Creating A Neural Pedagogical Agent by Jointly Learning to Review and Assess
Pith reviewed 2026-05-25 15:33 UTC · model grok-4.3
The pith
A bidirectional RNN with attention updates user knowledge in real time to predict response correctness more accurately than prior methods, especially for new users.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
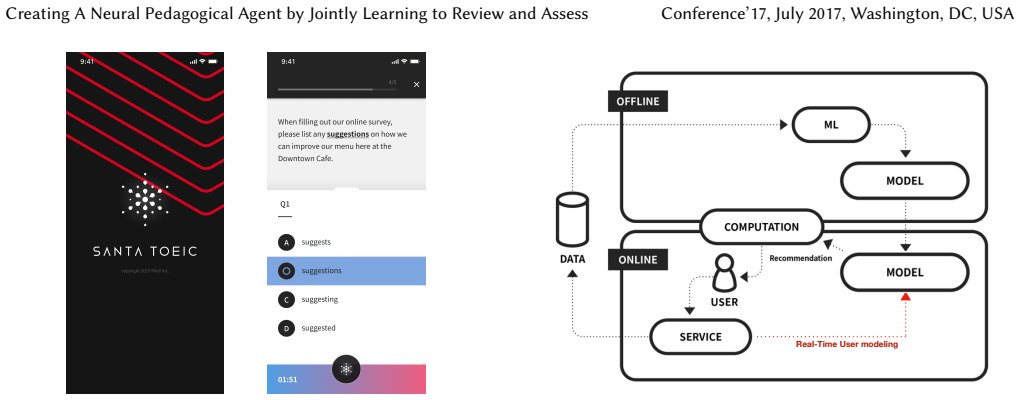
Our model updates user features in real-time via bidirectional recurrent neural networks with an attention mechanism over embedded question-response pairs. Our model outperforms existing approaches over several metrics in predicting user response correctness, notably out-performing other methods on new users without large question-response histories. Additionally, our attention mechanism and annotated tag set allow us to create an interpretable education platform, with a smart review system that addresses the issue of varied user attention and problem exhaustion.
What carries the argument
bidirectional recurrent neural networks with an attention mechanism over embedded question-response pairs
If this is right
- Real-time user feature updates become possible on mobile platforms where users arrive and change frequently.
- Prediction accuracy improves for users who have accumulated only short response histories.
- An interpretable review system can be built that uses attention weights and topic tags to select material for revisiting.
Where Pith is reading between the lines
- The architecture could be extended to joint prediction of both correctness and next-problem recommendations within the same model.
- Similar sequence-modeling approaches may transfer to other domains that require real-time updating of user state from sparse interaction logs.
- The interpretability claim would be strengthened by measuring whether attention-highlighted topics actually change user behavior when presented in the review system.
- The performance edge on new users suggests the model could reduce the cold-start problem in other sequential recommendation settings.
Load-bearing premise
The attention mechanism over embedded question-response pairs combined with expert topic tags produces reliable interpretability for the smart review system without separate validation of the explanations.
What would settle it
A direct comparison of the model's attention weights against independent expert ratings or user self-reports on which past questions most influence current correctness predictions would test whether the interpretability holds.
Figures







read the original abstract
Machine learning plays an increasing role in intelligent tutoring systems as both the amount of data available and specialization among students grow. Nowadays, these systems are frequently deployed on mobile applications. Users on such mobile education platforms are dynamic, frequently being added, accessing the application with varying levels of focus, and changing while using the service. The education material itself, on the other hand, is often static and is an exhaustible resource whose use in tasks such as problem recommendation must be optimized. The ability to update user models with respect to educational material in real-time is thus essential; however, existing approaches require time-consuming re-training of user features whenever new data is added. In this paper, we introduce a neural pedagogical agent for real-time user modeling in the task of predicting user response correctness, a central task for mobile education applications. Our model, inspired by work in natural language processing on sequence modeling and machine translation, updates user features in real-time via bidirectional recurrent neural networks with an attention mechanism over embedded question-response pairs. We experiment on the mobile education application SantaTOEIC, which has 559k users, 66M response data points as well as a set of 10k study problems each expert-annotated with topic tags and gathered since 2016. Our model outperforms existing approaches over several metrics in predicting user response correctness, notably out-performing other methods on new users without large question-response histories. Additionally, our attention mechanism and annotated tag set allow us to create an interpretable education platform, with a smart review system that addresses the aforementioned issue of varied user attention and problem exhaustion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a neural pedagogical agent for real-time user modeling in mobile education apps. It uses bidirectional RNNs with an attention mechanism over embedded question-response pairs to predict user response correctness, updating features without retraining. Experiments on the SantaTOEIC dataset (559k users, 66M responses, 10k expert-tagged problems) claim outperformance over existing methods on several metrics, especially for new users lacking large histories, while the attention and tags enable an interpretable smart review system.
