OPERA: A Reinforcement Learning--Enhanced Orchestrated Planner-Executor Architecture for Reasoning-Oriented Multi-Hop Retrieval
Pith reviewed 2026-05-21 22:56 UTC · model grok-4.3
The pith
OPERA couples reasoning and retrieval through a planner-executor design trained with a new reinforcement learning method to handle complex multi-hop questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
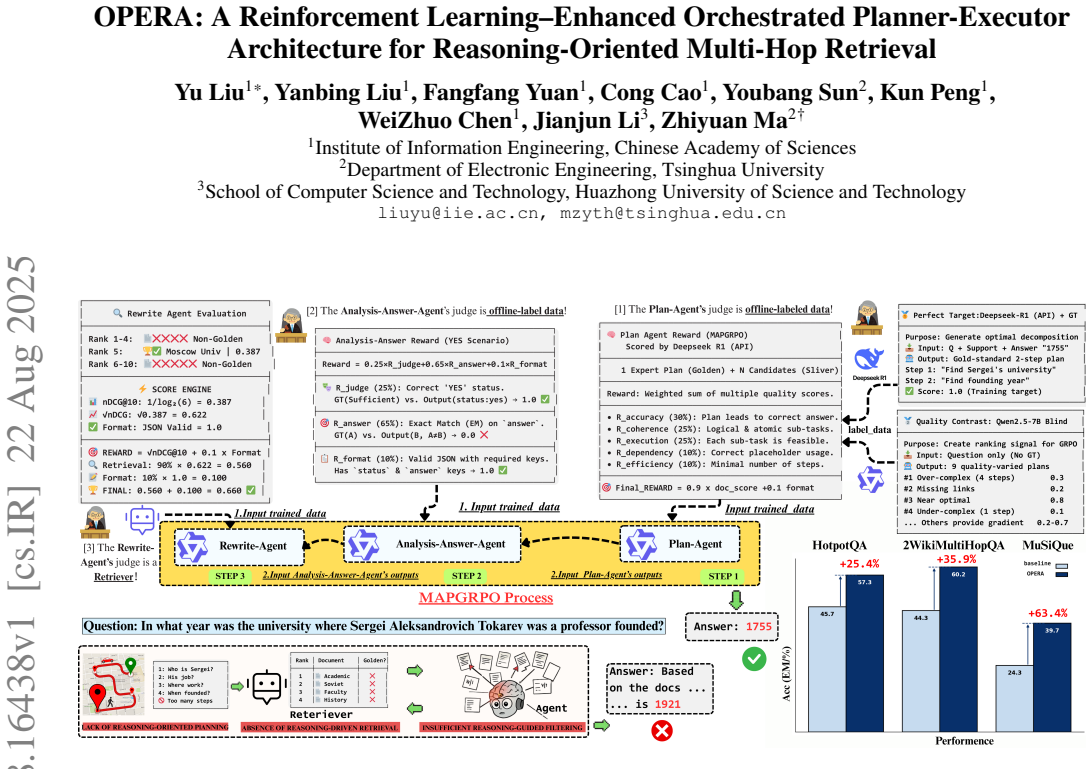
OPERA decomposes questions into sub-goals via its Goal Planning Module, which are then executed by the Reason-Execute Module with specialized reasoning and retrieval steps, all optimized by Multi-Agents Progressive Group Relative Policy Optimization to deliver superior results on reasoning-oriented multi-hop retrieval tasks.
What carries the argument
The Orchestrated Planner-Executor Reasoning Architecture (OPERA) with its Goal Planning Module (GPM) for sub-goal decomposition and Reason-Execute Module (REM) for coordinated reasoning-driven retrieval, trained end-to-end using Multi-Agents Progressive Group Relative Policy Optimization (MAPGRPO).
If this is right
- Robust multi-step plans emerge even for queries outside fixed templates.
- Iterative retrieval loops shorten because each step is guided by explicit reasoning.
- Salient facts are extracted more reliably from noisy retrieved sets.
- The MAPGRPO training approach itself proves effective for coordinating multiple retrieval-reasoning agents.
Where Pith is reading between the lines
- The same planner-executor split could reduce error accumulation in other chained reasoning tasks such as multi-document summarization.
- Progressive group optimization may scale to larger agent teams for web-scale retrieval without proportional increases in compute.
- Tighter reasoning-retrieval loops could lower overall latency in production RAG pipelines by cutting unnecessary document fetches.
Load-bearing premise
The three main limitations arise from weak coupling between retrieval and reasoning, and that the GPM, REM, and MAPGRPO training resolve them without creating comparable new failure modes.
