Semantic-Anchored Evidential Fusion for Domain-Robust Whole-Slide Survival Analysis
Pith reviewed 2026-06-26 18:32 UTC · model grok-4.3
The pith
High-level semantic anchors from visual questions let survival models trained on one hospital generalize to others without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SAEFS derives semantic anchors from WSIs via Visual Question Answering, runs a dual-stream evidence extractor, models uncertainty with Dirichlet-based Subjective Logic, and fuses the semantic and visual evidence streams through a cautious conjunction rule, yielding survival estimates that remain accurate and reliable when trained on a single source domain and evaluated zero-shot on four unseen domains.
What carries the argument
Semantic anchors obtained via Visual Question Answering on pathology concepts, fused with visual evidence through cautious conjunction in Subjective Logic.
Load-bearing premise
High-level pathology semantics such as tumor grade and micro-environmental architecture remain consistent across different staining protocols and scanners.
What would settle it
Measurements showing that VQA-derived semantic features exhibit high cross-center divergence or that the fused model fails to improve C-index on the four unseen domains.
Figures
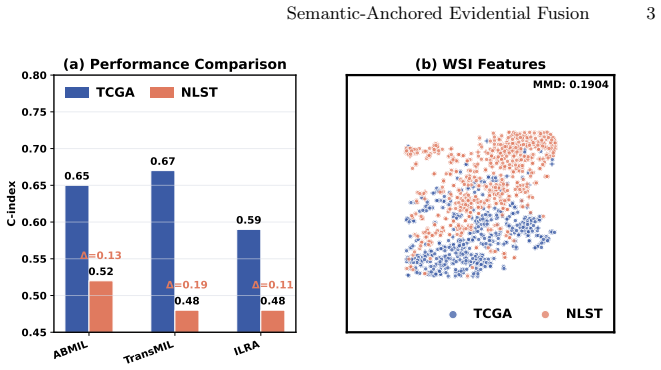
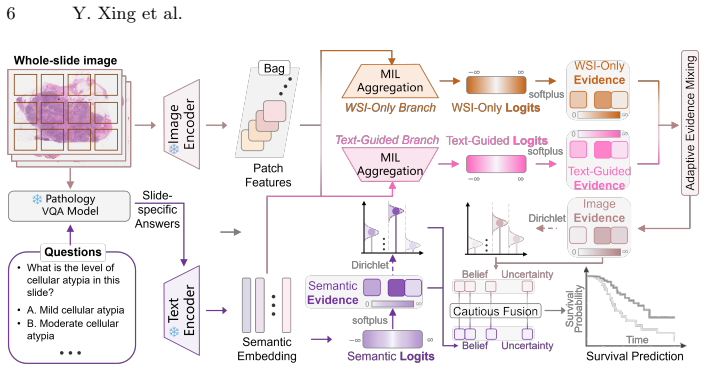
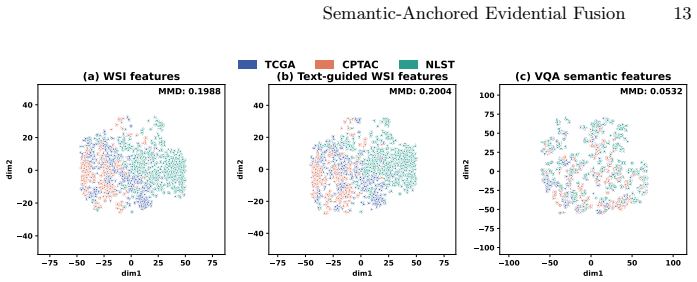
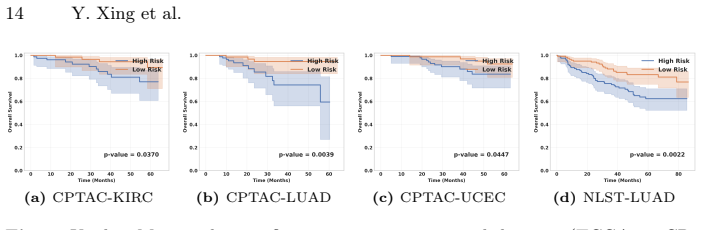
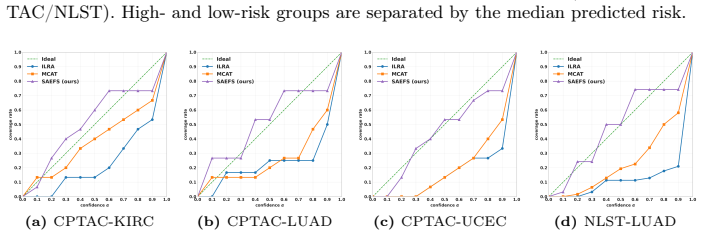
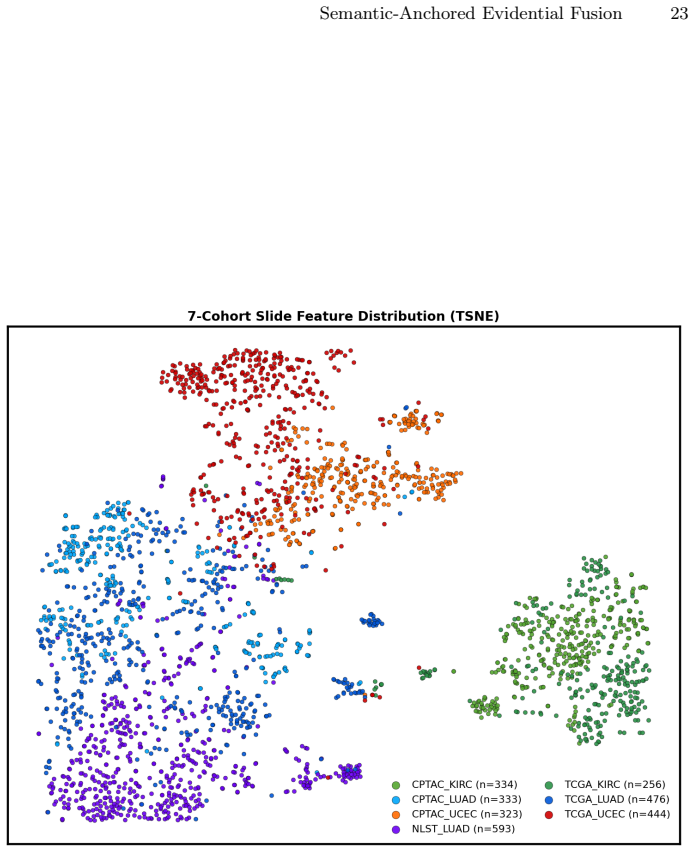
read the original abstract
Whole-slide images (WSIs) are widely used for computational cancer prognosis. However, most existing methods primarily focus on in-domain performance and fail to generalize across clinical centers. This limitation stems from their reliance on pixel-derived representations that are highly susceptible to domain-specific