FreeStyle: Free Control of Style-Content Dual-Reference Generation from Community LoRA Mining
Pith reviewed 2026-06-26 17:56 UTC · model grok-4.3
The pith
Mining community LoRAs produces large-scale clean triplets that train models to balance style transfer and content preservation without leakage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
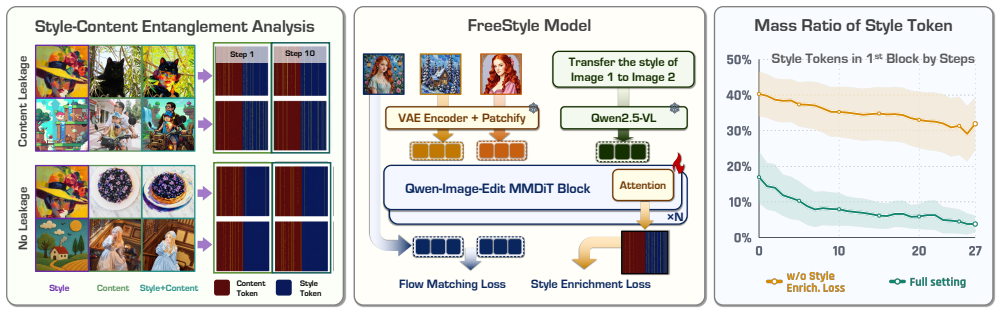
FreeStyle constructs large-scale Style-Reference and Content-Reference triplets by mining community LoRAs as compositional anchors and applying a rigorous generation and filtering pipeline across multiple base models. It trains with a two-stage curriculum that first applies an attention-level enrichment constraint to suppress style-reference leakage during style transfer, then uses frequency-aware RoPE modulation to address positional-correspondence leakage in the dual-reference stage. On a new benchmark that measures style similarity, content preservation, aesthetics, instruction following, and leakage via a calibrated VLM Rejection Score, the resulting model maintains a strong balance amon
What carries the argument
Community LoRA mining pipeline that turns shared adapters into style and content anchors, followed by attention-level enrichment constraint and frequency-aware RoPE modulation for stage-specific disentanglement.
If this is right
- Training data now covers long-tail styles that standard datasets miss.
- A single model can handle both single-reference style transfer and full dual-reference tasks.
- Leakage can be measured and reduced using a VLM-based Rejection Score alongside traditional metrics.
- The same mining approach works across different base diffusion models without retraining from scratch.
Where Pith is reading between the lines
- The same mining-plus-filtering idea could supply reference data for video or 3D generation if temporal or geometric LoRAs become available.
- Open model-sharing platforms effectively act as an implicit, continuously updated source of specialized training signals.
- If the disentanglement stages prove model-agnostic, they might transfer to other conditional generation settings that suffer from reference crosstalk.
Load-bearing premise
Community LoRAs can be treated as compositional anchors for style and content, and a generation-plus-filtering pipeline can produce large-scale triplets with clean content-style separation across multiple base models.
What would settle it
Run the triplet construction pipeline on a fresh collection of community LoRAs and check whether the filtered pairs still show measurable semantic leakage from the style reference into the content reference when used for training.
