GF-DiT: Scheduling Parallelism for Diffusion Transformer Serving
Pith reviewed 2026-06-27 05:33 UTC · model grok-4.3
The pith
DiT serving systems achieve better performance by dynamically scheduling GPU parallelism for each request instead of fixing it in advance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
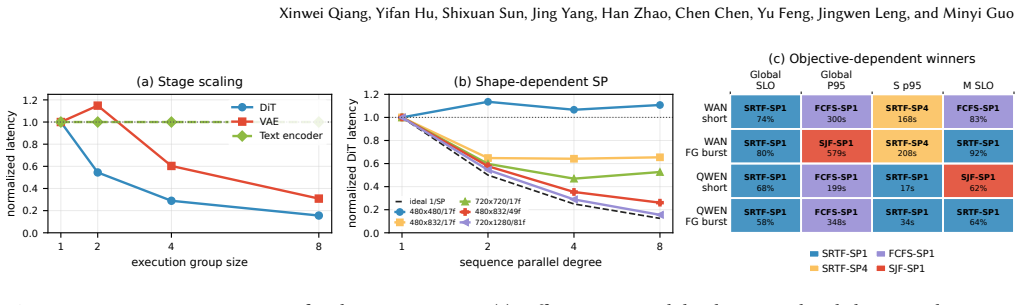
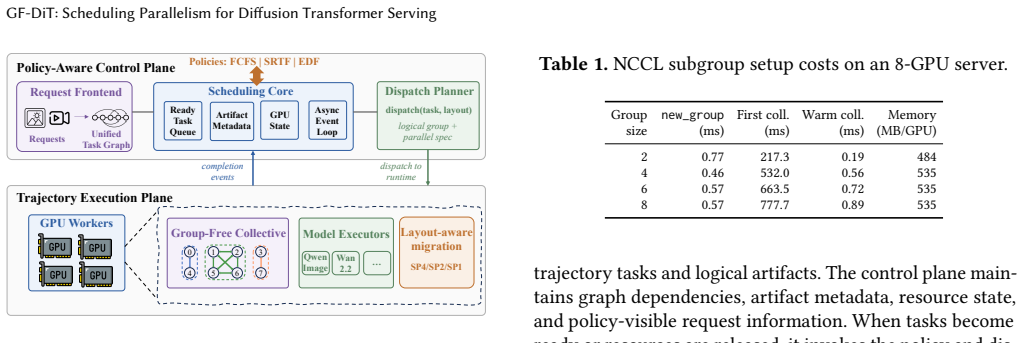
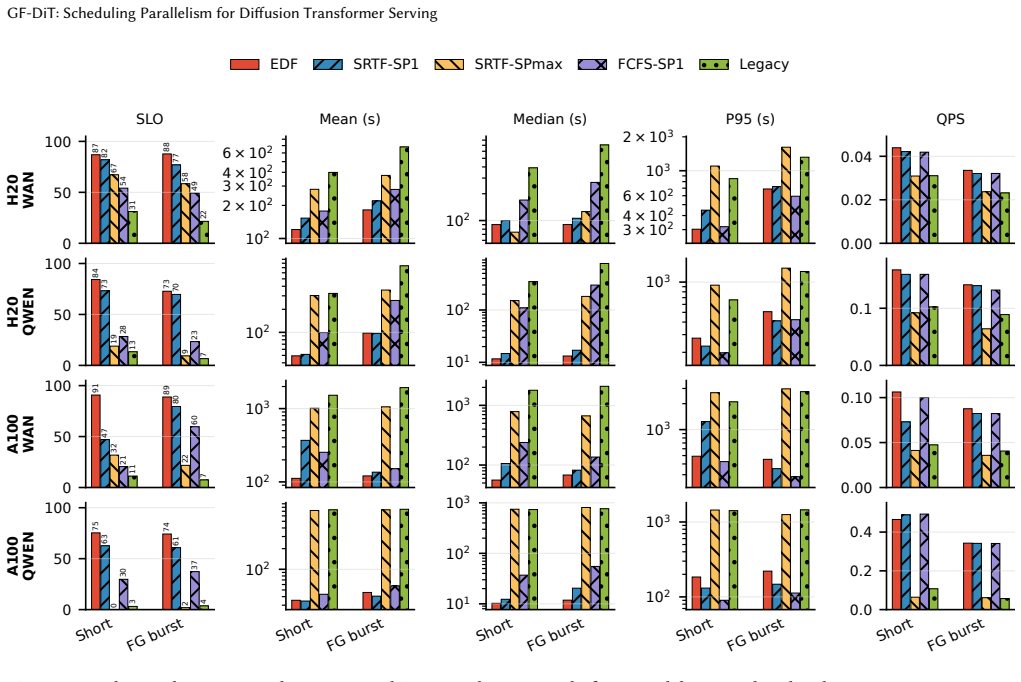
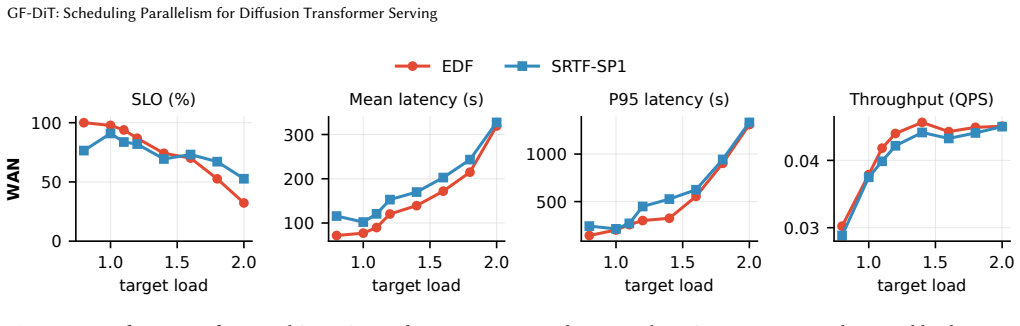
GF-DiT demonstrates that treating GPU parallelism as a schedulable resource, through an asynchronous execution model using trajectory tasks and group-free collectives, enables