artifacts caused by staining protocols and scanner hardware. We hypothesize that high-level pathology semantics, such as tumor grade and micro-environmental architecture, provide a domain-invariant semantic representation that mirrors the robust diagnostic logic of human pathologists. Therefore, we propose a Semantic-Anchored Evidential Fusion Survival (SAEFS) framework, where SAEFS derives semantic anchors from WSIs via Visual Question Answering (VQA), employs a dual-stream WSI evidence extraction architecture, uses Dirichlet-based Subjective Logic to model uncertainty, and fuses semantic and visual evidence through a cautious conjunction rule to avoid overconfident fusion from correlated sources. Trained exclusively on one source domain and evaluated zero-shot across four unseen domains, SAEFS consistently outperforms state-of-the-art models both in prediction accuracy and reliability, improving the average C-index by 10.2%. Quantitative analyses further show that VQA-derived semantic features exhibit significantly lower cross-center divergence than pixel-derived features, highlighting their robustness for cross-center clinical applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Semantic-Anchored Evidential Fusion Survival (SAEFS) framework for whole-slide image (WSI) survival analysis. It extracts high-level semantic anchors (tumor grade, micro-environmental architecture) via Visual Question Answering (VQA), employs a dual-stream architecture for visual and semantic evidence, models uncertainty with Dirichlet-based subjective logic, and fuses the streams via a cautious conjunction rule. The method is trained exclusively on a single source domain and evaluated zero-shot on four unseen domains, reporting a 10.2% average C-index gain over state-of-the-art baselines together with lower cross-center feature divergence for the VQA-derived anchors.
