X-LogSMask: Expand Transformer for Graph-Structured Data
Pith reviewed 2026-07-03 00:57 UTC · model grok-4.3
The pith
A multi-head logarithmic mask derived from the normalized adjacency matrix lets unmodified Transformers process graph data effectively.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
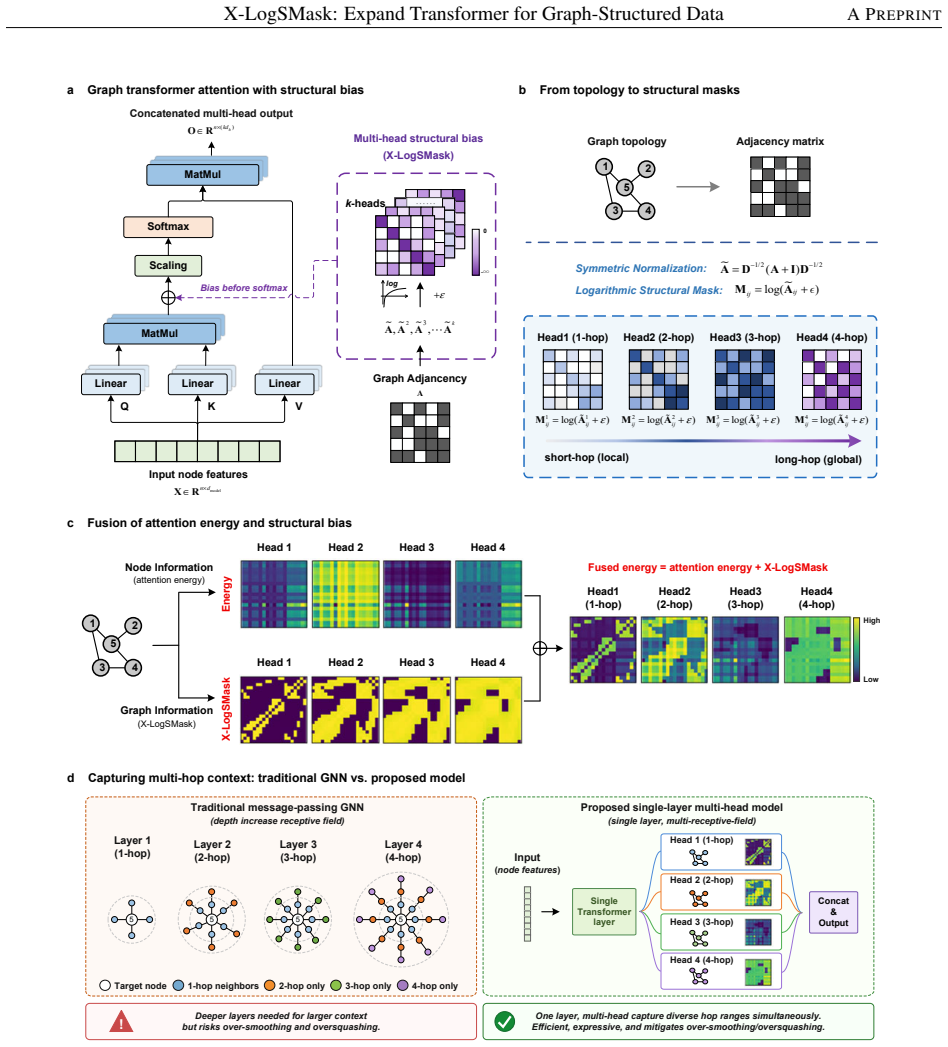
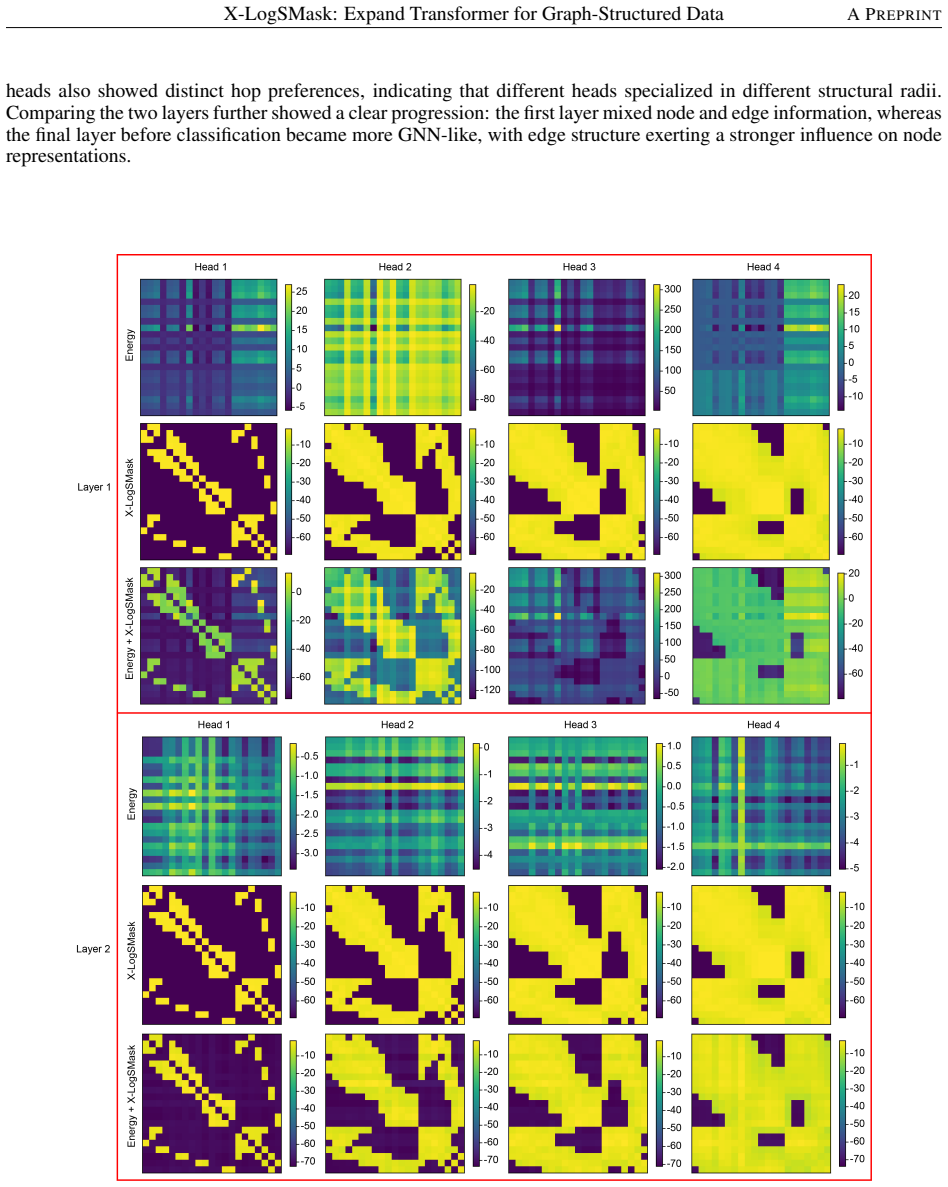
X-LogSMask converts the symmetrically normalized adjacency matrix into per-head logarithmic masks that are added directly to attention logits, thereby constraining self-attention to the graph's connectivity pattern, enabling multi-scale message passing within a single standard Transformer layer, and yielding state-of-the-art results on thirteen of twenty graph benchmarks without any change to the underlying architecture.
What carries the argument
X-LogSMask, the explainable multi-head logarithmic structural mask that adds log(A^k) terms (for different k) to the attention logits of each head, where A is the symmetrically normalized adjacency matrix.
If this is right
- A standard Transformer encoder can function as a one-layer multi-hop graph processor once the mask is applied.
- Different attention heads naturally acquire distinct receptive fields defined by the exponent on the adjacency matrix.
- Simple, fixed structural masks can replace learned attention constraints or hybrid message-passing modules.
