining prototype-level utility cost, but the results show that task-driven selective exposure can reduce incidental visual leakage before screenshots are released to a remote GUI agent.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents CAPED, a phone-side context-aware pre-upload layer for mobile GUI agents. It extracts task requirements from the user request, uses screen context as a privacy prior to parse visible UI elements, and selectively exposes only task-necessary content while masking incidental private information before screenshots are sent to a remote multimodal agent. On a controlled 28-task seeded privacy evaluation instrument, full CAPED reduces success-conditioned weighted seeded leakage from 0.766 (raw screenshots) to 0.268 while preserving high task utility; a broader AndroidWorld run shows remaining prototype-level utility cost.
Significance. If the task extraction and incidental/necessary classification steps prove reliable, CAPED offers a targeted defense against incidental visual privacy exposure in screenshot-based GUI agents that existing text anonymization or generic masking approaches do not address. The empirical leakage reduction is substantial and the task-driven selective exposure idea is a clear contribution, but the absence of separate validation metrics for the core inference components weakens the ability to attribute the result to reliable context-aware control.
major comments (3)
- [Evaluation] Evaluation section: the headline leakage reduction (0.766 → 0.268) and utility claims rest on the unvalidated accuracy of task-requirement extraction and incidental/necessary UI-element classification; the manuscript supplies no precision/recall, error analysis, or human-agreement numbers for these steps, so it is impossible to determine whether the measured drop reflects reliable selective masking or artifacts of over-/under-masking.
- [Seeded privacy evaluation] Seeded privacy evaluation: the construction of the 28-task seeded instrument (task selection, seeding procedure, definition of success-conditioned weighted seeded leakage) is not described, preventing assessment of whether the measurement instrument validly isolates incidental leakage independent of the agent's own inference quality.
- [AndroidWorld utility run] AndroidWorld utility run: the reported prototype-level utility cost is presented without accompanying details on how task-extraction accuracy or classification errors affect task completion rates, leaving open the possibility that utility preservation is overstated or contingent on the same unmeasured inference quality.
minor comments (2)
- The pipeline diagram or pseudocode for the extraction–classification–masking sequence would improve clarity of the system architecture.
- Results tables would benefit from explicit error bars or confidence intervals on the reported leakage and utility figures.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation methodology. We address each major comment below and will revise the manuscript to provide the requested clarifications and additional details.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the headline leakage reduction (0.766 → 0.268) and utility claims rest on the unvalidated accuracy of task-requirement extraction and incidental/necessary UI-element classification; the manuscript supplies no precision/recall, error analysis, or human-agreement numbers for these steps, so it is impossible to determine whether the measured drop reflects reliable selective masking or artifacts of over-/under-masking.
Authors: We acknowledge that the current manuscript does not report separate precision/recall, error analysis, or inter-annotator agreement metrics for the task-requirement extraction and incidental/necessary classification components. The primary results focus on end-to-end leakage reduction and utility under the seeded evaluation. In the revision we will add an appendix containing these metrics, computed via manual annotation of the 28 tasks by two independent annotators, to better support attribution of the observed leakage drop to the context-aware mechanism. revision: yes
-
Referee: [Seeded privacy evaluation] Seeded privacy evaluation: the construction of the 28-task seeded instrument (task selection, seeding procedure, definition of success-conditioned weighted seeded leakage) is not described, preventing assessment of whether the measurement instrument validly isolates incidental leakage independent of the agent's own inference quality.
Authors: The referee is correct that the manuscript does not describe the construction of the 28-task seeded privacy evaluation instrument in sufficient detail. We will expand the evaluation section in the revision to include the task selection criteria from AndroidWorld, the procedure used to seed private information into the tasks, and the exact definition and weighting formula for the success-conditioned weighted seeded leakage metric. This will enable readers to evaluate the instrument's validity independently. revision: yes
-
Referee: [AndroidWorld utility run] AndroidWorld utility run: the reported prototype-level utility cost is presented without accompanying details on how task-extraction accuracy or classification errors affect task completion rates, leaving open the possibility that utility preservation is overstated or contingent on the same unmeasured inference quality.
