Inclusive Interactive Collisions for Multi-View Consistent Compositional 3D Generation
Pith reviewed 2026-06-26 00:46 UTC · model grok-4.3
The pith
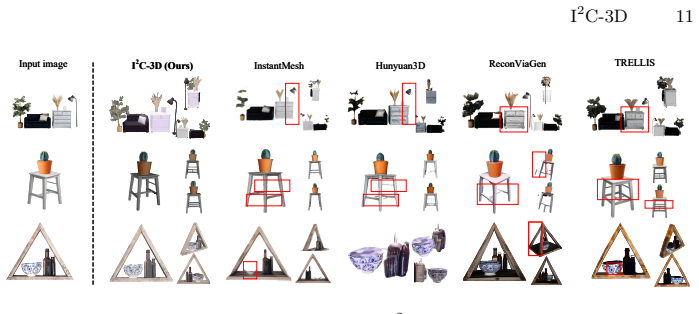
I2C-3D generates multi-view consistent compositional 3D assets by enforcing physically plausible interactions among objects through guided Gaussian primitives and attention-modulated distillation from pre-trained diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
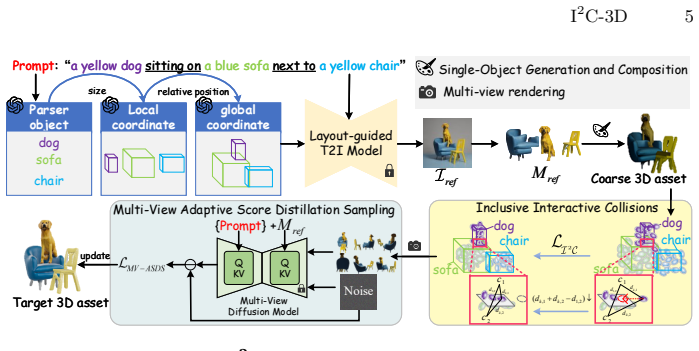
I2C-3D claims that reasonable object interactions and cross-view consistency can both be achieved in optimization-based 3D generation by first directing Gaussian primitives into plausible collision zones via an inclusive interaction strategy and second by distilling multi-view priors through viewpoint-adaptive modulation of attention maps on instance and spatial tokens inside a pre-trained diffusion model.
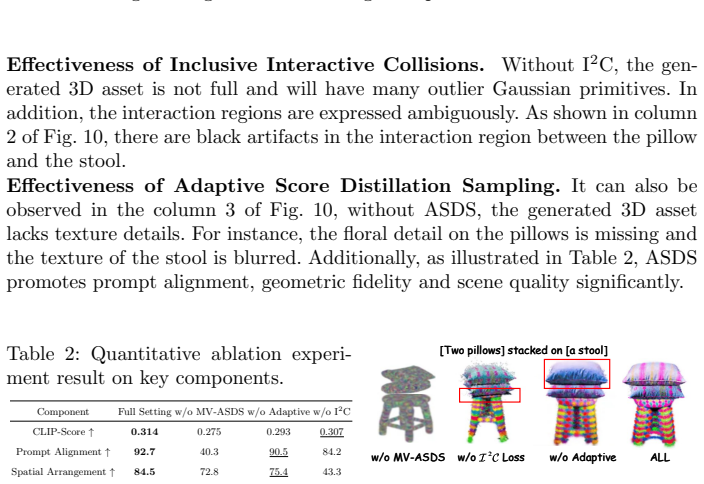
What carries the argument
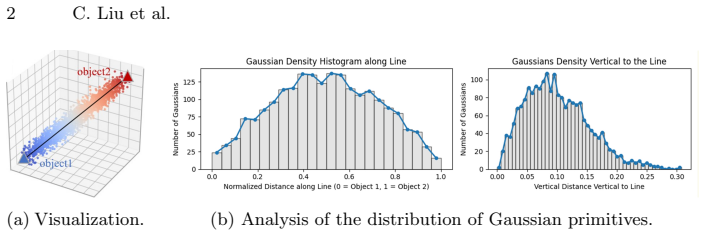
Inclusive Interactive Collisions strategy that places Gaussian primitives in physically plausible interaction regions, paired with Multi-View Adaptive Score Distillation Sampling that modulates attention maps of instance tokens and spatial tokens across multiple viewpoints to extract consistency and layout priors.
If this is right
- Compositional 3D scenes can be produced with objects that touch and occlude one another in visually coherent ways.
- The same generated asset remains consistent when rendered from arbitrary camera angles.
