Is One Layer Enough? Training A Single Transformer Layer Can Match Full-Parameter RL Training
Pith reviewed 2026-07-02 14:45 UTC · model grok-4.3
The pith
Training a single middle transformer layer recovers most gains from full-parameter RL training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
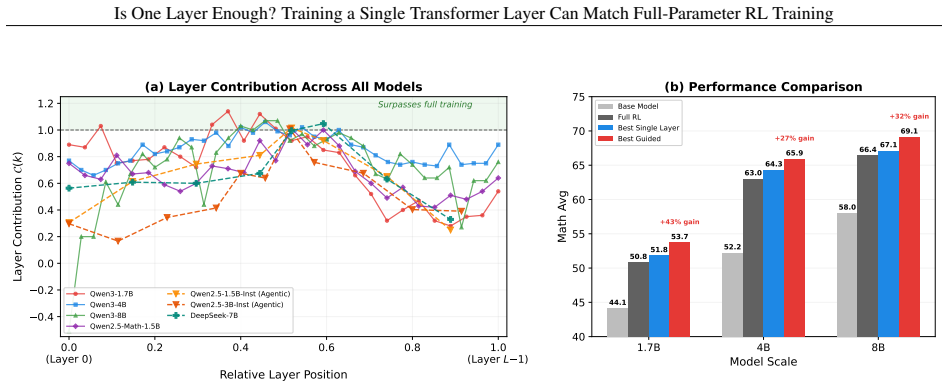