online adaptation that delivers up to 6.01 times higher throughput and 95 percent lower mean latency than static parallelism approaches.
What carries the argument
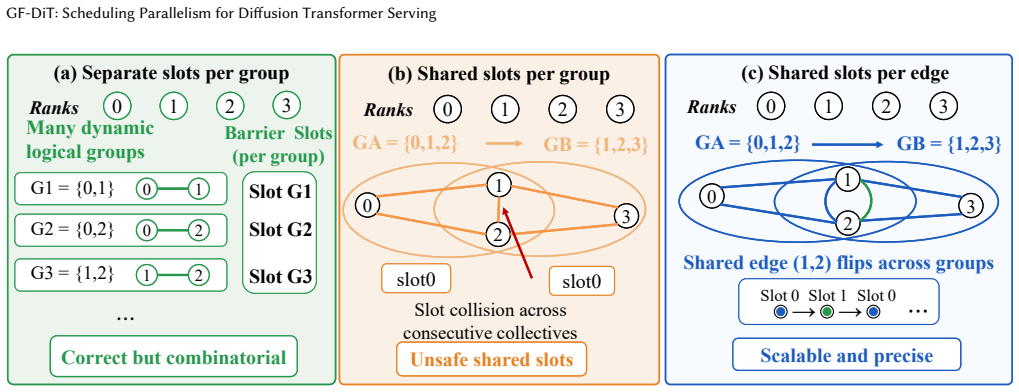
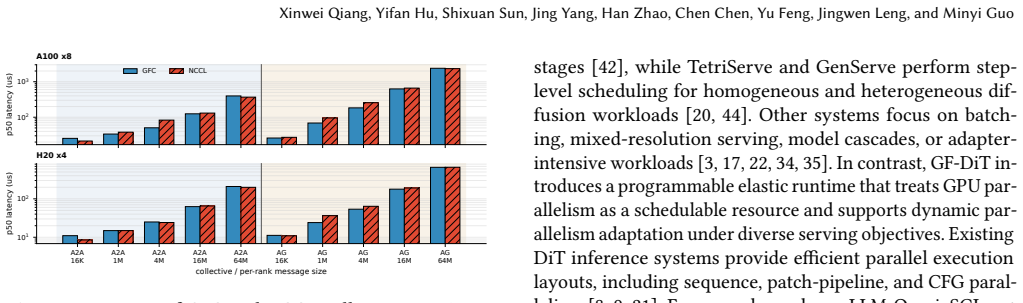
Group-free collectives, which allow low-overhead online formation and reconfiguration of arbitrary GPU execution groups for communication.
If this is right
- Throughput improves by up to 6.01 times compared to fixed-pipeline execution.
- Mean latency reduces by up to 95 percent.
- SLO violation rates drop by up to 90 percent.
- Communication-group setup overhead falls from 778 ms to about 60 microseconds.
