Learning from Acquisition: Metadata-driven Multimodal Pre-training for Cardiac MRI
Pith reviewed 2026-06-30 09:29 UTC · model grok-4.3
The pith
Metadata recorded during cardiac MRI scans supplies effective textual supervision for contrastive pre-training of image encoders.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
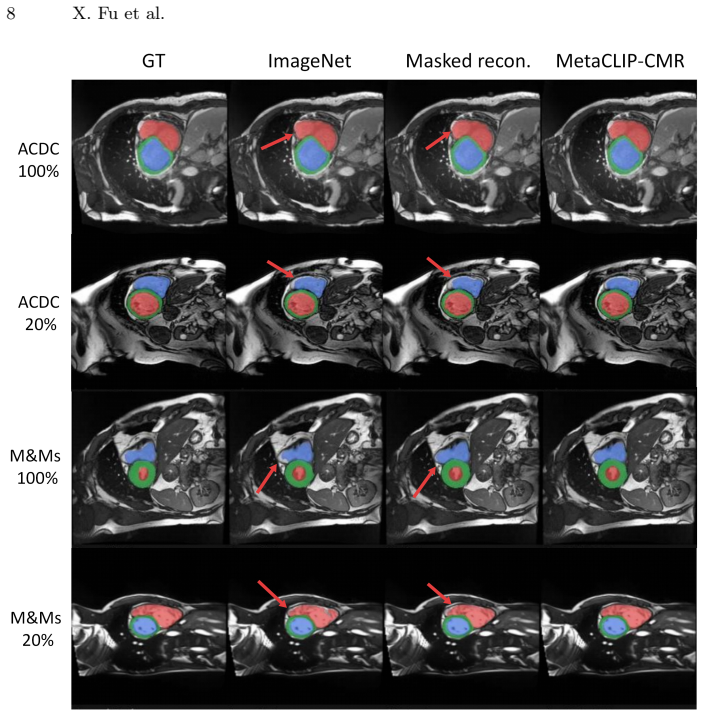
MetaCLIP-CMR converts five routine acquisition metadata fields into textual supervision inside a contrastive language-image pre-training loop; the resulting image encoder achieves higher accuracy on modality and cine-view classification than ImageNet or masked-reconstruction baselines and records the highest Dice scores on ACDC and M&Ms short-axis segmentation under both full-data and 20-percent fine-tuning regimes, all while using less than one percent of the pre-training images required by recent large-scale image-only CMR models.
What carries the argument
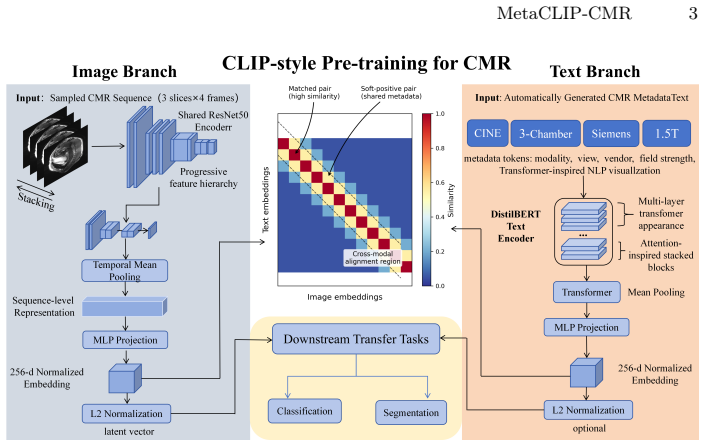
MetaCLIP-CMR, the CLIP-style contrastive framework that turns five acquisition metadata fields into paired text for image representation learning.
If this is right
- The encoder outperforms ImageNet and masked-reconstruction initializations on both modality classification and cine-view classification.
- It records the highest Dice scores for cardiac segmentation on the ACDC and M&Ms cine short-axis datasets under full-data and limited-data fine-tuning.
