Didact: A Cross-Domain Capability Discovery System for Defence
Pith reviewed 2026-06-27 21:53 UTC · model grok-4.3
The pith
Didact integrates defence documents and research into a knowledge graph that supports natural language policy queries with an interactive evidence trail.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
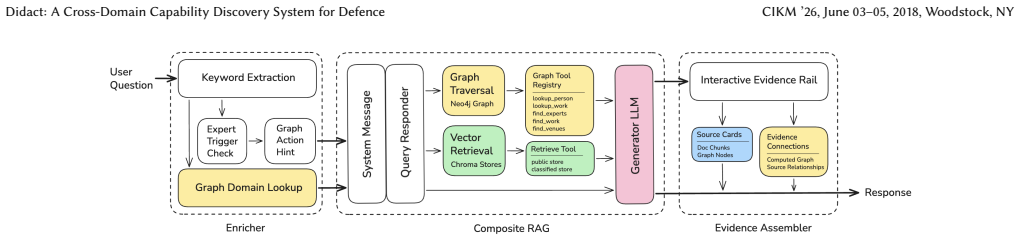
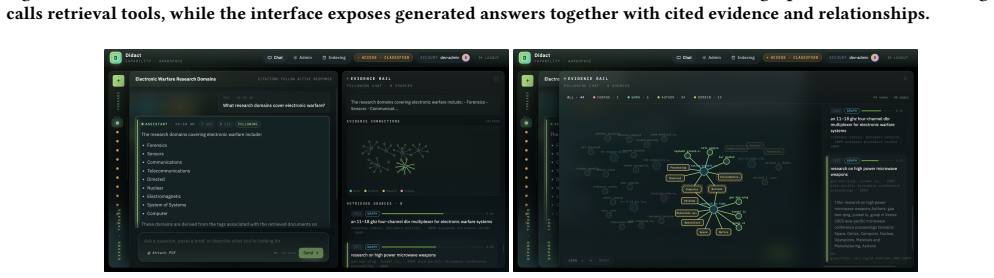
Didact integrates publicly available defence reports and policy documents from Australia with a purpose-built knowledge graph derived from Australian research publications. It provides natural language conversations for policy-oriented workflows and leverages a composite retrieval-augmented generation pipeline. A key feature of Didact is an interactive Evidence Rail that visualises retrieved evidence and source relationships. Evaluation of the output quality and runtime of Didact highlights its utility, while the system is presented as adaptable to other domains where knowledge is similarly fragmented.
What carries the argument
The composite retrieval-augmented generation pipeline over the knowledge graph, which supplies both generated answers and the Evidence Rail that makes source relationships visible for auditability.
If this is right
- Policymakers gain the ability to monitor evolving research and sector priorities across disjoint repositories without manual cross-referencing.
- Every generated response carries visible evidence links that allow direct audit of the underlying sources.
- Capability discovery tasks that previously required slow manual searches become conversational and faster.
- The same knowledge-graph-plus-pipeline structure can be reused in any other domain that stores knowledge in fragmented public documents.
Where Pith is reading between the lines
- If the Evidence Rail proves effective at building trust, comparable visual evidence interfaces could become standard for AI tools used in regulated policy work.
- Deployment at scale would need to handle ongoing document updates without rebuilding the entire graph each time.
- Adding non-public or classified material would require separate mechanisms for access control while preserving the audit trail.
Load-bearing premise
Combining heterogeneous public defence documents and research into one knowledge graph plus a composite retrieval pipeline will produce outputs that remain useful, accurate, and traceable without major errors introduced by data fragmentation or source quality differences.
What would settle it
Defence policymakers running real capability queries through the system and reporting frequent cases where answers cannot be traced to the correct source documents or contain clear inaccuracies traceable to the input materials.
Figures

read the original abstract
Policymakers in defence and defence-aligned sectors must monitor rapidly evolving research alongside sector priorities relevant to operational and strategic needs. In practice, these sources are fragmented across heterogeneous formats, disjoint repositories, and siloed update streams, making capability discovery slow and difficult to audit. We present Didact, a prototype that integrates publicly available defence reports and policy documents from Australia with a purpose-built knowledge graph derived from Australian research publications. Didact provides natural language conversations for policy-oriented workflows, and leverages a composite retrieval-augmented generation (RAG) pipeline. A key feature of Didact is an interactive Evidence Rail that visualises retrieved evidence and source relationships. Our evaluation of the output quality and runtime of Didact highlights its utility. While Didact has been co-developed as an academia-industry project for the Australian context, it is adaptable to other domains where knowledge is similarly fragmented. A demonstration video is available here:
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Didact, a prototype system integrating heterogeneous Australian defence reports, policy documents, and a knowledge graph derived from research publications. It supports natural language conversations via a composite RAG pipeline and features an interactive Evidence Rail for visualizing retrieved evidence and source relationships. The authors state that evaluation of output quality and runtime highlights the system's utility and note its potential adaptability to other domains with fragmented knowledge.