Significance. If the domain-invariance of the VQA anchors and the attribution of the performance gain can be rigorously established, the work would address a practically important limitation in computational pathology—domain shift due to staining and scanner variation—without requiring multi-center training data. The explicit uncertainty modeling via subjective logic is a methodological strength that could improve reliability assessments in clinical settings.
major comments (3)
- [Experiments / Ablation studies] The central claim that VQA-derived semantic anchors remain domain-invariant (and drive the 10.2% C-index gain) is load-bearing, yet the manuscript provides no ablation that replaces the VQA anchors with purely visual features while retaining the dual-stream architecture, Dirichlet fusion, and cautious conjunction rule. Without this control, the performance improvement cannot be attributed to semantic invariance rather than other modeling choices. (Experiments / Ablation studies section)
- [Method, VQA and fusion subsections] The invariance hypothesis requires that the VQA component itself does not encode source-domain visual cues. The manuscript does not state whether the VQA model is a frozen off-the-shelf network or fine-tuned on the source-domain WSIs, nor does it report the VQA architecture, its pre-training corpus, or any domain-shift experiments on the VQA outputs alone. These omissions directly affect whether the reported lower cross-center divergence and zero-shot gains can be credited to the semantic anchors. (Method section, VQA and fusion subsections)
- [Results / Quantitative comparison] Table or figure reporting the 10.2% average C-index improvement (and the per-domain results) does not include the number of WSIs per center, the exact survival endpoints, the full list of baselines with their hyper-parameter settings, or statistical significance tests (e.g., paired Wilcoxon or DeLong test on C-index). These details are required to evaluate whether the gain is robust and reproducible. (Results / Quantitative comparison section)
minor comments (2)
- [Method] Notation for the Dirichlet concentration parameters and the cautious conjunction rule should be introduced with explicit equations and a short derivation or reference to the subjective-logic literature to improve readability for readers outside the evidential-reasoning community.
- [Figures] Figure captions for the cross-center divergence plots should explicitly state the divergence metric (e.g., MMD, Wasserstein) and the feature dimensionality being compared.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects for strengthening the attribution of our results and improving reproducibility. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experiments / Ablation studies] The central claim that VQA-derived semantic anchors remain domain-invariant (and drive the 10.2% C-index gain) is load-bearing, yet the manuscript provides no ablation that replaces the VQA anchors with purely visual features while retaining the dual-stream architecture, Dirichlet fusion, and cautious conjunction rule. Without this control, the performance improvement cannot be attributed to semantic invariance rather than other modeling choices. (Experiments / Ablation studies section)
Authors: We agree that this ablation is necessary to rigorously attribute the performance gains to the semantic invariance of the VQA anchors rather than other architectural choices. In the revised manuscript, we will add an ablation study that replaces the VQA-derived semantic stream with additional purely visual features while retaining the dual-stream architecture, Dirichlet-based subjective logic, and cautious conjunction rule. This will directly test whether the 10.2% C-index improvement and reduced cross-center divergence are driven by the semantic anchors. revision: yes
-
Referee: [Method, VQA and fusion subsections] The invariance hypothesis requires that the VQA component itself does not encode source-domain visual cues. The manuscript does not state whether the VQA model is a frozen off-the-shelf network or fine-tuned on the source-domain WSIs, nor does it report the VQA architecture, its pre-training corpus, or any domain-shift experiments on the VQA outputs alone. These omissions directly affect whether the reported lower cross-center divergence and zero-shot gains can be credited to the semantic anchors. (Method section, VQA and fusion subsections)
Authors: We acknowledge these details were omitted. The VQA model is a frozen off-the-shelf network not fine-tuned on source-domain WSIs; we will explicitly state this in the revised Method section along with the specific architecture, pre-training corpus, and any relevant hyperparameters. Additionally, we will include domain-shift experiments on the VQA outputs alone (e.g., cross-center divergence metrics and zero-shot performance of VQA features) to support the invariance claim. revision: yes
-
Referee: [Results / Quantitative comparison] Table or figure reporting the 10.2% average C-index improvement (and the per-domain results) does not include the number of WSIs per center, the exact survival endpoints, the full list of baselines with their hyper-parameter settings, or statistical significance tests (e.g., paired Wilcoxon or DeLong test on C-index). These details are required to evaluate whether the gain is robust and reproducible. (Results / Quantitative comparison section)
Authors: We agree these details are essential for reproducibility and assessing robustness. In the revised Results section, we will expand the relevant table/figure to report the number of WSIs per center, exact survival endpoints used, the complete list of baselines with their hyper-parameter settings, and statistical significance tests (paired Wilcoxon signed-rank tests on C-index values across domains). revision: yes
Circularity Check
No significant circularity; empirical zero-shot claims are externally testable.