Significance. If the new-user generalization holds without data leakage, the real-time update capability without retraining would be a meaningful advance for dynamic user modeling in intelligent tutoring systems on mobile platforms. The combination of sequence modeling and expert annotations for interpretability is a constructive direction, though the absence of separate validation for the generated explanations reduces the immediate practical significance.
major comments (2)
- [Abstract] Abstract: The central empirical claim is outperformance on new users without large question-response histories. However, the manuscript provides no description of the train/test split procedure (user-level vs. response-level). A response-level split would allow shared RNN parameters and embeddings to encode user-specific patterns from a user's training responses, rendering the reported gains on 'new' users non-generalizable and undermining the headline result.
- [Experiments] Experiments section: The abstract asserts outperformance 'over several metrics' and 'notably' on new users, yet reports no numerical values, baseline implementations, statistical significance tests, or error analysis. This absence makes it impossible to assess whether the gains are substantive or whether they survive proper user-stratified evaluation.
minor comments (1)
- The abstract states that the model 'jointly learns to review and assess' in the title but the described architecture focuses on correctness prediction with attention used post-hoc for review; a clearer statement of the joint objective would improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. The two major comments highlight important gaps in the description of the evaluation protocol and the reporting of results. We address each below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim is outperformance on new users without large question-response histories. However, the manuscript provides no description of the train/test split procedure (user-level vs. response-level). A response-level split would allow shared RNN parameters and embeddings to encode user-specific patterns from a user's training responses, rendering the reported gains on 'new' users non-generalizable and undermining the headline result.
Authors: We agree that the absence of an explicit description of the train/test split is a serious omission that prevents proper assessment of the new-user results. The current manuscript does not state whether the split was performed at the user or response level. In the revision we will add a clear statement that all experiments use a user-stratified split (entire user histories are assigned wholly to train or test), which is the only procedure that supports the claimed generalization to new users. We will also move this description from the supplementary material into the main Experiments section. revision: yes
-
Referee: [Experiments] Experiments section: The abstract asserts outperformance 'over several metrics' and 'notably' on new users, yet reports no numerical values, baseline implementations, statistical significance tests, or error analysis. This absence makes it impossible to assess whether the gains are substantive or whether they survive proper user-stratified evaluation.
Authors: We acknowledge that the Experiments section (and abstract) currently lacks the concrete numbers, baseline implementation details, significance tests, and error analysis needed to evaluate the claims. In the revision we will insert a table of exact metric values (AUC, accuracy, etc.) for all methods, describe the baseline implementations, report paired statistical tests, and add a short error analysis focused on the new-user regime. These additions will be placed in the main text rather than only in supplementary material. revision: yes
Circularity Check
No significant circularity; model derivation is self-contained
full rationale
The paper describes a standard neural sequence model (bidirectional RNN + attention over embedded question-response pairs) trained on observed response data from SantaTOEIC to predict held-out response correctness. No equations, self-citations, or ansatzes are presented that reduce the claimed predictions or interpretability features to the inputs by construction; the central empirical claims rest on external data splits and evaluation metrics rather than definitional equivalence or load-bearing self-references. The derivation chain from embeddings through the RNN/attention layers to correctness predictions is independent and falsifiable on held-out data.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard neural network training assumptions hold, including that gradient-based optimization finds useful representations from the given data.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our model... updates user features in real-time via bidirectional recurrent neural networks with an attention mechanism over embedded question-response pairs.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our model outperforms existing approaches... on new users without large question-response histories.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jun Araki, Dheeraj Rajagopal, Sreecharan Sankaranarayanan, Susan Holm, Yukari Yamakawa, and Teruko Mitamura. 2016. Generating /Q_uestions and Multiple- Choice Answers using Semantic Analysis of Texts. In Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers. 1125–1136