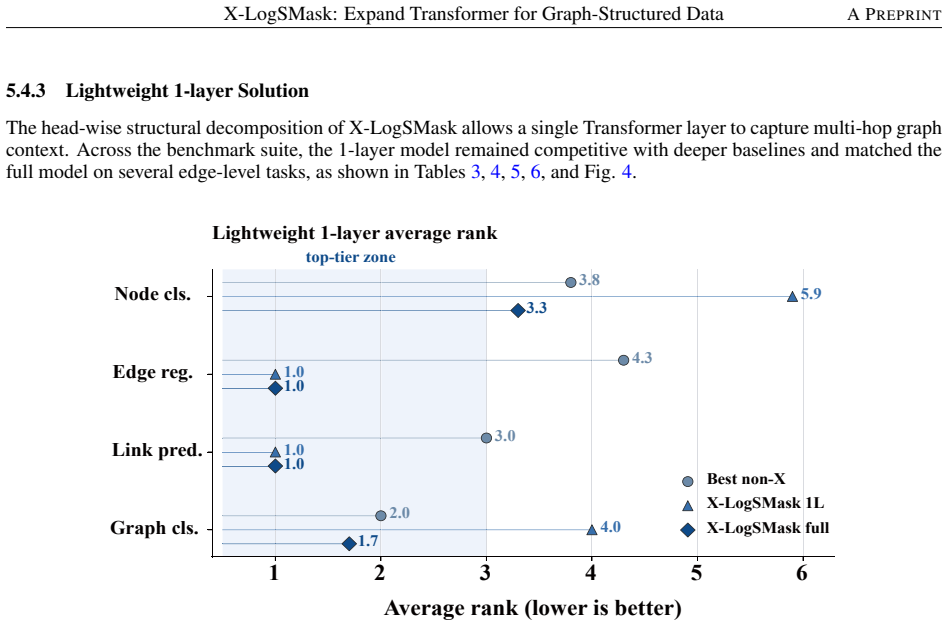
- Lightweight one-layer configurations remain competitive on node, edge and graph tasks.
Where Pith is reading between the lines
- The same log-based masking idea could be tested on other sparse relational structures such as trees or knowledge graphs.
- Performance differences may arise mainly from the fixed structural bias rather than the logarithmic scaling itself.
- The approach suggests that attention mechanisms can be made topology-aware by direct injection of adjacency information instead of architectural redesign.
Load-bearing premise
The logarithm of the symmetrically normalized adjacency matrix supplies an effective topology-aware gating signal that suppresses unsupported node interactions while preserving feature-dependent attention.
What would settle it
A graph benchmark in which a Transformer equipped with X-LogSMask produces lower accuracy than the identical model without the mask, or fails to reach competitive scores on a majority of new datasets drawn from the same task distribution.
Figures
read the original abstract
Transformers have become general-purpose architectures, but their all-to-all self-attention is poorly matched to graph data, whose interactions are sparse, structured and multi-scale. Existing Graph Transformers address this mismatch through structural encodings, hybrid message-passing modules or learned attention constraints, often introducing additional complexity and limited interpretability. Here we introduce X-LogSMask, an explainable multi-head logarithmic structural mask that injects symmetrically normalized graph topology directly into attention logits. The logarithmic transform converts structural connectivity into a topology-aware gating signal, suppressing unsupported node interactions while preserving feature-dependent attention. By assigning different powers of the normalized adjacency matrix to different attention heads, X-LogSMask gives each head a defined structural radius and supports multi-hop information propagation within a single layer. We further show that a standard Transformer encoder can be interpreted as one-step message passing on a complete graph, motivating X-LogSMask as a topology-constrained alternative to unrestricted self-attention. Across 20 node-, edge- and graph-level benchmarks, Transformers equipped with X-LogSMask achieve state-of-the-art performance on 13 datasets and remain competitive in a lightweight one-layer configuration. These results show that simple, interpretable structural masks can make self-attention an effective graph-learning operator without changing the Transformer architecture. The code is available at https://github.com/LiLeyan-0120/X-LogSMask.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces X-LogSMask, an explainable multi-head logarithmic structural mask derived from powers of the symmetrically normalized adjacency matrix. It injects graph topology directly into Transformer attention logits to provide topology-aware gating and multi-hop propagation within a single layer, while interpreting a standard Transformer encoder as one-step message passing on a complete graph. The central empirical claim is that Transformers equipped with this mask achieve state-of-the-art performance on 13 of 20 node-, edge-, and graph-level benchmarks and remain competitive even in a lightweight one-layer configuration. Code is released at a GitHub repository.