- Comparable segmentation accuracy is reached with less than one percent of the image volume used by recent large-scale image-focused CMR pre-training models.
- Metadata already logged at acquisition time can be turned into effective supervision without additional labeling effort.
Where Pith is reading between the lines
- The same metadata-to-text conversion could be applied to other modalities such as CT or ultrasound where acquisition parameters are routinely stored.
- Hospital archives of past scans could serve as ready-made pre-training corpora, lowering the barrier to building domain-specific medical imaging models.
- Gains may shrink if downstream data come from scanners or protocols whose metadata distributions diverge strongly from the pre-training set.
Load-bearing premise
The five metadata fields supply consistent, low-noise semantic signal that aligns reliably with visual content across the pre-training corpus and downstream datasets.
What would settle it
A controlled experiment in which the metadata-trained encoder underperforms standard image-only pre-training on a segmentation benchmark whose metadata statistics differ markedly from the original training distribution would falsify the claim.
Figures
read the original abstract
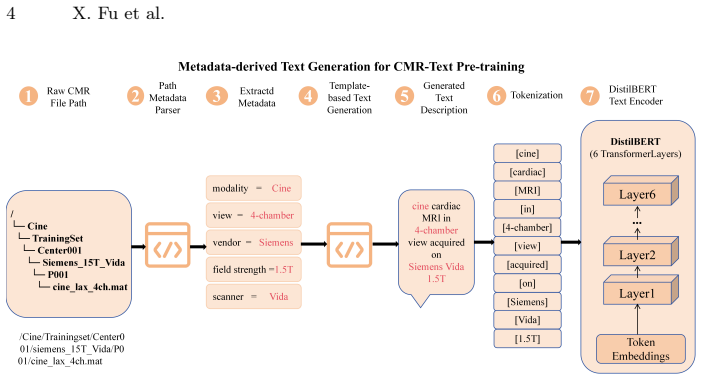
Cardiac magnetic resonance imaging (CMR) routinely records structured acquisition metadata, yet most CMR foundation models rely primarily on image-only pre-training and leave this naturally available source of weak semantic supervision largely underexplored. We propose MetaCLIP-CMR, a metadata-driven framework based on Contrastive Language--Image Pre-training (CLIP), which converts imaging modality, anatomical view, scanner vendor, field strength, and scanner model into textual supervision for CMR representation learning. The pretrained image encoder is evaluated on imaging modality classification, cine view classification, and cardiac segmentation. MetaCLIP-CMR achieves 86.8% modality accuracy and 86.5% cine view accuracy, clearly outperforming ImageNet and masked reconstruction initialisations. For downstream cardiac segmentation, MetaCLIP-CMR consistently obtains the highest Dice score across the evaluated ACDC and M&Ms cine short-axis (SAX) settings under both full-data and 20% fine-tuning regimes. Compared with recent image-focused large-scale CMR pre-training models, MetaCLIP-CMR achieves comparable ACDC segmentation performance, while requiring less than 1% of their pre-training image scale. These results suggest that metadata learning offers a natural and easy-to-use strategy for transforming routinely recorded acquisition information into effective supervision for foundation-level CMR representation learning, highlighting the promise of metadata-driven multimodal pre-training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MetaCLIP-CMR, a CLIP-based multimodal pre-training method that leverages five types of CMR acquisition metadata (imaging modality, anatomical view, scanner vendor, field strength, and scanner model) converted into text prompts for contrastive learning with the image encoder. The pretrained encoder is shown to achieve 86.8% accuracy on modality classification and 86.5% on cine view classification, outperforming ImageNet and masked reconstruction initializations. On downstream cardiac segmentation tasks using ACDC and M&Ms datasets for cine short-axis views, it achieves the highest Dice scores in both full-data and 20% fine-tuning settings, while using less than 1% of the pre-training images compared to recent large-scale image-focused CMR models.
