ASALT: Adaptive State Alignment for Lateral Transfer in Multi-agent Reinforcement Learning
Pith reviewed 2026-06-25 23:45 UTC · model grok-4.3
The pith
ASALT uses adapters to transfer multi-agent RL knowledge between domains with mismatched observation and state dimensions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
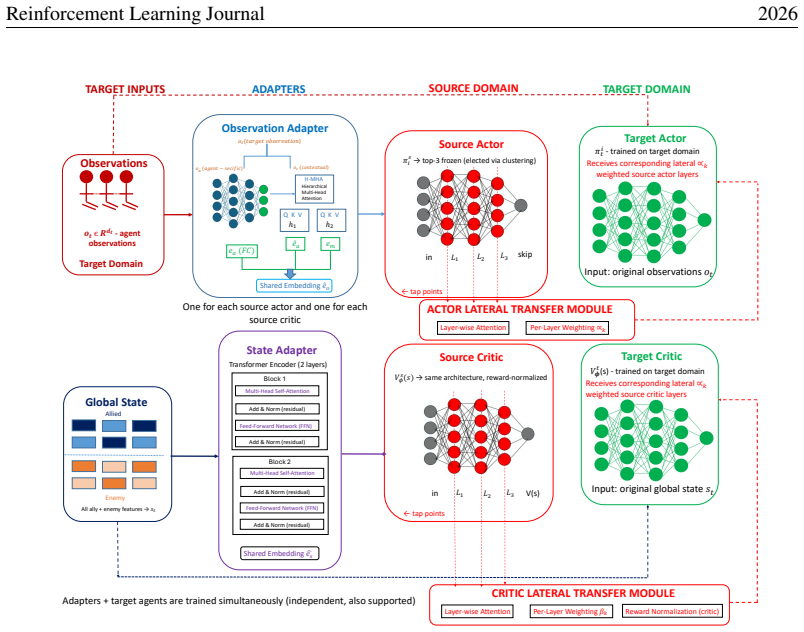
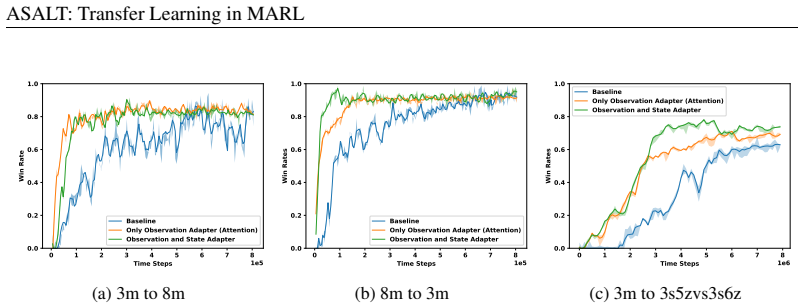
ASALT incorporates both observation-level and state-level adapters that map the target-domain observations and global states into a shared embedding space, thereby enabling more effective transfer of knowledge across both actors and critics even when dimensionalities differ. This approach demonstrates superior sample efficiency and global return in cooperative settings while mitigating negative transfer.
What carries the argument
observation-level and state-level adapters that map target observations and global states into a shared embedding space
If this is right
- ASALT achieves better sample efficiency than existing baselines in cooperative MARL transfer tasks.
- It produces higher global returns when policies are transferred across domains.
- Performance gains depend on the degree of mismatch between source and target state spaces.
- The method reduces negative transfer that often occurs with differing observation and action spaces.
Where Pith is reading between the lines
- The adapter alignment technique might apply to single-agent RL or other sequential decision problems with heterogeneous inputs.
- Further tests could examine how the approach scales when the number of agents or the action space mismatch grows larger.
- Embedding alignment may offer a general route for handling domain shifts in multi-agent systems beyond the benchmarks tested.
Load-bearing premise
The adapters can be trained to produce embeddings in a shared space that reliably support transfer of both actor and critic knowledge despite mismatched input dimensionalities.
What would settle it
An experiment on domains with moderate mismatch where the ASALT-transferred policy shows no improvement over training a policy from scratch on the target domain alone.
Figures
read the original abstract
Multi-agent reinforcement learning (MARL) addresses the problem of training multiple agents that pursue collaborative, competitive, or mixed objectives. Prior work has investigated transfer learning between source and target domains in MARL; however, the majority of existing approaches impose the constraint that the dimensionalities of the observation space and the global state space must be identical across domains. In this paper, we introduce a method that explicitly accommodates mismatched state-space dimensionalities between source and target domains. The proposed approach, ASALT, incorporates both observation-level and state-level adapters that map the target-domain observations and global states into a shared embedding space, thereby enabling more effective transfer of knowledge across both actors and critics. These adapters can generate embeddings that support efficient strategy transfer across heterogeneous domains. Experimental results on multiple configurations in standard benchmark environments demonstrate that ASALT surpasses existing baselines in terms of sample efficiency and global return in cooperative settings, but its effectiveness depends on the degree of mismatch between source and target domains. Furthermore, our findings indicate that ASALT mitigates negative transfer, which frequently constitutes a major obstacle when transferring policies between domains with differing observation and action spaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ASALT, a transfer learning method for multi-agent reinforcement learning that accommodates mismatched observation and global state dimensionalities between source and target domains. It employs observation-level and state-level adapters to project target-domain inputs into a shared embedding space, enabling transfer of both actor and critic parameters. Experiments across multiple configurations of standard benchmark environments report gains in sample efficiency and global return for cooperative tasks, along with reduced negative transfer relative to baselines.