Significance. If the reported results hold under scrutiny, the work would indicate that a simple, interpretable structural mask can adapt self-attention to sparse graph structures without architectural modifications or hybrid message-passing modules, offering a lightweight alternative to existing Graph Transformers. The multi-head assignment of different adjacency powers and the open code release are strengths that support reproducibility and further analysis.
major comments (1)
- [Abstract] Abstract: The claim of state-of-the-art performance on 13 of 20 benchmarks is the central empirical contribution and is load-bearing for the paper's argument, yet the abstract supplies no experimental details such as dataset splits, baselines, metrics, error bars, or ablation results; without these, the data cannot be verified to support the claim.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the manuscript. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of state-of-the-art performance on 13 of 20 benchmarks is the central empirical contribution and is load-bearing for the paper's argument, yet the abstract supplies no experimental details such as dataset splits, baselines, metrics, error bars, or ablation results; without these, the data cannot be verified to support the claim.
Authors: We agree that the abstract would benefit from additional context to support the central claim. While the full experimental protocol—including standard dataset splits, baselines, metrics, error bars from multiple runs, and ablation studies—is detailed in Section 4 and the appendix, we will revise the abstract to briefly reference the evaluation setup (e.g., 20 benchmarks across node/edge/graph tasks, standard splits, and reporting of means with standard deviations). revision: yes
Circularity Check
No significant circularity
full rationale
The paper defines X-LogSMask explicitly from the input graph's symmetrically normalized adjacency matrix (via log transform and per-head powers), then applies it as a fixed structural gate inside standard attention logits. This is a direct construction from external topology rather than a fitted quantity or self-referential prediction. No equations, uniqueness theorems, or self-citations are shown that would reduce the reported benchmark results to the mask definition by construction. The contribution is an architectural proposal validated empirically on 20 external datasets; the derivation chain remains self-contained against those benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A standard Transformer encoder can be interpreted as one-step message passing on a complete graph
invented entities (1)
-
X-LogSMask
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Semi-supervised classification with graph convolutional networks
Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. InIn- ternational Conference on Learning Representations, 2017. URLhttps://openreview.net/forum?id= SJU4ayYgl
2017
-
[2]
How powerful are graph neural networks? In International Conference on Learning Representations, 2019
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? In International Conference on Learning Representations, 2019
2019
-
[3]
Attention is all you need.Advances in Neural Information Processing Systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[4]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4171–4186. Associa- 15 X-LogSMask: Expand Transformer for...
-
[5]
Language models are few-shot learners.Advances in Neural Information Processing Systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Nee- lakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in Neural Information Processing Systems, 33:1877–1901, 2020
1901
-
[6]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021. URLhttps://openreview.net/forum?id=YicbFdNTTy
2021
-
[7]
Informer: Beyond efficient transformer for long sequence time-series forecasting
Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianbin Li, Hui Xiong, and Wancai Wang. Informer: Beyond efficient transformer for long sequence time-series forecasting. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 11106–11115, 2021
2021
-
[8]
Ast: Audio spectrogram transformer