Where Pith is reading between the lines
- This approach could extend to serving other models with heterogeneous compute patterns, such as large language models with varying generation lengths.
- Data centers might reduce hardware requirements by using elastic scheduling to handle peak loads without dedicated overprovisioning.
- Future schedulers could incorporate workload prediction to decide when to trigger parallelism changes.
Load-bearing premise
The workloads for diffusion transformers vary enough in their parallelism requirements across requests and stages that dynamic reconfiguration pays off despite any added complexity.
What would settle it
Running the system on a set of requests that all require the same fixed parallelism degree throughout their execution would produce no measurable improvement over static methods.
Figures

read the original abstract
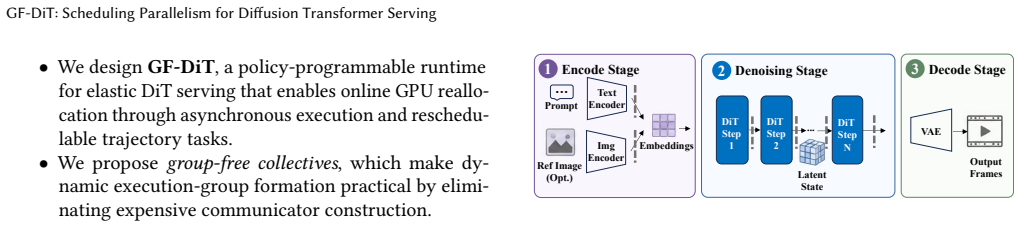
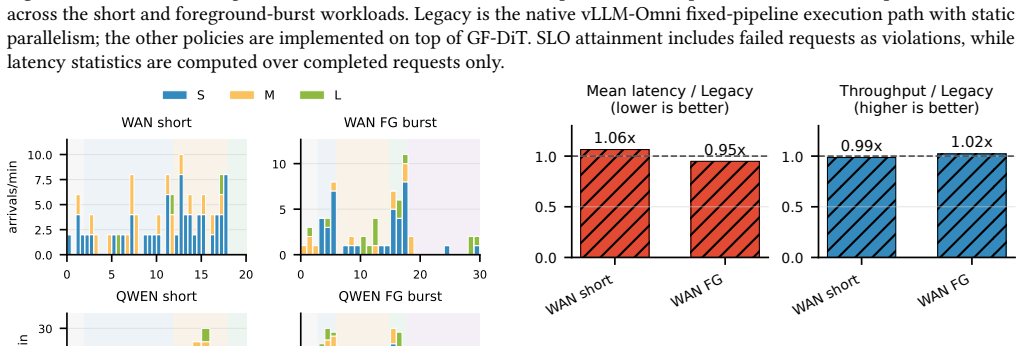
Diffusion Transformers (DiTs) have become the dominant architecture for image and video generation, creating growing demand for efficient DiT serving. Existing systems assign each request a fixed parallel configuration throughout its lifetime. However, DiT workloads exhibit substantial heterogeneity across requests, execution stages, and system conditions, making static parallelism inefficient and often leading to poor GPU utilization and degraded service quality. This paper argues that DiT serving should treat GPU parallelism as a first-class schedulable resource. We present GF-DiT, a policy-programmable runtime for elastic DiT serving that dynamically adapts the parallelism of running requests according to workload demands and service objectives. GF-DiT introduces an asynchronous execution abstraction that decomposes requests into independently schedulable trajectory tasks and enables online GPU reallocation. To make elastic parallelism practical, GF-DiT further proposes group-free collectives, a lightweight communication abstraction that supports low-overhead online formation and reconfiguration of arbitrary execution groups. We implement GF-DiT in vLLM-Omni and evaluate it on representative image and video diffusion workloads. Compared with fixed-pipeline execution with static parallelism, GF-DiT improves throughput by up to 6.01$\times$, reduces mean latency by up to 95%, lowers SLO violation rates by up to 90%, and reduces communication-group setup overhead from 778 ms to approximately 60 $\mu$s.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that DiT serving systems suffer from inefficiency due to static parallelism in the face of workload heterogeneity across requests, stages, and conditions; GF-DiT addresses this by treating GPU parallelism as a schedulable resource via an asynchronous execution abstraction that decomposes requests into independently schedulable trajectory tasks, combined with group-free collectives for low-overhead dynamic group formation, yielding up to 6.01× throughput, 95% lower mean latency, 90% fewer SLO violations, and reconfiguration overhead reduced from 778 ms to ~60 μs versus fixed-pipeline static parallelism.