What would settle it
A head-to-head evaluation on the same complex multi-hop benchmarks where OPERA shows no accuracy or efficiency gain over prior methods would disprove the superiority claim and the validation of its design.
Figures








read the original abstract
Recent advances in large language models (LLMs) and dense retrievers have driven significant progress in retrieval-augmented generation (RAG). However, existing approaches face significant challenges in complex reasoning-oriented multi-hop retrieval tasks: 1) Ineffective reasoning-oriented planning: Prior methods struggle to generate robust multi-step plans for complex queries, as rule-based decomposers perform poorly on out-of-template questions. 2) Suboptimal reasoning-driven retrieval: Related methods employ limited query reformulation, leading to iterative retrieval loops that often fail to locate golden documents. 3) Insufficient reasoning-guided filtering: Prevailing methods lack the fine-grained reasoning to effectively filter salient information from noisy results, hindering utilization of retrieved knowledge. Fundamentally, these limitations all stem from the weak coupling between retrieval and reasoning in current RAG architectures. We introduce the Orchestrated Planner-Executor Reasoning Architecture (OPERA), a novel reasoning-driven retrieval framework. OPERA's Goal Planning Module (GPM) decomposes questions into sub-goals, which are executed by a Reason-Execute Module (REM) with specialized components for precise reasoning and effective retrieval. To train OPERA, we propose Multi-Agents Progressive Group Relative Policy Optimization (MAPGRPO), a novel variant of GRPO. Experiments on complex multi-hop benchmarks show OPERA's superior performance, validating both the MAPGRPO method and OPERA's design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OPERA, an orchestrated planner-executor architecture for reasoning-oriented multi-hop retrieval in RAG systems. It identifies three core limitations in prior work—in effective planning, suboptimal retrieval, and insufficient filtering—and attributes them to weak retrieval-reasoning coupling. OPERA introduces a Goal Planning Module (GPM) to decompose queries into sub-goals and a Reason-Execute Module (REM) with specialized reasoning and retrieval components. Training uses Multi-Agents Progressive Group Relative Policy Optimization (MAPGRPO), a novel GRPO variant. Experiments on complex multi-hop benchmarks are reported to demonstrate superior performance, validating both the architecture and the training method.
Significance. If the reported benchmark gains hold under rigorous controls, the work would advance retrieval-augmented reasoning by demonstrating a tighter integration of planning, execution, and RL-based optimization. The MAPGRPO training procedure for multi-agent RAG systems could also serve as a reusable contribution for other reasoning-heavy retrieval tasks.
major comments (2)
- [§5 Experiments] §5 Experiments (and associated tables): the central claim of 'superior performance' validating both MAPGRPO and the OPERA design is stated, yet the manuscript supplies no numerical results, baseline comparisons, metrics (e.g., exact-match, F1, or retrieval recall), error bars, or statistical tests. Without these data the validation cannot be assessed and the claim remains unevaluated.
- [§3 Architecture] §3 Architecture and §4 Training: the paper asserts that GPM + REM plus MAPGRPO directly resolve the three listed limitations without introducing comparable new failure modes, but provides no ablation isolating the contribution of each module or any analysis of potential new error patterns (e.g., planning instability or over-filtering). This assumption is load-bearing for the causal story.
minor comments (2)
- [§4 Training] Notation for MAPGRPO is introduced without an explicit algorithmic listing or pseudocode; a compact algorithm box would improve reproducibility.
- [Abstract] The abstract and introduction use the term 'golden documents' without defining the precise retrieval-success criterion employed in the benchmarks.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback on our manuscript. We agree that the current version requires additional empirical details and analyses to fully support the claims. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§5 Experiments] §5 Experiments (and associated tables): the central claim of 'superior performance' validating both MAPGRPO and the OPERA design is stated, yet the manuscript supplies no numerical results, baseline comparisons, metrics (e.g., exact-match, F1, or retrieval recall), error bars, or statistical tests. Without these data the validation cannot be assessed and the claim remains unevaluated.
Authors: We agree that the submitted manuscript does not present the requested numerical results, baseline comparisons, specific metrics, error bars, or statistical tests. This omission prevents proper evaluation of the performance claims. In the revised version we will add complete experimental tables reporting exact-match, F1, and retrieval-recall scores for OPERA and all baselines, include error bars from multiple random seeds, and report statistical significance tests (paired t-tests or Wilcoxon signed-rank tests) with p-values. revision: yes
-
Referee: [§3 Architecture] §3 Architecture and §4 Training: the paper asserts that GPM + REM plus MAPGRPO directly resolve the three listed limitations without introducing comparable new failure modes, but provides no ablation isolating the contribution of each module or any analysis of potential new error patterns (e.g., planning instability or over-filtering). This assumption is load-bearing for the causal story.