Yuan Gong, Yu-An Chung, and James Glass. Ast: Audio spectrogram transformer. InProceedings of Interspeech 2021, pages 571–575, 2021. doi: 10.21437/Interspeech.2021-698
-
[9]
Graph attention networks
Petar Veli ˇckovi´c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Li`o, and Yoshua Bengio. Graph attention networks. InInternational Conference on Learning Representations, 2018
2018
-
[10]
Trans- gnn: Harnessing the collaborative power of transformers and graph neural networks for recommender systems
Peiyan Zhang, Yuchen Yan, Xi Zhang, Chaozhuo Li, Senzhang Wang, Feiran Huang, and Sunghun Kim. Trans- gnn: Harnessing the collaborative power of transformers and graph neural networks for recommender systems. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1285–1295, 2024
2024
-
[11]
Recipe for a general, powerful, scalable graph transformer
Ladislav Ramp ´aˇsek, Mikhail Galkin, Vijay Prakash Dwivedi, Anh Tuan Luu, Guy Wolf, and Dominique Beaini. Recipe for a general, powerful, scalable graph transformer. InAdvances in Neural Information Processing Systems, volume 35, 2022
2022
-
[12]
Do transformers really perform bad for graph representation? InAdvances in Neural Information Processing Systems, volume 34, pages 28877–28888, 2021
Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, and Tie-Yan Liu. Do transformers really perform bad for graph representation? InAdvances in Neural Information Processing Systems, volume 34, pages 28877–28888, 2021
2021
-
[13]
Gradformer: Graph transformer with exponential decay
Chuang Liu, Zelin Yao, Yibing Zhan, Xueqi Ma, Shirui Pan, and Wenbin Hu. Gradformer: Graph transformer with exponential decay. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelli- gence, pages 2171–2179, 2024. doi: 10.24963/ijcai.2024/240
-
[14]
Graph transformers without positional encodings.arXiv preprint arXiv:2401.17791, 2024
Ayush Garg. Graph transformers without positional encodings.arXiv preprint arXiv:2401.17791, 2024
-
[15]
Collective classification in network data.AI Magazine, 29(3):93–93, 2008
Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi-Rad. Collective classification in network data.AI Magazine, 29(3):93–93, 2008
2008
-
[16]
Pitfalls of Graph Neural Network Evaluation
Oleksandr Shchur, Maximilian Mumme, Aleksandar Bojchevski, and Stephan G ¨unnemann. Pitfalls of graph neural network evaluation.arXiv preprint arXiv:1811.05868, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[17]
Wiki-cs: A wikipedia-based benchmark for graph neural networks,
P ´eter Mernyei and C ˘at˘alina Cangea. Wiki-cs: A wikipedia-based benchmark for graph neural networks.arXiv preprint arXiv:2007.02901, 2020
-
[18]
Classic gnns are strong baselines: Reassessing gnns for node classi- fication
Yuankai Luo, Lei Shi, and Xiao-Ming Wu. Classic gnns are strong baselines: Reassessing gnns for node classi- fication. InAdvances in Neural Information Processing Systems, 2024
2024
-
[19]
Inductive representation learning on large graphs
William L Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. In Advances in Neural Information Processing Systems, volume 30, 2017
2017
-
[20]
Sgformer: Simplifying and empowering transformers for large-graph representations
Qitian Wu, Wentao Zhao, Chenxiao Yang, Hengrui Zhang, Fan Nie, Haitian Jiang, Yatao Bian, and Junchi Yan. Sgformer: Simplifying and empowering transformers for large-graph representations. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[21]
Polynormer: Polynomial-expressive graph transformer in linear time
Chenhui Deng, Zichao Yue, and Zhiru Zhang. Polynormer: Polynomial-expressive graph transformer in linear time. InInternational Conference on Learning Representations, 2024
2024
-
[22]
Bayan Bruss, and Tom Goldstein
Kezhi Kong, Jiuhai Chen, John Kirchenbauer, Renkun Ni, C. Bayan Bruss, and Tom Goldstein. Goat: A global transformer on large-scale graphs. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 17375–17390. PMLR, 2023
2023
-
[23]
Nodeformer: A scalable graph structure learning transformer for node classification
Qitian Wu, Wentao Zhao, Zenan Li, David Wipf, and Junchi Yan. Nodeformer: A scalable graph structure learning transformer for node classification. InAdvances in Neural Information Processing Systems, volume 35, 2022
2022
-
[24]
Nagphormer: A tokenized graph transformer for node classification in large graphs
