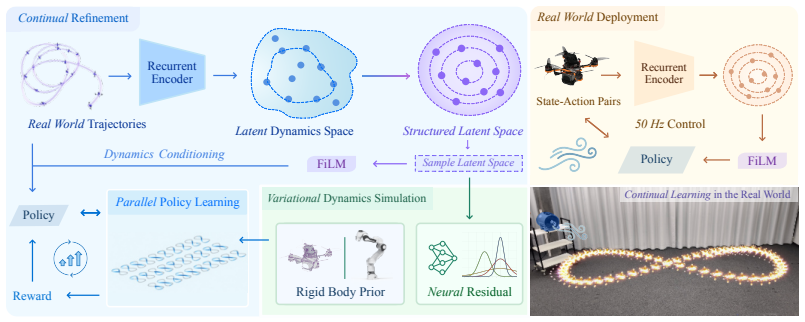
Continual Robot Policy Learning via Variational Neural Dynamics
Pith reviewed 2026-06-26 04:26 UTC · model grok-4.3
The pith
A variational dynamics model lets robot policies recover from recurring disturbances like wind changes by inferring hidden conditions online instead of re-fitting residuals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
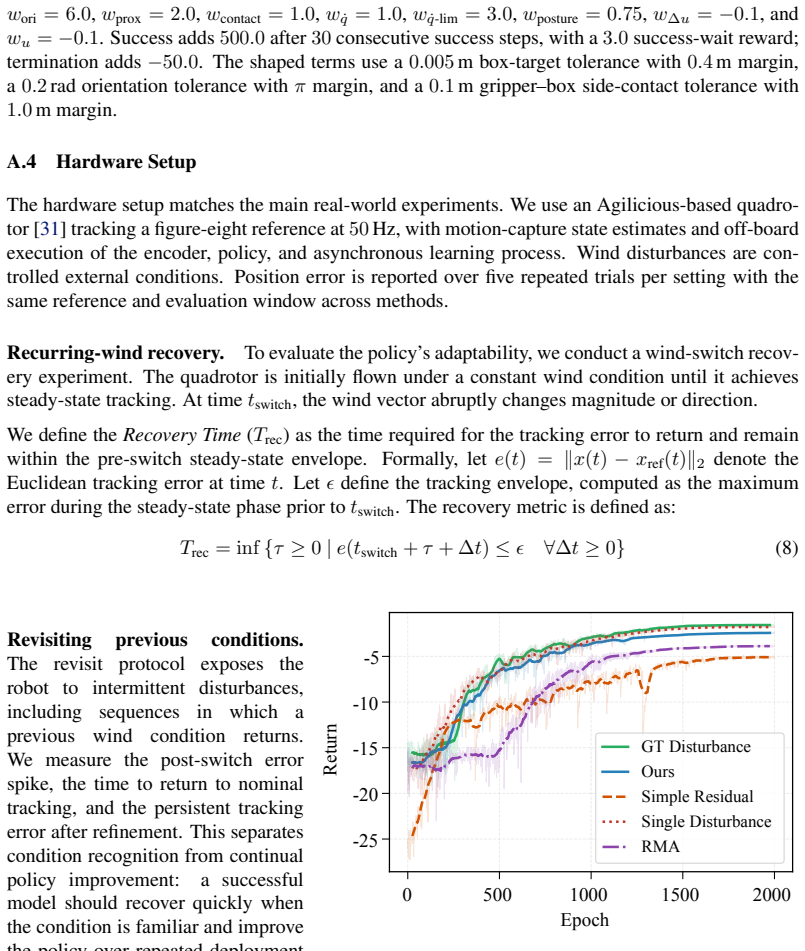
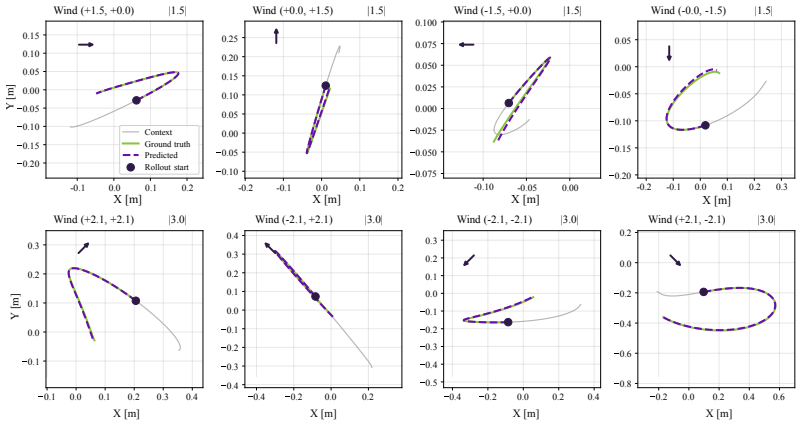
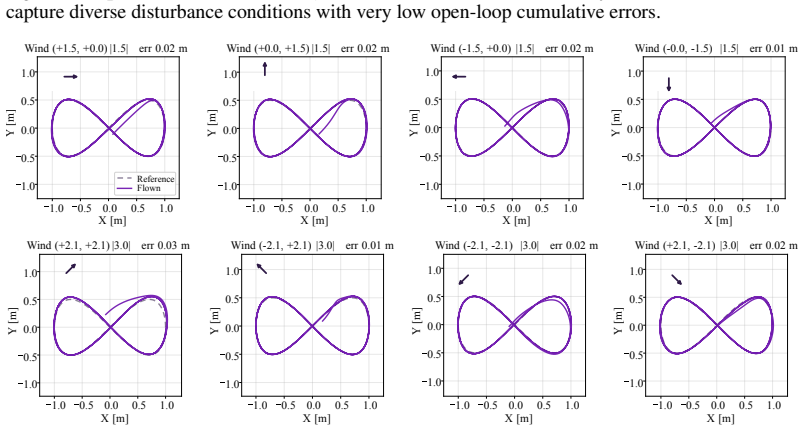
By training a policy on dynamics sampled from a variational model whose latent conditions are inferred online by a recurrent encoder, the robot can adapt to recurring hidden dynamics through recognition rather than residual re-fitting, yielding recovery times around one second and error reductions of 65.7 percent in hover and 53.3 percent in tracking on real quadrotors under changing wind.
What carries the argument
A variational neural dynamics model that fuses an analytical physics prior with a neural residual and conditions both the residual and the policy on a latent state inferred by a recurrent encoder from recent trajectories.
If this is right
- Policies recover from recurring disturbances in roughly one second on real quadrotors under changing wind.
- Large-disturbance hover errors drop by 65.7 percent and tracking errors by 53.3 percent versus state-of-the-art online adaptation.
- Policy learning proceeds by sampling diverse conditions from the latent model inside differentiable simulation.
- At deployment, real-time encoder outputs replace sampled conditions to enable fast recognition of known dynamics.
Where Pith is reading between the lines
- The same encoder-based inference could be tested on ground robots facing recurring terrain or payload shifts.
- If the separation between prior and residual holds, the method might reduce the frequency of full policy retraining in long deployments.
- Combining the latent condition with other adaptation signals such as visual cues could be examined as an extension.
- The approach suggests a route for continual learning on platforms where dynamics recur but are not fully observable from single steps.
Load-bearing premise
The framework assumes recurring hidden dynamics can be reliably inferred online from short recent interaction histories via the recurrent encoder without significant interference or mode collapse between the physics prior and neural residual.
What would settle it
If recovery time from recurring wind disturbances on the quadrotor equals or exceeds the time required by online residual re-fitting, the advantage of inference-based adaptation would be falsified.
