CSULoRA: Closest Safe Update Low-Rank Adaptation
Pith reviewed 2026-06-29 08:22 UTC · model grok-4.3
The pith
CSULoRA corrects trained LoRA adapters by estimating a safety subspace from aligned models and attenuating unsafe update directions via penalized minimum change.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
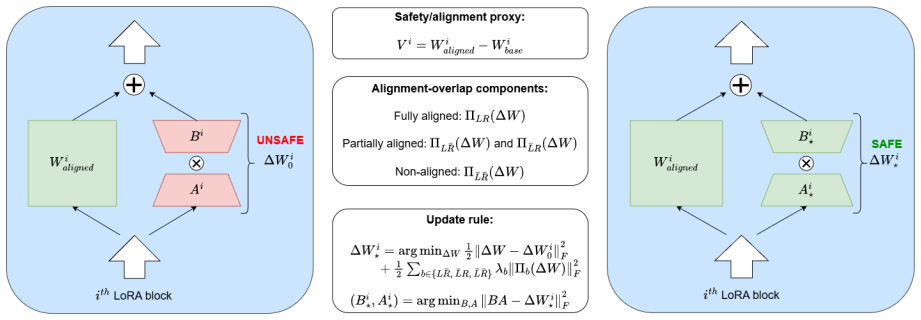
CSULoRA estimates a safety-aligned subspace from the weight displacement between a safety-aligned model and its corresponding base checkpoint. It decomposes each LoRA update into fully aligned, partially aligned, and off-subspace components. Instead of discarding off-subspace parts, it solves a closed-form penalized minimum-change problem that preserves the fully aligned component while smoothly attenuating potentially unsafe directions according to their relative energy.
What carries the argument
Safety-aligned subspace estimated from weight displacement between safety-aligned and base models, used within a penalized minimum-change optimization to produce the closest safe LoRA update.
If this is right
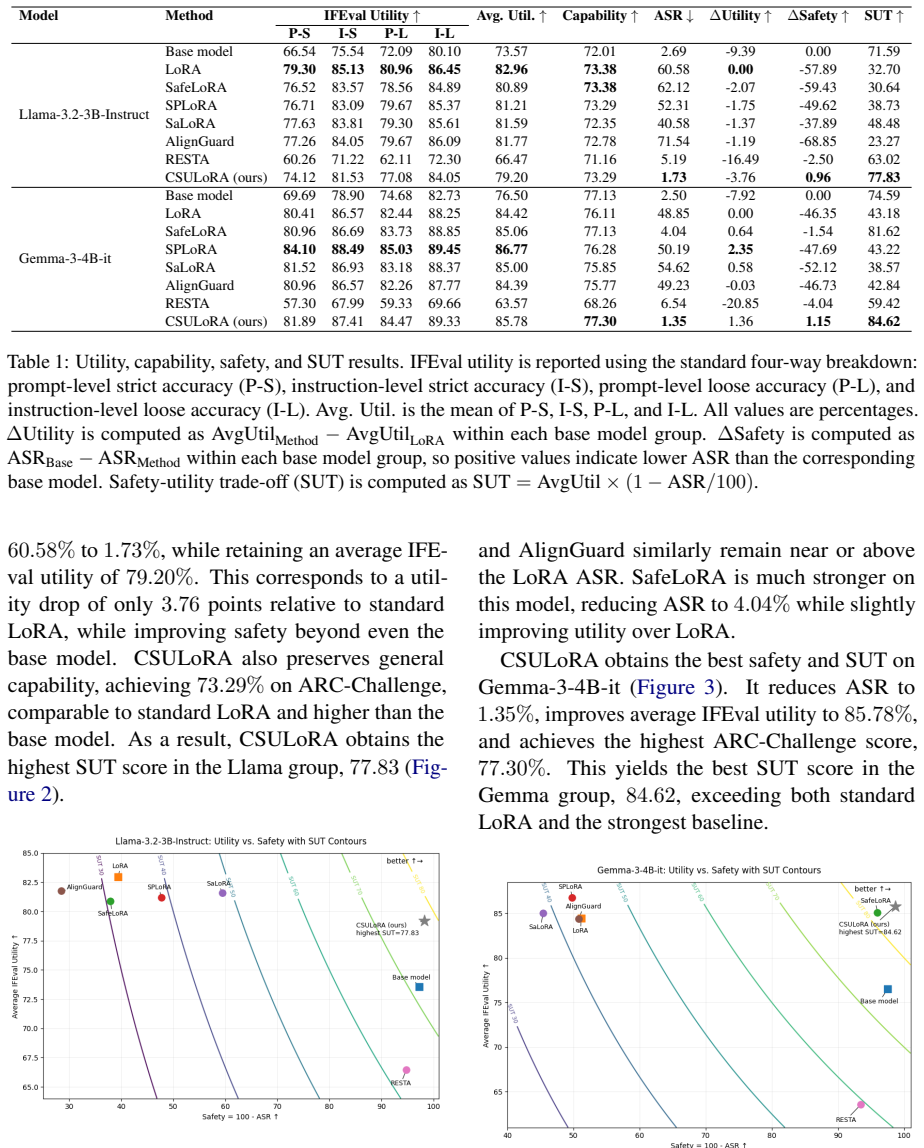
- Substantially reduces attack success rate in adversarial fine-tuning experiments.
- Preserves most of the utility gains from standard LoRA fine-tuning.
- Avoids hard interventions such as projection or pruning that can remove task-relevant information.
- Operates as a post-hoc correction without additional training objectives or hyperparameters beyond the penalty term.
Where Pith is reading between the lines
- The subspace approach may extend to preserving other model properties such as factual accuracy or specific behavioral constraints.
- Safety information appears concentrated enough in low-dimensional weight differences to allow selective attenuation rather than full retraining.