Figures



















read the original abstract
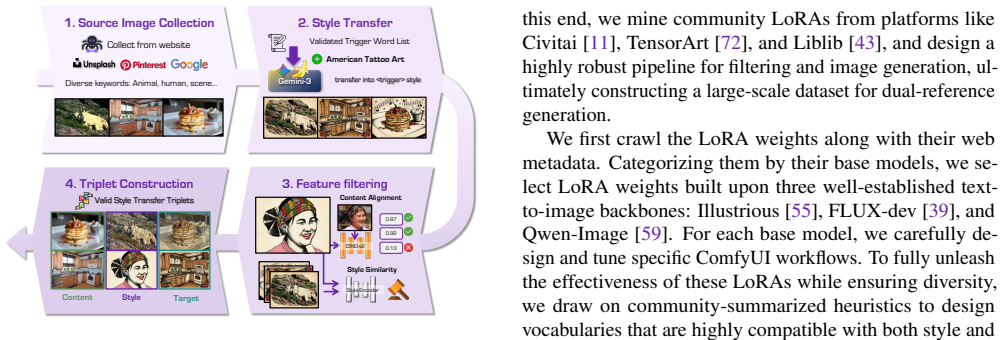
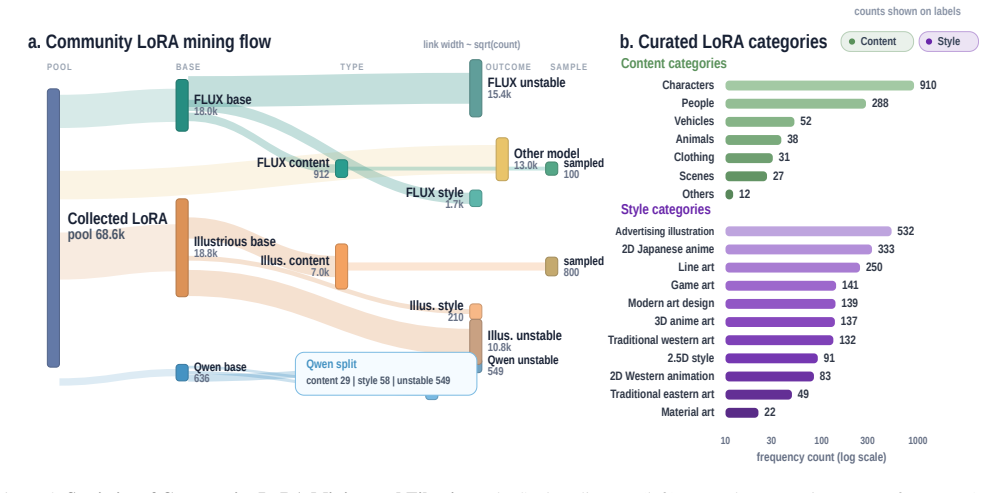
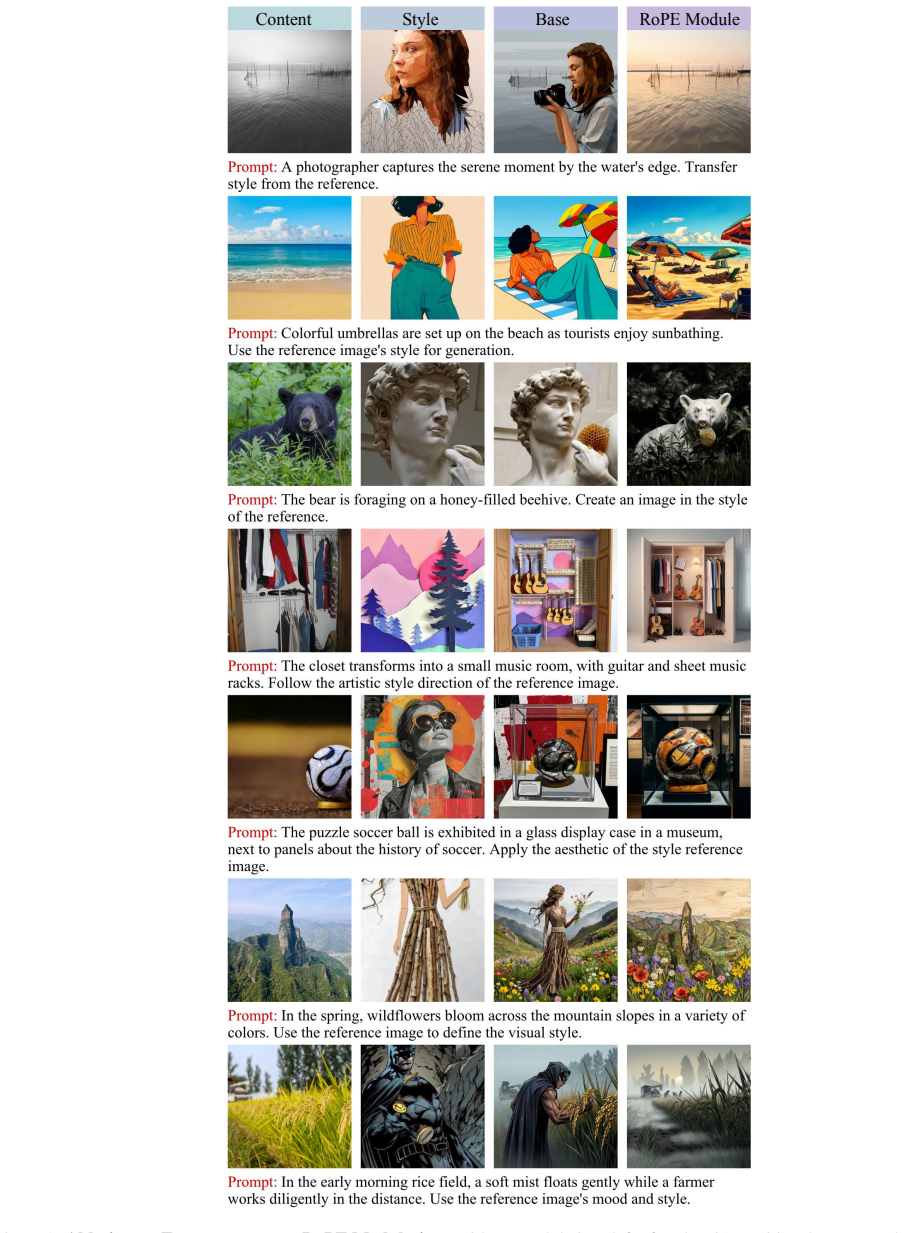
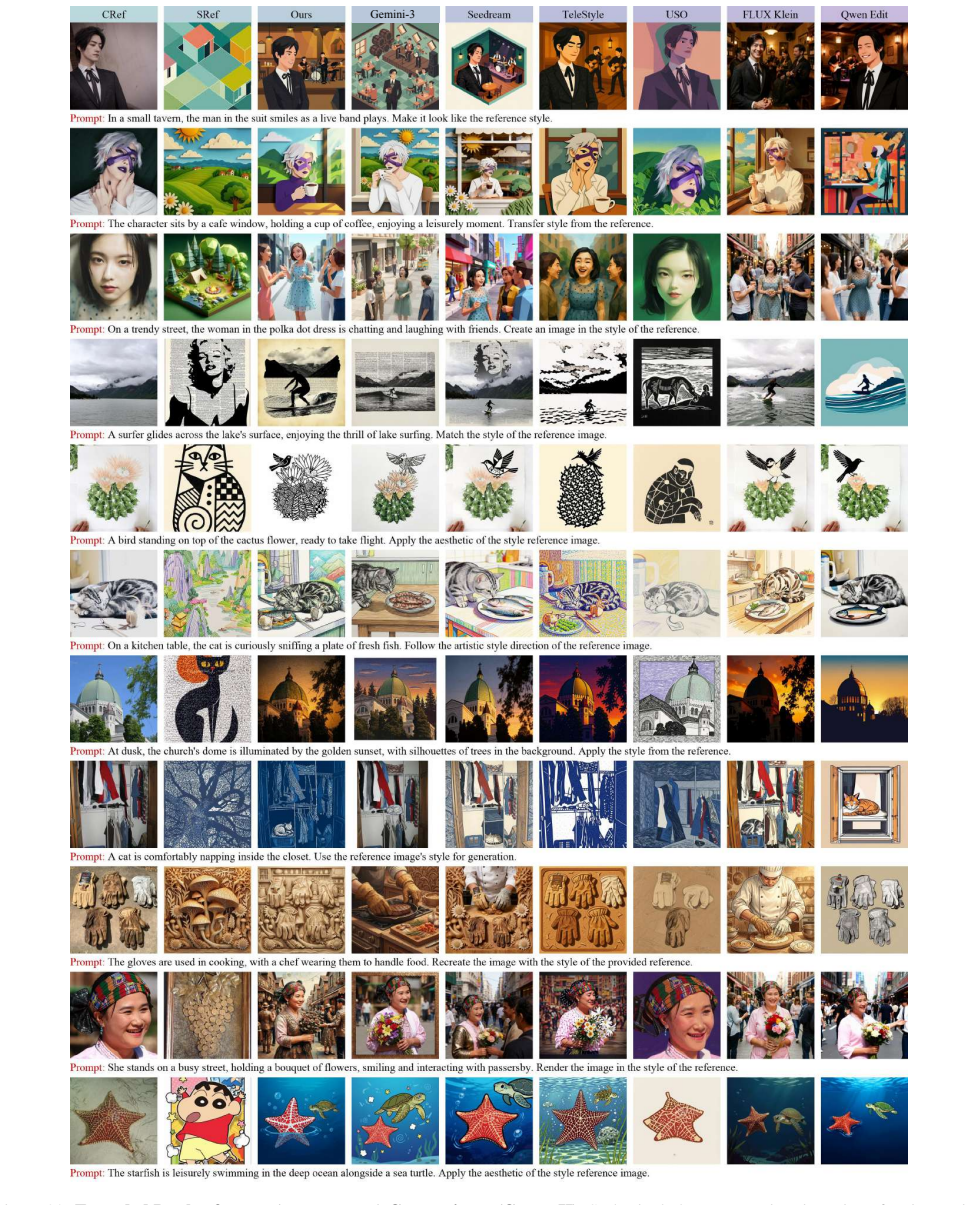
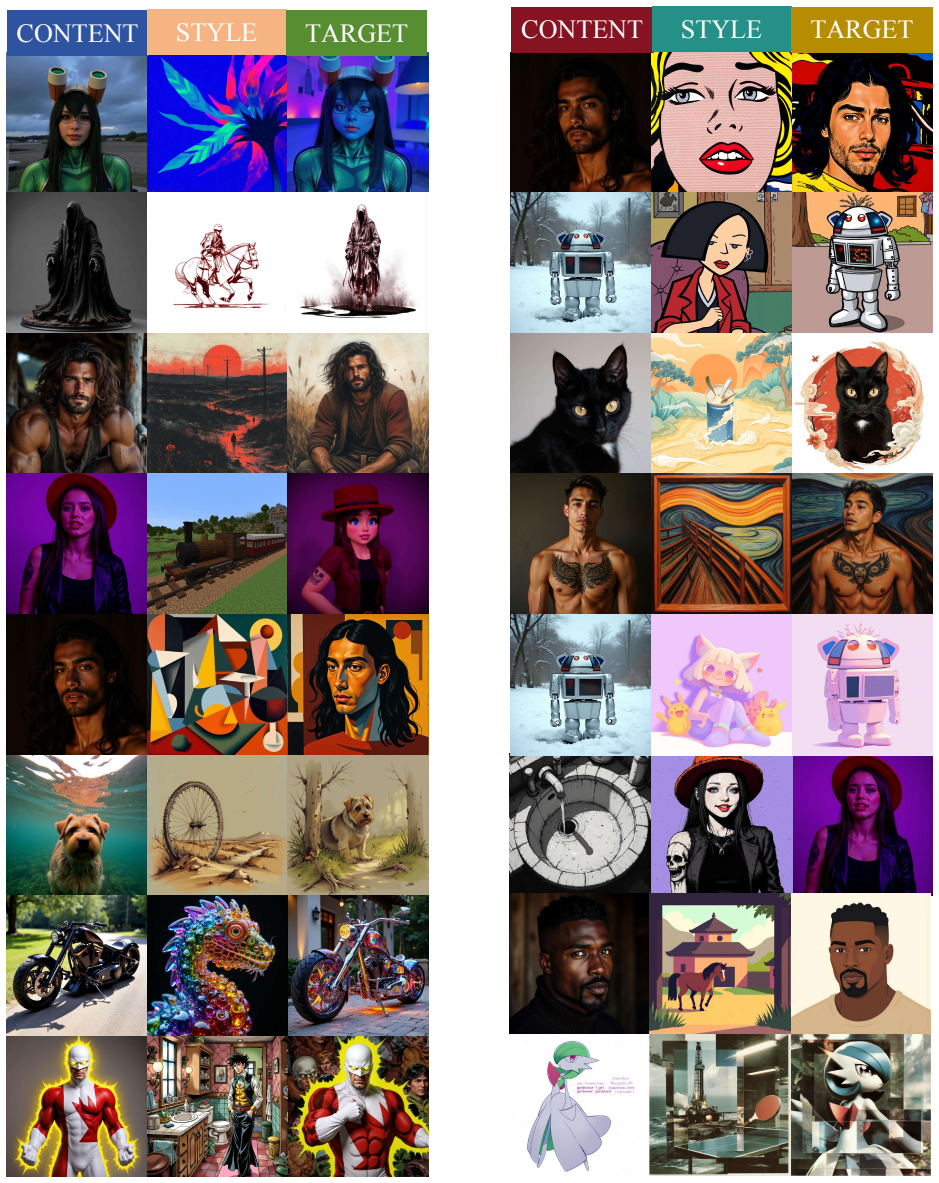
Style-content dual-reference generation aims to synthesize an image that preserves the structure and semantics of a content reference while adopting the style of a separate style reference.Despite recent progress, this setting remains challenging because models must balance content fidelity, style alignment, and instruction following avoiding semantic leakage from the style reference.A key bottleneck is the lack of large-scale triplet data with clean content-style separation and broad long-tail style coverage.In this work, we propose FreeStyle, a scalable dual-reference generation framework based on community LoRA mining.We treat community LoRAs as compositional anchors for style and content, and design a rigorous generation and filtering pipeline to construct large-scale Style-Reference and Content-Reference triplets across multiple