BOUNDARY_SYNC: Measuring Communication-Induced Representational Coupling in Multi-Agent LLM Systems
Pith reviewed 2026-07-03 17:31 UTC · model grok-4.3
The pith
Text communication between LLM agents causes their outputs to converge toward shared representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
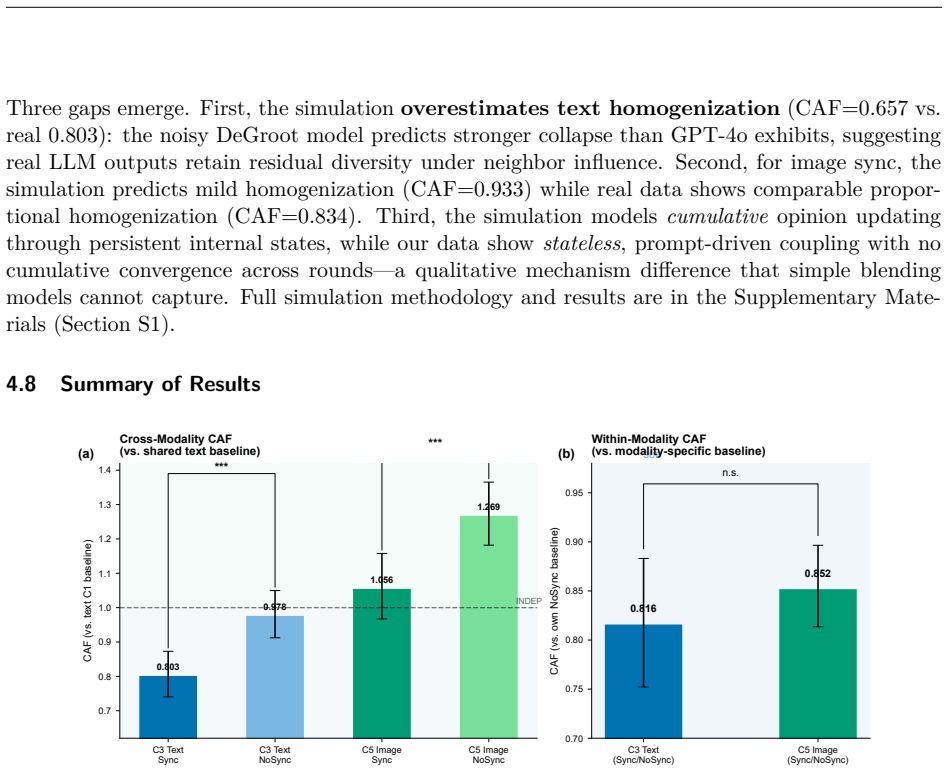
Inter-agent communication induces representational coupling in LLM systems, with text messages producing a Coupling Amplification Factor of 0.803 that signals significant homogenization, as isolated through no-communication ablations and prompt controls in GPT-4o trials.
What carries the argument
The Coupling Amplification Factor (CAF), defined as conditional JSD divided by baseline JSD, which measures the change in output divergence attributable to inter-agent messages.
If this is right
- Multi-agent LLM systems will show reduced output divergence when agents exchange text messages.
- Increasing group size from 3 to 5 agents can shift coupling from diversification to homogenization.
- Coupling arises from prompt context and produces monotonic convergence under continuous consensus.
- Designers can modulate coupling strength at the prompt level without changing model weights.
Where Pith is reading between the lines
- Agent teams may require explicit diversity mechanisms when communication is present to avoid unintended consensus.
- Extreme CAF variation across models implies that coupling strength must be measured per model before deployment.
- The stateless character of the effect suggests that periodic prompt resets could interrupt convergence in long-running systems.
Load-bearing premise
The chosen baselines and JSD computations isolate the causal effect of communication without interference from prompt formatting or model artifacts.
What would settle it
A controlled replication in which agents exchange messages yet the computed CAF equals 1.0 with no statistical difference from the no-communication baseline would falsify the homogenization effect.