Significance. If the empirical claims hold after verification of experimental details and dependency handling, the work would offer a practical advance in elastic serving for diffusion models, improving GPU utilization for heterogeneous image/video generation workloads and providing a policy-programmable runtime that could influence future systems designs in this domain.
major comments (2)
- [Abstract] Abstract: The reported performance numbers (6.01× throughput, 95% latency reduction, 90% SLO improvement, 60 μs overhead) are presented without any description of experimental setup, workloads (image/video diffusion), hardware, baselines, number of trials, or error bars; this absence is load-bearing because the central claim rests entirely on these empirical comparisons rather than derivations.
- [Abstract] Abstract (asynchronous execution abstraction): Diffusion denoising forms a strict Markov chain in which the input to step t+1 is the output of step t. The claim that requests can be decomposed into independently schedulable trajectory tasks to enable online GPU reallocation (tensor-parallel degree, pipeline stages) therefore requires an explicit account of how per-request data dependencies are preserved without stalls or extra synchronization at step boundaries; absent this, the 60 μs reconfiguration and 6.01× throughput figures cannot be evaluated.
minor comments (2)
- [Abstract] Abstract: The sentence introducing 'group-free collectives' would benefit from a one-sentence parenthetical gloss on the communication primitive before the performance claims.
- [Abstract] Abstract: 'vLLM-Omni' is mentioned as the implementation vehicle but receives no further characterization; a brief clause on its relation to the base vLLM system would aid readers.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and are prepared to revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported performance numbers (6.01× throughput, 95% latency reduction, 90% SLO improvement, 60 μs overhead) are presented without any description of experimental setup, workloads (image/video diffusion), hardware, baselines, number of trials, or error bars; this absence is load-bearing because the central claim rests entirely on these empirical comparisons rather than derivations.
Authors: We agree that the abstract would be strengthened by a concise reference to the experimental context. In the revised version we will append a single sentence to the abstract summarizing the workloads (representative image and video diffusion models), hardware platform, and static-parallelism baselines. Full methodology, including trial counts and error bars, already appears in the Evaluation section; we will ensure the abstract points readers there explicitly. revision: yes
-
Referee: [Abstract] Abstract (asynchronous execution abstraction): Diffusion denoising forms a strict Markov chain in which the input to step t+1 is the output of step t. The claim that requests can be decomposed into independently schedulable trajectory tasks to enable online GPU reallocation (tensor-parallel degree, pipeline stages) therefore requires an explicit account of how per-request data dependencies are preserved without stalls or extra synchronization at step boundaries; absent this, the 60 μs reconfiguration and 6.01× throughput figures cannot be evaluated.
Authors: The manuscript (Section 3) already supplies the required account: the asynchronous execution abstraction decomposes each request into a chain of trajectory tasks whose data dependencies are tracked explicitly by the scheduler; a task for denoising step t+1 is released only after its predecessor completes, with reallocation and group formation occurring at these natural boundaries. Group-free collectives eliminate the 778 ms setup cost by allowing dynamic group formation without global barriers, keeping per-boundary overhead at ~60 μs. Because the dependency mechanism is described in the body, the abstract numbers are supported by the full text; we will nevertheless add a short clarifying clause to the abstract if the referee prefers the abstract to be self-contained. revision: partial
Circularity Check
No circularity: empirical systems paper with no derivations or fitted predictions
full rationale
The paper introduces a runtime system (GF-DiT) with asynchronous execution abstraction and group-free collectives, evaluated via throughput/latency measurements on image/video workloads. No equations, parameter fits, uniqueness theorems, or self-citation chains appear in the provided text. All performance claims (6.01× throughput, 95% latency reduction, etc.) are presented as direct empirical outcomes from implementation in vLLM-Omni, not as predictions derived from prior fitted values or self-referential definitions. The central claims rest on workload heterogeneity observations and measured reconfiguration overheads, which are externally falsifiable via benchmarks and do not reduce to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption DiT workloads exhibit substantial heterogeneity across requests, execution stages, and system conditions
invented entities (2)
-
group-free collectives
no independent evidence
-
asynchronous execution abstraction
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advanced Micro Devices, Inc. 2026. ROCm Communication Collec- tives Library (RCCL).https://rocm.docs.amd.com/projects/rccl/en/ latest/. Documentation
2026
-
[2]
Gulavani, Alexey Tumanov, and Ramachandran Ramjee
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S. Gulavani, Alexey Tumanov, and Ramachandran Ramjee. 2024. Taming throughput-latency tradeoff in LLM inference with sarathi-serve. InProceedings of the 18th USENIX Conference on Operating Systems Design and Implementation(Santa Clara, CA, USA) (OSDI’24). USENIX Association, ...