- The closed-form solution could support iterative application across multiple sequential fine-tuning steps.
Load-bearing premise
The directions of change from base model to safety-aligned model mark the features that must be preserved to maintain safety during later fine-tuning updates.
What would settle it
An experiment showing that CSULoRA-corrected adapters produce attack success rates equal to or higher than uncorrected LoRA adapters on standard safety benchmarks while matching their utility scores.
Figures
read the original abstract
Low-rank adaptation has become a standard method for parameter-efficient fine-tuning of large language models, but even small amounts of unsafe or adversarial fine-tuning data can substantially weaken the safety behavior of aligned models. Existing safety-preserving LoRA methods often rely on hard interventions such as projection, pruning, thresholding, or additional training objectives. While these methods can suppress unsafe update directions, they may also remove task-relevant information or require extra tuning. We introduce CSULoRA, a post-hoc method for correcting trained LoRA adapters through closest safe update estimation. CSULoRA estimates a safety-aligned subspace from the weight displacement between a safety-aligned model and its corresponding base checkpoint. It then decomposes each LoRA update into fully aligned, partially aligned, and off-subspace components. Instead of discarding components outside the estimated safety subspace, CSULoRA solves a closed-form penalized minimum-change problem that preserves the fully aligned component while smoothly attenuating potentially unsafe directions according to their relative energy. In adversarial fine-tuning experiments, CSULoRA substantially reduces attack success rate while preserving most of the utility gains obtained from standard LoRA fine-tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CSULoRA, a post-hoc correction for LoRA adapters that estimates a safety-aligned subspace from the weight displacement between a safety-aligned model and its base checkpoint. It decomposes each trained LoRA update into fully aligned, partially aligned, and off-subspace components, then solves a closed-form penalized minimum-change problem that preserves the aligned component while attenuating off-subspace directions according to their relative energy. In adversarial fine-tuning experiments the method is reported to substantially lower attack success rate while retaining most of the utility gains of standard LoRA.
Significance. If the safety-subspace estimation and the closed-form penalization are shown to be robust, the approach would supply an efficient, training-free safeguard for parameter-efficient fine-tuning that avoids the information loss of hard projections or extra objectives. The closed-form character of the update is a methodological strength that could be reproduced and extended.
major comments (2)
- [Abstract] Abstract: the claim that the single difference vector (or its span) between a safety-aligned checkpoint and its base accurately identifies directions that preserve safety under subsequent LoRA updates on new adversarial data is load-bearing for the reported reductions in attack success rate, yet the abstract supplies no validation that this fixed subspace was checked against the actual unsafe directions observed in the experiments.
- [Abstract] Abstract: the penalized optimization is described as preserving the fully aligned component while smoothly attenuating off-subspace directions, but without the explicit objective function, the definition of the penalty term, or the decomposition into the three components, it is impossible to verify that the closed-form solution does not inadvertently permit unsafe projections when the LoRA rank or initialization places energy outside the estimated subspace.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract would benefit from greater substantiation of its claims and a brief reference to the method's formulation. We address each point below and will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the single difference vector (or its span) between a safety-aligned checkpoint and its base accurately identifies directions that preserve safety under subsequent LoRA updates on new adversarial data is load-bearing for the reported reductions in attack success rate, yet the abstract supplies no validation that this fixed subspace was checked against the actual unsafe directions observed in the experiments.
Authors: The abstract is a high-level summary. The full manuscript reports adversarial fine-tuning experiments in which CSULoRA applied to LoRA adapters trained on new adversarial data yields substantial reductions in attack success rate relative to standard LoRA, while retaining most utility gains. These results constitute empirical validation that the subspace estimated from the single safety-aligned difference vector attenuates unsafe directions arising in subsequent updates. We will revise the abstract to explicitly note that the subspace's effectiveness is supported by the reported experimental safety improvements on new adversarial tasks. revision: yes
-
Referee: [Abstract] Abstract: the penalized optimization is described as preserving the fully aligned component while smoothly attenuating off-subspace directions, but without the explicit objective function, the definition of the penalty term, or the decomposition into the three components, it is impossible to verify that the closed-form solution does not inadvertently permit unsafe projections when the LoRA rank or initialization places energy outside the estimated subspace.
Authors: The abstract summarizes the high-level behavior; the explicit objective function, penalty term, three-component decomposition (fully aligned, partially aligned, off-subspace), and closed-form solution are derived and stated in Section 3 of the manuscript. The penalization attenuates off-subspace energy proportionally, and the experimental reductions in attack success rate confirm that unsafe projections are not inadvertently permitted. We will revise the abstract to include a short reference to the closed-form penalized minimum-change problem. revision: yes
Circularity Check
No significant circularity; derivation uses external displacement for subspace and independent penalized optimization.
full rationale
The paper defines CSULoRA via an external safety subspace estimated from a fixed base-vs-aligned weight displacement (independent of the LoRA training data) followed by a closed-form penalized minimum-change decomposition of the update. No equations reduce the output to a quantity fitted from the same data by construction, no self-citations are load-bearing in the provided description, and the central procedure is not self-definitional or a renamed known result. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Direct preference optimization: your language model is secretly a reward model. InProceedings of the 37th International Conference on Neural In- formation Processing Systems, NIPS ’23, Red Hook, NY , USA. Curran Associates Inc. Shaan Shah, Kaustubh Ponkshe, Raghav Singhal, and Praneeth Vepakomma. 2025. Safety subspaces are not distinct: A fine-tuning case...
-
[2]
Shadow alignment: The ease of subvert- ing safely-aligned language models.arXiv preprint arXiv:2310.02949. Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2020. Bertscore: Eval- uating text generation with bert. InInternational Conference on Learning Representations. Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahm...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.