full rationale
The paper advances an empirical framework (SAEFS) with training restricted to one source domain and zero-shot evaluation on four unseen domains, reporting a 10.2% average C-index gain. No equations, fitted parameters, or self-citations are presented that reduce the reported performance or the claimed domain-invariance of VQA anchors to quantities defined by construction within the same work. The hypothesis that high-level semantics are domain-invariant is stated as motivation and supported by post-hoc divergence measurements, but these measurements are independent of the fusion rules and do not create a definitional loop. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- Dirichlet concentration parameters
- Cautious conjunction rule parameters
axioms (2)
- domain assumption VQA-derived semantics are domain-invariant across staining and scanner variations
- domain assumption Semantic and visual evidence streams are correlated yet the cautious rule prevents overconfident fusion
Reference graph
Works this paper leans on
-
[1]
Nature medicine30(3), 850–862 (2024)
Chen, R.J., Ding, T., Lu, M.Y., Williamson, D.F., Jaume, G., Song, A.H., Chen, B., Zhang, A., Shao, D., Shaban, M., et al.: Towards a general-purpose foundation model for computational pathology. Nature medicine30(3), 850–862 (2024)
2024
-
[2]
In: Proceedings of the IEEE/CVF interna- tional conference on computer vision
Chen, R.J., Lu, M.Y., Weng, W.H., Chen, T.Y., Williamson, D.F., Manz, T., Shady, M., Mahmood, F.: Multimodal co-attention transformer for survival pre- diction in gigapixel whole slide images. In: Proceedings of the IEEE/CVF interna- tional conference on computer vision. pp. 4015–4025 (2021)
2021
-
[3]
Cancer cell40(8), 865–878 (2022)
Chen, R.J., Lu, M.Y., Williamson, D.F., Chen, T.Y., Lipkova, J., Noor, Z., Shaban, M., Shady, M., Williams, M., Joo, B., et al.: Pan-cancer integrative histology- genomic analysis via multimodal deep learning. Cancer cell40(8), 865–878 (2022)
2022
-
[4]
In: 11th International Conference on Learning Representations (ICLR 2023) (2023)
Cui, Y., Liu, Z., Liu, X., Liu, X., Wang, C., Kuo, T.W., Xue, C.J., Chan, A.B.: Bayes-mil: A new probabilistic perspective on attention-based multiple instance learning for whole slide images. In: 11th International Conference on Learning Representations (ICLR 2023) (2023)
2023
-
[5]
In: Classic works of the Dempster-Shafer theory of belief functions, pp
Dempster, A.P.: Upper and lower probabilities induced by a multivalued mapping. In: Classic works of the Dempster-Shafer theory of belief functions, pp. 57–72. Springer (2008)
2008
-
[6]
Artificial intelligence172(2-3), 234–264 (2008)
Denœux, T.: Conjunctive and disjunctive combination of belief functions induced by nondistinct bodies of evidence. Artificial intelligence172(2-3), 234–264 (2008)
2008
-
[7]
Journal of proteome research14(6), 2707–2713 (2015)
Edwards, N.J., Oberti, M., Thangudu, R.R., Cai, S., McGarvey, P.B., Jacob, S., Madhavan, S., Ketchum, K.A.: The cptac data portal: a resource for cancer pro- teomics research. Journal of proteome research14(6), 2707–2713 (2015)
2015
-
[8]
MedRxiv pp
Filiot, A., Ghermi, R., Olivier, A., Jacob, P., Fidon, L., Camara, A., Mac Kain, A., Saillard, C., Schiratti, J.B.: Scaling self-supervised learning for histopathology with masked image modeling. MedRxiv pp. 2023–07 (2023)
2023
-
[9]
In: international conference on machine learn- ing
Gal, Y., Ghahramani, Z.: Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In: international conference on machine learn- ing. pp. 1050–1059. PMLR (2016)