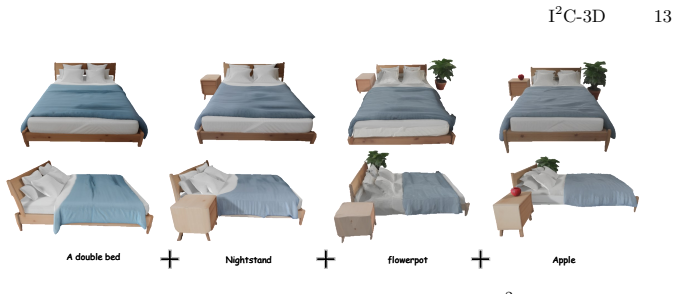
- Individual objects inside a scene can be edited in 3D while preserving the rest of the composition.
- Complex multi-object environments become feasible without manual placement of every element.
Where Pith is reading between the lines
- The same collision and attention-modulation ideas could be tested on dynamic sequences to produce time-consistent motion of interacting objects.
- If the priors extracted from the diffusion model prove reliable, the approach might reduce the need for explicit 3D supervision in other compositional tasks.
- Extending the interaction guidance to non-Gaussian representations could show whether the benefit is tied to the primitive type or to the collision rule itself.
Load-bearing premise
A pre-trained diffusion model already holds multi-view consistency and layout information that can be extracted simply by changing how attention is paid to instance and spatial tokens when the model looks at several viewpoints at once.
What would settle it
Render a generated multi-object scene from several novel viewpoints not used during optimization and check whether object boundaries, contact points, and relative layouts remain free of new hallucinations or geometric drift.
Figures







read the original abstract
Recent breakthroughs in 3D generation have advanced notably with the development of text-to-image diffusion model. However, existing methods remain two practical challenges: (1) They primarily generate single 3D object, but struggle to generate multi-object compositional 3D assets due to the lack of the modeling for Gaussian primitives in reasonable interactions. (2) They often suffer from cross-view inconsistency during 3D optimization, as Score Distillation Sampling inherently performs on each single view, inevitably resulting in cross-view hallucinations. To solve above issues, we propose I2C-3D, a novel optimization-based method to generate multi-view consistent compositional 3D assets with reasonable interactions. Specifically, we propose an Inclusive Interactive Collisions strategy to guide Gaussian primitives appearing in reasonable interaction regions naturally, thereby ensuring objects in the compositional scene interact in a physically plausible and visually coherent way. Additionally, to enhance multi-view consistency, Multi-View Adaptive Score Distillation Sampling is devised to distill multi-view consistency prior and layout prior from pre-trained diffusion model by modulating attention map of instance token and spatial token across viewpoints. Benefiting from above elaborate designs, I2C-3D not only generates high-fidelity multi-view consistent compositional 3D assets but also supports 3D editing flexibly, facilitating complex scene generation. Extensive experiments demonstrate our I2C-3D outperforms existing methods in generation quality and multi-view consistency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces I2C-3D, an optimization-based method for text-to-3D generation of multi-object compositional scenes. It proposes Inclusive Interactive Collisions to enforce physically plausible interactions among Gaussian primitives and Multi-View Adaptive Score Distillation Sampling that modulates attention maps of instance and spatial tokens across views to extract consistency and layout priors from a pre-trained diffusion model. The central claim is that these components together yield high-fidelity, multi-view consistent 3D assets that support flexible editing and outperform prior methods.
Significance. If the quantitative claims hold, the work would address two persistent limitations in 3D generation—unrealistic object interactions and cross-view inconsistency—while adding editing functionality. This could improve downstream applications such as scene synthesis and interactive content creation. The method's reliance on modulating existing diffusion priors without new training is a practical strength.
major comments (2)
- [Abstract, §4] Abstract and §4 (Experiments): the manuscript asserts that I2C-3D 'outperforms existing methods in generation quality and multi-view consistency' and produces 'high-fidelity' results, yet the abstract supplies no numerical metrics, ablation tables, or baseline comparisons. Without these data it is impossible to verify whether the two proposed components are responsible for the claimed gains.
- [§3.2] §3.2 (Multi-View Adaptive Score Distillation Sampling): the description states that consistency and layout priors are 'distilled' by modulating attention maps of instance tokens and spatial tokens, but provides no derivation or pseudocode showing how the modulation is computed or how it differs from standard SDS. This leaves the precise mechanism and its parameter-free status unclear.
minor comments (2)
- [§3] Notation for the collision term and the attention-modulation operator should be defined once in a preliminary section rather than introduced inline.