Authors: We agree that the manuscript lacks a breakdown of how extraction or classification errors influence task completion rates in the broader AndroidWorld evaluation. In the revision we will add a qualitative error analysis section discussing observed failure modes attributable to these components, along with any quantitative counts of affected tasks. A full quantitative ablation of error propagation would require new experiments beyond the current prototype results. revision: partial
Circularity Check
No circularity; purely empirical system evaluation
full rationale
The paper presents CAPED as an implemented phone-side filtering layer whose headline result (success-conditioned weighted seeded leakage dropping from 0.766 to 0.268) is reported as a direct experimental measurement on AndroidWorld and a 28-task seeded instrument. No equations, fitted parameters, self-citations, or derivation steps appear in the supplied text; the pipeline of task extraction and incidental/necessary classification is described at the system level but is not claimed to be derived from prior results or by construction. The evaluation therefore stands as an independent empirical claim rather than a reduction to its own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Task requirements can be extracted accurately from user requests
- domain assumption Screen context serves as a reliable prior for identifying private UI elements
Reference graph
Works this paper leans on
-
[1]
AppAgent: Multimodal agents as smartphone users,
C. Zhang, Z. Yang, J. Liu, Y . Han, X. Chen, Z. Huang, B. Fu, and G. Yu, “AppAgent: Multimodal agents as smartphone users,” 2023. [Online]. Available: https://arxiv.org/abs/2312.13771
Pith/arXiv arXiv 2023
-
[2]
Mobile-Agent: Autonomous multi-modal mobile device agent with visual perception,
J. Wang, H. Xu, J. Ye, M. Yan, W. Shen, J. Zhang, F. Huang, and J. Sang, “Mobile-Agent: Autonomous multi-modal mobile device agent with visual perception,” 2024. [Online]. Available: https://arxiv.org/abs/2401.16158
Pith/arXiv arXiv 2024
-
[3]
Mobile-Agent-v2: Mobile device operation assistant with effective navigation via multi-agent collaboration,
J. Wang, H. Xu, H. Jia, X. Zhang, M. Yan, W. Shen, J. Zhang, F. Huang, and J. Sang, “Mobile-Agent-v2: Mobile device operation assistant with effective navigation via multi-agent collaboration,” in Advances in Neural Information Processing Systems, 2024. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/2024/hash/ 0520537ba799d375b8ff55...
2024
-
[4]
UI-TARS: Pioneering automated GUI interaction with native agents,
Y . Qin, Y . Ye, J. Fang, H. Wang, S. Liang, S. Tian, J. Zhang, J. Li, Y . Li, S. Huang, W. Zhong, K. Li, J. Yang, Y . Miao, W. Lin, L. Liu, X. Jiang, Q. Ma, J. Li, X. Xiao, K. Cai, C. Li, Y . Zheng, C. Jin, C. Li, X. Zhou, M. Wang, H. Chen, Z. Li, H. Yang, H. Liu, F. Lin, T. Peng, X. Liu, and G. Shi, “UI-TARS: Pioneering automated GUI interaction with na...
Pith/arXiv arXiv 2025
-
[5]
Mobile-agent-v3: Fundamental agents for gui automation,
J. Ye, X. Zhang, H. Xu, H. Liu, J. Wang, Z. Zhu, Z. Zheng, F. Gao, J. Cao, Z. Lu, J. Liao, Q. Zheng, F. Huang, J. Zhou, and M. Yan, “Mobile-agent-v3: Fundamental agents for gui automation,” 2025. [Online]. Available: https://arxiv.org/abs/2508.15144
Pith/arXiv arXiv 2025
-
[6]
AndroidWorld: A dynamic benchmarking environment for autonomous agents,
C. Rawles, S. Clinckemaillie, Y . Chang, J. Waltz, G. Lau, M. Fair, A. Li, W. Bishop, W. Li, F. Campbell-Ajala, D. Toyama, R. Berry, D. Tyamagundlu, T. Lillicrap, and O. Riva, “AndroidWorld: A dynamic benchmarking environment for autonomous agents,” inThe Thirteenth International Conference on Learning Representations, 2025. [Online]. Available: https://o...