Figures
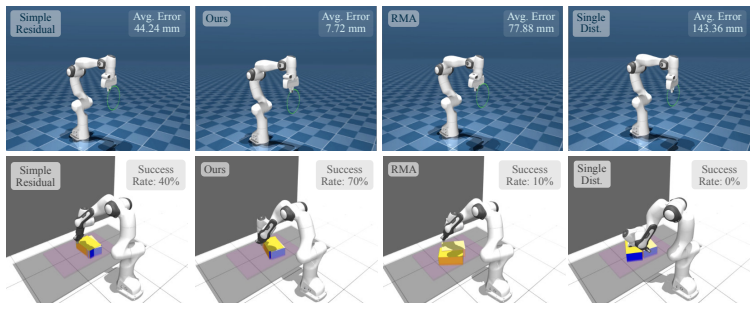
read the original abstract
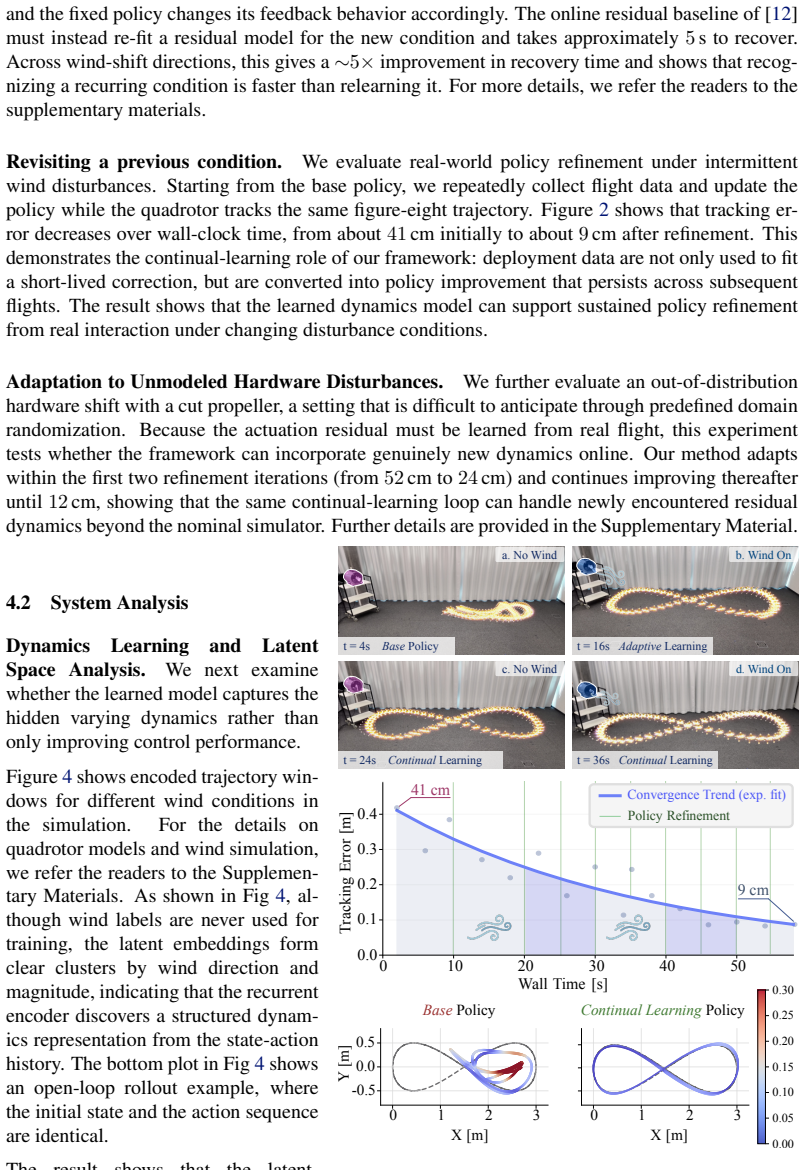
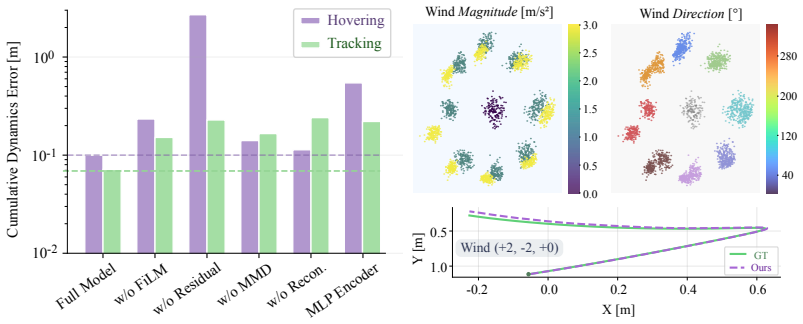
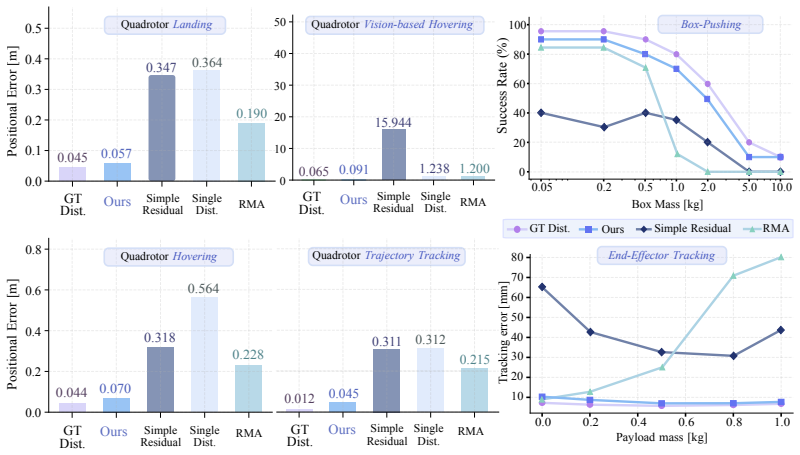
Robots deployed in the real world rarely operate under a single fixed dynamics model: wind changes, payloads vary, batteries drain, contacts shift, and hardware wears. Yet most learning-based controllers are trained once and deployed as if learning were complete. This prevents the robot from using deployment experience to further improve task performance. In this work, we propose a continual learning framework that uses real-world experience to improve robot policies under hidden and recurring dynamics. Our method learns a condition-aware dynamics model from real state-action trajectories by combining an analytical physics prior with a neural residual for unmodeled effects. A recurrent encoder infers the current hidden condition from recent interaction, and this estimate conditions both the residual model and the policy. Policy learning is performed via differentiable simulation using diverse learned dynamics sampled from the latent model. At deployment, these sampled conditions are replaced by conditions inferred online from recent real interaction, allowing the policy to recover recurring dynamics by recognition rather than residual re-fitting. Through extensive simulation studies and real-world experiments, we demonstrate that the framework improves policy performance under diverse unobserved disturbances. On real quadrotor trajectory tracking under changing wind, the policy recovers from recurring disturbances in roughly 1s, about 5x faster than online residual re-fitting. It also reduces large-disturbance hover and tracking errors by 65.7% and 53.3% over the state-of-the-art online adaptation approaches
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a continual learning framework for robot policies under hidden recurring dynamics. It learns a condition-aware dynamics model by combining an analytical physics prior with a neural residual, uses a recurrent encoder to infer the current hidden condition from recent state-action trajectories, and conditions both the residual and the policy on this latent estimate. Policy learning occurs via differentiable simulation sampling