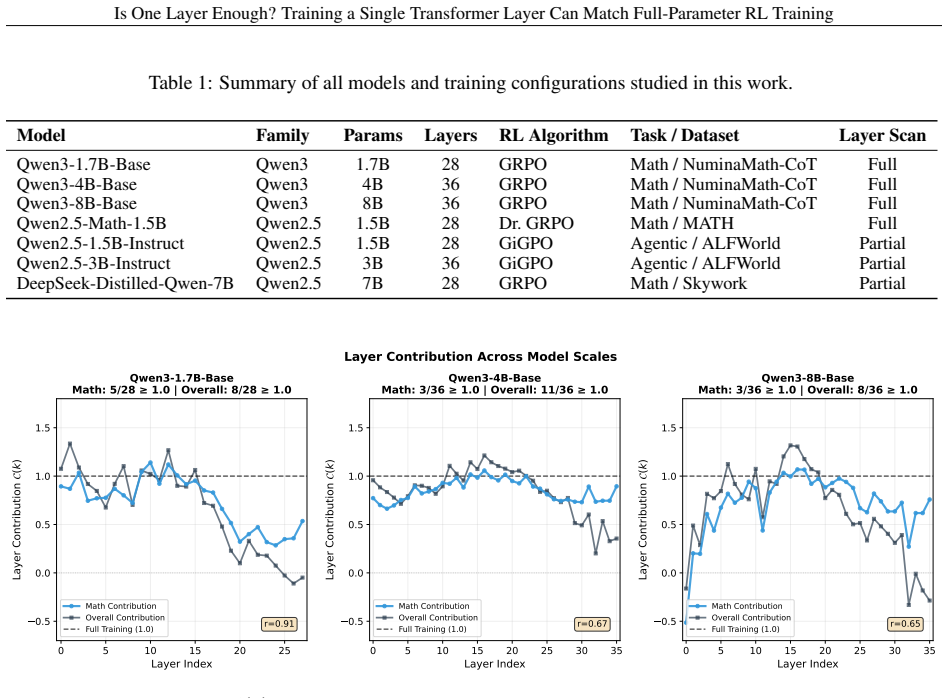
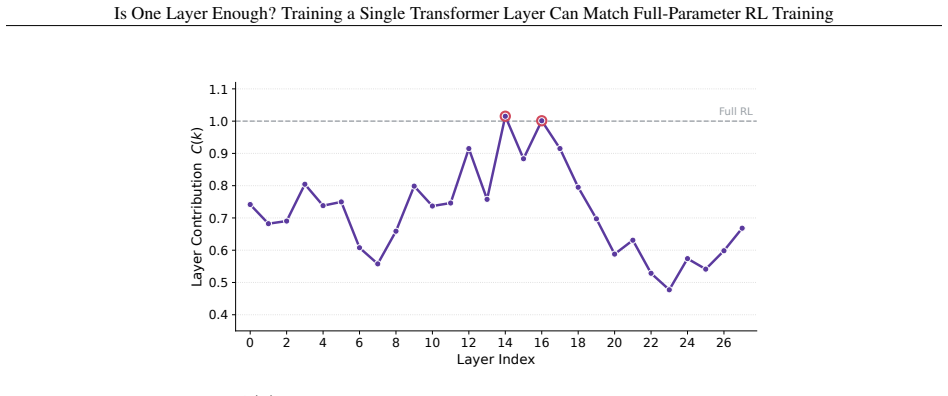
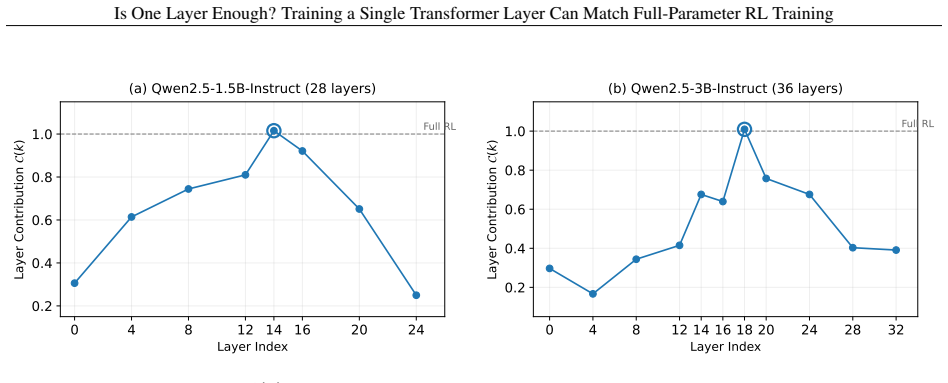
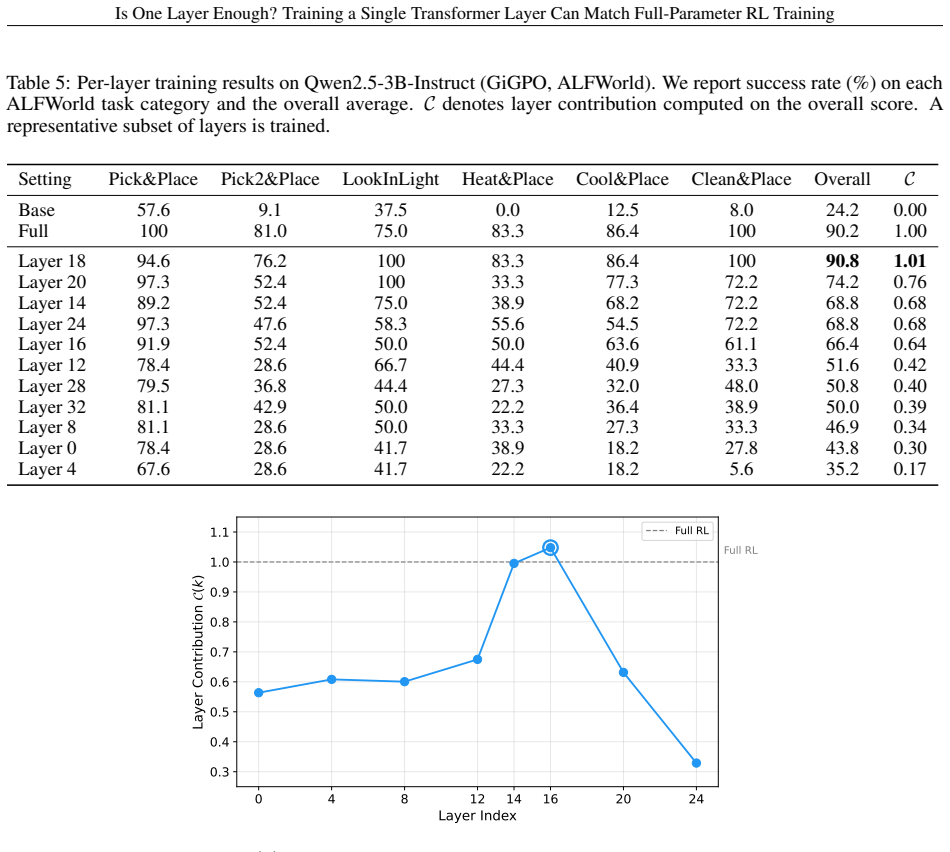
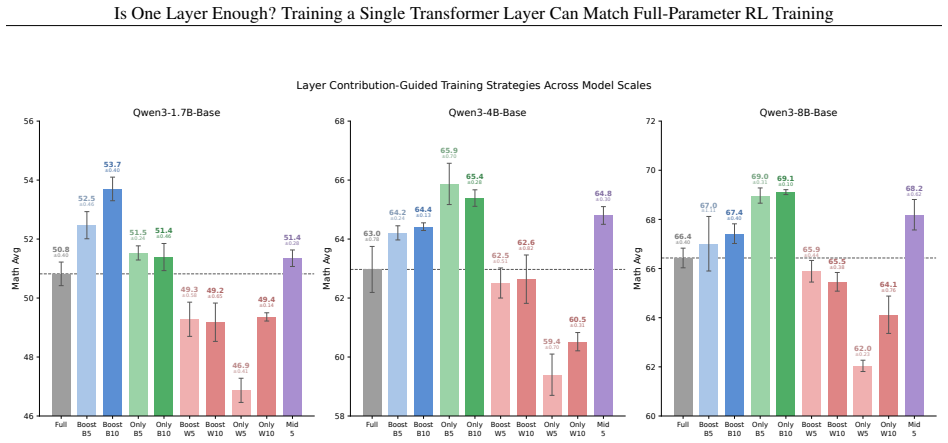
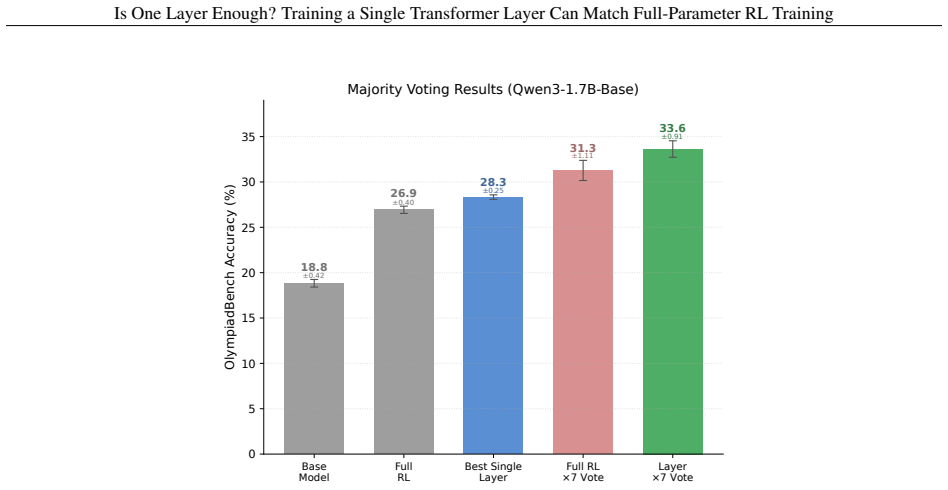
Across seven models, three RL algorithms, and tasks in math, code, and agentic settings, RL gains concentrate in a small subset