One Demonstration Is Enough for Real-World Robotic Reinforcement Learning
Pith reviewed 2026-07-03 12:36 UTC · model grok-4.3
The pith
AutoSERL trains effective real-world robot policies from one demonstration by automating all human intervention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
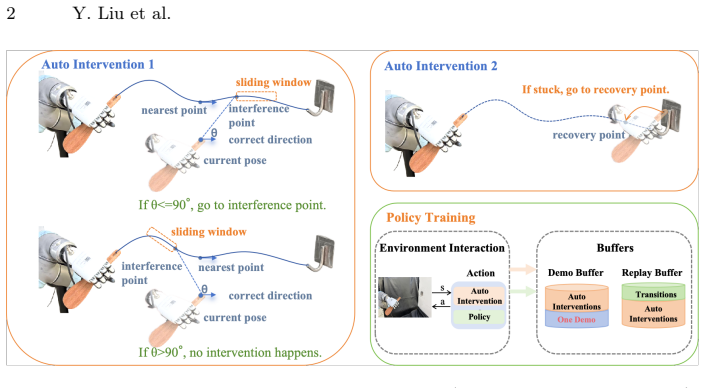
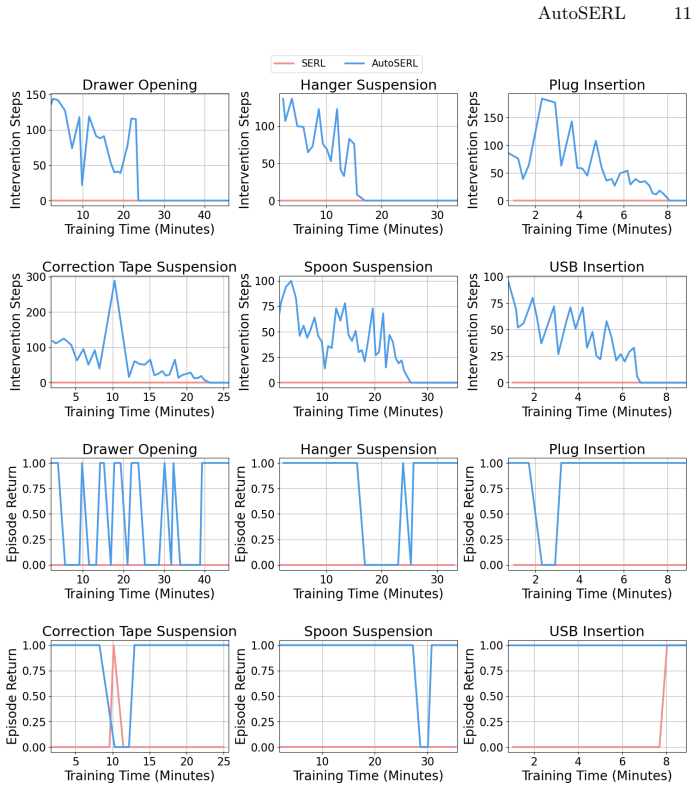
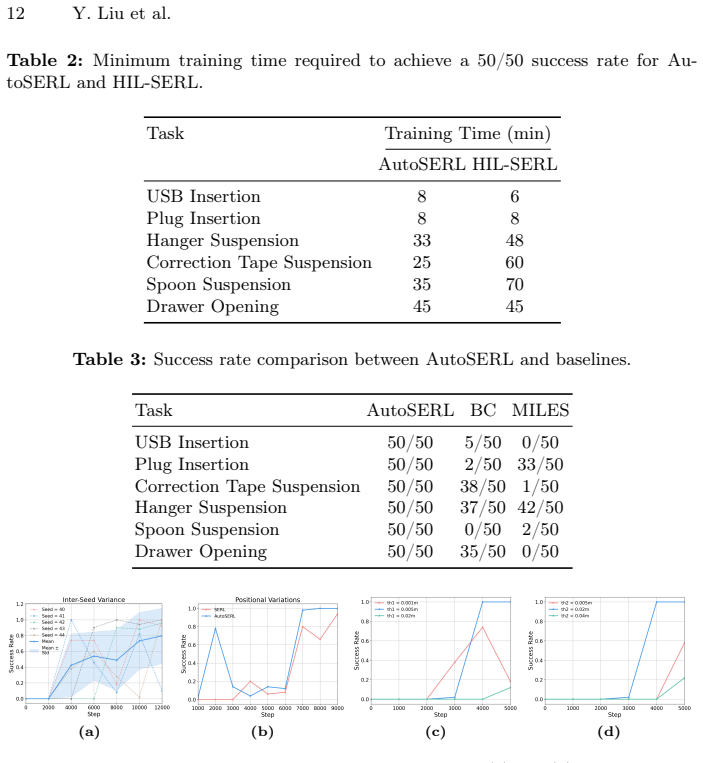
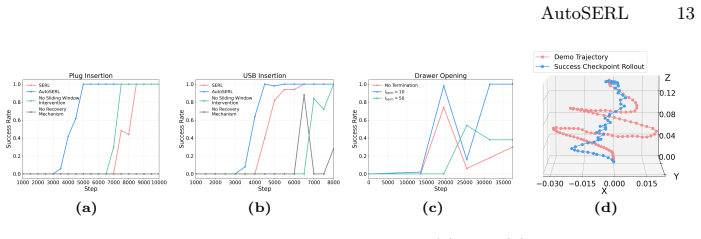
AutoSERL automates intervention in real-world robot RL from a single demonstration by combining a sliding window intervention mechanism that continuously steers exploration away from local optima, a safety recovery mechanism that returns the robot to predefined trajectory points after detected failures, and an intervention termination criterion that disables guidance once the policy completes the task independently. On six contact-intensive manipulation tasks the method reaches 100 percent success on insertion problems, exceeds SERL initialized with twenty demonstrations, behavior cloning, and a dedicated one-shot imitation baseline, and matches human-in-the-loop SERL while improving robustn
What carries the argument
The AutoSERL framework, whose three mechanisms (sliding-window guidance, recovery-point safety correction, and automatic termination) together convert one demonstration into continuous automated supervision until the policy no longer needs it.
If this is right
- Policies reach 100 percent success on insertion tasks using only one demonstration.
- Performance exceeds methods that start with twenty demonstrations or rely on behavior cloning.
- Robustness to positional variations improves compared with the listed baselines.
- Results match those of continuous human-in-the-loop training without requiring the human during learning.
Where Pith is reading between the lines
- The approach lowers the barrier to deploying RL on new robot hardware by reducing both demonstration volume and live supervision.
- If recovery points can be generated automatically rather than supplied by hand, the method would extend to a wider set of tasks without additional engineering.
- The termination criterion may allow the same framework to scale to longer-horizon sequences once the policy stabilizes on the initial sub-tasks.
Load-bearing premise
