IRDS: Interpretable RLVR Data Selection via Verifier-Coupled Sparse Autoencoder Coverage
Pith reviewed 2026-06-29 14:45 UTC · model grok-4.3
The pith
IRDS selects RLVR training data on sparse autoencoder clusters using a verifier-coupled coverage objective to raise accuracy on math reasoning benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
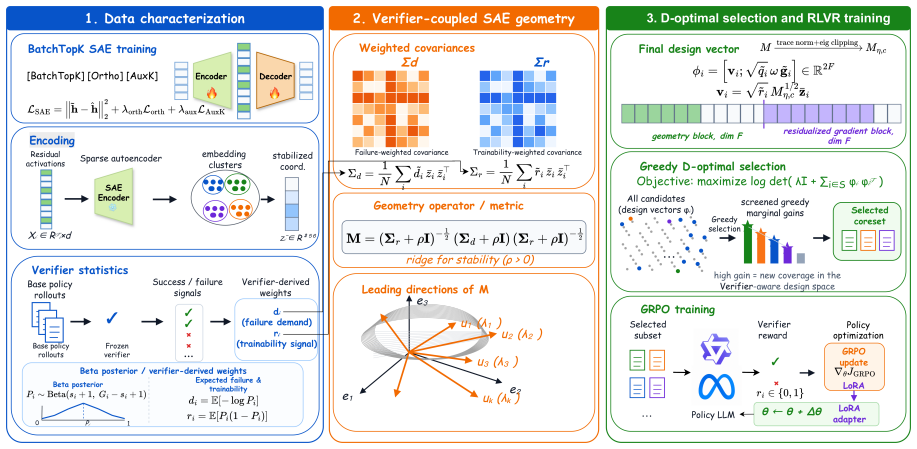
IRDS selects RLVR training instances on a sparse autoencoder cluster basis so the selection itself is auditable on recognizable problem motifs. To select instances the model both fails on and can still learn from, it introduces a verifier-coupled coverage objective on the SAE basis and solves it by greedy log-determinant maximization.
What carries the argument
The verifier-coupled coverage objective on the SAE basis, solved by greedy log-determinant maximization, which ensures both interpretability through motif clusters and effective identification of learnable failures.
If this is right
- IRDS achieves the highest overall accuracy across six math reasoning benchmarks.
- It exceeds the strongest baseline by 3.9 and 4.0 percentage points on the two Qwen models.
- It exceeds the strongest baseline by 0.5 percentage points on Llama-3.1-8B.
- It runs an order of magnitude cheaper than the trajectory-based baseline.
Where Pith is reading between the lines
- The same cluster-based selection could be tested on non-math domains to check whether problem motifs transfer.
- If clusters prove stable across model sizes, they might serve as a shared vocabulary for auditing training data in other verifiable-reward settings.
Load-bearing premise
That SAE-derived clusters correspond to recognizable, auditable problem motifs and that the verifier-coupled coverage objective reliably identifies instances the model fails on yet can still learn from.
What would settle it
Applying IRDS to a held-out model and benchmark set and measuring no accuracy gain over the strongest existing baseline would falsify the performance claim.
Figures
read the original abstract
Reinforcement learning with verifiable rewards (RLVR) has become a key technique for en- hancing LLM reasoning, yet its data ineffi- ciency remains a major bottleneck. Existing methods address this problem only partially, each missing at least one of subset-level cov- erage, verifier signal use, or interpretability. To address this gap, we present IRDS (Inter- pretable RLVR Data Selection), which selects RLVR training instances on a sparse autoen- coder (SAE) cluster basis so the selection itself is auditable on recognizable problem motifs. To select instances the model both fails on and can still learn from, we introduce a verifier- coupled coverage objective on the SAE basis and solve it by greedy log-determinant max- imization. Experiments on three instruction- tuned models and six math reasoning bench- marks show that IRDS achieves the highest overall accuracy, exceeding the strongest base- line by +3.9/+4.0 pp on the two Qwen models and by +0.5 pp on Llama-3.1-8B, while run- ning an order of magnitude cheaper than the trajectory-based baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces IRDS (Interpretable RLVR Data Selection), a method that selects training instances for reinforcement learning with verifiable rewards (RLVR) on the basis of sparse autoencoder (SAE) clusters. The selection uses a verifier-coupled coverage objective solved via greedy log-determinant maximization, with the goal of choosing instances the model fails on yet can still learn from while keeping the selection auditable via recognizable problem motifs. Experiments on three instruction-tuned models and six math reasoning benchmarks are reported to show IRDS attaining the highest overall accuracy, exceeding the strongest baseline by +3.9/+4.0 pp on the two Qwen models and +0.5 pp on Llama-3.1-8B, at an order of magnitude lower cost than a trajectory-based baseline.