2016
-
[10]
medRxiv pp
Gao, Z., He, K., Su, W., Machado, I.P., McGough, W., Jimenez-Linan, M., Rous, B., Wang, C., Li, C., Pang, X., et al.: Alpaca: Adapting llama for pathology context analysis to enable slide-level question answering. medRxiv pp. 2025–04 (2025)
2025
-
[11]
The journal of machine learning research13(1), 723–773 (2012)
Gretton, A., Borgwardt, K.M., Rasch, M.J., Schölkopf, B., Smola, A.: A kernel two-sample test. The journal of machine learning research13(1), 723–773 (2012)
2012
-
[12]
IEEE transactions on pattern analysis and machine intelligence45(2), 2551–2566 (2022)
Han, Z., Zhang, C., Fu, H., Zhou, J.T.: Trusted multi-view classification with dynamic evidential fusion. IEEE transactions on pattern analysis and machine intelligence45(2), 2551–2566 (2022)
2022
-
[13]
Medical Image Analysis97, 103223 (2024)
Huang, L., Ruan, S., Xing, Y., Feng, M.: A review of uncertainty quantification in medical image analysis: Probabilistic and non-probabilistic methods. Medical Image Analysis97, 103223 (2024)
2024
-
[14]
In: International Conference on Belief Functions
Huang, L., Xing, Y., Denoeux, T., Feng, M.: An evidential time-to-event prediction model based on gaussian random fuzzy numbers. In: International Conference on Belief Functions. pp. 49–57. Springer (2024)
2024
-
[15]
IEEE Transactions on Fuzzy Systems (2025)
Huang, L., Xing, Y., Lin, Q., Duan, J., Ruan, S., Feng, M.: Esurvfusion: An ev- idential multimodal survival fusion model based on epistemic random fuzzy sets. IEEE Transactions on Fuzzy Systems (2025)
2025
-
[16]
International Journal of Ap- proximate Reasoning181, 109403 (2025) Semantic-Anchored Evidential Fusion 17
Huang, L., Xing, Y., Mishra, S., Denœux, T., Feng, M.: Evidential time-to-event prediction with calibrated uncertainty quantification. International Journal of Ap- proximate Reasoning181, 109403 (2025) Semantic-Anchored Evidential Fusion 17
2025
-
[17]
Nature medicine29(9), 2307–2316 (2023)
Huang, Z., Bianchi, F., Yuksekgonul, M., Montine, T.J., Zou, J.: A visual–language foundation model for pathology image analysis using medical twitter. Nature medicine29(9), 2307–2316 (2023)
2023
-
[18]
Advances in neural information processing systems36, 37995– 38017 (2023)
Ikezogwo, W., Seyfioglu, S., Ghezloo, F., Geva, D., Sheikh Mohammed, F., Anand, P.K., Krishna, R., Shapiro, L.: Quilt-1m: One million image-text pairs for histopathology. Advances in neural information processing systems36, 37995– 38017 (2023)
2023
-
[19]
In: International conference on machine learning
Ilse,M.,Tomczak,J.,Welling,M.:Attention-baseddeepmultipleinstancelearning. In: International conference on machine learning. pp. 2127–2136. PMLR (2018)
2018
-
[20]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
Jaume, G., Vaidya, A., Chen, R., Williamson, D., Liang, P., Mahmood, F.: Mod- eling dense multimodal interactions between biological pathways and histology for survival prediction. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
2024
-
[21]
IEEE Transactions on Medical Imaging (2025)
Jiang, S., Cai, L., Gan, Z., Wang, Y., Tang, G., Zhang, Y.: Uncertainty-aware survival analysis with dirichlet distribution for multi-scale pathology and genomics. IEEE Transactions on Medical Imaging (2025)
2025
-
[22]
arXiv preprint arXiv:2501.18055 (2025)
de Jong, E.D., Marcus, E., Teuwen, J.: Current pathology foundation models are unrobust to medical center differences. arXiv preprint arXiv:2501.18055 (2025)
arXiv 2025
-