base models.To address content leakage, we adopt a two-stage curriculum with stage-specific disentanglement mechanisms: an attention-level enrichment constraint that suppresses style-reference leakage in the style-transfer stage, and a frequency-aware RoPE modulation strategy that targets positional-correspondence-based leakage in the harder dual-reference stage.We also introduce a benchmark covering both style-reference and dual-reference generation, with evaluations on style similarity, content preservation, aesthetics, instruction following, and leakage rejection. The benchmark incorporates a style-invariant Content Alignment Score (CAS) and introduces a calibrated VLM-based Rejection Score for evaluating generation reliability and leakage suppression.Extensive experiments show that our model achieves a strong balance among style alignment, content preservation, and leakage suppression.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FreeStyle, a dual-reference generation framework that mines community LoRAs to construct large-scale style-content triplets via a generation-plus-filtering pipeline, applies a two-stage curriculum (attention enrichment constraint in style-transfer stage, frequency-aware RoPE in dual-reference stage) to suppress leakage, and releases a benchmark with style-invariant Content Alignment Score (CAS) and calibrated VLM-based Rejection Score. Extensive experiments are claimed to demonstrate balanced performance on style alignment, content preservation, leakage suppression, aesthetics, and instruction following across style-reference and dual-reference tasks.
Significance. If the quantitative results and pipeline validation hold, the work would be significant for addressing data scarcity in controllable generation through scalable community-resource mining and for introducing targeted disentanglement mechanisms plus new evaluation metrics (CAS, Rejection Score) that target leakage modes. The practical use of existing LoRAs for long-tail coverage is a concrete strength.
major comments (3)
- [§3.2] §3.2 (triplet construction pipeline): the claim that the generation-plus-filtering pipeline produces triplets with clean content-style separation is load-bearing for all downstream claims, yet no independent validation (e.g., separate human study or auxiliary classifier accuracy on held-out triplets) is reported; correctness is only inferred from final generation metrics.
- [§4] §4 (experimental results): the abstract and results section assert a 'strong balance' among style alignment, content preservation, and leakage suppression, but no numerical scores, error bars, statistical tests, or dataset statistics (number of triplets, base models, style diversity) are supplied, so the central empirical claim cannot be evaluated.
- [§4.3] §4.3 (ablation on disentanglement): the two-stage mechanisms (attention enrichment + frequency-aware RoPE) are presented as addressing specific leakage modes, but no ablation isolating each component's contribution to the Rejection Score or CAS is shown, leaving the necessity of the frequency modulation untested.
minor comments (2)
- [§3.3] Figure 3 caption and §3.3: the frequency bands used in RoPE modulation are not numerically specified (e.g., exact cutoff frequencies), making reproduction difficult.