of layers, frequently a single middle layer, such that training that layer alone recovers most or all of the improvement from full-parameter training.
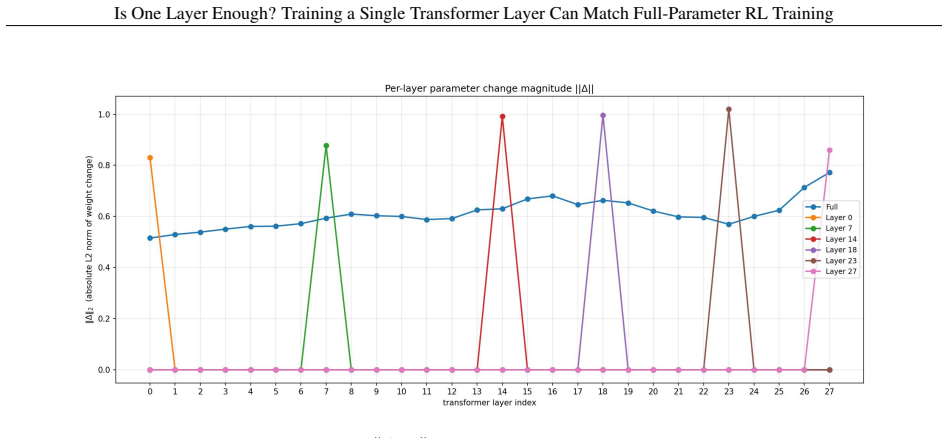
What carries the argument
layer contribution metric, defined as the fraction of full RL improvement recovered by training one layer in isolation with others frozen.