[23]
Springer Publishing Company, Incorporated (2018)
Jsang, A.: Subjective Logic: A formalism for reasoning under uncertainty. Springer Publishing Company, Incorporated (2018)
2018
-
[24]
Journal of digital imaging33(4), 1034–1040 (2020)
Kumar, N., Gupta, R., Gupta, S.: Whole slide imaging (wsi) in pathology: current perspectives and future directions. Journal of digital imaging33(4), 1034–1040 (2020)
2020
-
[25]
Advances in neural information pro- cessing systems30(2017)
Lakshminarayanan, B., Pritzel, A., Blundell, C.: Simple and scalable predictive uncertainty estimation using deep ensembles. Advances in neural information pro- cessing systems30(2017)
2017
-
[26]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, B., Li, Y., Eliceiri, K.W.: Dual-stream multiple instance learning network for whole slide image classification with self-supervised contrastive learning. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14318–14328 (2021)
2021
-
[27]
Advances in Neural Information Processing Systems36, 28541–28564 (2023)
Li, C., Wong, C., Zhang, S., Usuyama, N., Liu, H., Yang, J., Naumann, T., Poon, H., Gao, J.: Llava-med: Training a large language-and-vision assistant for biomedicine in one day. Advances in Neural Information Processing Systems36, 28541–28564 (2023)
2023
-
[28]
International Journal of Computer Vision133(1), 31–64 (2025)
Liang, J., He, R., Tan, T.: A comprehensive survey on test-time adaptation under distribution shifts. International Journal of Computer Vision133(1), 31–64 (2025)
2025
-
[29]
In: International conference on machine learning
Liang, J., Hu, D., Feng, J.: Do we really need to access the source data? source hy- pothesis transfer for unsupervised domain adaptation. In: International conference on machine learning. pp. 6028–6039. PMLR (2020)
2020
-
[30]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Liu,J.,Li,H.,Yang,C.,Deutges,M.,Sadafi,A.,You,X.,Breininger,K.,Navab,N., Schüffler, P.J.: Hasd: hierarchical adaption for pathology slide-level domain-shift. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 332–342. Springer (2025)
2025
-
[31]
Nature Medicine30, 863–874 (2024)
Lu, M.Y., Chen, B., Williamson, D.F., Chen, R.J., Liang, I., Ding, T., Jaume, G., Odintsov, I., Le, L.P., Gerber, G., et al.: A visual-language foundation model for computational pathology. Nature Medicine30, 863–874 (2024)
2024
-
[32]
Nature634(8033), 466–473 (2024) 18 Y
Lu, M.Y., Chen, B., Williamson, D.F., Chen, R.J., Zhao, M., Chow, A.K., Ikemura, K., Kim, A., Pouli, D., Patel, A., et al.: A multimodal generative ai copilot for human pathology. Nature634(8033), 466–473 (2024) 18 Y. Xing et al
2024
-
[33]
In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition
Lu, M.Y., Chen, B., Zhang, A., Williamson, D.F., Chen, R.J., Ding, T., Le, L.P., Chuang, Y.S., Mahmood, F.: Visual language pretrained multiple instance zero- shot transfer for histopathology images. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition. pp. 19764–19775 (2023)
2023
-
[34]
Nature biomedical engineering5(6), 555–570 (2021)
Lu, M.Y., Williamson, D.F., Chen, T.Y., Chen, R.J., Barbieri, M., Mahmood, F.: Data-efficient and weakly supervised computational pathology on whole-slide images. Nature biomedical engineering5(6), 555–570 (2021)
2021
-
[35]
In: 2009 IEEE international symposium on biomedical imaging: from nano to macro
Macenko, M., Niethammer, M., Marron, J.S., Borland, D., Woosley, J.T., Guan, X., Schmitt, C., Thomas, N.E.: A method for normalizing histology slides for quan- titative analysis. In: 2009 IEEE international symposium on biomedical imaging: from nano to macro. pp. 1107–1110. IEEE (2009)