- [§2] Related work section: several recent dual-reference papers using diffusion adapters are cited but the comparison table omits their reported leakage metrics, weakening the positioning of the new Rejection Score.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point-by-point below. Where the concerns are valid, we will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3.2] §3.2 (triplet construction pipeline): the claim that the generation-plus-filtering pipeline produces triplets with clean content-style separation is load-bearing for all downstream claims, yet no independent validation (e.g., separate human study or auxiliary classifier accuracy on held-out triplets) is reported; correctness is only inferred from final generation metrics.
Authors: We agree that independent validation of the triplet pipeline would strengthen the claims. The current manuscript infers triplet quality from downstream generation metrics after the described filtering steps in §3.2. In the revision we will add a human study on a held-out subset of triplets to directly measure content-style separation. revision: yes
-
Referee: [§4] §4 (experimental results): the abstract and results section assert a 'strong balance' among style alignment, content preservation, and leakage suppression, but no numerical scores, error bars, statistical tests, or dataset statistics (number of triplets, base models, style diversity) are supplied, so the central empirical claim cannot be evaluated.
Authors: The comment is correct: the submitted version does not supply explicit numerical scores, error bars, statistical tests, or dataset statistics in §4. We will revise the experimental section to include these details, with concrete metric values, error bars from repeated runs, significance tests, and statistics on triplet count, base models, and style diversity. revision: yes
-
Referee: [§4.3] §4.3 (ablation on disentanglement): the two-stage mechanisms (attention enrichment + frequency-aware RoPE) are presented as addressing specific leakage modes, but no ablation isolating each component's contribution to the Rejection Score or CAS is shown, leaving the necessity of the frequency modulation untested.
Authors: We acknowledge that the ablations in §4.3 do not isolate the contribution of each disentanglement component. We will add a new ablation study in the revision that evaluates variants with and without attention enrichment and frequency-aware RoPE, reporting effects on CAS and Rejection Score. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and available text describe a data pipeline (LoRA mining + generation + filtering) and two-stage disentanglement mechanisms without any equations, self-definitional claims, or load-bearing self-citations that reduce predictions to inputs by construction. No fitted parameters are renamed as predictions, and no uniqueness theorems or ansatzes are imported via self-citation. The central claims rest on empirical benchmarks and a new evaluation protocol (CAS, Rejection Score) that are presented as external to the pipeline itself. Per hard rules, absence of quotable reduction steps requires score 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
FirstName Alpher , title =
-
[2]
Journal of Foo , volume = 13, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe , title =. Journal of Foo , volume = 13, number = 1, pages =
-
[3]
Journal of Foo , volume = 14, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe and FirstName Gamow , title =. Journal of Foo , volume = 14, number = 1, pages =
-
[4]
FirstName Alpher and FirstName Gamow , title =
-
[5]
Computer Vision -- ECCV 2022 , year =
2022
-
[6]
Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization , author=
-
[7]
Universal Style Transfer via Feature Transforms , author=
-
[8]
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation , author=
-
[9]
LoRA: Low-Rank Adaptation of Large Language Models , author=
-
[10]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion , author=
-
[11]
arXiv preprint arXiv:2308.06721 , year=
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models , author=. arXiv preprint arXiv:2308.06721 , year=
-
[12]
Adding Conditional Control to Text-to-Image Diffusion Models , author=
-
[13]
StyleDrop: Text-to-Image Generation in Any Style , author=
-
[14]
2022 , howpublished =
2022
-
[15]
arXiv preprint arXiv:2404.02733 , year=
Instantstyle: Free lunch towards style-preserving in text-to-image generation , author=. arXiv preprint arXiv:2404.02733 , year=
-
[16]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Deadiff: An efficient stylization diffusion model with disentangled representations , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[17]
arXiv preprint arXiv:2408.16766 , year=
CSGO: Content-Style Composition in Text-to-Image Generation , author=. arXiv preprint arXiv:2408.16766 , year=
-
[18]
arXiv preprint arXiv:2602.20721 , year=
