Decompose, Compare, and Decide: Multimodal LLMs are Implicit Few-Shot Learners
Pith reviewed 2026-07-02 19:45 UTC · model grok-4.3
The pith
Off-the-shelf multimodal LLMs become strong few-shot image classifiers by decomposing the task into pairwise same-class decisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
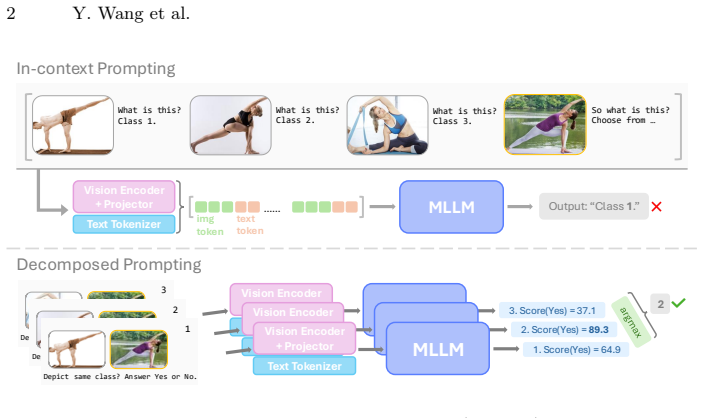
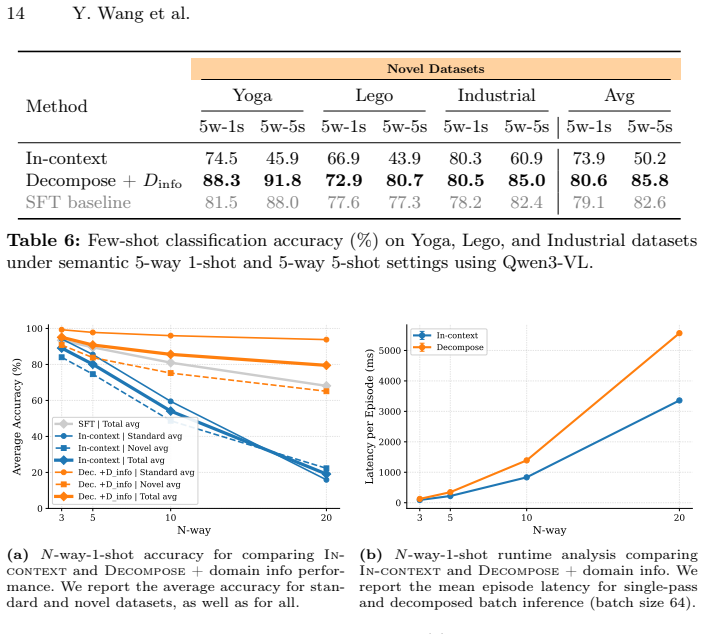
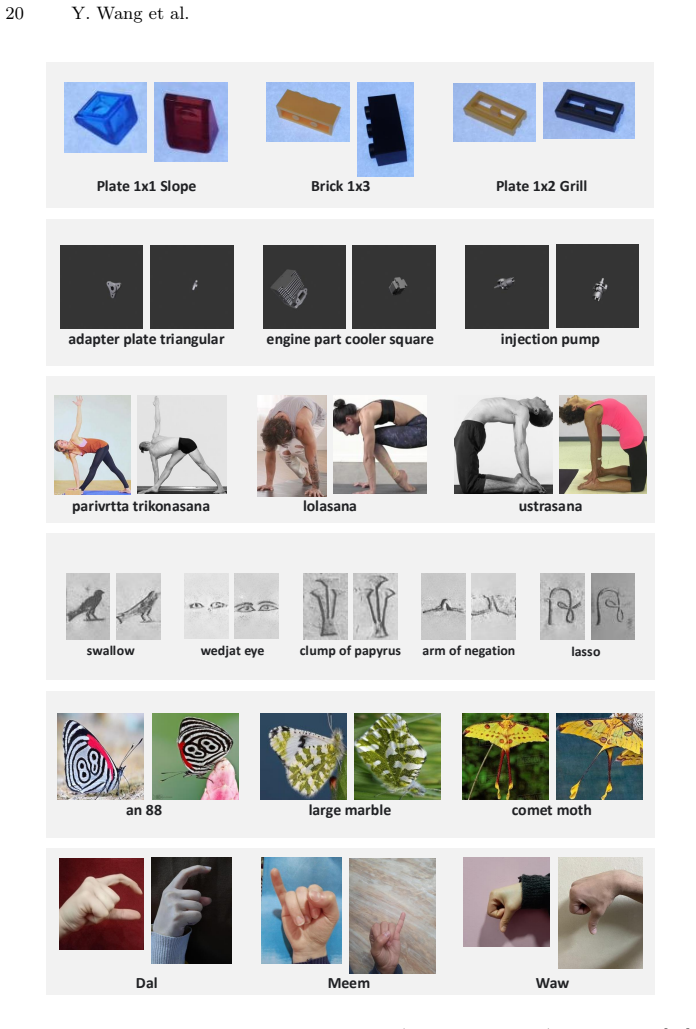
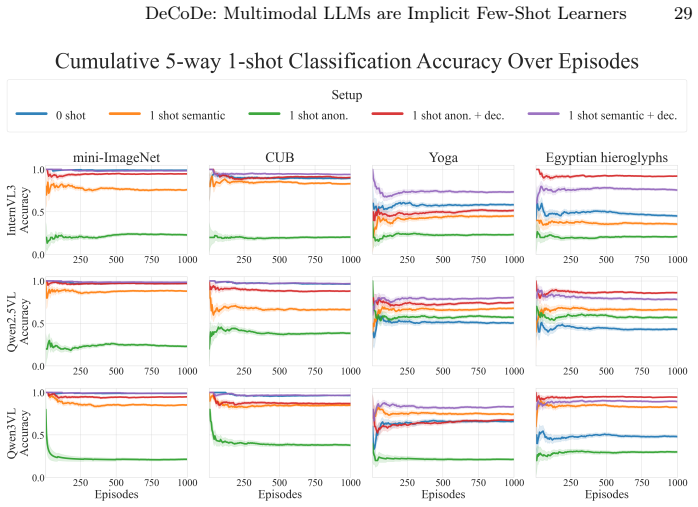
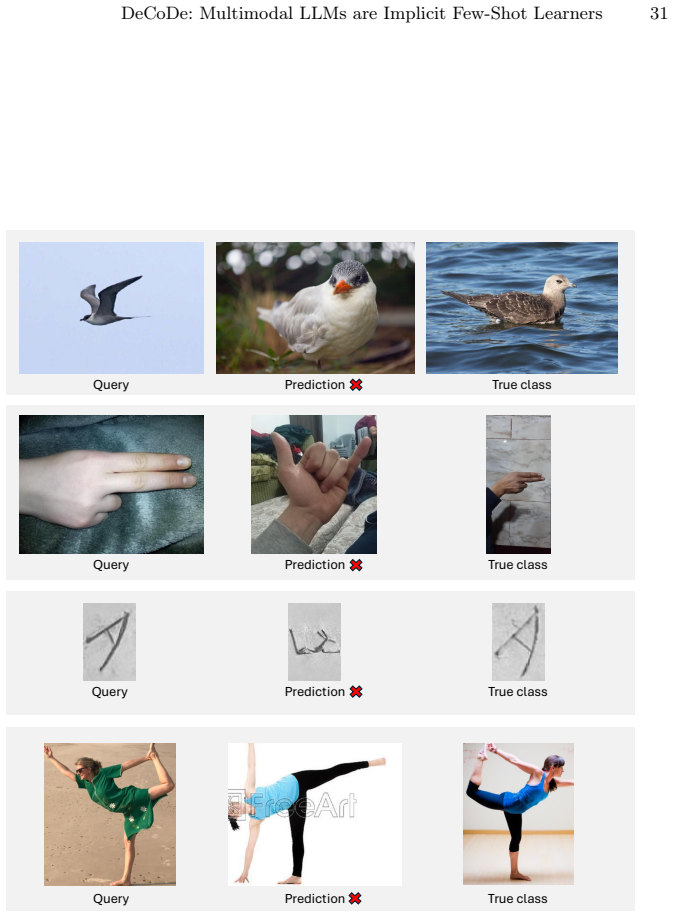
DeCoDe decomposes few-shot classification into a collection of pairwise binary decisions by prompting an MLLM to judge whether a query image and a support image belong to the same class; the logit of the affirmative token is then used directly as a similarity score to select the most likely class for the query. Supplying high-level domain information in the prompt improves the scores. On twelve datasets the method exceeds current specialized few-shot baselines without any additional training.