2009
-
[36]
Proceedings of the National Academy of Sciences115(13), E2970–E2979 (2018)
Mobadersany, P., Yousefi, S., Amgad, M., Gutman, D.A., Barnholtz-Sloan, J.S., Velázquez Vega, J.E., Brat, D.J., Cooper, L.A.: Predicting cancer outcomes from histology and genomics using convolutional networks. Proceedings of the National Academy of Sciences115(13), E2970–E2979 (2018)
2018
-
[37]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[38]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Raza, M., Azam, A., Qaiser, T., Rajpoot, N.: Ps3: A multimodal transformer inte- grating pathology reports with histology images and biological pathways for cancer survival prediction. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 22175–22186 (2025)
2025
-
[39]
IEEE Computer graphics and applications21(5), 34–41 (2002)
Reinhard, E., Adhikhmin, M., Gooch, B., Shirley, P.: Color transfer between im- ages. IEEE Computer graphics and applications21(5), 34–41 (2002)
2002
-
[40]
In: International Conference on Medical Image Computing and Computer- Assisted Intervention
Ren, Q., Wang, Y., Fang, R., Ling, H., You, C.: Otsurv: A novel multiple instance learning framework for survival prediction with heterogeneity-aware optimal trans- port. In: International Conference on Medical Image Computing and Computer- Assisted Intervention. pp. 439–449. Springer (2025)
2025
-
[41]
Cell reports23(1), 181–193 (2018)
Saltz,J.,Gupta,R.,Hou,L.,Kurc,T.,Singh,P.,Nguyen,V.,Samaras,D.,Shroyer, K.R., Zhao, T., Batiste, R., et al.: Spatial organization and molecular correlation of tumor-infiltrating lymphocytes using deep learning on pathology images. Cell reports23(1), 181–193 (2018)
2018
-
[42]
Advances in neural information processing systems31(2018)
Sensoy, M., Kaplan, L., Kandemir, M.: Evidential deep learning to quantify classi- fication uncertainty. Advances in neural information processing systems31(2018)
2018
-
[43]
Princeton university press (2020)
Shafer, G.: A mathematical theory of evidence. Princeton university press (2020)
2020
-
[44]
Advances in neural information processing systems34, 2136–2147 (2021)
Shao, Z., Bian, H., Chen, Y., Wang, Y., Zhang, J., Ji, X., et al.: Transmil: Trans- former based correlated multiple instance learning for whole slide image classifica- tion. Advances in neural information processing systems34, 2136–2147 (2021)
2021
-
[45]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Shou, Y., Cao, X., Yan, P., Hui, Q., Zhao, Q., Meng, D.: Graph domain adaptation with dual-branch encoder and two-level alignment for whole slide image-based survival prediction. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 19925–19935 (2025)
2025
-
[46]
Nature Reviews Bioengineering1(12), 930–949 (2023)
Song, A.H., Jaume, G., Williamson, D.F., Lu, M.Y., Vaidya, A., Miller, T.R., Mah- mood, F.: Artificial intelligence for digital and computational pathology. Nature Reviews Bioengineering1(12), 930–949 (2023)
2023
-
[47]
New England Journal of Medicine365(5), 395–409 (2011)
Team, N.L.S.T.R.: Reduced lung-cancer mortality with low-dose computed tomo- graphic screening. New England Journal of Medicine365(5), 395–409 (2011)
2011
-
[48]
Medical image analysis58, 101544 (2019)
Tellez, D., Litjens, G., Bándi, P., Bulten, W., Bokhorst, J.M., Ciompi, F., Van Der Laak, J.: Quantifying the effects of data augmentation and stain color nor- Semantic-Anchored Evidential Fusion 19 malization in convolutional neural networks for computational pathology. Medical image analysis58, 101544 (2019)