Significance. If the reported gains prove robust under full experimental reporting, the work would be significant for data-efficient RLVR by combining SAE-based interpretability with a coverage objective that incorporates verifier signals. The order-of-magnitude computational saving relative to trajectory baselines and the explicit focus on auditable clusters are concrete strengths that could influence practical data curation pipelines.
major comments (2)
- Abstract: performance numbers (+3.9/+4.0 pp on Qwen models, +0.5 pp on Llama-3.1-8B) are stated without any experimental details, error bars, ablation studies, statistical tests, or description of the six benchmarks and three models, rendering the central superiority claim impossible to evaluate from the provided text.
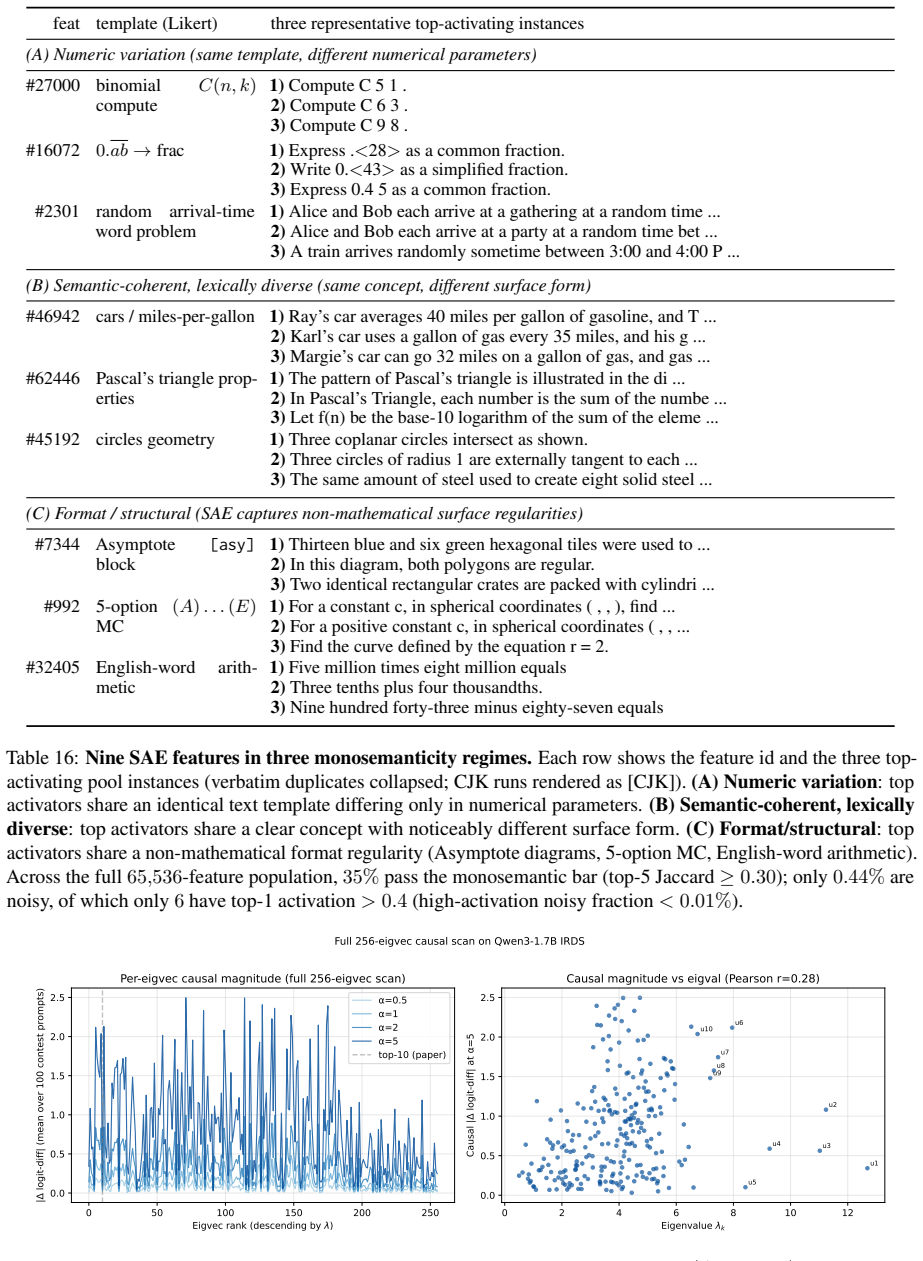
- Abstract: the claim that SAE-derived clusters enable selection on 'recognizable problem motifs' and that the verifier-coupled objective 'reliably identifies instances the model fails on yet can still learn from' is presented as a core contribution, yet no cluster examples, motif validation, or failure-mode analysis is supplied, leaving the interpretability and selection reliability assumptions untested.
minor comments (1)
- Abstract: hyphenation artifacts appear in 'en- hancing' and 'in- efficiency'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below. The full manuscript supplies the experimental details and supporting analyses referenced in the abstract; we agree the abstract itself can be strengthened for standalone clarity.
read point-by-point responses
-
Referee: [—] Abstract: performance numbers (+3.9/+4.0 pp on Qwen models, +0.5 pp on Llama-3.1-8B) are stated without any experimental details, error bars, ablation studies, statistical tests, or description of the six benchmarks and three models, rendering the central superiority claim impossible to evaluate from the provided text.
Authors: We agree that the abstract, constrained by length, omits these details. The full paper specifies the three models and six benchmarks in Section 4.1, reports results with error bars across three random seeds in Table 1, presents ablations in Section 5, and includes paired statistical tests in Section 4.3. We will revise the abstract to include a concise description of the experimental setup. revision: yes