What carries the argument
Decomposition of few-shot classification into binary same-class prompts whose affirmative logits serve as cross-image similarity scores.
If this is right
- MLLMs can perform few-shot image classification without any training or fine-tuning.
- Including domain context in the prompt measurably raises classification accuracy.
- The same decomposition works on both established benchmarks and newly curated datasets from varied domains.
- Pairwise comparison is sufficient to surface classification capability already present in off-the-shelf MLLMs.
Where Pith is reading between the lines
- The result implies that MLLMs already contain implicit representations of visual class similarity that prompting can surface.
- Analogous decompositions into binary decisions could be tested on other multimodal tasks such as few-shot detection or retrieval.
- If the logit-based scores prove stable, the approach offers a training-free route to adapt MLLMs to new visual domains.
Load-bearing premise
The logit of an MLLM's affirmative response to a pairwise same-class prompt forms a reliable and comparable similarity measure across classes and datasets.
What would settle it
On a held-out dataset the similarity scores produced by the pairwise prompts fail to rank support images by true class membership better than chance or a simple baseline.
Figures

read the original abstract
Multimodal Large Language Models (MLLMs) have demonstrated remarkable abilities when analyzing images, yet translating these capabilities to few-shot image classification remains challenging. To bridge this gap, we present DeCoDe, a simple yet effective technique that enables off-the-shelf MLLMs to act as strong few-shot classifiers without any additional training. Our approach builds on the idea of few-shot classification as a set of pairwise image comparisons, decomposing the task into a set of binary decisions. Given a query image and a support image from a candidate class, the MLLM is prompted to decide whether the two images depict the same class. The logit corresponding to an affirmative response is then used as a similarity score to assign the query image to the most likely class. While this already yields good results, we show that providing additional high-level information, such as the data domain, to the model further improves performance. Our evaluation provides an extensive analysis of various inference variants on a suite of twelve datasets, six established and six newly curated few-shot benchmarks spanning across diverse domains. The results show that the proposed simple decomposition technique can turn off-the-shelf MLLMs into powerful few-shot learners, significantly outperforming current state-of-the-art few-shot methods on both standard and novel domains. Code is available at https://github.com/yunhanwang1105/DeCoDe.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DeCoDe, a prompting technique that decomposes few-shot image classification into a series of pairwise binary decisions: an MLLM is queried whether a support image and query image belong to the same class, and the logit of the affirmative token is used directly as a similarity score to select the class with the highest score. The base procedure is augmented by optionally injecting high-level domain information into the prompt. Extensive experiments are reported across twelve datasets (six established, six newly curated), with claims of significant outperformance over existing few-shot methods in both standard and novel domains.