Predefined trajectory recovery points must be supplied for each task so that the safety mechanism can correct failures without introducing hidden task-specific engineering.
What would settle it
Measure success rates on the same insertion tasks after removing or randomly perturbing the predefined recovery points; a sharp drop would falsify the claim that one demonstration plus the described automation is sufficient.
Figures




read the original abstract
Learning effective robot control policies on physical hardware is challenging due to costly data collection and the difficulty of reward specification. Prior work has incorporated demonstrations into reinforcement learning (RL), yet existing approaches either require large numbers of demonstrations or depend on continuous human intervention during training. To address these limitations, we present AutoSERL, a framework that leverages a single demonstration to fully automate the intervention process in real-world robot RL. The framework includes three complementary mechanisms to accomplish certain tasks: a sliding window intervention mechanism that continuously guides exploration to prevent local optima and unsafe deviations, a safety recovery mechanism that detects and corrects failure states via predefined trajectory recovery points, and an intervention termination criterion that automatically disables guidance once the policy can independently complete the task, preserving its exploration advantage. We evaluate AutoSERL on six contact-intensive manipulation tasks across two robot platforms, spanning insertion, hanging, and hinge-based tasks. AutoSERL consistently outperforms SERL initialized with 20 demonstrations, behavior cloning, and MILES -- a dedicated one-shot imitation learning baseline -- across all tasks while matching HIL-SERL, achieves 100% success rate on insertion tasks, and demonstrates improved robustness to positional variations, all from a single demonstration. Code and videos are available on our project website: https://autoserl.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents AutoSERL, a framework for automating intervention in real-world robotic RL using only one demonstration. It features a sliding window intervention, safety recovery via predefined trajectory recovery points, and an automatic termination criterion. Evaluations on six tasks across two platforms show outperformance over several baselines and 100% success on insertion tasks.