Authors: The referee is correct that the manuscript currently lacks ablations and analysis of possible new failure modes. We will add a new subsection with systematic ablations that remove or replace GPM, REM components, and the MAPGRPO objective one at a time, reporting the resulting performance drops on the same benchmarks. We will also include a qualitative error analysis section that examines cases of planning instability and over-filtering, with concrete examples and frequency statistics drawn from the evaluation sets. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces OPERA as a new architecture with GPM and REM modules plus the MAPGRPO training variant, motivated by three limitations in prior RAG systems. No equations, derivations, or first-principles reductions appear in the abstract or described claims. Performance validation rests on external benchmark experiments rather than any self-referential fit or definition. No self-citation chains, uniqueness theorems, or ansatzes are invoked in a load-bearing way within the provided text. The central claims remain independent of the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Rule-based decomposers perform poorly on out-of-template questions
- domain assumption Limited query reformulation leads to failing iterative retrieval loops
invented entities (3)
-
Goal Planning Module (GPM)
no independent evidence
-
Reason-Execute Module (REM)
no independent evidence
-
Multi-Agents Progressive Group Relative Policy Optimization (MAPGRPO)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce the Orchestrated Planner-Executor Reasoning Architecture (OPERA)... MAPGRPO, a novel variant of GRPO... Experiments on complex multi-hop benchmarks show OPERA's superior performance
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The reward function is: rplan(q, P) = λ1 · flogic(q, P) + λ2 · fstruct(P) + λ3 · fexec(P, E)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Hong, S.; Zhuge, M.; Chen, J.; Zheng, X.; Cheng, Y .; Zhang, C.; Wang, J.; Wang, Z.; Yau, S
Barcelona, Spain (Online): International Committee on Computational Linguistics. Hong, S.; Zhuge, M.; Chen, J.; Zheng, X.; Cheng, Y .; Zhang, C.; Wang, J.; Wang, Z.; Yau, S. K. S.; Lin, Z.; Zhou, L.; Ran, C.; Xiao, L.; Wu, C.; and Schmidhuber, J. 2024. MetaGPT: Meta Programming for A Multi-Agent Collaborative Frame- work. In Proceedings of the 12th Intern...
work page 2024
-
[2]
Lee, M.; An, S.; and Kim, M.-S
Florence, Italy: Association for Computational Lin- guistics. Lee, M.; An, S.; and Kim, M.-S. 2024. PlanRAG: A Plan- then-Retrieval Augmented Generation for Generative Large Language Models as Decision Makers. InProceedings of the 2024 Conference of the North American Chapter of the As- sociation for Computational Linguistics: Human Language Technologies ...
work page 2024
-
[3]
Proximal Policy Optimization Algorithms
Sparse, Dense, and Attentional Representations for Text Retrieval. Transactions of the Association for Compu- tational Linguistics, 9: 329–345. Papangelis, A.; Wang, Y .-C.; Molino, P.; and Tur, G. 2019. Collaborative Multi-Agent Dialogue Model Training via Re- inforcement Learning. In Proceedings of the 20th Annual SIGdial Meeting on Discourse and Dialog...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[4]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
DeepSeekMath: Pushing the Limits of Mathemati- cal Reasoning in Open Language Models. arXiv preprint arXiv:2402.03300. Stiennon, N.; Ouyang, L.; Wu, J.; Ziegler, D. M.; Lowe, R.; V oss, C.; Radford, A.; Amodei, D.; and Christiano, P. F
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Learning to Summarize with Human Feedback. In Advances in Neural Information Processing Systems , vol- ume 33, 3008–3021. Tang, Y .; and Yang, Y . 2024. MultiHop-RAG: Bench- marking Retrieval-Augmented Generation for Multi-Hop Queries. In First Conference on Language Modeling (COLM). Trivedi, H.; Balasubramanian, N.; Khot, T.; and Sabharwal, A. 2022. MuSi...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
End-to-End Beam Retrieval for Multi-Hop Question Answering. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computa- tional Linguistics: Human Language Technologies, Volume 1: Long Papers, 1718–1731. Mexico City, Mexico: Associ- ation for Computational Linguistics. A Appendix Case Study OPERA vs. Traditional RAG....
work page 2024
-
[7]
Which company acquired WhatsApp?
-
[8]
Where is [company from step 1] headquartered? {deps: [1]}
-
[9]
Which company acquired WhatsApp?