Significance. If the central results hold after addressing calibration concerns, the work would demonstrate that off-the-shelf MLLMs can function as strong few-shot classifiers via a simple, training-free decomposition, with broad applicability across domains. The release of code and the introduction of new benchmarks are positive contributions to reproducibility and evaluation standards in multimodal few-shot learning.
major comments (1)
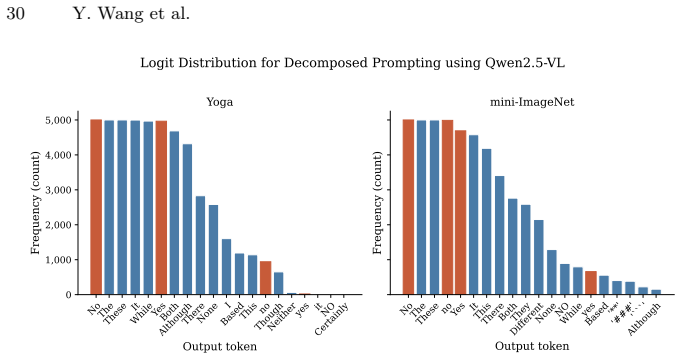
- [Abstract] Abstract (paragraph describing the scoring procedure): the method assumes the raw affirmative logit constitutes a reliable, monotonic, and cross-class/cross-dataset similarity measure suitable for argmax assignment. No analysis, normalization, or ablation is described that tests whether these logits are comparably scaled or free from class-specific biases (e.g., higher values for frequent pretraining categories). This assumption is load-bearing for the claim that the decomposition itself turns MLLMs into powerful few-shot learners, as unaddressed logit-scale variation could produce the reported gains through bias rather than visual comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the scoring procedure. We address the concern regarding the use of raw affirmative logits below.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph describing the scoring procedure): the method assumes the raw affirmative logit constitutes a reliable, monotonic, and cross-class/cross-dataset similarity measure suitable for argmax assignment. No analysis, normalization, or ablation is described that tests whether these logits are comparably scaled or free from class-specific biases (e.g., higher values for frequent pretraining categories). This assumption is load-bearing for the claim that the decomposition itself turns MLLMs into powerful few-shot learners, as unaddressed logit-scale variation could produce the reported gains through bias rather than visual comparison.
Authors: We agree that the abstract does not include an explicit analysis of logit scaling or potential class-specific biases. The full manuscript reports results across twelve datasets with diverse class distributions and domains, where the method outperforms baselines without normalization; this cross-dataset consistency provides indirect evidence that the logits function as effective relative similarity measures for argmax selection. To directly address the concern, we will add a dedicated analysis section with ablations on logit distributions, monotonicity checks, and simple calibration experiments (e.g., per-query normalization) to verify that performance gains derive from visual comparisons rather than pretraining biases. revision: yes
Circularity Check
No circularity; method is prompting procedure validated externally
full rationale
The paper describes a prompting-based decomposition (pairwise 'same class?' queries, affirmative logit as similarity score) evaluated on external benchmarks across twelve datasets. No equations, fitted parameters, or self-citation chains appear in the provided text that reduce the reported performance to inputs defined inside the paper. The central claim rests on empirical comparison to SOTA few-shot methods rather than any internal derivation that loops back by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal LLMs produce logits for affirmative answers to 'same class?' prompts that can be interpreted as comparable similarity scores across classes.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2301.11932 (2023)