Significance. Should the central claims regarding full automation from a single demonstration hold, this work could significantly lower the barrier to applying RL on physical robots by minimizing human input. The provision of code and videos is a positive aspect for reproducibility.
major comments (1)
- Abstract: The safety recovery mechanism relies on 'predefined trajectory recovery points' to detect and correct failure states. However, the paper's claim is that it 'fully automate[s] the intervention process' from 'a single demonstration.' The manuscript does not specify how these recovery points are sourced or derived from the single demonstration alone. This is a load-bearing issue for the automation and one-demonstration claims, as manual specification per task would introduce additional human effort not accounted for in the central guarantee.
minor comments (1)
- Abstract: The results are presented without error bars, statistical tests, or implementation details for baselines, which limits assessment of the performance claims.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive comments. We address the single major comment below.
read point-by-point responses
-
Referee: Abstract: The safety recovery mechanism relies on 'predefined trajectory recovery points' to detect and correct failure states. However, the paper's claim is that it 'fully automate[s] the intervention process' from 'a single demonstration.' The manuscript does not specify how these recovery points are sourced or derived from the single demonstration alone. This is a load-bearing issue for the automation and one-demonstration claims, as manual specification per task would introduce additional human effort not accounted for in the central guarantee.
Authors: We agree that the abstract and methods would benefit from greater explicitness on this point to support the central claim. The recovery points are obtained directly from the single demonstration by automatically selecting key states along the demonstrated trajectory that enable return to safe configurations. In the revised manuscript we will update the abstract and the relevant methods description to state this derivation process explicitly, confirming that no per-task manual specification beyond the initial demonstration is required. revision: yes
Circularity Check
No circularity: empirical results rest on external robot benchmarks
full rationale
The paper reports physical-robot success rates and robustness metrics for AutoSERL versus independent baselines (SERL with 20 demonstrations, behavior cloning, MILES, HIL-SERL). No equations, fitted parameters, or derivations appear in the provided text that could reduce the claimed 100% insertion success or outperformance to a quantity defined by the method itself. The safety-recovery mechanism is described at the level of implementation rather than as a mathematical reduction; any cost of supplying recovery points is an empirical assumption, not a self-referential derivation. The evaluation therefore remains self-contained against external hardware benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alshiekh, M., Bloem, R., Ehlers, R., Könighofer, B., Niekum, S., Topcu, U.: Safe reinforcement learning via shielding (2017),https://arxiv.org/abs/1708.08611
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [2]
-
[3]
UniIntervene: Agentic Intervention for Efficient Real-World Reinforcement Learning
Deng, H., Gao, Y., Lin, Y., Liu, H., Wu, Z., Wang, Z.: Uniintervene: Agen- tic intervention for efficient real-world reinforcement learning. arXiv preprint arXiv:2606.12372 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Challenges of Real-World Reinforcement Learning
Dulac-Arnold, G., Mankowitz, D., Hester, T.: Challenges of real-world reinforce- ment learning. arXiv preprint arXiv:1904.12901 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[5]