What is the population of [city from step 2]? {deps: [2]} Reward: 0.92 (High-quality decomposition) Step 2: Analysis-Answer Agent - Subgoal 1 Query “Which company acquired WhatsApp?” Retrieved 1. “...Facebook Inc. announced the acquisition of WhatsApp for $19 billion...”
-
[10]
The messaging app WhatsApp, owned by Meta (formerly Facebook)
“...The messaging app WhatsApp, owned by Meta (formerly Facebook)...” Analysis Clear evidence that Facebook (now Meta) acquired WhatsApp. Decision YES → Answer: “Facebook (now Meta)” (Conf: 0.95) TMC Update Entity Resolution: “company from step 1” → “Facebook/Meta” Step 3: Analysis-Answer Agent - Subgoal 2 Query “Where is Facebook/Meta headquartered?” Ret...
-
[11]
Facebook’s main campus is located at 1 Hacker Way, Menlo Park, CA
“...Facebook’s main campus is located at 1 Hacker Way, Menlo Park, CA...” Decision YES → Answer: “Menlo Park, California” (Conf: 0.98) TMC Update Entity Resolution: “city from step 2” → “Menlo Park” Step 4: Analysis-Answer Agent - Subgoal 3 (Initial Failure) Query “What is the population of Menlo Park?” Retrieved 1. “...Menlo Park is known for its tech co...
-
[12]
The city has numerous parks and recreational areas
“...The city has numerous parks and recreational areas...” Analysis Retrieved documents lack specific population data. Decision NO - Need more specific information Step 5: Rewrite Agent (3B) - Query Refinement Failed Query “What is the population of Menlo Park?” Strategy Add demographic keywords and year specificity Rewritten “Menlo Park California popula...
work page 2020
-
[13]
Menlo Park demographics show a diverse community with 35,211 residents
“...Menlo Park demographics show a diverse community with 35,211 residents...” Decision YES → Answer: “35,211 (as of 2020 census)” (Conf: 0.93) Final Answer The population of Menlo Park, California, where Meta (formerly Facebook), the company that acquired WhatsApp, is headquar- tered, is 35,211 according to the 2020 census. Metrics Steps: 6 — Plan: 1 — A...
work page 2020
-
[14]
The reward function r(k) is bounded: |r(k)(x, y)| ≤ Rmax for all (x, y)
-
[15]
The policy π(k) θk is differentiable with respect to θk and satisfies the Lipschitz condition: ∥∇θk log π(k) θk (y|x)∥ ≤ L for some constant L > 0
-
[16]
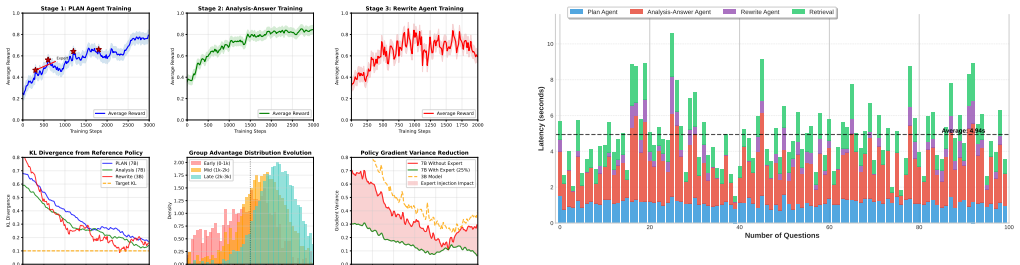
The KL divergence constraint is satisfied: Ex∼Dk[DKL[π(k) θk (·|x)∥π(k) ref (·|x)]] ≤ ϵKL for some ϵKL > 0. MAPGRPO Convergence. Under these conditions, each stage of MAPGRPO converges to a local optimum of its ob- jective function. For agent k trained in stage k, the expected squared gradient norm satisfies: E ∥∇θk Jk(θk|θ∗ <k)∥2 = O 1√Tk , (12) where Tk...
-
[17]
DeepSeek R1 Generation Quality: Use R1’s built-in reasoning verification and self-correction capabilities
-
[18]
Execution Simulation: Complete end-to-end execution of each plan using our retrieval pipeline
-
[19]
Answer Verification: Exact match validation against ground-truth answers with normalized string comparison
-
[20]
Format Compliance: JSON structure and placeholder syntax validation using automated parsers
-
[21]
Diversity Filtering: Removal of near-duplicate candi- dates using semantic similarity thresholds (cosine simi- larity < 0.85) Statistical Distribution and Quality Metrics. The final Dscored has the following characteristics: • Score Distribution: µ = 0.73, σ = 0.21 (on 0-1 scale) • High-score samples (> 0.85): 15% of dataset (4,500 samples) • Medium-score...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.