2024
-
[3]
Sohaib Ahmad, Qizheng Yang, Haoliang Wang, Ramesh K. Sitara- man, and Hui Guan. 2025. DiffServe: Efficiently Serving Text- to-Image Diffusion Models with Query-Aware Model Scaling. arXiv:2411.15381 [cs.DC]https://arxiv.org/abs/2411.15381
arXiv 2025
-
[4]
Jason Ansel, Edward Yang, Horace He, Natalia Gimelshein, Animesh Jain, Michael Voznesensky, Bin Bao, Peter Bell, David Berard, Evgeni Burovski, Geeta Chauhan, Anjali Chourdia, Will Constable, Alban Desmaison, Zachary DeVito, Elias Ellison, Will Feng, Jiong Gong, Michael Gschwind, Brian Hirsh, Sherlock Huang, Kshiteej Kalam- barkar, Laurent Kirsch, Michael...
-
[5]
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh. 2024. Video generation models as world simulators. (2024).https://openai.com/research/video- generation-models-as-world-simulators
2024
-
[6]
Zixian Cai, Zhengyang Liu, Saeed Maleki, Madanlal Musuvathi, Todd Mytkowicz, Jacob Nelson, and Olli Saarikivi. 2021. Synthesizing opti- mal collective algorithms. InProceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP ’21). ACM, 62–75. doi:10.1145/3437801.3441620
-
[7]
DeepSeek-AI. 2025. DeepEP: An Efficient Expert-Parallel Communi- cation Library.https://github.com/deepseek-ai/DeepEP. Software library
2025
-
[8]
Jiarui Fang, Jinzhe Pan, Aoyu Li, Xibo Sun, and Jiannan Wang. 2025. PipeFusion: Patch-level Pipeline Parallelism for Diffusion Transform- ers Inference. arXiv:2405.14430 [cs.CV]https://arxiv.org/abs/2405. 14430
Pith/arXiv arXiv 2025
-
[9]
Jiarui Fang, Jinzhe Pan, Xibo Sun, Aoyu Li, and Jiannan Wang. 2024. xDiT: an Inference Engine for Diffusion Transformers (DiTs) with Massive Parallelism. arXiv:2411.01738 [cs.DC]https://arxiv.org/abs/ 2411.01738
arXiv 2024
-
[10]
FastVideo Team. 2025. FastVideo: A Unified Inference and Post- Training Framework for Accelerated Video Generation.https://github. com/hao-ai-lab/FastVideo. Software
2025
-
[11]
Yu Gao, Haoyuan Guo, Tuyen Hoang, Weilin Huang, Lu Jiang, Fangyuan Kong, Huixia Li, Jiashi Li, Liang Li, Xiaojie Li, Xunsong Li, Yifu Li, Shanchuan Lin, Zhijie Lin, Jiawei Liu, Shu Liu, Xiaonan Nie, Zhiwu Qing, Yuxi Ren, Li Sun, Zhi Tian, Rui Wang, Sen Wang, Guo- qiang Wei, Guohong Wu, Jie Wu, Ruiqi Xia, Fei Xiao, Xuefeng Xiao, Jiangqiao Yan, Ceyuan Yang,...
-
[12]
arXiv:2506.09113 [cs.CV]https://arxiv.org/abs/2506.09113
Seedance 1.0: Exploring the Boundaries of Video Generation Models. arXiv:2506.09113 [cs.CV]https://arxiv.org/abs/2506.09113
-
[13]
Agrim Gupta, Lijun Yu, Kihyuk Sohn, Xiuye Gu, Meera Hahn, Li Fei-Fei, Irfan Essa, Lu Jiang, and José Lezama. 2023. Photorealistic Video Generation with Diffusion Models. arXiv:2312.06662 [cs.CV] https://arxiv.org/abs/2312.06662
arXiv 2023
-
[14]
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, Poriya Panet, Sapir Weissbuch, Victor Kulikov, Yaki Bitterman, Zeev Melumian, and Ofir Bibi. 2024. LTX-Video: Re- altime Video Latent Diffusion. arXiv:2501.00103 [cs.CV]https: //arxiv.org/abs/2501.00103
Pith/arXiv arXiv 2024
-
[15]
Changho Hwang, Peng Cheng, Roshan Dathathri, Abhinav Jangda, Saeed Maleki, Madan Musuvathi, Olli Saarikivi, Aashaka Shah, Ziyue Yang, Binyang Li, Caio Rocha, Qinghua Zhou, Mahdieh Ghazimirsaeed, Sreevatsa Anantharamu, and Jithin Jose. 2026. MSCCL++: Rethinking GPU Communication Abstractions for AI Inference. InProceedings of the 31st ACM International Con...