-
Referee: [—] Abstract: the claim that SAE-derived clusters enable selection on 'recognizable problem motifs' and that the verifier-coupled objective 'reliably identifies instances the model fails on yet can still learn from' is presented as a core contribution, yet no cluster examples, motif validation, or failure-mode analysis is supplied, leaving the interpretability and selection reliability assumptions untested.
Authors: The abstract summarizes the claims; the full manuscript supplies the supporting material in Section 3.2 (cluster examples with recognizable motifs and human validation) and Section 4.4 (failure-mode analysis linking verifier signals to learnable instances). If additional examples or quantitative motif validation metrics are desired, we can expand these sections. revision: partial
Circularity Check
No significant circularity; method uses external verifier and standard SAE optimization
full rationale
The abstract and provided context describe IRDS as selecting data via SAE clusters with a verifier-coupled coverage objective solved by greedy log-determinant maximization. No equations, fitted parameters renamed as predictions, or self-citation chains are shown that reduce the central claim to its inputs by construction. The reported accuracy gains are presented as empirical outcomes on external benchmarks, not forced by definition or internal fitting. This matches the default expectation of a non-circular paper; the reader's score of 2.0 is consistent with minor self-citation potential but no load-bearing reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
FineScope: SAE-guided data selection en- ables domain-specific LLM pruning and fine-tuning. Preprint, arXiv:2505.00624. Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nicholas L. Turner, Cem Anil, Carson Denison, Amanda Askell, and 1 others. 2023. Towards monosemanticity: De- composing language models with dictionary...
-
[3]
InInternational Conference on Learning Representations
Let’s verify step by step. InInternational Conference on Learning Representations. Ilya Loshchilov and Frank Hutter. 2019. Decoupled weight decay regularization. InInternational Confer- ence on Learning Representations. Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Y . Tang, Manan Roongta, Colin Cai, Jef- frey Luo, Tianjun Zhang, Erran Li Li...