2025
-
[7]
A3: Android agent arena for mobile GUI agents with essential-state procedural evaluation,
Y . Chai, S. Tang, H. Xiao, W. Lin, H. Li, J. Zhang, L. Liu, P. Zhao, G. Liu, G. Wang, S. Ren, R. Han, H. Zhang, S. Huang, and H. Li, “A3: Android agent arena for mobile GUI agents with essential-state procedural evaluation,” 2025. [Online]. Available: https://arxiv.org/abs/2501.01149
arXiv 2025
-
[8]
Chatgpt agent,
“Chatgpt agent,” [Online; accessed 2026-05-14]. [Online]. Available: https://chatgpt.com/features/agent/
2026
-
[9]
Computer use tool - claude api docs,
“Computer use tool - claude api docs,” [Online; accessed 2026-05-14]. [Online]. Available: https://platform.claude.com/docs/ en/agents-and-tools/tool-use/computer-use-tool
2026
-
[10]
Droidrun: The first native mobile agent,
Droidrun, “Droidrun: The first native mobile agent,” 2025, [Online; accessed 2026-05-15]. [Online]. Available: https://droidrun.ai/
2025
-
[11]
Browser use: Open-source browser automation for ai agents,
Browser Use, “Browser use: Open-source browser automation for ai agents,” 2025, [Online; accessed 2026-05-15]. [Online]. Available: https://browser-use.com/
2025
-
[12]
Browser operator,
Manus, “Browser operator,” 2025, [Online; accessed 2026-05-15]. [Online]. Available: https://manus.im/docs/features/browser-operator
2025
-
[13]
Guiguard: Toward a general framework for privacy-preserving gui agents,
Y . Wang, Z. Zhang, W. Zhou, W. Zhang, J. Zhang, Q. Zhu, Y . Shi, S. Zheng, and J. He, “Guiguard: Toward a general framework for privacy-preserving gui agents,”arXiv preprint arXiv:2601.18842, 2026
Pith/arXiv arXiv 2026
-
[14]
Webpii: Benchmarking visual pii detection for computer- use agents,
N. Zhao, “Webpii: Benchmarking visual pii detection for computer- use agents,”arXiv preprint arXiv:2603.17357, 2026
arXiv 2026
-
[15]
Agentdam: Privacy leakage evaluation for autonomous web agents,
A. Zharmagambetov, C. Guo, I. Evtimov, M. Pavlova, R. Salakhut- dinov, and K. Chaudhuri, “Agentdam: Privacy leakage evaluation for autonomous web agents,”Advances in Neural Information Processing Systems, vol. 38, 2026
2026
-
[16]
CAPID: Context-aware PII detection for question-answering systems,
M. Ponomarenko, S. Abedini, M. Shafieinejad, D. B. Emerson, S. Mohapatra, and X. He, “CAPID: Context-aware PII detection for question-answering systems,” 2026. [Online]. Available: https: //arxiv.org/abs/2602.10074
arXiv 2026
-
[17]
Anonymization-enhanced privacy protection for mobile gui agents: Available but invisible,
L. Zhao, Z. Zou, S. Li, and Z. Liu, “Anonymization-enhanced privacy protection for mobile gui agents: Available but invisible,” 2026
2026
-
[18]
Towards a visual privacy advisor: Understanding and predicting privacy risks in images,
T. Orekondy, B. Schiele, and M. Fritz, “Towards a visual privacy advisor: Understanding and predicting privacy risks in images,” in Proceedings of the IEEE International Conference on Computer Vision, 2017
2017
-
[19]
PrivacyAlert: A dataset for image privacy prediction,
C. Zhao, J. Mangat, S. Koujalgi, A. Squicciarini, and C. Caragea, “PrivacyAlert: A dataset for image privacy prediction,”Proceedings of the International AAAI Conference on Web and Social Media, vol. 16, pp. 1352–1361, May 2022. [Online]. Available: http://dx.doi.org/10.1609/icwsm.v16i1.19387
-
[20]
Private attribute inference from images with vision-language models,
B. T ¨omekc ¸e, M. Vero, R. Staab, and M. Vechev, “Private attribute inference from images with vision-language models,” 2024. [Online]. Available: https://arxiv.org/abs/2404.10618
arXiv 2024
-
[21]
Multi- PA: A multi-perspective benchmark on privacy assessment for large vision-language models,
J. Zhang, X. Cao, Z. Han, S. Shan, and X. Chen, “Multi- PA: A multi-perspective benchmark on privacy assessment for large vision-language models,” 2024. [Online]. Available: https: //arxiv.org/abs/2412.19496