Jinsong Chen, Kaiyuan Gao, Gaichao Li, and Kun He. Nagphormer: A tokenized graph transformer for node classification in large graphs. InInternational Conference on Learning Representations, 2023. 16 X-LogSMask: Expand Transformer for Graph-Structured DataA PREPRINT
2023
-
[25]
Sutherland, and Ali Kemal Sinop
Hamed Shirzad, Ameya Velingker, Balaji Venkatachalam, Danica J. Sutherland, and Ali Kemal Sinop. Ex- phormer: Sparse transformers for graphs. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 31613–31632, 2023
2023
-
[26]
Benchmarking edge regression on temporal net- works.Journal of Data-centric Machine Learning Research, 2024
Muberra Ozmen, Florence Regol, and Thomas Markovich. Benchmarking edge regression on temporal net- works.Journal of Data-centric Machine Learning Research, 2024. URLhttps://openreview.net/forum? id=4k4cocpuSw
2024
-
[27]
Link prediction based on graph neural networks
Muhan Zhang and Yixin Chen. Link prediction based on graph neural networks. InAdvances in Neural Infor- mation Processing Systems, volume 31, 2018
2018
-
[28]
Seongjun Yun, Seoyoon Kim, Junhyun Lee, Jaewoo Kang, and Hyunwoo J. Kim. Neo-gnns: Neighborhood overlap-aware graph neural networks for link prediction. InAdvances in Neural Information Processing Systems, volume 34, pages 13683–13694, 2021
2021
-
[29]
Bronstein, and Max Hansmire
Benjamin Paul Chamberlain, Sergey Shirobokov, Emanuele Rossi, Fabrizio Frasca, Thomas Markovich, Nils Yannick Hammerla, Michael M. Bronstein, and Max Hansmire. Graph neural networks for link predic- tion with subgraph sketching. InInternational Conference on Learning Representations, 2023
2023
-
[30]
Neural common neighbor with completion for link prediction
Xiyuan Wang, Haotong Yang, and Muhan Zhang. Neural common neighbor with completion for link prediction. InInternational Conference on Learning Representations, 2024
2024
-
[31]
Lpformer: An adaptive graph transformer for link prediction
Harry Shomer, Yao Ma, Haitao Mao, Juanhui Li, Bo Wu, and Jiliang Tang. Lpformer: An adaptive graph transformer for link prediction. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD ’24, page 2686–2698. ACM, August 2024. doi: 10.1145/3637528.3672025. URL http://dx.doi.org/10.1145/3637528.3672025
-
[32]
Tu- dataset: A collection of benchmark datasets for learning with graphs
Christopher Morris, Nils M Kriege, Frank Bause, Kristian Kersting, Petra Mutzel, and Marion Neumann. Tu- dataset: A collection of benchmark datasets for learning with graphs. 2020. URLwww.graphlearning.io
2020
-
[33]
Open graph benchmark: Datasets for machine learning on graphs
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs. InAdvances in Neural Information Processing Systems, volume 33, 2020
2020
-
[34]
Xavier Bresson and Thomas Laurent. Residual gated graph convnets.arXiv preprint arXiv:1711.07553, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[35]
A generalization of transformer networks to graphs
Vijay Prakash Dwivedi and Xavier Bresson. A generalization of transformer networks to graphs. InAAAI Workshop on Deep Learning on Graphs: Methods and Applications, 2021
2021
-
[36]
Hamilton, Vincent L´etourneau, and Prudencio Tossou
Devin Kreuzer, Dominique Beaini, William L. Hamilton, Vincent L´etourneau, and Prudencio Tossou. Rethinking graph transformers with spectral attention. InAdvances in Neural Information Processing Systems, volume 34, 2021
2021
-
[37]
Graph transformer for graph-to-sequence learning
Deng Cai and Wai Lam. Graph transformer for graph-to-sequence learning. InProceedings of the AAAI Confer- ence on Artificial Intelligence, volume 34, pages 7464–7471, 2020. doi: 10.1609/aaai.v34i05.6243
-
[38]
Accurate learning of graph representations with graph multiset pooling
Jinheon Baek, Minki Kang, and Sung Ju Hwang. Accurate learning of graph representations with graph multiset pooling. InInternational Conference on Learning Representations, 2021
2021
-
[39]
Structure-aware transformer for graph representation learning
Dexiong Chen, Leslie O’Bray, and Karsten Borgwardt. Structure-aware transformer for graph representation learning. InProceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, pages 3469–3489, 2022. 17
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.