- [Figures] Figure captions should explicitly state the number of views and the prompt used for each qualitative example.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below and will revise the manuscript to improve clarity and verifiability of our claims.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): the manuscript asserts that I2C-3D 'outperforms existing methods in generation quality and multi-view consistency' and produces 'high-fidelity' results, yet the abstract supplies no numerical metrics, ablation tables, or baseline comparisons. Without these data it is impossible to verify whether the two proposed components are responsible for the claimed gains.
Authors: We agree the abstract would be strengthened by including key quantitative results. Section 4 already contains baseline comparisons and ablation studies with metrics on generation quality and multi-view consistency that demonstrate the contribution of each proposed component. To address the concern directly, we will revise the abstract to report specific numerical improvements and ensure the ablation tables and metrics are prominently referenced in §4. revision: yes
-
Referee: [§3.2] §3.2 (Multi-View Adaptive Score Distillation Sampling): the description states that consistency and layout priors are 'distilled' by modulating attention maps of instance tokens and spatial tokens, but provides no derivation or pseudocode showing how the modulation is computed or how it differs from standard SDS. This leaves the precise mechanism and its parameter-free status unclear.
Authors: We will add a step-by-step derivation of the attention modulation and pseudocode to §3.2. The approach differs from standard SDS by adaptively modulating instance and spatial token attention maps across views to extract consistency and layout priors; it remains parameter-free because it operates solely on attention maps from the frozen pre-trained diffusion model without introducing additional parameters or training. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an optimization procedure that extracts priors from external pre-trained diffusion models via attention modulation and proposes two new guidance strategies (Inclusive Interactive Collisions and Multi-View Adaptive Score Distillation Sampling). No equations, fitted parameters renamed as predictions, or self-citation chains are present in the abstract or described method; the derivation relies on standard SDS-style distillation applied to external models rather than reducing to its own inputs by construction. The central claims therefore remain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2510.23306 (2025)
Chang, J., Ye, C., Wu, Y., Chen, Y., Zhang, Y., Luo, Z., Li, C., Zhi, Y., Han, X.: Reconviagen: Towards accurate multi-view 3d object reconstruction via generation. arXiv preprint arXiv:2510.23306 (2025)
arXiv 2025
-
[2]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, T., Ding, C., Zhang, S., Yu, C., Zang, Y., Li, Z., Peng, S., Sun, L.: Rapid 3d model generation with intuitive 3d input. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12554–12564 (2024)
2024
-
[3]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition
Chen, Y., Pan, Y., Yang, H., Yao, T., Mei, T.: Vp3d: Unleashing 2d visual prompt for text-to-3d generation. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. pp. 4896–4905 (2024)
2024
-
[5]
In: European Conference on Computer Vision
Chen, Y., Wang, T., Wu, T., Pan, X., Jia, K., Liu, Z.: Comboverse: Composi- tional 3d assets creation using spatially-aware diffusion guidance. In: European Conference on Computer Vision. pp. 128–146. Springer (2024)
2024
-
[6]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Chen, Z., Wang, F., Wang, Y., Liu, H.: Text-to-3d using gaussian splatting. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 21401–21412 (2024)
2024
-
[7]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Deitke, M., Schwenk, D., Salvador, J., Weihs, L., Michel, O., VanderBilt, E., Schmidt, L., Ehsani, K., Kembhavi, A., Farhadi, A.: Objaverse: A universe of annotated 3d objects. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 13142–13153 (2023)
2023
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Gao, G., Liu, W., Chen, A., Geiger, A., Sch¨ olkopf, B.: Graphdreamer: Composi- tional 3d scene synthesis from scene graphs. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21295–21304 (2024)
2024
-
[9]
In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition
Ge, C., Xu, C., Ji, Y., Peng, C., Tomizuka, M., Luo, P., Ding, M., Jampani, V., Zhan, W.: Compgs: Unleashing 2d compositionality for compositional text-to-3d via dynamically optimizing 3d gaussians. In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition. pp. 18509–18520 (2025) 16 C. Liu et al
2025
-
[10]
Guo, Y.C., Liu, Y.T., Shao, R., Laforte, C., Voleti, V., Luo, G., Chen, C.H., Zou, Z.X., Wang, C., Cao, Y.P., et al.: threestudio: A unified framework for 3d content generation (2023)
2023
-
[11]
arXiv preprint arXiv:2405.18525 (2024)
Han, H., Yang, R., Liao, H., Xing, J., Xu, Z., Yu, X., Zha, J., Li, X., Li, W.: Reparo: Compositional 3d assets generation with differentiable 3d layout alignment. arXiv preprint arXiv:2405.18525 (2024)
arXiv 2024
-
[12]
arXiv preprint arXiv:2311.04400 (2023)
Hong, Y., Zhang, K., Gu, J., Bi, S., Zhou, Y., Liu, D., Liu, F., Sunkavalli, K., Bui, T., Tan, H.: Lrm: Large reconstruction model for single image to 3d. arXiv preprint arXiv:2311.04400 (2023)
Pith/arXiv arXiv 2023
-
[13]
In: Advances in Neural Information Processing
Hu, T., Li, L., van de Weijer, J., Gao, H., Shahbaz Khan, F., Yang, J., Cheng, M.M., Wang, K., Wang, Y.: Token merging for training-free semantic binding in text-to-image synthesis. In: Advances in Neural Information Processing. vol. 37, pp. 137646–137672 (2024)
2024
-
[14]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, S., Wang, Z., Li, P., Jia, B., Liu, T., Zhu, Y., Liang, W., Zhu, S.C.: Diffusion-based generation, optimization, and planning in 3d scenes. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16750–16761 (2023)
2023
-
[15]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Huang, Z., Guo, Y.C., An, X., Yang, Y., Li, Y., Zou, Z.X., Liang, D., Liu, X., Cao, Y.P., Sheng, L.: Midi: Multi-instance diffusion for single image to 3d scene genera- tion. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 23646–23657 (2025)
2025
-
[16]
arXiv preprint arXiv:2506.15442 (2025)
Hunyuan3D, T., Yang, S., Yang, M., Feng, Y., Huang, X., Zhang, S., He, Z., Luo, D., Liu, H., Zhao, Y., et al.: Hunyuan3d 2.1: From images to high-fidelity 3d assets with production-ready pbr material. arXiv preprint arXiv:2506.15442 (2025)
Pith/arXiv arXiv 2025
-
[17]
ACM Trans
Kerbl, B., Kopanas, G., Leimk¨ uhler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023)
2023
-
[18]
In: Proceedings of the IEEE/CVF international conference on computer vision
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4015–4026 (2023)
2023
-
[19]
arXiv preprint arXiv:2311.06214 (2023)
Li, J., Tan, H., Zhang, K., Xu, Z., Luan, F., Xu, Y., Hong, Y., Sunkavalli, K., Shakhnarovich, G., Bi, S.: Instant3d: Fast text-to-3d with sparse-view generation and large reconstruction model. arXiv preprint arXiv:2311.06214 (2023)
arXiv 2023
-
[20]
In: International Joint Conference on Neural Networks (IJCNN2025) (2025)
Li, P., Sun, Y., Cheng, H.: Pointdico: Contrastive 3d representation learning guided by diffusion models. In: International Joint Conference on Neural Networks (IJCNN2025) (2025)
2025
-
[21]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, Y., Liu, H., Wu, Q., Mu, F., Yang, J., Gao, J., Li, C., Lee, Y.J.: Gligen: Open-set grounded text-to-image generation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 22511–22521 (2023)
2023
-
[22]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Lin, C.H., Gao, J., Tang, L., Takikawa, T., Zeng, X., Huang, X., Kreis, K., Fidler, S., Liu, M.Y., Lin, T.Y.: Magic3d: High-resolution text-to-3d content creation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 300–309 (2023)
2023
-
[23]
In: European Conference on Computer Vision
Liu, Y., Li, X., Li, X., Qi, L., Li, C., Yang, M.H.: Pyramid diffusion for fine 3d large scene generation. In: European Conference on Computer Vision. pp. 71–87. Springer (2024)
2024
-
[24]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Metzer, G., Richardson, E., Patashnik, O., Giryes, R., Cohen-Or, D.: Latent-nerf for shape-guided generation of 3d shapes and textures. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12663– 12673 (2023) I2C-3D 17
2023
-
[25]
Commu- nications of the ACM65(1), 99–106 (2021)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Commu- nications of the ACM65(1), 99–106 (2021)
2021
-
[26]
arXiv preprint arXiv:2209.14988 (2022)
Poole, B., Jain, A., Barron, J.T., Mildenhall, B.: Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988 (2022)
Pith/arXiv arXiv 2022
-
[27]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[28]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Rombach, et al.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 10684–10695 (2022)
2022
-
[29]
In: Advances in Neural Information Processing