-
[4]
Improving data efficiency for LLM rein- forcement fine-tuning through difficulty-targeted on- line data selection and rollout replay.Preprint, arXiv:2506.05316. Xinyu Tang, Zhenduo Zhang, Yurou Liu, Wayne Xin Zhao, Zujie Wen, Zhiqiang Zhang, and Jun Zhou
-
[5]
X., Wen, Z., Zhang, Z., and Zhou, J
Towards high data efficiency in reinforce- ment learning with verifiable reward.Preprint, arXiv:2509.01321. Shubham Toshniwal, Wei Du, Ivan Moshkov, Branislav Kisacanin, Alexan Ayrapetyan, and Igor Gitman
-
[6]
arXiv preprint arXiv:2410.01560 , year=
OpenMathInstruct-2: Accelerating AI for math with massive open-source instruction data. Preprint, arXiv:2410.01560. Mengzhou Xia, Sadhika Malladi, Suchin Gururangan, Sanjeev Arora, and Danqi Chen. 2024a. Less: Select- ing influential data for targeted instruction tuning. In International Conference on Machine Learning. Tingyu Xia, Bowen Yu, Kai Dang, An Y...
-
[7]
InInternational Confer- ence on Learning Representations
ReClor: A reading comprehension dataset requiring logical reasoning. InInternational Confer- ence on Learning Representations. Yongcheng Zeng, Zexu Sun, Bokai Ji, Erxue Min, Hengyi Cai, Shuaiqiang Wang, Dawei Yin, Haifeng Zhang, Xu Chen, and Jun Wang. 2025. CurES: From gradient analysis to efficient curriculum learning for reasoning LLMs.Preprint, arXiv:2...
-
[8]
Decoding set- tings match the in-domain protocol (mean@16 for HE/RC, pass@1 for LCB) under each benchmark’s standard prompt format; no system prompt is in- jected
for Python code generation, LiveCodeBench (LCB) (Jain et al., 2025) for contest-level coding, and ReClor (RC) (Yu et al., 2020) for reading- comprehension multiple choice. Decoding set- tings match the in-domain protocol (mean@16 for HE/RC, pass@1 for LCB) under each benchmark’s standard prompt format; no system prompt is in- jected. D Budget-sweep per-be...
2025
-
[9]
The PPO clip ratio is 0.2, the KL coefficient against the frozen reference policy is 10−3, and the entropy coefficient is 10−3
(β1=0.9, β2=0.999, weight decay 0.1) with learning rate 5×10 −6, 5 warmup steps, and gradi- ent clip norm 1.0. The PPO clip ratio is 0.2, the KL coefficient against the frozen reference policy is 10−3, and the entropy coefficient is 10−3. All experiments are conducted on 8× NVIDIA H20 GPUs. We monitor validation on MATH500 with n=16 samples per problem du...
2000
-
[10]
task feature
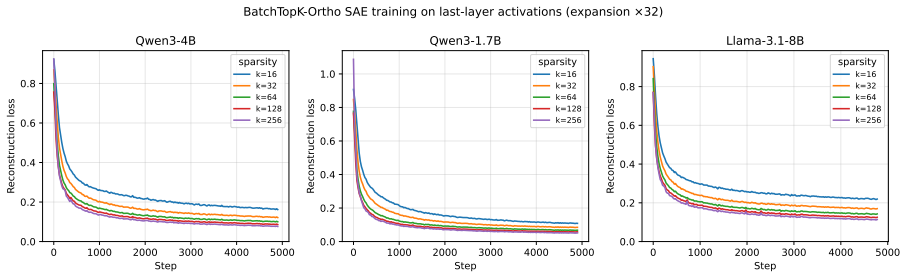
on the latent embedding with k=256. The fixed seed 0 produces the cluster labels reported throughout the paper. Cluster sizes range from 65 to 520 (median 143.5); mean within-cluster cosine similarity is 0.428. Latents outside the frequency band carry label −1 and contribute zero cluster mass. Per-instance cluster activations.The cluster- activation matri...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.