diverse conditions from the variational model; at deployment, online-inferred conditions replace sampling to enable recognition-based recovery rather than residual re-fitting. Real quadrotor experiments under changing wind report ~1s recovery (5x faster than online residual re-fitting) and 65.7%/53.3% reductions in large-disturbance hover/tracking errors versus SOTA online adaptation methods.
Significance. If the central claims hold, the framework provides a practical route to continual policy improvement in real-world robotics by leveraging variational inference for condition recognition instead of repeated adaptation. Strengths include the hybrid analytical-neural model, differentiable simulation for policy optimization, and demonstration on physical hardware with recurring disturbances. This could influence adaptive control and lifelong learning in robotics if the inference step proves robust.
major comments (1)
- [recurrent encoder and online inference procedure (Section 3)] The headline performance claims (1s recovery, 5x speedup, 65.7% and 53.3% error reductions) rest on the recurrent encoder reliably extracting a usable latent condition from short recent histories without mode collapse or leakage into the analytical prior. No quantitative evaluation of inference accuracy, latent disentanglement, or robustness to sensor noise is reported, which is load-bearing for the advantage over residual re-fitting.
minor comments (1)
- Notation for the variational posterior and the conditioning mechanism could be clarified with an explicit diagram or additional equations showing how the latent sample is injected into the residual and policy.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below and will incorporate revisions to strengthen the paper.
read point-by-point responses
-
Referee: [recurrent encoder and online inference procedure (Section 3)] The headline performance claims (1s recovery, 5x speedup, 65.7% and 53.3% error reductions) rest on the recurrent encoder reliably extracting a usable latent condition from short recent histories without mode collapse or leakage into the analytical prior. No quantitative evaluation of inference accuracy, latent disentanglement, or robustness to sensor noise is reported, which is load-bearing for the advantage over residual re-fitting.