Significance. If substantiated, the system could address practical challenges in monitoring fragmented defence sources for policymakers by enabling auditable, conversational access. The Evidence Rail's visualization of source relationships is a potentially useful feature for traceability. However, without supporting data the practical significance remains unclear.
major comments (2)
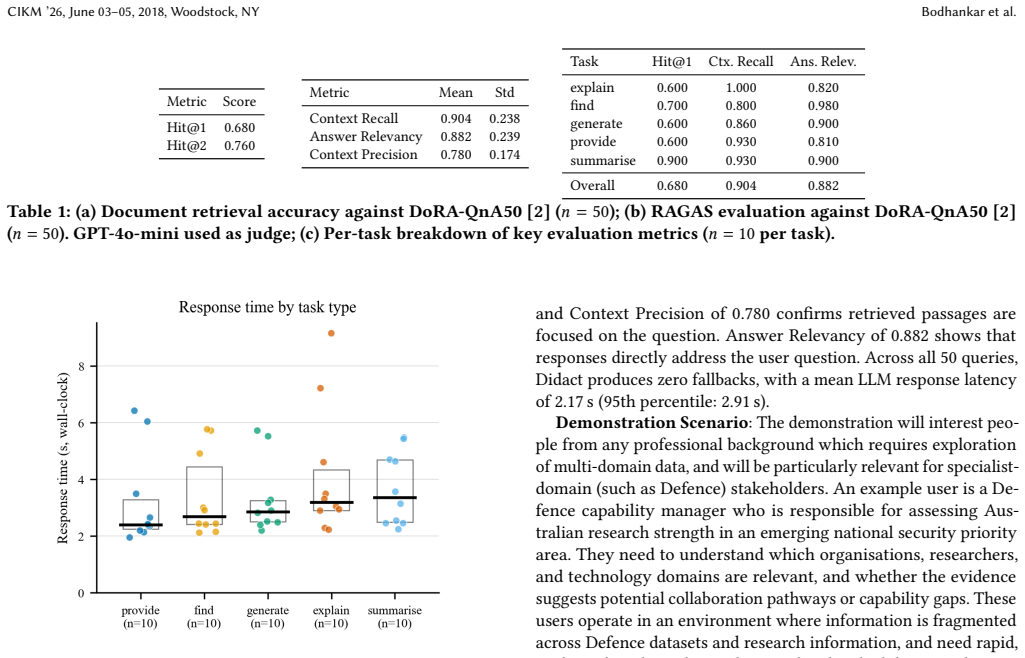
- [Evaluation section] Evaluation section: the claim that 'Our evaluation of the output quality and runtime of Didact highlights its utility' is unsupported because the section supplies no quantitative metrics (e.g., precision/recall, hallucination rates), baselines, expert-rated correctness scores, or error analysis for RAG accuracy, auditability, or robustness to data heterogeneity and fragmentation. This directly undermines the central utility claim.
- [Abstract and system description] Abstract and system description: the composite RAG pipeline and knowledge-graph integration are presented at a high level without details on handling source-quality issues or fragmentation, which is load-bearing for the assertion that outputs will be accurate and auditable for policymakers.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and agree that revisions are required to strengthen the manuscript.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section: the claim that 'Our evaluation of the output quality and runtime of Didact highlights its utility' is unsupported because the section supplies no quantitative metrics (e.g., precision/recall, hallucination rates), baselines, expert-rated correctness scores, or error analysis for RAG accuracy, auditability, or robustness to data heterogeneity and fragmentation. This directly undermines the central utility claim.
Authors: We agree that the evaluation section does not contain quantitative metrics such as precision/recall, hallucination rates, or expert-rated scores, and that the utility claim is therefore unsupported by the data presented. The current evaluation is limited to runtime measurements and qualitative examples. We will revise the evaluation section to remove or qualify the unsupported claim, add any available runtime and qualitative data with clearer limitations, and include an error analysis where feasible from existing prototype logs. revision: yes
-
Referee: [Abstract and system description] Abstract and system description: the composite RAG pipeline and knowledge-graph integration are presented at a high level without details on handling source-quality issues or fragmentation, which is load-bearing for the assertion that outputs will be accurate and auditable for policymakers.