arXiv 2024
-
[22]
Connecting pixels to privacy and utility: Automatic redaction of private information in images,
T. Orekondy, M. Fritz, and B. Schiele, “Connecting pixels to privacy and utility: Automatic redaction of private information in images,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 8466–8475. [Online]. Available: https://arxiv.org/abs/1712.01066
Pith/arXiv arXiv 2018
-
[23]
Visual content privacy protection: A survey,
R. Zhao, Y . Zhang, T. Wang, W. Wen, Y . Xiang, and X. Cao, “Visual content privacy protection: A survey,” 2023. [Online]. Available: https://arxiv.org/abs/2303.16552
arXiv 2023
-
[24]
SeeClick: Harnessing GUI grounding for advanced visual GUI agents,
K. Cheng, Q. Sun, Y . Chu, F. Xu, Y . Li, J. Zhang, and Z. Wu, “SeeClick: Harnessing GUI grounding for advanced visual GUI agents,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024. [Online]. Available: https://aclanthology.org/2024.acl-long.505/
2024
-
[25]
W. Luo, T. Lu, Q. Zhang, X. Liu, B. Hu, Y . Zhao, J. Zhao, S. Gao, P. McDaniel, Z. Xianget al., “Doxing via the lens: Revealing location-related privacy leakage on multi-modal large reasoning mod- els,”arXiv preprint arXiv:2504.19373, 2025
arXiv 2025
-
[26]
Eia: Environmental injection attack on generalist web agents for privacy leakage,
Z. Liao, L. Mo, C. Xu, M. Kang, J. Zhang, C. Xiao, Y . Tian, B. Li, and H. Sun, “Eia: Environmental injection attack on generalist web agents for privacy leakage,” inInternational Conference on Learning Representations, vol. 2025, 2025, pp. 66 972–67 003
2025
-
[27]
Unveiling privacy risks in llm agent memory,
B. Wang, W. He, S. Zeng, Z. Xiang, Y . Xing, J. Tang, and P. He, “Unveiling privacy risks in llm agent memory,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), 2025, pp. 25 241–25 260
2025
-
[28]
MLA-Trust: Benchmarking trustworthiness of multimodal LLM agents in GUI environments,
X. Yang, J. Chen, J. Luo, Z. Fang, Y . Dong, H. Su, and J. Zhu, “MLA-Trust: Benchmarking trustworthiness of multimodal LLM agents in GUI environments,” 2025. [Online]. Available: https://arxiv.org/abs/2506.01616
arXiv 2025
-
[29]
Y . Zhao, D. Zheng, K. Huang, Y . Wei, Z. Yang, and L. Zhou, “MaskClaw: Edge-side personalized privacy arbitration for GUI agents with behavior-driven skill evolution,” arXiv preprint arXiv:2605.28646, 2026. [Online]. Available: https://arxiv.org/abs/2605.28646
Pith/arXiv arXiv 2026
-
[30]
Pp-ocrv3: More attempts for the improvement of ultra lightweight ocr system,
C. Li, W. Liu, R. Guo, X. Yin, K. Jiang, Y . Du, Y . Du, L. Zhu, B. Lai, X. Hu, D. Yu, and Y . Ma, “Pp-ocrv3: More attempts for the improvement of ultra lightweight ocr system,”arXiv preprint arXiv:2206.03001, 2022
arXiv 2022
-
[31]
M. Xie, S. Feng, Z. Xing, J. Chen, and C. Chen, “Uied: a hybrid tool for gui element detection,” inProceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the F oundations of Software Engineering, ser. ESEC/FSE 2020. New York, NY , USA: Association for Computing Machinery, 2020, pp. 1655–1659. [Online]. Avail...
-
[32]
OpenAI API models,
OpenAI, “OpenAI API models,” [Online; accessed 2026-06-10]. [Online]. Available: https://platform.openai.com/docs/models
2026
-
[33]
Mobile-Agent-E: Self-evolving mobile assistant for complex tasks,
Z. Wang, H. Xu, J. Wang, X. Zhang, M. Yan, J. Zhang, F. Huang, and H. Ji, “Mobile-Agent-E: Self-evolving mobile assistant for complex tasks,” 2025. [Online]. Available: https://arxiv.org/abs/2501.11733
arXiv 2025
-
[34]
AppVLM: A lightweight vision language model for online app control,
G. Papoudakis, T. Coste, Z. Wu, J. Hao, J. Wang, and K. Shao, “AppVLM: A lightweight vision language model for online app control,” 2025. [Online]. Available: https://arxiv.org/abs/2502.06395
arXiv 2025
-
[35]
On the effects of data scale on UI control agents,