Authors: We agree that the reported performance advantages depend on the recurrent encoder's ability to perform reliable online inference. While the end-to-end simulation and hardware results provide indirect support through task-level metrics, we acknowledge the value of direct quantitative analysis. In the revised manuscript, we will add: (i) inference accuracy metrics on trajectories with known ground-truth conditions in simulation, (ii) quantitative measures of latent disentanglement (e.g., mutual information or correlation analysis between latent dimensions and condition parameters), and (iii) robustness evaluations under injected sensor noise. These additions will directly substantiate the claims regarding the inference procedure's contribution to faster recovery versus residual re-fitting. revision: yes
Circularity Check
No significant circularity; performance claims rest on external experimental comparisons
full rationale
The paper's core claims concern empirical recovery speed and error reductions on real quadrotor hardware under wind disturbances, benchmarked against online residual re-fitting and state-of-the-art adaptation methods. The framework description (analytical prior + neural residual, recurrent encoder for latent condition, differentiable simulation for policy training) introduces no self-definitional loops, no fitted parameters renamed as predictions, and no load-bearing self-citations that substitute for independent verification. All reported metrics derive from held-out real trajectories and baseline comparisons rather than algebraic reduction to the model's own fitted values. This is the normal non-circular outcome for an experimental robotics paper whose central results are falsifiable outside its training loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Kaufmann, L
E. Kaufmann, L. Bauersfeld, A. Loquercio, M. M ¨uller, V . Koltun, and D. Scaramuzza. Champion-level drone racing using deep reinforcement learning.Nature, 620(7976):982–987, Aug 2023. ISSN 1476-4687
2023
-
[2]
Geles, L
I. Geles, L. Bauersfeld, A. Romero, J. Xing, and D. Scaramuzza. Demonstrating agile flight from pixels without state estimation.Robotics: Science and Systems, 2024
2024
-
[3]
J. Xing, I. Geles, E. Aljalbout, and D. Scaramuzza. Multi-task reinforcement learning for quadrotor control.IEEE Robotics and Automation Letters, 9(10), 2024
2024
-
[4]
T. Miki, J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter. Learning robust per- ceptive locomotion for quadrupedal robots in the wild.Science Robotics, 7(62), 2022
2022
-
[5]
J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter. Learning quadrupedal locomo- tion over challenging terrain.Science Robotics, 5(47), 2020
2020
-
[6]
C. Chi, Z. Xu, S. Feng, et al. Diffusion policy: Visuomotor policy learning via action diffusion. International Journal of Robotics Research, 2025
2025
-
[7]
Aljalbout, J
E. Aljalbout, J. Xing, A. Romero, I. Akinola, C. R. Garrett, E. Heiden, A. Gupta, T. Hermans, Y . Narang, D. Fox, et al. The reality gap in robotics: Challenges, solutions, and best practices. Annual Review of Control, Robotics, and Autonomous Systems, 9, 2025
2025
-
[8]
Tobin, R
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. InProc. IROS, 2017
2017
-
[9]
Y . Ren, Z. Zhu, J. Xing, and D. Scaramuzza. Learning agile quadrotor flight in the real world. InarXiv Preprint, 2026
2026
-
[10]
Hwangbo, J
J. Hwangbo, J. Lee, A. Dosovitskiy, et al. Learning agile and dynamic motor skills for legged robots.Science Robotics, 4(26), 2019
2019
-
[11]
Bauersfeld, E
L. Bauersfeld, E. Kaufmann, P. Foehn, S. Sun, and D. Scaramuzza. NeuroBEM: Hybrid aero- dynamic quadrotor model. InRobotics: Science and Systems, 2021
2021
-
[12]
J. Pan*, J. Xing*, R. Reiter, Y . Zhai, E. Aljalbout, and D. Scaramuzza. Learning on the fly: Rapid policy adaptation via differentiable simulation.IEEE Robotics and Automation Letters, 2025
2025
-
[13]