-
[16]
Diederik P Kingma and Max Welling. 2022. Auto-Encoding Variational Bayes. arXiv:1312.6114 [stat.ML]https://arxiv.org/abs/1312.6114
Pith/arXiv arXiv 2022
-
[17]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, Kathrina Wu, Qin Lin, Junkun Yuan, Yanxin Long, Aladdin Wang, Andong Wang, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Hongmei Wang, Jacob Song, Ji- awang Bai, Jianbing Wu, Jinbao Xue, Joey Wang, Kai Wang, Mengyang Liu, Pengyu Li, Shuai Li...
Pith/arXiv arXiv 2025
-
[18]
Suyi Li, Lingyun Yang, Xiaoxiao Jiang, Hanfeng Lu, Dakai An, Zhipeng Di, Weiyi Lu, Jiawei Chen, Kan Liu, Yinghao Yu, Tao Lan, Guodong Yang, Lin Qu, Liping Zhang, and Wei Wang. 2025. KATZ: efficient workflow serving for diffusion models with many adapters. InPro- ceedings of the 2025 USENIX Conference on Usenix Annual Technical Conference(Boston, MA, USA)(...
2025
-
[19]
C. L. Liu and James W. Layland. 1973. Scheduling Algorithms for Multiprogramming in a Hard-Real-Time Environment.J. ACM20, 1 (Jan. 1973), 46–61. doi:10.1145/321738.321743
-
[20]
Haoyu Lu, Guoxing Yang, Nanyi Fei, Yuqi Huo, Zhiwu Lu, Ping Luo, and Mingyu Ding. 2023. VDT: General-purpose Video Diffu- sion Transformers via Mask Modeling. arXiv:2305.13311 [cs.CV] https://arxiv.org/abs/2305.13311
arXiv 2023
-
[21]
Ma, Ang Chen, and Mosharaf Chowdhury
Runyu Lu, Shiqi He, Wenxuan Tan, Shenggui Li, Ruofan Wu, Jeff J. Ma, Ang Chen, and Mosharaf Chowdhury. 2026. TetriS- erve: Efficient DiT Serving for Heterogeneous Image Generation. arXiv:2510.01565 [cs.LG]https://arxiv.org/abs/2510.01565
Pith/arXiv arXiv 2026
-
[22]
Jiajun Luo, Yicheng Xiao, Jianru Xu, Yangxiu You, Rongwei Lu, Chen Tang, Jingyan Jiang, and Zhi Wang. 2025. Accelerat- ing Parallel Diffusion Model Serving with Residual Compression. arXiv:2507.17511 [cs.CV]https://arxiv.org/abs/2507.17511
arXiv 2025
-
[23]
Michael Luo, Aaron Hao, Zhengxu Yan, Chengkun Cao, and Quang Lu- ong Nhat Nguyen. 2026. DiT-Serve: An Efficient Serving Engine for Dif- fusion Transformers.https://openreview.net/forum?id=NGNRc7rZBg
2026
-
[24]
Xin Ma, Yaohui Wang, Xinyuan Chen, Gengyun Jia, Ziwei Liu, Yuan- Fang Li, Cunjian Chen, and Yu Qiao. 2025. Latte: Latent Diffusion Transformer for Video Generation. arXiv:2401.03048 [cs.CV]https: //arxiv.org/abs/2401.03048
Pith/arXiv arXiv 2025
-
[25]
Ziming Mao, Yihan Zhang, Chihan Cui, Zhen Huang, Kaichao You, Zhongjie Chen, Zhiying Xu, Zhenyu Gu, Scott Shenker, Costin Raiciu, Yang Zhou, and Ion Stoica. 2026. UCCL-EP: Portable Expert-Parallel Communication. arXiv:2512.19849 [cs.DC]https://arxiv.org/abs/2512. 19849
arXiv 2026
-
[26]
NVIDIA Corporation. 2026. NVIDIA Collective Communication Li- brary (NCCL).https://developer.nvidia.com/nccl. Software library
2026
-
[27]
Lichen Pan, Juncheng Liu, Yongquan Fu, Jinhui Yuan, Rongkai Zhang, Pengze Li, and Zhen Xiao. 2025. Comprehensive Deadlock Prevention for GPU Collective Communication. InProceedings of the Twentieth Eu- ropean Conference on Computer Systems (EuroSys ’25). ACM, 541–557. doi:10.1145/3689031.3717466
-
[28]
William Peebles and Saining Xie. 2023. Scalable Diffusion Models with Transformers. arXiv:2212.09748 [cs.CV]https://arxiv.org/abs/ 2212.09748
Pith/arXiv arXiv 2023
-
[29]
Sampson, Shikai Li, Simone Parmeggiani, Steve Fine, Tara Fowler, Vladan Petrovic, and Yum- ing Du
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih-Yao Ma, Ching-Yao Chuang, David Yan, Dhruv Choudhary, Dingkang Wang, Geet Sethi, Guan Pang, Haoyu Ma, Ishan Misra, Ji Hou, Jialiang Wang, Kiran Ja- gadeesh, Kunpeng Li, Luxin Zhang, Mannat Singh, Mary Williamson, Matt Le, Matthew Yu, Mitesh Kumar Si...