Figures
read the original abstract
As large language models (LLMs) are deployed as communicating agents, does inter-agent communication cause outputs to converge? We introduce BOUNDARY_SYNC, a protocol measuring representational coupling via the Coupling Amplification Factor (CAF = JSD_cond / JSD_baseline), where CAF < 1 indicates homogenization and CAF > 1 indicates diversification. In controlled GPT-4o experiments (N=30, ~9,900 API calls), we measure coupling in text and image communication. Key findings: (1) text communication causes significant homogenization (CAF=0.803 [0.740, 0.873], d=1.30, p<0.001), confirmed by no-communication ablation and prompt-perturbation controls; (2) image communication also homogenizes under within-modality baselines (CAF=0.834 [0.811, 0.858]), with comparable proportional effect; (3) group size moderates coupling direction -- K=5 produces homogenization while K=3 yields CAF > 1.0 (point estimates 1.14 and 1.06, CI pending), suggesting a directional shift toward diversification; (4) cross-model replication shows extreme variation (CAF 0.034-0.803), with DeepSeek dominated by format artifacts; (5) coupling is stateless -- driven by prompt context rather than cumulative updating, with continuous consensus producing monotonic convergence. These results establish LLM agent coupling as real, measurable, and controllable at the prompt level, with direct implications for multi-agent system design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the BOUNDARY_SYNC protocol to quantify communication-induced representational coupling in multi-agent LLM systems via the Coupling Amplification Factor (CAF = JSD_cond / JSD_baseline), where CAF < 1 indicates homogenization. In GPT-4o experiments (N=30, ~9,900 API calls), it reports that text communication produces significant homogenization (CAF=0.803 [0.740, 0.873], d=1.30, p<0.001) confirmed by ablations, with comparable effects for image communication, moderation by group size (K=5 homogenizes while K=3 diversifies), extreme cross-model variation, and stateless prompt-driven dynamics.
Significance. If the measurements correctly isolate communication effects, the work supplies a quantitative, statistically reported framework (with CIs, effect sizes, and controls) for assessing and controlling coupling in multi-agent LLM systems, directly relevant to system design. The emphasis on prompt-level controllability and the volume of API calls are strengths.
major comments (1)
- [Abstract] Abstract: The central claim that text communication produces homogenization (CAF=0.803) rests on JSD_cond / JSD_baseline correctly attributing divergence reduction to inter-agent message exchange. The no-communication ablation and prompt-perturbation controls are asserted to rule out confounds, yet it is not shown that the baseline condition holds prompt structure, instruction phrasing, and output formatting identical to the conditional case (e.g., absence of additional tokens, role labels, or message delimiters). Cross-model variation (CAF 0.034–0.803) already indicates format sensitivity, making this isolation step load-bearing for the GPT-4o result.
minor comments (2)
- [Abstract] Abstract: The group-size results report point estimates (1.14 and 1.06) but note 'CI pending'; providing the intervals would strengthen the moderation claim.
- [Abstract] Abstract: The statement that coupling is 'stateless' and 'driven by prompt context' would benefit from explicit comparison of cumulative vs. single-turn conditions to clarify the operational definition.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for identifying a critical point about prompt equivalence. We address the comment below and propose a targeted revision to strengthen the isolation claim.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that text communication produces homogenization (CAF=0.803) rests on JSD_cond / JSD_baseline correctly attributing divergence reduction to inter-agent message exchange. The no-communication ablation and prompt-perturbation controls are asserted to rule out confounds, yet it is not shown that the baseline condition holds prompt structure, instruction phrasing, and output formatting identical to the conditional case (e.g., absence of additional tokens, role labels, or message delimiters). Cross-model variation (CAF 0.034–0.803) already indicates format sensitivity, making this isolation step load-bearing for the GPT-4o result.