2019
-
[49]
Contemporary Oncol- ogy/Współczesna Onkologia2015(1), 68–77 (2015)
Tomczak, K., Czerwińska, P., Wiznerowicz, M.: Review the cancer genome atlas (tcga): an immeasurable source of knowledge. Contemporary Oncol- ogy/Współczesna Onkologia2015(1), 68–77 (2015)
2015
-
[50]
arXiv preprint arXiv:2302.13971 (2023)
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023)
Pith/arXiv arXiv 2023
-
[51]
IEEE transactions on medical imaging35(8), 1962–1971 (2016)
Vahadane, A., Peng, T., Sethi, A., Albarqouni, S., Wang, L., Baust, M., Steiger, K., Schlitter, A.M., Esposito, I., Navab, N.: Structure-preserving color normalization and sparse stain separation for histological images. IEEE transactions on medical imaging35(8), 1962–1971 (2016)
1962
-
[52]
arXiv preprint arXiv:2006.10726 (2020)
Wang, D., Shelhamer, E., Liu, S., Olshausen, B., Darrell, T.: Tent: Fully test-time adaptation by entropy minimization. arXiv preprint arXiv:2006.10726 (2020)
Pith/arXiv arXiv 2006
-
[53]
Medical image analysis81, 102559 (2022)
Wang, X., Yang, S., Zhang, J., Wang, M., Zhang, J., Yang, W., Huang, J., Han, X.: Transformer-based unsupervised contrastive learning for histopathological image classification. Medical image analysis81, 102559 (2022)
2022
-
[54]
In: The Eleventh International Conference on Learning Representations (2023)
Xiang, J., Zhang, J.: Exploring low-rank property in multiple instance learning for whole slide image classification. In: The Eleventh International Conference on Learning Representations (2023)
2023
-
[55]
arXiv preprint arXiv:2510.00053 (2025)
Xing, Y., Huang, L., Ma, J., Hong, R., Qiu, J., Liu, P., He, K., Fu, H., Feng, M.: Dpsurv: Dual-prototype evidential fusion for uncertainty-aware and interpretable whole-slide image survival prediction. arXiv preprint arXiv:2510.00053 (2025)
Pith/arXiv arXiv 2025
-
[56]
In: Proceedings of the IEEE/CVF international conference on computer vision
Xu, Y., Chen, H.: Multimodal optimal transport-based co-attention transformer with global structure consistency for survival prediction. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 21241–21251 (2023)
2023
-
[57]
In: Proceedings of the IEEE/CVF international conference on computer vision
Yang, S., Wang, Y., Van De Weijer, J., Herranz, L., Jui, S.: Generalized source-free domain adaptation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 8978–8987 (2021)
2021
-
[58]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhang, H., Meng, Y., Zhao, Y., Qiao, Y., Yang, X., Coupland, S.E., Zheng, Y.: Dtfd-mil: Double-tier feature distillation multiple instance learning for histopathol- ogy whole slide image classification. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18802–18812 (2022)
2022
-
[59]
In: European conference on computer vision
Zhang, Y., Li, H., Sun, Y., Zheng, S., Zhu, C., Yang, L.: Attention-challenging mul- tiple instance learning for whole slide image classification. In: European conference on computer vision. pp. 125–143. Springer (2024)
2024
-
[60]
not assessable in this slide
Zhu, X., Yao, J., Zhu, F., Huang, J.: Wsisa: Making survival prediction from whole slide histopathological images. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 7234–7242 (2017) 20 Y. Xing et al. 6 Appendix 6.1 Semantic Anchor Generation via Slide-Level VQA Slide-Level Vision-Language ModelTo generate semantic anch...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.