Al-Barham, M., Alsharkawi, A., Al-Yaman, M., Al-Fetyani, M., Elnagar, A., SaAleek, A.A., Al-Odat, M.: Rgb arabic alphabets sign language dataset. arXiv preprint arXiv:2301.11932 (2023)
-
[2]
In: CVPR (2023)
Assran, M., Duval, Q., Misra, I., Bojanowski, P., Vincent, P., Rabbat, M., Le- Cun, Y., Ballas, N.: Self-supervised learning from images with a joint-embedding predictive architecture. In: CVPR (2023)
2023
-
[3]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Baldassini, F.B., Shukor, M., Cord, M., Soulier, L., Piwowarski, B.: What makes multimodal in-context learning work? In: CVPR (2024)
2024
-
[6]
In: CVPR (2025)
Bendou, Y., Ouasfi, A., Gripon, V., Boukhayma, A.: Proker: A kernel perspective on few-shot adaptation of large vision-language models. In: CVPR (2025)
2025
-
[7]
In: ICLR (2023)
Chen, G., Yao, W., Song, X., Li, X., Rao, Y., Zhang, K.: Plot: Prompt learning with optimal transport for vision-language models. In: ICLR (2023)
2023
-
[8]
In: ICLR (2025)
Chi, Z., Gu, L., Liu, H., Wang, Z., Wu, Y., Wang, Y., Plataniotis, K.N.: Learning to adapt frozen CLIP for few-shot test-time domain adaptation. In: ICLR (2025)
2025
-
[9]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[10]
In: CVPR (2025)
Farina, M., Mancini, M., Iacca, G., Ricci, E.: Rethinking few-shot adaptation of vision-language models in two stages. In: CVPR (2025)
2025
-
[11]
In: ICLR (2024)
Fifty, C., Duan, D., Junkins, R.G., Amid, E., Leskovec, J., Re, C., Thrun, S.: Context-aware meta-learning. In: ICLR (2024)
2024
-
[12]
In: ICML (2017)
Finn, C., Abbeel, P., Levine, S.: Model-agnostic meta-learning for fast adaptation of deep networks. In: ICML (2017)
2017
-
[13]
In: ACM MM (2013)
Franken, M., van Gemert, J.C.: Automatic egyptian hieroglyph recognition by retrieving images as texts. In: ACM MM (2013)
2013
-
[14]
IJCV (2024)
Gao, P., Geng, S., Zhang, R., Ma, T., Fang, R., Zhang, Y., Li, H., Qiao, Y.: Clip- adapter: Better vision-language models with feature adapters. IJCV (2024)
2024
-
[15]
Garciam, P.: Lego brick sorting image recognition (2019), kaggle
2019
-
[16]
In: ICLR (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: Lora: Low-rank adaptation of large language models. In: ICLR (2022)
2022
-
[17]
In: CVPR (2025)
Hu, Z., Wei, Y., Shen, L., Yuan, C., Tao, D.: Unlocking tuning-free few-shot adapt- ability in visual foundation models by recycling pre-tuned loras. In: CVPR (2025)
2025
-
[18]
In: CVPR (2023)
Khattak, M.U., Rasheed, H., Maaz, M., Khan, S., Khan, F.S.: Maple: Multi-modal prompt learning. In: CVPR (2023)
2023
-
[19]
Khosla, A., Jayadevaprakash, N., Yao, B., Li, F.F.: Novel dataset for fine-grained image categorization: Stanford dogs
-
[20]
In: ICCV (2025)
Kravets, A., Chen, D., Namboodiri, V.P.: Rethinking few shot clip benchmarks: A critical analysis in the inductive setting. In: ICCV (2025)
2025
-
[21]
In: ICCV (2021) DeCoDe: Multimodal LLMs are Implicit Few-Shot Learners 17
Kukleva, A., Kuehne, H., Schiele, B.: Generalized and incremental few-shot learn- ing by explicit learning and calibration without forgetting. In: ICCV (2021) DeCoDe: Multimodal LLMs are Implicit Few-Shot Learners 17
2021
-
[22]
LLaVA-OneVision: Easy Visual Task Transfer
Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y., Liu, Z., et al.: Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
In: CVPR (2025)
Li, S., Liu, F., Hao, Z., Wang, X., Li, L., Liu, X., Chen, P., Ma, W.: Logits decon- fusion with clip for few-shot learning. In: CVPR (2025)
2025
-
[24]
In: ECCV (2018)
Li, Y., Li, Y., Vasconcelos, N.: Resound: Towards action recognition without rep- resentation bias. In: ECCV (2018)
2018
-
[25]
In: ECCV (2024)