Shen, T., Gao, J., Yin, K., Liu, M.Y., Fidler, S.: Deep marching tetrahedra: a hy- brid representation for high-resolution 3d shape synthesis. In: Advances in Neural Information Processing. vol. 34, pp. 6087–6101 (2021)
2021
-
[30]
arXiv preprint arXiv:2010.02502 (2020)
Song, et al.: Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020)
Pith/arXiv arXiv 2010
-
[31]
In: European Conference on Computer Vision
Tang, J., Chen, Z., Chen, X., Wang, T., Zeng, G., Liu, Z.: Lgm: Large multi-view gaussian model for high-resolution 3d content creation. In: European Conference on Computer Vision. pp. 1–18. Springer (2024)
2024
-
[32]
arXiv preprint arXiv:2605.07287 (2026)
Wan, Y., Li, F., Shao, M., Zuo, W.: Splatweaver: Learning to allocate gaussian primitives for generalizable novel view synthesis. arXiv preprint arXiv:2605.07287 (2026)
Pith/arXiv arXiv 2026
-
[33]
In: Proceedings of the Computer Vision and Pattern Recog- nition Conference
Wan, Y., Shao, M., Cheng, Y., Zuo, W.: S2gaussian: Sparse-view super-resolution 3d gaussian splatting. In: Proceedings of the Computer Vision and Pattern Recog- nition Conference. pp. 711–721 (2025)
2025
-
[34]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, H., Du, X., Li, J., Yeh, R.A., Shakhnarovich, G.: Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12619– 12629 (2023)
2023
-
[35]
In: Advances in Neural Information Processing
Wang, Z., Lu, C., Wang, Y., Bao, F., Li, C., Su, H., Zhu, J.: Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. In: Advances in Neural Information Processing. vol. 36, pp. 8406–8441 (2023)
2023
-
[36]
IEEE transactions on image processing 13(4), 600–612 (2004)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13(4), 600–612 (2004)
2004
-
[37]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wu, T., Yang, G., Li, Z., Zhang, K., Liu, Z., Guibas, L., Lin, D., Wetzstein, G.: Gpt- 4v (ision) is a human-aligned evaluator for text-to-3d generation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 22227–22238 (2024)
2024
-
[38]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: Structured 3d latents for scalable and versatile 3d generation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 21469–21480 (2025)
2025
-
[39]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Xie, J., Li, Y., Huang, Y., Liu, H., Zhang, W., Zheng, Y., Shou, M.Z.: Boxdiff: Text- to-image synthesis with training-free box-constrained diffusion. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 7452–7461 (2023)
2023
-
[40]
arXiv preprint arXiv:2404.07191 (2024) 18 C
Xu, J., Cheng, W., Gao, Y., Wang, X., Gao, S., Shan, Y.: Instantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruction models. arXiv preprint arXiv:2404.07191 (2024) 18 C. Liu et al
Pith/arXiv arXiv 2024
-
[41]
arXiv preprint arXiv:2410.09009 (2024)
Yang, L., Zhang, Z., Han, J., Zeng, B., Li, R., Torr, P., Zhang, W.: Semantic score distillation sampling for compositional text-to-3d generation. arXiv preprint arXiv:2410.09009 (2024)
arXiv 2024
-
[42]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yi, T., Fang, J., Wang, J., Wu, G., Xie, L., Zhang, X., Liu, W., Tian, Q., Wang, X.: Gaussiandreamer: Fast generation from text to 3d gaussians by bridging 2d and 3d diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6796–6807 (2024)
2024
-
[43]
arXiv preprint arXiv:2310.19415 (2023)
Yu, X., Guo, Y.C., Li, Y., Liang, D., Zhang, S.H., Qi, X.: Text-to-3d with classifier score distillation. arXiv preprint arXiv:2310.19415 (2023)
arXiv 2023
-
[45]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhang, Q., Wang, C., Siarohin, A., Zhuang, P., Xu, Y., Yang, C., Lin, D., Zhou, B., Tulyakov, S., Lee, H.Y.: Towards text-guided 3d scene composition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6829–6838 (2024)
2024
-
[46]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018)
2018
-
[47]
arXiv preprint arXiv:2605.03639 (2026)
Zhang*, Z., Sun*, Y., Fang, C., Cheng, H., Liu, J., Zhu, J., Mian, A.S.: Diffu- sion masked pretraining for dynamic point cloud. arXiv preprint arXiv:2605.03639 (2026)
Pith/arXiv arXiv 2026
-
[49]
arXiv preprint arXiv:2410.15391 (2024)
Zhou, J., Li, X., Qi, L., Yang, M.H.: Layout-your-3d: Controllable and precise 3d generation with 2d blueprint. arXiv preprint arXiv:2410.15391 (2024)
arXiv 2024
-
[50]
arXiv preprint arXiv:2402.07207 (2024)
Zhou, X., Ran, X., Xiong, Y., He, J., Lin, Z., Wang, Y., Sun, D., Yang, M.H.: Gala3d: Towards text-to-3d complex scene generation via layout-guided generative gaussian splatting. arXiv preprint arXiv:2402.07207 (2024)
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.