Fisac, J.F., Akametalu, A.K., Zeilinger, M.N., Kaynama, S., Gillula, J., Tomlin, C.J.: A general safety framework for learning-based control in uncertain robotic systems (2018),https://arxiv.org/abs/1705.01292
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
In: 2012 IEEE International Conference on Robotics and Automation
Gillula, J.H., Tomlin, C.J.: Guaranteed safe online learning via reachability: track- ing a ground target using a quadrotor. In: 2012 IEEE International Conference on Robotics and Automation. pp. 2723–2730 (2012).https://doi.org/10.1109/ ICRA.2012.6225136
- [7]
- [8]
- [9]
-
[10]
Kelly, M., Sidrane, C., Driggs-Campbell, K., Kochenderfer, M.J.: Hg-dagger: In- teractive imitation learning with human experts (2019),https://arxiv.org/abs/ 1810.02890
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[11]
arXiv preprint arXiv:2601.07821 (2026)
Li, H., Lei, K., Zang, S., Hu, K., Liang, Y., An, B., Li, X., Xu, H.: Failure-aware rl: Reliable offline-to-online reinforcement learning with self-recovery for real-world manipulation. arXiv preprint arXiv:2601.07821 (2026)
- [12]
- [13]
-
[14]
In: 2024 IEEE International Conference on Robotics and Automation (ICRA)
Luo,J.,Hu,Z.,Xu,C.,Tan,Y.L.,Berg,J.,Sharma,A.,Schaal,S.,Finn,C.,Gupta, A., Levine, S.: Serl: A software suite for sample-efficient robotic reinforcement learning. In: 2024 IEEE International Conference on Robotics and Automation (ICRA). pp. 16961–16969. IEEE (2024)
2024
-
[15]
Science Robotics10(105), eads5033 (2025)
Luo, J., Xu, C., Wu, J., Levine, S.: Precise and dexterous robotic manipulation via human-in-the-loop reinforcement learning. Science Robotics10(105), eads5033 (2025)
2025
- [16]
-
[17]
Playing Atari with Deep Reinforcement Learning
Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., Riedmiller, M.: Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[18]
In: 2018 IEEE inter- national conference on robotics and automation (ICRA)
Nair, A., McGrew, B., Andrychowicz, M., Zaremba, W., Abbeel, P.: Overcoming exploration in reinforcement learning with demonstrations. In: 2018 IEEE inter- national conference on robotics and automation (ICRA). pp. 6292–6299. IEEE (2018)
2018
- [19]
-
[20]
arXiv preprint arXiv:2410.19693 (2024)
Papagiannis, G., Johns, E.: Miles: Making imitation learning easy with self- supervision. arXiv preprint arXiv:2410.19693 (2024)
-
[21]
Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations
Rajeswaran, A., Kumar, V., Gupta, A., Vezzani, G., Schulman, J., Todorov, E., Levine, S.: Learning complex dexterous manipulation with deep reinforcement learning and demonstrations. arXiv preprint arXiv:1709.10087 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Ross, S., Gordon, G.J., Bagnell, J.A.: A reduction of imitation learning and struc- tured prediction to no-regret online learning (2011),https://arxiv.org/abs/ 1011.0686
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[23]
nature529(7587), 484–489 (2016)
Silver, D., Huang, A., Maddison, C.J., Guez, A., Sifre, L., Van Den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M., et al.: Master- ing the game of go with deep neural networks and tree search. nature529(7587), 484–489 (2016)
2016
- [24]
- [25]
-
[26]
Leveraging Demonstrations for Deep Reinforcement Learning on Robotics Problems with Sparse Rewards
Vecerik, M., Hester, T., Scholz, J., Wang, F., Pietquin, O., Piot, B., Heess, N., Rothörl, T., Lampe, T., Riedmiller, M.: Leveraging demonstrations for deep re- inforcement learning on robotics problems with sparse rewards. arXiv preprint arXiv:1707.08817 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [27]
- [28]
-
[29]
Xu, X., Hou, Y., Xin, C., Liu, Z., Song, S.: Compliant residual dagger: Improving real-world contact-rich manipulation with human corrections (2025),https:// arxiv.org/abs/2506.16685 18 Y. Liu et al. Appendix A Learning Details Our training framework is based on SERL [14]. Following SERL, we maintain bothademobufferandareplaybufferfordatastorage.Thedemobu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.