Authors: The system description was kept high-level to emphasize the Evidence Rail and overall prototype concept. We acknowledge that this leaves the claims of accuracy and auditability insufficiently supported. We will expand the system description and methods sections with additional details on data preprocessing, source-quality checks, handling of fragmentation across repositories, and specific mechanisms in the composite RAG pipeline that support traceability and auditability. revision: yes
Circularity Check
No circularity: descriptive system paper with no derivations or load-bearing self-references
full rationale
The paper is a high-level description of a prototype RAG-based system for defence document retrieval. No equations, fitted parameters, predictions, or derivation chains exist. The single evaluation sentence is a qualitative claim without reduction to inputs or self-citations. This matches the default expectation of no circularity for non-mathematical system papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chroma. 2023. Chroma: Open-source search infrastructure for AI. https://www. trychroma.com/ Accessed 2026-06-03
2023
-
[2]
Bao Gia Doan, Aditya Joshi, Pantelis Elinas, Aarya Bodhankar, Oscar Leslie, Tom Marchant, and Flora Salim. 2026. A Benchmark Construction and Evaluation Framework for Specialist Domains: Case Study on Defense-related Documents. arXiv preprint arXiv:2604.17943(2026)
Pith/arXiv arXiv 2026
-
[3]
Shahul Es, Jithin James, Luis Espinosa Anke, and Steven Schockaert. 2024. Ra- gas: Automated evaluation of retrieval augmented generation. InProceedings of the 18th conference of the european chapter of the association for computational linguistics: system demonstrations. 150–158
2024
-
[4]
Max Franz, Christian T Lopes, Gerardo Huck, Yue Dong, Onur Sumer, and Gary D Bader. 2016. Cytoscape. js: a graph theory library for visualisation and analysis. Bioinformatics32, 2 (2016), 309–311
2016
-
[5]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, Haofen Wang, et al. 2023. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997 2, 1 (2023), 32
Pith/arXiv arXiv 2023
-
[6]
Rashid, Anisa Rula, Lukas Schmelzeisen, Juan Sequeda, Steffen Staab, and An- toine Zimmermann
Aidan Hogan, Eva Blomqvist, Michael Cochez, Claudia D’amato, Gerard De Melo, Claudio Gutierrez, Sabrina Kirrane, José Emilio Labra Gayo, Roberto Nav- igli, Sebastian Neumaier, Axel-Cyrille Ngonga Ngomo, Axel Polleres, Sabbir M. Rashid, Anisa Rula, Lukas Schmelzeisen, Juan Sequeda, Steffen Staab, and An- toine Zimmermann. 2021. Knowledge Graphs.Comput. Sur...
-
[7]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open- Domain Question Answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, 6769–6781. doi:10.18653/v1/2020.emn...
-
[8]
2024.LangGraph: Build Resilient Language Agents as Graphs
LangChain Inc. 2024.LangGraph: Build Resilient Language Agents as Graphs. https://github.com/langchain-ai/langgraph Open-source framework for building stateful and controllable AI agents
2024
-
[9]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks.Advances in Neural Information Processing Systems33 (2020), 9459–9474
2020
-
[10]
2026.Neo4j Graph Database
Neo4j, Inc. 2026.Neo4j Graph Database. https://neo4j.com/ Graph database management system for connected data
2026
-
[11]
Boci Peng, Yun Zhu, Yongchao Liu, Xiaohe Bo, Haizhou Shi, Chuntao Hong, Yan Zhang, and Siliang Tang. 2025. Graph retrieval-augmented generation: A survey. ACM Transactions on Information Systems44, 2 (2025), 1–52
2025
-
[12]
Jason Priem, Heather Piwowar, and Richard Orr. 2022. OpenAlex: A fully-open index of scholarly works, authors, venues, institutions, and concepts.arXiv preprint arXiv:2205.01833(2022)
Pith/arXiv arXiv 2022
-
[13]
2018.FastAPI
Sebastián Ramírez. 2018.FastAPI. https://fastapi.tiangolo.com
2018
-
[14]
Arnav Nishith Sharma, Khandakar Ashrafi Akbar, Bhavani Thuraisingham, and Latifur Khan. 2025. Enhancing Security Insights with KnowGen-RAG: Combining Knowledge Graphs, LLMs, and Multimodal Interpretability. InProceedings of the 2025 ACM International Workshop on Security and Privacy Analytics. 2–12
2025
-
[15]
Qinggang Zhang, Shengyuan Chen, Yuanchen Bei, Zheng Yuan, Huachi Zhou, Zijin Hong, Hao Chen, Yilin Xiao, Chuang Zhou, Junnan Dong, et al . 2025. A survey of graph retrieval-augmented generation for customized large language models.arXiv preprint arXiv:2501.13958(2025)
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.