If this is right
- RL post-training can target only middle layers instead of all parameters for similar results.
- The high-contribution pattern remains stable across datasets, model families, and RL algorithms.
- Layers near the input and output ends contribute substantially less than middle layers.
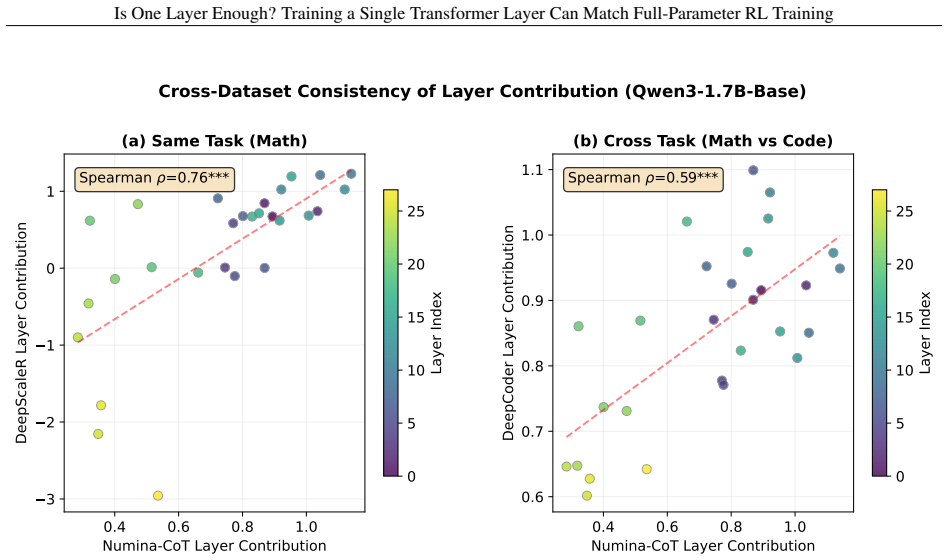
- Layer rankings derived from the metric stay consistent across different tasks.
Where Pith is reading between the lines
- Methods to locate high-contribution layers early could reduce total compute needed for RL post-training.
- The concentration finding raises the question of whether middle layers specialize in the adaptations RL induces.
- Uniform parameter updates may waste effort on low-impact layers in current practice.
Load-bearing premise
Gains measured when training one layer in isolation reflect that layer's contribution during simultaneous full-parameter training without important cross-layer interactions.
What would settle it
An experiment where combining updates to the top two layers produces substantially more improvement than the sum of their individual layer contributions.
Figures
read the original abstract
Reinforcement learning (RL) has become a central component of post-training large language models (LLMs), yet little is understood about how RL adaptation is distributed across transformer layers. Existing approaches typically update all model parameters uniformly, implicitly assuming that every layer contributes similarly to the gains obtained during RL post-training. In this work, we challenge this assumption through a systematic layer-wise study of RL training. Surprisingly, we find that training a single transformer layer can recover most of the gains achieved by full-parameter RL training, and in some cases even surpass it. To quantify this phenomenon, we introduce the quantity layer contribution, which measures the fraction of full RL improvement recovered by training a layer in isolation. Across seven models spanning two model families (Qwen3, Qwen2.5), three RL algorithms (GRPO, GiGPO, Dr. GRPO), and multiple task domains including mathematical reasoning, code generation, and agentic decision-making, we observe a remarkably stable pattern: RL gains are highly concentrated in a small subset of, and in many cases even a single, transformer layers. More strikingly, the same structural pattern consistently emerges: high-contribution layers concentrate in the middle of the transformer stack, while layers near the input and output ends contribute substantially less. The resulting layer rankings remain strongly correlated across datasets, tasks, model families, and RL algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that RL post-training gains in LLMs are highly concentrated in a small subset of (often a single middle) transformer layers. Training one layer in isolation recovers most or all of the gains from full-parameter RL training across seven models (Qwen3, Qwen2.5), three algorithms (GRPO, GiGPO, Dr. GRPO), and domains including math, code, and agentic tasks. They introduce a 'layer contribution' metric (fraction of full RL improvement recovered by isolated layer training) and report that high-contribution layers consistently appear in the middle of the stack with stable rankings across settings.