Pith/arXiv arXiv 2025
-
[30]
PyTorch Contributors. 2025. PyTorch Symmetric Memory.https: //docs.pytorch.org/docs/stable/symmetric_memory.html. Accessed: 2026-06-08
2025
-
[31]
Linus Schrage. 1968. Letter to the Editor—A Proof of the Optimality of the Shortest Remaining Processing Time Discipline.Oper. Res.16, 3 (June 1968), 687–690. doi:10.1287/opre.16.3.687
-
[32]
SGLang Diffusion Team. 2025. SGLang Diffusion: Accelerating Video and Image Generation.https://www.lmsys.org/blog/2025-11- 07-sglang-diffusion/. LMSYS Blog
2025
-
[33]
Aashaka Shah, Vijay Chidambaram, Meghan Cowan, Saeed Maleki, Madan Musuvathi, Todd Mytkowicz, Jacob Nelson, Olli Saarikivi, and Rachee Singh. 2023. TACCL: Guiding Collective Algorithm Synthe- sis using Communication Sketches. In20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23). USENIX As- sociation, Boston, MA, 593–612.https:/...
2023
-
[34]
Min Si, Pavan Balaji, Yongzhou Chen, Ching-Hsiang Chu, Adi Gangidi, Saif Hasan, Subodh Iyengar, Dan Johnson, Bingzhe Liu, Regina Ren, Deep Shah, Ashmitha Jeevaraj Shetty, Greg Steinbrecher, Yulun Wang, Bruce Wu, Xinfeng Xie, Jingyi Yang, Mingran Yang, Kenny Yu, Min- lan Yu, Cen Zhao, Wes Bland, Denis Boyda, Suman Gumudavelli, Prashanth Kannan, Cristian Lu...
arXiv 2026
-
[35]
Desen Sun, Zepeng Zhao, and Yuke Wang. 2025. PATCHEDSERVE: A Patch Management Framework for SLO-Optimized Hybrid Resolution Diffusion Serving. arXiv:2501.09253 [cs.DC]https://arxiv.org/abs/ 2501.09253
arXiv 2025
-
[36]
Desen Sun, Zepeng Zhao, and Yuke Wang. 2026. MixFusion: A Patch- Level Parallel Serving System for Mixed-Resolution Diffusion Models. InProceedings of the 31st ACM SIGPLAN Annual Symposium on Prin- ciples and Practice of Parallel Programming(Sydney, NSW, Australia) (PPoPP ’26). Association for Computing Machinery, New York, NY, USA, 522–536. doi:10.1145/3...
-
[37]
Meituan LongCat Team, Xunliang Cai, Qilong Huang, Zhuoliang Kang, Hongyu Li, Shijun Liang, Liya Ma, Siyu Ren, Xiaoming Wei, Rixu Xie, and Tong Zhang. 2025. LongCat-Video Technical Report. arXiv:2510.22200 [cs.CV]https://arxiv.org/abs/2510.22200
arXiv 2025
-
[38]
Philippe Tillet, H. T. Kung, and David Cox. 2019. Triton: an interme- diate language and compiler for tiled neural network computations. InProceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages(Phoenix, AZ, USA) (MAPL 2019). Association for Computing Machinery, New York, NY, USA, 10–19. doi:10.1145/3315508....