H. Wang, J. Xing, N. Messikommer, and D. Scaramuzza. Environment as policy: Learning to race in unseen tracks. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 11333–11339. IEEE, 2025
2025
-
[14]
Hanover, P
D. Hanover, P. Foehn, S. Sun, E. Kaufmann, and D. Scaramuzza. Performance, precision, and payloads: Adaptive nonlinear mpc for quadrotors.IEEE Robotics and Automation Letters, 7 (2):690–697, 2021
2021
-
[15]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[16]
Schulman, S
J. Schulman, S. Levine, P. Abbeel, M. Jordan, and P. Moritz. Trust region policy optimization. InInternational conference on machine learning, pages 1889–1897. PMLR, 2015. 9
2015
-
[17]
Rudin, D
N. Rudin, D. Hoeller, P. Reist, and M. Hutter. Learning to walk in minutes using massively parallel deep reinforcement learning. InConference on robot learning, pages 91–100. PMLR, 2022
2022
-
[18]
W. Yu, J. Tan, C. K. Liu, and G. Turk. Preparing for the unknown: Learning a universal policy with online system identification.arXiv preprint arXiv:1702.02453, 2017
Pith/arXiv arXiv 2017
-
[19]
X. B. Peng, M. Andrychowicz, W. Zaremba, and P. Abbeel. Sim-to-real transfer of robotic control with dynamics randomization. In2018 IEEE international conference on robotics and automation (ICRA), pages 3803–3810. IEEE, 2018
2018
-
[20]
Rakelly, A
K. Rakelly, A. Zhou, C. Finn, S. Levine, and D. Quillen. Efficient off-policy meta- reinforcement learning via probabilistic context variables. InInternational conference on ma- chine learning, pages 5331–5340. PMLR, 2019
2019
-
[21]
O’Connell, G
M. O’Connell, G. Shi, X. Shi, K. Azizzadenesheli, A. Anandkumar, Y . Yue, and S.-J. Chung. Neural-fly enables rapid learning for agile flight in strong winds.Science Robotics, 7(66): eabm6597, 2022
2022
-
[22]
Kumar, Z
A. Kumar, Z. Fu, D. Pathak, and J. Malik. Rma: Rapid motor adaptation for legged robots. Proceedings of Robotics: Science and Systems (RSS), 2021
2021
-
[23]
H. Qi, A. Kumar, R. Calandra, Y . Ma, and J. Malik. In-hand object rotation via rapid motor adaptation. InConference on Robot Learning, pages 1722–1732. PMLR, 2023
2023
-
[24]
Kumar, Z
A. Kumar, Z. Li, J. Zeng, D. Pathak, K. Sreenath, and J. Malik. Adapting rapid motor adapta- tion for bipedal robots. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1161–1168. IEEE, 2022
2022
-
[25]
Huang, R
K. Huang, R. Rana, A. Spitzer, G. Shi, and B. Boots. DATT: Deep adaptive trajectory tracking for quadrotor control. InConference on Robot Learning, 2023
2023
-
[26]
Kaufmann, L
E. Kaufmann, L. Bauersfeld, and D. Scaramuzza. A benchmark comparison of learned control policies for agile quadrotor flight. In2022 International Conference on Robotics and Automa- tion (ICRA), pages 10504–10510. IEEE, 2022
2022
-
[27]
Gretton, K
A. Gretton, K. M. Borgwardt, M. J. Rasch, B. Sch ¨olkopf, and A. Smola. A kernel two-sample test.Journal of Machine Learning Research, 13(1):723–773, 2012
2012
-
[28]
C. D. Freeman, E. Frey, A. Raichuk, S. Girgin, I. Mordatch, and O. Bachem. Brax – a differ- entiable physics engine for large scale rigid body simulation.Advances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[29]
Y . Song, S. Kim, and D. Scaramuzza. Learning quadrupedal locomotion via differentiable simulation. InProc. Conference on Robot Learning, 2024
2024
-
[30]
D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. In Y . Bengio and Y . LeCun, editors,3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015
2015
-
[31]
Neuralfeels with neural fields: Visuotactile perception for in-hand manipulation,
P. Foehn, E. Kaufmann, A. Romero, R. Penicka, S. Sun, L. Bauersfeld, T. Laengle, G. Cioffi, Y . Song, A. Loquercio, and D. Scaramuzza. Agilicious: Open-source and open-hardware agile quadrotor for vision-based flight.Science Robotics, 7(67), 2022. doi:10.1126/scirobotics. abl6259. 10 A Supplementary Materials Our supplementary materials provide the implem...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.