work page 2016
-
[2]
Frank B. Baker. 1985. /T_he Basics of Item Response /T_heory. ERIC Clearinghouse on Assessment and Evaluation
work page 1985
-
[3]
Robert M Bell and Yehuda Koren. 2007. Improved Neighborhood-Based Collabo- rative Filtering. In KDD cup and workshop at the 13th ACM SIGKDD international conference on knowledge discovery and data mining . Citeseer, 7–14
work page 2007
-
[4]
JESUS Bobadilla, Francisco Serradilla, Antonio Hernando, et al. 2009. Collabora- tive Filtering Adapted to Recommender Systems of E-Learning.Knowledge-Based Systems 22, 4 (2009), 261–265
work page 2009
-
[5]
Kyunghyun Cho, Bart Van Merri¨enboer, Dzmitry Bahdanau, and Yoshua Ben- gio. 2014. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches. arXiv preprint arXiv:1409.1259 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[6]
Edward Choi, Mohammad Taha Bahadori, Jimeng Sun, Joshua Kulas, Andy Schuetz, and Walter Stewart. 2016. RETAIN: An Interpretable Predictive Model for Healthcare using Reverse Time A/t_tention Mechanism. InAdvances in Neural Information Processing Systems. 3504–3512
work page 2016
-
[7]
Cristina Conati, Kaska Porayska-Pomsta, and Manolis Mavrikis. 2018. AI in Education needs interpretable machine learning: Lessons from Open Learner Creating A Neural Pedagogical Agent by Jointly Learning to Review and Assess Conference’17, July 2017, Washington, DC, USA Figure 9: /T_he attention trajectory. Modelling. arXiv preprint arXiv:1807.00154 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
Christian Desrosiers and George Karypis. 2011. A Comprehensive Survey of Neighborhood-Based Recommendation Methods. In Recommender systems hand- book. Springer, 107–144
work page 2011
-
[9]
Benedict du Boulay. 2016. ARTIFICIAL INTELLIGENCE AS AN EFFECTIVE CLASSROOM ASSISTANT. IEEE Intelligent Systems 31, 6 (2016), 76–81
work page 2016
-
[10]
Arthur K Ellis, David W Denton, and John B Bond. 2014. An Analysis of Research on Metacognitive Teaching Strategies. InProcedia - Social and Behavioral Sciences, Volume 116. 4015–4024
work page 2014
-
[11]
Bahdanau et al. 2014. NEURAL MACHINE TRANSLATION BY JOINTLY LEARN- ING TO ALIGN AND TRANSLATE. arXiv preprint arXiv:1409.0473 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[12]
Mikolov et al. 2013. Efficient Estimation of Word Representations in Vector Space. arXiv preprint arXiv:1301.3781 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[13]
Leilani H Gilpin, David Bau, Ben Z Yuan, Ayesha Bajwa, Michael Specter, and Lalana Kagal. 2018. Explaining Explanations: An Overview of Interpretability of Machine Learning. In 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA). IEEE, 80–89
work page 2018
-
[14]
Xavier Glorot and Yoshua Bengio. 2010. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the thirteenth international conference on arti/f_icial intelligence and statistics. 249–256
work page 2010
-
[15]
Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. 2017. Neural Collaborative Filtering. InProceedings of the 26th International Conference on World Wide Web . International World Wide Web Conferences Steering Commi/t_tee, 173–182
work page 2017
-
[16]
Sepp Hochreiter and J ¨urgen Schmidhuber. 1997. Long Short-Term Memory. Neural computation 9, 8 (1997), 1735–1780
work page 1997
-
[17]
Aarij Mahmood Hussaan and Karim Sehaba. 2014. Learn and Evolve the Domain Model in Intelligent Tutoring Systems. In CSEDU 2014 - Proceedings of the 6th International Conference on Computer Supported Education . 197–204
work page 2014
-
[18]
TabMCQ: A Dataset of General Knowledge Tables and Multiple-choice Questions
Sujay Kumar Jauhar, Peter D. Turney, and Eduard H. Hovy. 2016. TabMCQ: A Dataset of General Knowledge Tables and Multiple-choice /Q_uestions. CoRR abs/1602.03960 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[19]
Diederik P Kingma and Jimmy Ba. 2014. ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION. arXiv preprint arXiv:1412.6980 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[20]
Andr´e Klaßen, Marcus Eibrink-Lunzenauer, and Till Gl¨oggler. 2013. Requirements for mobile learning applications in higher education. In 2013 IEEE International Symposium on Multimedia. IEEE, 492–497