Significance. If the empirical pattern holds under the stated methodology, the result would be significant for understanding how RL adaptation is distributed in transformers and for designing more parameter-efficient RL fine-tuning methods. The reported consistency across models, algorithms, and tasks provides a broad empirical base; the introduction of a quantifiable 'layer contribution' metric is a useful framing device for future work on selective updates.
major comments (2)
- [Section 3 (Layer Contribution definition and experimental protocol)] The layer contribution metric (defined via isolated training of one layer with all others frozen) is load-bearing for the headline claim that 'one layer is enough.' The manuscript provides no experiments testing whether isolated gains are additive or whether non-additive cross-layer interactions (gradient interference, representation realignment, or compensatory plasticity) arise only under simultaneous full-parameter updates. Without such controls or an ablation showing that the sum of isolated contributions approximates full training, the metric may not accurately reflect each layer's role during standard RL training.
- [Section 4 (Results) and Appendix (training details)] Abstract and results sections report consistent patterns but give no details on statistical significance testing, variance across random seeds, or exact controls for training protocol differences (e.g., learning rate scaling, batch size, or optimizer state when only one layer is updated). These omissions make it difficult to assess whether the reported 'most of the gains' or 'surpass' cases are robust.
minor comments (2)
- [Section 3] Notation for 'layer contribution' should be formalized with an equation (e.g., C_l = (Perf_l - Perf_0) / (Perf_full - Perf_0)) to avoid ambiguity in how 'recovered fraction' is computed when isolated training exceeds full training.
- [Figures 2-5 and Tables 1-3] Figure captions and tables should explicitly state the number of runs per condition and whether error bars represent standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Section 3 (Layer Contribution definition and experimental protocol)] The layer contribution metric (defined via isolated training of one layer with all others frozen) is load-bearing for the headline claim that 'one layer is enough.' The manuscript provides no experiments testing whether isolated gains are additive or whether non-additive cross-layer interactions (gradient interference, representation realignment, or compensatory plasticity) arise only under simultaneous full-parameter updates. Without such controls or an ablation showing that the sum of isolated contributions approximates full training, the metric may not accurately reflect each layer's role during standard RL training.
Authors: The layer contribution metric is defined to measure the fraction of full RL improvement recovered by training one layer in isolation. This directly supports the empirical claim that a single middle layer suffices to recover most gains. While non-additive interactions may exist under joint updates, our results demonstrate that they are not required to obtain the reported performance; the isolated setting already matches or exceeds full training in many cases. We will add a clarifying paragraph in Section 3 noting that the metric quantifies isolated efficacy rather than providing an exact additive decomposition of full-parameter contributions. revision: partial
-
Referee: [Section 4 (Results) and Appendix (training details)] Abstract and results sections report consistent patterns but give no details on statistical significance testing, variance across random seeds, or exact controls for training protocol differences (e.g., learning rate scaling, batch size, or optimizer state when only one layer is updated). These omissions make it difficult to assess whether the reported 'most of the gains' or 'surpass' cases are robust.
Authors: We agree that explicit reporting of variance and protocol controls strengthens the results. The revised manuscript will expand the Appendix to include: (i) the number of random seeds (3–5) and standard-error bars on all figures, (ii) confirmation that single-layer experiments used identical learning rates, batch sizes, and optimizer states as the full-parameter baselines, and (iii) brief mention of statistical significance for the largest reported differences. revision: yes
Circularity Check
No circularity: purely empirical definition and measurement of layer contribution
full rationale
The paper reports direct experimental measurements of RL performance when training individual layers in isolation versus full-parameter updates. The layer contribution quantity is defined explicitly as the observed fraction of full RL gain recovered by each isolated run; this is a measurement, not a fitted parameter or derived prediction that reduces to its own inputs. No equations, ansatzes, uniqueness theorems, or self-citations are used to generate the reported results. The central claims rest on the experimental outcomes themselves across multiple models, algorithms, and tasks, with no load-bearing step that collapses by construction to a prior definition or fit within the paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transformer layers can be trained independently while freezing the remainder to isolate their contribution to RL gains
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.