Lin, Z., Pathak, D., Li, B., Li, J., Xia, X., Neubig, G., Zhang, P., Ramanan, D.: Evaluating text-to-visual generation with image-to-text generation. In: ECCV (2024)
2024
-
[26]
In: AAAI (2025)
Liu, F., Cai, W., Huo, J., Zhang, C., Chen, D., Zhou, J.: Making large vision language models to be good few-shot learners. In: AAAI (2025)
2025
-
[27]
Fine-Grained Visual Classification of Aircraft
Maji, S., Kannala, J., Rahtu, E., Blaschko, M., Vedaldi, A.: Fine-grained visual classification of aircraft. arXiv preprint arXiv:1306.5151 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[28]
In: ICCV (2025)
Mitra, C., Huang, B., Chai, T., Lin, Z., Arbelle, A., Feris, R., Karlinsky, L., Darrell, T., Ramanan, D., Herzig, R.: Enhancing few-shot vision-language classification with large multimodal model features. In: ICCV (2025)
2025
-
[29]
NVIDIA: NVIDIA H100 Tensor Core GPU Architecture (2022), whitepaper
2022
-
[30]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
In: ICCV (2019)
Peng, X., Bai, Q., Xia, X., Huang, Z., Saenko, K., Wang, B.: Moment matching for multi-source domain adaptation. In: ICCV (2019)
2019
-
[32]
Piosenka, G.: Butterfly and moths image classification 100 species (2023), kaggle
2023
-
[33]
In: ICML (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: ICML (2021)
2021
-
[34]
In: ICLR (2017)
Ravi, S., Larochelle, H.: Optimization as a model for few-shot learning. In: ICLR (2017)
2017
-
[35]
Saxena, S.: Yoga pose image classification dataset (2021), kaggle
2021
-
[36]
Schuerrle, B., Sankarappan, V.: Industrial classification dataset (2023), kaggle
2023
-
[37]
In: NeurIPS (2022)
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al.: Laion-5b: An open large-scale dataset for training next generation image-text models. In: NeurIPS (2022)
2022
-
[38]
In: CVPR (2025)
Shvetsova, N., Nagrani, A., Schiele, B., Kuehne, H., Rupprecht, C.: Unbiasing through textual descriptions: Mitigating representation bias in video benchmarks. In: CVPR (2025)
2025
-
[39]
In: NeurIPS (2017)
Snell, J., Swersky, K., Zemel, R.: Prototypical networks for few-shot learning. In: NeurIPS (2017)
2017
-
[40]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Soomro, K., Zamir, A.R., Shah, M.: Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402 (2012)
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[41]
In: CVPR (2018)
Sung, F., Yang, Y., Zhang, L., Xiang, T., Torr, P.H., Hospedales, T.M.: Learning to compare: Relation network for few-shot learning. In: CVPR (2018)
2018
-
[42]
Tian, Y., Wang, Y., Krishnan, D., Tenenbaum, J.B., Isola, P.: Rethinking few-shot image classification: a good embedding is all you need? In: ECCV (2020)
2020
-
[43]
In: ICCV (2023)
Udandarao, V., Gupta, A., Albanie, S.: Sus-x: Training-free name-only transfer of vision-language models. In: ICCV (2023)
2023
-
[44]
In: NeurIPS (2016) 18 Y
Vinyals, O., Blundell, C., Lillicrap, T., Wierstra, D., et al.: Matching networks for one shot learning. In: NeurIPS (2016) 18 Y. Wang et al
2016
-
[45]
Wah,C.,Branson,S.,Welinder,P.,Perona,P.,Belongie,S.,etal.:Thecaltech-ucsd birds-200-2011 dataset. Tech. rep
2011
-
[46]
In: ICCV (2025)
Yang, C.F., Yin, D., Hu, W., Ji, H., Peng, N., Zhou, B., Chang, K.W.: Verbalized representation learning for interpretable few-shot generalization. In: ICCV (2025)
2025
-
[47]
In: CVPR (2023)
Yao, H., Zhang, R., Xu, C.: Visual-language prompt tuning with knowledge-guided context optimization. In: CVPR (2023)
2023
-
[48]
In: CVPR (2023)
Yu, T., Lu, Z., Jin, X., Chen, Z., Wang, X.: Task residual for tuning vision-language models. In: CVPR (2023)
2023
-
[49]
In: ICCV (2023)