CleanStyle: Plug-and-Play Style Conditioning Purification for Text-to-Image Stylization , author=. arXiv preprint arXiv:2602.20721 , year=
-
[19]
arXiv preprint arXiv:2412.09618 , year=
EasyRef: Omni-Generalized Group Image Reference for Diffusion Models via Multimodal LLM , author=. arXiv preprint arXiv:2412.09618 , year=
-
[20]
arXiv preprint arXiv:2505.14028 , year=
OmniStyle: Filtering High Quality Style Transfer Data at Scale , author=. arXiv preprint arXiv:2505.14028 , year=
-
[21]
arXiv preprint arXiv:2601.20175 , year=
TeleStyle: Content-Preserving Style Transfer in Images and Videos , author=. arXiv preprint arXiv:2601.20175 , year=
-
[22]
arXiv preprint arXiv:2508.18966 , year=
USO: Unified Style and Subject-Driven Generation via Disentangled and Reward Learning , author=. arXiv preprint arXiv:2508.18966 , year=
-
[23]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Wang, Zihao and Wei, Yuxiang and Zhou, Xinpeng and Zhang, Tianyu and Liang, Tao and Bai, Yalong and Zhang, Hongzhi and Zuo, Wangmeng , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2026 , pages =
2026
-
[24]
arXiv preprint arXiv:2604.08364 , year=
MegaStyle: Constructing Diverse and Scalable Style Dataset via Consistent Text-to-Image Style Mapping , author=. arXiv preprint arXiv:2604.08364 , year=
-
[25]
GPT Image 1.5 , year =
-
[26]
Nano Banana Pro , year =
-
[27]
arXiv preprint arXiv:2508.02324 , year=
Qwen-Image Technical Report , author=. arXiv preprint arXiv:2508.02324 , year=
-
[28]
FLUX.2 [klein]: Towards Interactive Visual Intelligence , year =
-
[29]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[30]
arXiv preprint arXiv:2010.02502 , year=
Denoising diffusion implicit models , author=. arXiv preprint arXiv:2010.02502 , year=
Pith/arXiv arXiv 2010
-
[31]
Advances in neural information processing systems , volume=
Diffusion models beat gans on image synthesis , author=. Advances in neural information processing systems , volume=
-
[32]
arXiv preprint arXiv:2207.12598 , year=
Classifier-free diffusion guidance , author=. arXiv preprint arXiv:2207.12598 , year=
-
[33]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[34]
International Conference on Learning Representations , volume=
Sdxl: Improving latent diffusion models for high-resolution image synthesis , author=. International Conference on Learning Representations , volume=
-
[35]
arXiv preprint arXiv:2204.06125 , volume=
Hierarchical text-conditional image generation with clip latents , author=. arXiv preprint arXiv:2204.06125 , volume=
-
[36]
Advances in neural information processing systems , volume=
Photorealistic text-to-image diffusion models with deep language understanding , author=. Advances in neural information processing systems , volume=
-
[37]
arXiv preprint arXiv:2112.10741 , year=
Glide: Towards photorealistic image generation and editing with text-guided diffusion models , author=. arXiv preprint arXiv:2112.10741 , year=
-
[38]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Scalable diffusion models with transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[39]
Forty-first international conference on machine learning , year=
Scaling rectified flow transformers for high-resolution image synthesis , author=. Forty-first international conference on machine learning , year=
-
[40]
arXiv preprint arXiv:2210.02747 , year=
Flow matching for generative modeling , author=. arXiv preprint arXiv:2210.02747 , year=
-
[41]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow , author=
-
[42]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[43]
arXiv preprint arXiv:2010.11929 , year=
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
Pith/arXiv arXiv 2010
-
[44]
Neurocomputing , volume=
Roformer: Enhanced transformer with rotary position embedding , author=. Neurocomputing , volume=. 2024 , publisher=
2024
-
[45]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Image style transfer using convolutional neural networks , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[46]
European conference on computer vision , pages=
Perceptual losses for real-time style transfer and super-resolution , author=. European conference on computer vision , pages=. 2016 , organization=
2016
-
[47]
Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks , author=
-
[48]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
A style-based generator architecture for generative adversarial networks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[49]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[50]
arXiv preprint arXiv:2304.07193 , year=
Dinov2: Learning robust visual features without supervision , author=. arXiv preprint arXiv:2304.07193 , year=
-
[51]
arXiv preprint arXiv:2404.01292 , year=
Measuring style similarity in diffusion models , author=. arXiv preprint arXiv:2404.01292 , year=
-
[52]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
The unreasonable effectiveness of deep features as a perceptual metric , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[53]