W. Li, W. Bishop, A. Li, C. Rawles, F. Campbell-Ajala, D. Tyamagundlu, and O. Riva, “On the effects of data scale on UI control agents,” 2024. [Online]. Available: https://arxiv.org/abs/2406. 03679
2024
-
[36]
Caution for the environment: Multimodal llm agents are susceptible to environmental distractions,
X. Ma, Y . Wang, Y . Yao, T. Yuan, A. Zhang, Z. Zhang, and H. Zhao, “Caution for the environment: Multimodal llm agents are susceptible to environmental distractions,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), 2025, pp. 22 324–22 339
2025
-
[37]
Simple prompt injection attacks can leak personal data observed by LLM agents during task execution,
M. Alizadeh, Z. Samei, D. Stetsenko, and F. Gilardi, “Simple prompt injection attacks can leak personal data observed by LLM agents during task execution,” 2025. [Online]. Available: https://arxiv.org/abs/2506.01055
arXiv 2025
-
[38]
Mind the third eye! benchmarking privacy awareness in mllm-powered smartphone agents,
Z. Lin, J. Li, S. Pan, Y . Shi, Y . Yao, and D. Xu, “Mind the third eye! benchmarking privacy awareness in mllm-powered smartphone agents,” 2025
2025
-
[39]
PrivScope: Task-scoped disclosure control for hybrid agentic systems,
S. R. Seeam, Z. Li, Z. Yu, Y . Chen, and Y . Hu, “PrivScope: Task-scoped disclosure control for hybrid agentic systems,”arXiv preprint arXiv:2605.16630, 2026. [Online]. Available: https://arxiv. org/abs/2605.16630
Pith/arXiv arXiv 2026
-
[40]
PRISM-XR: Empowering privacy- aware XR collaboration with multimodal large language models,
J. Chen, M. Zhu, and B. Li, “PRISM-XR: Empowering privacy- aware XR collaboration with multimodal large language models,” in 2026 IEEE Conference on Virtual Reality and 3D User Interfaces (VR). IEEE, Mar. 2026, pp. 486–496. [Online]. Available: http://dx.doi.org/10.1109/VR67842.2026.00069
-
[41]
OmniParser for pure vision based GUI agent,
Y . Lu, J. Yang, Y . Shen, and A. Awadallah, “OmniParser for pure vision based GUI agent,” 2024. [Online]. Available: https://arxiv.org/abs/2408.00203
arXiv 2024
-
[42]
mplug/gui-owl-7b - hugging face,
“mplug/gui-owl-7b - hugging face,” 9 2025, [Online; accessed 2026-05-14]. [Online]. Available: https://huggingface.co/mPLUG/ GUI-Owl-7B
2025
-
[43]
mplug/gui-owl-32b - hugging face,
“mplug/gui-owl-32b - hugging face,” 9 2025, [Online; accessed 2026-05-15]. [Online]. Available: https://huggingface.co/mPLUG/ GUI-Owl-32B
2025
-
[44]
Technical statement from doubao mobile assistant: protected content such as banking keyboards cannot be screenshotted,
Doubao Mobile Assistant, “Technical statement from doubao mobile assistant: protected content such as banking keyboards cannot be screenshotted,” 12 2025, [Online; accessed 2026- 05-15]. Original title in Chinese. [Online]. Available: https: //mp.weixin.qq.com/s/QuLEnFlKK6OAAvunHFmgOA
2025
-
[45]
Qwen/qwen3.5-0.8b - hugging face,
“Qwen/qwen3.5-0.8b - hugging face,” 3 2026, [Online; accessed 2026-05-14]. [Online]. Available: https://huggingface.co/Qwen/ Qwen3.5-0.8B
2026
-
[46]
Qwen3.5: Towards native multimodal agents,
Qwen Team, “Qwen3.5: Towards native multimodal agents,” February 2026. [Online]. Available: https://qwen.ai/blog?id=qwen3.5
2026
-
[47]
google/embeddinggemma-300m - hugging face,
“google/embeddinggemma-300m - hugging face,” 3 2026, [Online; accessed 2026-05-14]. [Online]. Available: https://huggingface.co/ google/embeddinggemma-300m
2026
-
[48]
Embeddinggemma: Powerful and lightweight text representations,
H. Schechter Vera, S. Dua, B. Zhang, D. Salz, R. Mullins, S. Raghuram Panyam, S. Smoot, I. Naim, J. Zou, F. Chen, D. Cer, A. Lisak, M. Choi, L. Gonzalez, O. Sanseviero, G. Cameron, I. Ballantyne, K. Black, K. Chen, W. Wang, Z. Li, G. Martins, J. Lee, M. Sherwood, J. Ji, R. Wu, J. Zheng, J. Singh, A. Sharma, D. Sreepat, A. Jain, A. Elarabawy, A. Co, A. Dou...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.