work page 2013
-
[21]
Kristopher J. Kopp, Amy M. Johnson, Sco/t_t A. Crossley, and Danielle S. McNamara
-
[22]
Assessing /Q_uestion /Q_uality using NLP. InArti/f_icial Intelligence in Education - 18th International Conference, AIED 2017, Wuhan, China, June 28 - July 1, 2017, Proceedings. 523–527
work page 2017
-
[23]
Yehuda Koren. 2008. Factorization Meets the Neighborhood: A Multifaceted Col- laborative Filtering Model. In Proceedings ACM SIGKDD International Conference on Knowledge Discovery and Data mining . ACM, 426–434
work page 2008
-
[24]
Vassilis Kostakos and Mirco Musolesi. 2017. Avoiding Pitfalls When Using Machine Learning in HCI Studies. interactions 24, 4 (2017), 34–37
work page 2017
-
[25]
Oleksii Kuchaiev and Boris Ginsburg. 2017. Training Deep AutoEncoders for Collaborative Filtering. arXiv preprint arXiv:1708.01715 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. 2015. Deep Learning. nature 521, 7553 (2015), 436
work page 2015
-
[27]
Kangwook Lee, Jichan Chung, Yeongmin Cha, and Changho Suh. 2016. Ma- chine Learning Approaches for Learning Analytics: Collaborative Filtering Or Regression With Experts?. In NIPS Workshop. NIPS
work page 2016
-
[28]
Minh-/T_hang Luong, Hieu Pham, and Christopher D Manning. 2015. Effective Approaches to A/t_tention-based Neural Machine Translation. arXiv preprint arXiv:1508.04025 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[29]
Peter Afflerbach Marcel V. J. Veenman, Bernade/t_te H. A. M. Van Hout-Wolters
- [30]
-
[31]
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013. Distributed Representations of Words and Phrases and their Compositionality. In Advances in Neural Information Processing Systems . 3111–3119
work page 2013
-
[32]
Tomas Mikolov, Wen-tau Yih, and Geoffrey Zweig. 2013. Linguistic Regularities in Continuous Space Word Representations. InProceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 746–751
work page 2013
-
[33]
Andriy Mnih and Ruslan R Salakhutdinov. 2008. Probabilistic Matrix Factoriza- tion. In Advances in Neural Information Processing Systems . 1257–1264
work page 2008
-
[34]
Fumiya Okubo, Takayoshi Yamashita, Atsushi Shimada, and Hiroaki Ogata. 2017. A Neural Network Approach for Students’ Performance Prediction. InProceedings of the Seventh International Learning Analytics & Knowledge Conference . ACM, 598–599
work page 2017
-
[35]
Jeffrey Pennington, Richard Socher, and Christopher Manning. 2014. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) . 1532–1543
work page 2014
-
[36]
Carissa Schoenick, Peter Clark, Oyvind Ta/f_jord, Peter D. Turney, and Oren Etzioni
-
[37]
Moving Beyond the Turing Test with the Allen AI Science Challenge. Commun. ACM 60, 9 (2017), 60–64
work page 2017
-
[38]
Mike Schuster and Kuldip K Paliwal. 1997. Bidirectional Recurrent Neural Networks. IEEE Transactions on Signal Processing 45, 11 (1997), 2673–2681
work page 1997
-
[39]
Suvash Sedhain, Aditya Krishna Menon, Sco/t_t Sanner, and Lexing Xie. 2015. AutoRec: Autoencoders Meet Collaborative Filtering. In Proceedings of the 24th International Conference on World Wide Web. ACM, 111–112
work page 2015
-
[40]
Nguyen /T_hai-Nghe, Lucas Drumond, Artus Krohn-Grimberghe, and Lars Schmidt- /T_hieme. 2010. Recommender System for Predicting Student Performance.Proce- dia Computer Science 1, 2 (2010), 2811–2819
work page 2010
-
[41]
Andreas Toscher and Michael Jahrer. 2010. Collaborative Filtering Applied to Educational Data Mining. KDD cup (2010)
work page 2010
-
[42]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. A/t_tention Is All You Need. In Advances in neural information processing systems . 5998–6008
work page 2017
- [43]
-
[44]
Darrell M West. 2015. Connected learning: How mobile technology can improve education. Center for Technology Innovation at Brookings. Retrieved March 25 (2015), 2016
work page 2015
-
[45]
Chao-Yuan Wu, Amr Ahmed, Alex Beutel, Alexander J Smola, and How Jing. 2017. Recurrent Recommender Networks. In Proceedings of the 10th ACM International Conference on Web Search and Data Mining . ACM, 495–503
work page 2017
-
[46]
Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, and Yoshua Bengio. 2015. Show, A/t_tend and Tell: Neu- ral Image Caption Generation with Visual A/t_tention. InInternational conference on machine learning. 2048–2057
work page 2015
-
[47]
Vincent Aleven Yanjin Long. 2017. Enhancing learning outcomes through self- regulated learning support with an Open Learner Model. In User Modeling and User-Adapted Interaction. 55–88
work page 2017
-
[48]
Shuai Zhang, Lina Yao, Aixin Sun, and Yi Tay. 2019. Deep Learning based Recommender System: A Survey and New Perspectives.ACM Computing Surveys (CSUR) 52, 1 (2019), 5
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.