Authors: We agree that explicit demonstration of prompt equivalence is essential for attributing effects to communication. The manuscript's Methods section (Experimental Setup and Prompt Templates) specifies that baseline and conditional prompts are identical in instruction phrasing, output formatting, role labels, and token structure; the sole difference is the insertion of inter-agent messages in the conditional condition. The no-communication ablation uses the identical baseline prompt without message tokens, and prompt-perturbation controls explicitly vary delimiters and formatting to test sensitivity. Cross-model variation is presented as model-specific behavior (with DeepSeek dominated by format artifacts), not as evidence against isolation in the GPT-4o runs, which maintained fixed formatting. To make this isolation transparent, we will add a supplementary table with verbatim side-by-side prompt strings for all conditions. revision: yes
Circularity Check
No circularity: CAF is an experimental ratio of independently measured quantities
full rationale
The paper defines CAF explicitly as the ratio JSD_cond / JSD_baseline and reports its value from controlled experiments (N=30, ~9900 API calls) that include no-communication ablations and prompt-perturbation controls. No derivation step reduces the reported CAF values or homogenization claims to fitted parameters, self-referential equations, or self-citations; the central results are direct empirical measurements of divergence under different conditions rather than algebraic identities or renamed inputs. The protocol is therefore self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Jensen-Shannon divergence is an appropriate quantitative measure of representational similarity between LLM outputs
Reference graph
Works this paper leans on
-
[1]
doi: 10.18653/v1/2024.c3nlp-1.2. J. Chen, W. Li, and Y. Zhao. ReConcile: Round-table conference improves reasoning via consensus among diverse LLMs. InProceedings of ACL,
-
[2]
Young-Min Cho, Sharath Chandra Guntuku, and Lyle Ungar
doi: 10.18653/v1/2024.acl-long.381. Young-Min Cho, Sharath Chandra Guntuku, and Lyle Ungar. Herd behavior: Investigating peer influence in LLM-based multi-agent systems.arXiv preprint arXiv:2505.21588,
-
[3]
Guillaume Deffuant, David Neau, Frédéric Amblard, and Gérard Weisbuch
arXiv:2412.00802. Guillaume Deffuant, David Neau, Frédéric Amblard, and Gérard Weisbuch. Mixing beliefs among interacting agents.Advances in Complex Systems, 3(1–4):87–98,
-
[4]
Yilun Du, Shuang Li, Antonio Torralba, Joshua B
doi: 10.1080/01621459.1974.10480137. Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. Improving fac- tuality and reasoning in language models through multiagent debate. InInternational Conference on Machine Learning (ICML),
-
[5]
doi: 10.18564/jasss.3521. Noah E. Friedkin and Eugene C. Johnsen. Social influence and opinions.Journal of Mathematical Sociology, 15(3–4):193–206,
-
[6]
doi: 10.1080/0022250X.1990.9990069. Hossein Hassani, Roozbeh Razavi-Far, Mehrdad Saif, Francisco Chiclana, Ondrej Krejcar, and Enrique Herrera-Viedma. Classical dynamic consensus and opinion dynamics models: A survey of recent trends and methodologies.Information Fusion, 88:22–40,
-
[7]
doi: 10.1016/j.inffus. 2022.07.003. 17 Rainer Hegselmann and Ulrich Krause. Opinion dynamics and bounded confidence: Models, anal- ysis and simulation.Journal of Artificial Societies and Social Simulation, 5(3),
-
[8]
Adit Jain and Vikram Krishnamurthy. Interacting large language model agents: Interpretable models and social learning.arXiv preprint arXiv:2411.01271,
-
[9]
Hsien-Tsung Lin, Pei-Cing Huang, Chan-Tung Ku, Chan Hsu, Pei-Xuan Shieh, and Yihuang Kang. Towards simulating social influence dynamics with LLM-based multi-agents.arXiv preprint arXiv:2507.22467,
-
[10]
Aliakbar Mehdizadeh and Martin Hilbert. When your AI agent succumbs to peer-pressure: Study- ing opinion-change dynamics of LLMs.arXiv preprint arXiv:2510.19107,
-
[11]
doi: 10.18653/v1/2025.blackboxnlp-1.12. arXiv:2512.00047. Joon Sung Park, Joseph C. O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST),
-
[12]
doi: 10.1145/3586183.3606763. Dipkumar Patel. Representational collapse in multi-agent LLM committees: Measurement and diversity-aware consensus.arXiv preprint arXiv:2604.03809,
-
[13]
Maojia Song, Tej Deep Pala, Ruiwen Zhou, Weisheng Jin, Amir Zadeh, Chuan Li, Dorien Herre- mans, and Soujanya Poria. LLMs Can’t Handle Peer Pressure: Crumbling under Multi-Agent Social Interactions (KAIROS Benchmark).arXiv preprint arXiv:2508.18321,
-
[14]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W. White, Doug Burger, and Chi Wang. AutoGen: Enabling next-gen LLM applications via multi-agent conversation.arXiv preprint arXiv:2308.08155,
work page internal anchor Pith review Pith/arXiv arXiv
- [15]
-
[16]
Y. Xiao, R. Ma, and L. Sun. The chameleon’s limit: Investigating persona collapse and homoge- nization in large language models.arXiv preprint arXiv:2604.24698,
work page internal anchor Pith review Pith/arXiv arXiv
- [17]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.