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language image pre-training. In: ICCV (2023)
2023
-
[50]
In: ECCV (2022)
Zhang, R., Wei, Z., Fang, R., Gao, P., Li, K., Dai, J., Qiao, Y., Li, H.: Tip-adapter: Training-free adaption of clip for few-shot classification. In: ECCV (2022)
2022
-
[51]
In: ICML (2021)
Zhao, Z., Wallace, E., Feng, S., Klein, D., Singh, S.: Calibrate before use: Improving few-shot performance of language models. In: ICML (2021)
2021
-
[52]
In: CVPR (2022)
Zhou, K., Yang, J., Loy, C.C., Liu, Z.: Conditional prompt learning for vision- language models. In: CVPR (2022)
2022
-
[53]
IJCV (2022)
Zhou, K., Yang, J., Loy, C.C., Liu, Z.: Learning to prompt for vision-language models. IJCV (2022)
2022
-
[54]
In: ICCV (2023)
Zhu, B., Niu, Y., Han, Y., Wu, Y., Zhang, H.: Prompt-aligned gradient for prompt tuning. In: ICCV (2023)
2023
-
[55]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y., Su, W., Shao, J., et al.: Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479 (2025) DeCoDe: Multimodal LLMs are Implicit Few-Shot Learners 19 A Supplementary Materials A.1 Dataset Details Dataset Classes T ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Put the query image first, followed by the support images (query first)
-
[57]
Redefine the few-shot classification problem as an in-context visual matching task (visual match)
-
[58]
Present the support images and query image first, followed by the text de- scription and instruction (images then text)
-
[59]
Standardin-contextpromptinChainofThought(CoT)style,weuseQwen3- VL-Thinking-8B for this prompt, and set max_token=600. 26 Y. Wang et al. Novel Datasets Prompt Setting Y oga Hiero. Sign A vg. With semantic label Standard in-context 74.582.4 68.4 75.1
-
[60]
Query first76.777.8 56.1 70.2
-
[61]
Images then text 9.0 13.8 12.5 11.8
-
[62]
CoT (Thinking) 41.7 68.4 24.1 44.7 Anonymous Standard in-context 20.3 30.0 28.1 26.1
-
[63]
Query first70.5 80.5 52.5 67.8
-
[64]
Visual match 18.5 12.5 15.2 15.4
-
[65]
Images then text 5.9 20.8 8.4 11.7
-
[66]
Standard in-context denotes the interleaved in-context prompting used in the main paper
CoT (Thinking) 9.0 47.3 2.3 19.5 T able 13:In-context prompt exploration on three novel datasets using Qwen3-VL. Standard in-context denotes the interleaved in-context prompting used in the main paper. We experimented with both the semantic and anonymous settings
-
[67]
<Image:x s 1,1> Option 1:c 1
Query first prompt: <Image:x q> What is this? Match it to one of the options below. <Image:x s 1,1> Option 1:c 1. ... <Image:x s 5,1> Option 5:c 5. Which option matches the query image shown first? Choose one of: 1.c 1; ...; 5.c 5
-
[68]
Visual match prompt: <Image:x s 1,1> Image 1. ... <Image:x s 5,1> Image 5. <Image:x q> Which image (1-5) is most visually similar to the last image? Answer with 1-5 only. DeCoDe: Multimodal LLMs are Implicit Few-Shot Learners 27
-
[69]
<Image:x s 5,1> <Image:x q> Image 1 belongs to Option 1:c 1; ...; Image 5 belongs to Option 5:c 5
Images then text prompt: <Image:x s 1,1> ... <Image:x s 5,1> <Image:x q> Image 1 belongs to Option 1:c 1; ...; Image 5 belongs to Option 5:c 5. What class is in the last image? Choose one of the options (1-5)
-
[70]
(we use)
CoT style prompt (Thinking): <Image:x s 1,1> What is this?c 1 (option 1). ... <Image:x s 5,1> What is this?c 5 (option 5). The following image is the query image. <Image:x q> So what is this? Choose one of the options: 1.c 1; ...; 5.c 5 Think step by step, then output exactly one final line in this format: Final answer: <number> In Table 13, under the sem...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.