-
[39]
Manjunath Gorentla Venkata, Valentine Petrov, Sergey Lebedev, De- vendar Bureddy, Ferrol Aderholdt, Joshua Ladd, Gil Bloch, Mike Dub- man, and Gilad Shainer. 2025. Unified Collective Communication: A Unified Library for CPU, GPU, and DPU Collectives.IEEE Micro45, 2 (March 2025), 26–35. doi:10.1109/MM.2025.3534638
-
[40]
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
Pith/arXiv arXiv 2025
-
[41]
William Won, Midhilesh Elavazhagan, Sudarshan Srinivasan, Swati Gupta, and Tushar Krishna. 2024. TACOS: Topology-Aware Collec- tive Algorithm Synthesizer for Distributed Machine Learning. InPro- ceedings of the 2024 57th IEEE/ACM International Symposium on Mi- croarchitecture(Austin, TX, USA)(MICRO ’24). IEEE Press, 856–870. doi:10.1109/MICRO61859.2024.00068
-
[42]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxi- ang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, Deqing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingk...
Pith/arXiv arXiv 2025
-
[43]
Yifei Xia, Fangcheng Fu, Hao Yuan, Hanke Zhang, Xupeng Miao, Yijun Liu, Suhan Ling, Jie Jiang, and Bin Cui. 2025. TridentServe: A Stage- level Serving System for Diffusion Pipelines. arXiv:2510.02838 [cs.DC] https://arxiv.org/abs/2510.02838
arXiv 2025
-
[44]
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, Da Yin, Yuxuan Zhang, Weihan Wang, Yean Cheng, Bin Xu, Xiaotao Gu, Yuxiao Dong, and Jie Tang. 2025. CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer. arXiv:2408.06072 [cs.CV]https://arxiv.org/abs/2408.06072
Pith/arXiv arXiv 2025
-
[45]
Fanjiang Ye, Zhangke Li, Xinrui Zhong, Ethan Ma, Russell Chen, Kai- jian Wang, Jingwei Zuo, Desen Sun, Ye Cao, Triston Cao, Myungjin Lee, Arvind Krishnamurthy, and Yuke Wang. 2026. GENSERVE: Efficient Co-Serving of Heterogeneous Diffusion Model Workloads. arXiv:2604.04335 [cs.DC]https://arxiv.org/abs/2604.04335
Pith/arXiv arXiv 2026
-
[46]
Peiqi Yin, Jiangyun Zhu, Han Gao, Chenguang Zheng, Yongxiang Huang, Taichang Zhou, Ruirui Yang, Weizhi Liu, Weiqing Chen, Canlin Guo, Didan Deng, Zifeng Mo, Cong Wang, James Cheng, Roger Wang, and Hongsheng Liu. 2026. vLLM-Omni: Fully Disaggregated Serving for Any-to-Any Multimodal Models. arXiv:2602.02204 [cs.DC]https: //arxiv.org/abs/2602.02204
arXiv 2026
-
[47]
Zangwei Zheng, Xiangyu Peng, Yuxuan Lou, Chenhui Shen, Tom Young, Xinying Guo, Binluo Wang, Hang Xu, Hongxin Liu, Mingyan Jiang, Wenjun Li, Yuhui Wang, Anbang Ye, Gang Ren, Qianran Ma, Wanying Liang, Xiang Lian, Xiwen Wu, Yuting Zhong, Zhuangyan Li, Chaoyu Gong, Guojun Lei, Leijun Cheng, Limin Zhang, Ming- hao Li, Ruijie Zhang, Silan Hu, Shijie Huang, Xia...
Pith/arXiv arXiv 2026
-
[48]
Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Sheng- gui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You
-
[49]
arXiv:2412.20404 [cs.CV]https://arxiv.org/abs/2412.20404
Open-Sora: Democratizing Efficient Video Production for All. arXiv:2412.20404 [cs.CV]https://arxiv.org/abs/2412.20404
-
[50]
Yang Zhou, Zhongjie Chen, Ziming Mao, ChonLam Lao, Shuo Yang, Pravein Govindan Kannan, Jiaqi Gao, Yilong Zhao, Yongji Wu, Kaichao You, Fengyuan Ren, Zhiying Xu, Costin Raiciu, and Ion Stoica
-
[51]
arXiv:2504.17307 [cs.NI]https://arxiv.org/abs/2504.17307
An Extensible Software Transport Layer for GPU Network- ing. arXiv:2504.17307 [cs.NI]https://arxiv.org/abs/2504.17307
-
[52]
Yuan Zhou, Qiuyue Wang, Yuxuan Cai, and Huan Yang. 2024. Allegro: Open the Black Box of Commercial-Level Video Generation Model. arXiv:2410.15458 [cs.CV]https://arxiv.org/abs/2410.15458 15
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.