Advances in neural information processing systems , volume=
Gans trained by a two time-scale update rule converge to a local nash equilibrium , author=. Advances in neural information processing systems , volume=
-
[54]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Multi-concept customization of text-to-image diffusion , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[55]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Instructpix2pix: Learning to follow image editing instructions , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[56]
The Eleventh International Conference on Learning Representations , year=
Prompt-to-Prompt Image Editing with Cross-Attention Control , author=. The Eleventh International Conference on Learning Representations , year=
-
[57]
2022 , url=
Chenlin Meng and Yutong He and Yang Song and Jiaming Song and Jiajun Wu and Jun-Yan Zhu and Stefano Ermon , booktitle=. 2022 , url=
2022
-
[58]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Style injection in diffusion: A training-free approach for adapting large-scale diffusion models for style transfer , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[59]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Visual Instruction Tuning , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[60]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[61]
arXiv preprint arXiv:2511.21631 , year=
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
-
[62]
2022 , url=
Christoph Schuhmann and Romain Beaumont and Richard Vencu and Cade W Gordon and Ross Wightman and Mehdi Cherti and Theo Coombes and Aarush Katta and Clayton Mullis and Mitchell Wortsman and Patrick Schramowski and Srivatsa R Kundurthy and Katherine Crowson and Ludwig Schmidt and Robert Kaczmarczyk and Jenia Jitsev , booktitle=. 2022 , url=
2022
-
[63]
Proceedings of the AAAI conference on artificial intelligence , volume=
T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[64]
arXiv preprint arXiv:2602.05013 , year=
Untwisting RoPE: Frequency Control for Shared Attention in DiTs , author=. arXiv preprint arXiv:2602.05013 , year=
-
[65]
arXiv preprint arXiv:1603.03417 , year=
Texture networks: Feed-forward synthesis of textures and stylized images , author=. arXiv preprint arXiv:1603.03417 , year=
-
[66]
International Conference on Learning Representations , year=
A Learned Representation For Artistic Style , author=. International Conference on Learning Representations , year=
-
[67]
arXiv preprint arXiv:1612.04337 , year=
Fast patch-based style transfer of arbitrary style , author=. arXiv preprint arXiv:1612.04337 , year=
-
[68]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep photo style transfer , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[69]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Avatar-net: Multi-scale zero-shot style transfer by feature decoration , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[70]
proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Arbitrary style transfer with style-attentional networks , author=. proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[71]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Artflow: Unbiased image style transfer via reversible neural flows , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[72]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Adaattn: Revisit attention mechanism in arbitrary neural style transfer , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[73]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Stytr2: Image style transfer with transformers , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[74]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Exact feature distribution matching for arbitrary style transfer and domain generalization , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[75]
European conference on computer vision , pages=
Ccpl: Contrastive coherence preserving loss for versatile style transfer , author=. European conference on computer vision , pages=. 2022 , organization=
2022
-
[76]
Advances in Neural Information Processing Systems , volume=
Artistic style transfer with internal-external learning and contrastive learning , author=. Advances in Neural Information Processing Systems , volume=
-
[77]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Photorealistic style transfer via wavelet transforms , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[78]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Learning linear transformations for fast image and video style transfer , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[79]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Style transfer by relaxed optimal transport and self-similarity , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[80]
arXiv preprint arXiv:2509.20427 , year=
Seedream 4.0: Toward next-generation multimodal image generation , author=. arXiv preprint arXiv:2509.20427 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.