Significance. If the empirical claims hold under rigorous controls, the work addresses a practical barrier in MARL transfer by relaxing the identical-dimensionality constraint common in prior methods. Demonstrating mitigation of negative transfer across varying mismatch degrees would be a useful contribution for heterogeneous multi-agent settings.
major comments (3)
- [§3] §3 (Method): The description of how the observation-level and state-level adapters are jointly trained (including the alignment loss, optimization procedure, and handling of mismatched input dimensionalities) is insufficient to evaluate whether the shared embedding space reliably supports actor-critic transfer; this mechanism is load-bearing for the central empirical claim.
- [§4] §4 (Experiments): No ablation isolating the contribution of the state-level adapter versus the observation-level adapter is reported, so it is unclear whether both components are necessary for the reported gains in sample efficiency and negative-transfer mitigation.
- [Table 2] Table 2 (or equivalent results table): The performance improvements are stated without error bars, number of random seeds, or statistical significance tests, weakening the claim that ASALT consistently surpasses baselines across mismatch degrees.
minor comments (2)
- [Abstract] The abstract and §1 could more explicitly define the range of mismatch degrees tested, as the effectiveness is stated to depend on this quantity.
- [§3] Notation for the embedding spaces and adapter functions should be introduced consistently in §3 to avoid ambiguity when describing the transfer of actor and critic networks.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation and empirical support.
read point-by-point responses
-
Referee: [§3] §3 (Method): The description of how the observation-level and state-level adapters are jointly trained (including the alignment loss, optimization procedure, and handling of mismatched input dimensionalities) is insufficient to evaluate whether the shared embedding space reliably supports actor-critic transfer; this mechanism is load-bearing for the central empirical claim.
Authors: We agree the current description in §3 is insufficiently detailed. In the revised manuscript we will expand the method section with the explicit alignment loss formulation, the joint optimization procedure (including gradients and update rules), and the precise mechanism by which the adapters accommodate mismatched input dimensionalities to produce the shared embedding. These additions will clarify how the embedding reliably supports actor-critic transfer. revision: yes
-
Referee: [§4] §4 (Experiments): No ablation isolating the contribution of the state-level adapter versus the observation-level adapter is reported, so it is unclear whether both components are necessary for the reported gains in sample efficiency and negative-transfer mitigation.
Authors: We acknowledge the absence of this ablation. The revised version will include a dedicated ablation study that isolates the observation-level adapter, the state-level adapter, and their combination, reporting the resulting sample-efficiency and negative-transfer metrics to demonstrate the necessity of both components. revision: yes
-
Referee: [Table 2] Table 2 (or equivalent results table): The performance improvements are stated without error bars, number of random seeds, or statistical significance tests, weakening the claim that ASALT consistently surpasses baselines across mismatch degrees.
Authors: We agree that statistical details are required. We will revise all result tables to report means with standard-error bars, state the number of random seeds (five seeds were used), and add statistical significance tests (paired t-tests with p-values) to substantiate the claims of consistent improvement across mismatch degrees. revision: yes
Circularity Check
No significant circularity identified
full rationale
The manuscript presents ASALT as an empirical transfer-learning method for MARL that uses observation- and state-level adapters to produce shared embeddings, enabling actor-critic transfer across mismatched dimensionalities. The abstract and description contain no equations, loss functions, or derivation steps; all central claims (improved sample efficiency, higher global return, mitigation of negative transfer) are stated as experimental outcomes on benchmark environments rather than as mathematical predictions derived from fitted parameters or prior self-citations. Because no load-bearing derivation chain exists in the supplied text, none of the enumerated circularity patterns can be exhibited by direct quotation and reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ISSN 1935-8245. DOI: 10.1561/2200000080. URL http://dx.doi.org/10.1561/2200000080. Sushrut Bhalla, Sriram Ganapathi Subramanian, and Mark Crowley. Deep multi agent reinforcement learning for autonomous driving. In Canadian Conference on Artificial Intelligence, pp. 67–78. Springer,
-
[2]
Autonomous air traffic controller: A deep multi-agent reinforcement learning approach
Marc Brittain and Peng Wei. Autonomous air traffic controller: A deep multi-agent reinforcement learning approach. arXiv preprint arXiv:1905.01303,
Pith/arXiv arXiv 1905
-
[3]
URL https://books.google.co.in/books? id=fEQxEAAAQBAJ
ISBN 9781636391359. URL https://books.google.co.in/books? id=fEQxEAAAQBAJ. Haotian Fu, Hongyao Tang, Jianye Hao, Zihan Lei, Yingfeng Chen, and Changjie Fan. Deep multi-agent reinforcement learning with discrete-continuous hybrid action spaces. arXiv preprint arXiv:1903.04959,
Pith/arXiv arXiv 1903
-
[4]
Policy-based trajectory clustering in offline reinforce- ment learning
Hao Hu, Xinqi Wang, and Simon Shaolei Du. Policy-based trajectory clustering in offline reinforce- ment learning. arXiv preprint arXiv:2506.09202,
-
[5]
Tikick: Towards playing multi-agent football full games from single-agent demonstra- tions
Shiyu Huang, Wenze Chen, Longfei Zhang, Ziyang Li, Fengming Zhu, Deheng Ye, Ting Chen, and Jun Zhu. Tikick: Towards playing multi-agent football full games from single-agent demonstra- tions. arXiv preprint arXiv:2110.04507,
-
[6]
Reinforcement Learning Journal 2026 Q. Long, Z. Zhou, A. Gupta, F. Fang, Y . Wu, and X. Wang. Evolutionary population curriculum for scaling multi-agent reinforcement learning. arXiv preprint arXiv:2003.10423,
arXiv 2026
-
[7]
Maven: Multi-agent variational exploration
Anuj Mahajan, Tabish Rashid, Mikayel Samvelyan, and Shimon Whiteson. Maven: Multi-agent variational exploration. arXiv preprint arXiv:1910.07483,
arXiv 1910
-
[8]
A centralized reinforcement learning method for multi-agent job scheduling in grid
Milad Moradi. A centralized reinforcement learning method for multi-agent job scheduling in grid. In 2016 6th International Conference on Computer and Knowledge Engineering (ICCKE) , pp. 171–176. IEEE,
2016
-
[9]
Emergence of grounded compositional language in multi-agent populations
Igor Mordatch and Pieter Abbeel. Emergence of grounded compositional language in multi-agent populations. arXiv preprint arXiv:1703.04908,
-
[10]
Janarthanan Rajendran, Aravind Srinivas, Mitesh M Khapra, P Prasanna, and Balaraman Ravindran. Attend, adapt and transfer: Attentive deep architecture for adaptive transfer from multiple sources in the same domain. arXiv preprint arXiv:1510.02879,
-
[11]
Mikayel Samvelyan, Tabish Rashid, Christian Schroeder de Witt, Gregory Farquhar, Nantas Nardelli, Tim G. J. Rudner, Chia-Man Hung, Philiph H. S. Torr, Jakob Foerster, and Shimon Whiteson. The StarCraft Multi-Agent Challenge. CoRR, abs/1902.04043,
arXiv 1902
-
[13]
Annie Wong, Thomas Bäck, Anna V Kononova, and Aske Plaat
URL http://arxiv.org/abs/1706.03762. Annie Wong, Thomas Bäck, Anna V Kononova, and Aske Plaat. Deep multiagent reinforcement learning: Challenges and directions. Artificial Intelligence Review, 56(6):5023–5056,
-
[14]
ASALT: Transfer Learning in MARL Kaiqing Zhang, Zhuoran Yang, Han Liu, Tong Zhang, and Tamer Basar
URL https: //arxiv.org/abs/2103.01955. ASALT: Transfer Learning in MARL Kaiqing Zhang, Zhuoran Yang, Han Liu, Tong Zhang, and Tamer Basar. Fully decentralized multi- agent reinforcement learning with networked agents. In International Conference on Machine Learning, pp. 5872–5881. PMLR,
-
[15]
Cooperative multiagent transfer learning with coalition pattern decomposition
Tianze Zhou, Fubiao Zhang, Kun Shao, Zipeng Dai, Kai Li, Wenhan Huang, Weixun Wang, Bin Wang, Dong Li, Wulong Liu, and Jianye Hao. Cooperative multiagent transfer learning with coalition pattern decomposition. IEEE Transactions on Games , 16(2):352–364, 2024a. DOI: 10.1109/TG.2023.3272386. Tianze Zhou, Fubiao Zhang, Kun Shao, Zipeng Dai, Kai Li, Wenhan Hu...
-
[16]
Transfer learning in deep reinforcement learning: A survey
Zhuangdi Zhu, Kaixiang Lin, Anil K Jain, and Jiayu Zhou. Transfer learning in deep reinforcement learning: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence , 45(11): 13344–13362, 2023a. Zhuangdi Zhu, Kaixiang Lin, Anil K. Jain, and Jiayu Zhou. Transfer learning in deep reinforcement learning: A survey. IEEE Transactions on Pattern ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.