Significance. If the results hold under proper verification, the work demonstrates that routinely recorded acquisition metadata can provide effective weak supervision for learning transferable CMR representations. This offers a data-efficient alternative to large-scale image-only pre-training and could influence practical strategies for foundation models in medical imaging where metadata is abundant.
major comments (2)
- [Abstract] Abstract: The reported performance metrics (86.8% modality accuracy, 86.5% view accuracy, and highest Dice scores on ACDC/M&Ms under full and 20% regimes) are presented without any description of experimental protocol, data splits, baseline implementations, number of runs, or statistical tests. This absence is load-bearing because the central claims rest on these unverifiable empirical results.
- [Experiments] Experiments (implied): No quantitative analysis, statistics, or checks are provided on the noise level, consistency, or cross-dataset drift of the five metadata fields used as text supervision. Since the contrastive pre-training and its transfer to segmentation rely on these fields supplying low-noise, visually aligned semantics, the lack of validation directly undermines interpretation of the reported gains over baselines.
minor comments (2)
- [Abstract] Abstract: The phrase 'recent image-focused large-scale CMR pre-training models' should include explicit citations to allow readers to assess the scale comparison (<1% pre-training images).
- [Methods] The manuscript would benefit from a dedicated subsection on metadata preprocessing and prompt construction to clarify how the five fields are converted into text.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive feedback. We address each major comment point-by-point below, clarifying the manuscript content and outlining revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported performance metrics (86.8% modality accuracy, 86.5% view accuracy, and highest Dice scores on ACDC/M&Ms under full and 20% regimes) are presented without any description of experimental protocol, data splits, baseline implementations, number of runs, or statistical tests. This absence is load-bearing because the central claims rest on these unverifiable empirical results.
Authors: We agree that the abstract, constrained by length, omits protocol details. The full manuscript (Sections 3 and 4) specifies the experimental protocol, including data splits for pre-training and downstream tasks on ACDC/M&Ms, baseline implementations (ImageNet, masked reconstruction), and evaluation under full-data and 20% regimes. Multiple runs with standard deviations are reported for segmentation Dice scores. To improve clarity, we will revise the abstract to include a brief statement on evaluation settings and direct readers to the methods and experiments sections for full protocol, splits, and statistical details. revision: yes
-
Referee: [Experiments] Experiments (implied): No quantitative analysis, statistics, or checks are provided on the noise level, consistency, or cross-dataset drift of the five metadata fields used as text supervision. Since the contrastive pre-training and its transfer to segmentation rely on these fields supplying low-noise, visually aligned semantics, the lack of validation directly undermines interpretation of the reported gains over baselines.
Authors: This is a valid observation. The manuscript relies on the observed classification accuracies (86.8% modality, 86.5% view) as indirect evidence of metadata reliability but does not include explicit quantitative analysis of noise levels, inter-field consistency, or cross-dataset drift. We will add a dedicated analysis subsection reporting metadata consistency statistics across the pre-training corpus and downstream datasets, including any observed label noise or drift, to better support interpretation of the pre-training gains. revision: yes
Circularity Check
Empirical contrastive pipeline with external benchmarks; no derivations or self-referential reductions
full rationale
The manuscript describes a metadata-to-text CLIP-style pre-training pipeline evaluated on modality/view classification and downstream segmentation (ACDC, M&Ms) under full and 20% regimes. No equations, parameter fits, or predictions appear; results are measured against external baselines (ImageNet, masked reconstruction, other large-scale CMR models) rather than being defined by internal quantities. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked. The work is self-contained against external tasks, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Contrastive loss pulls matching image-text pairs together and pushes non-matching pairs apart in embedding space
Reference graph
Works this paper leans on
-
[1]
https://doi.org/10.1109/TMI.2018.2837502
Bernard, O., Lalande, A., Zotti, C., Cervenansky, F., Yang, X., Heng, P.A., Cetin, I., Lekadir, K., Camara, O., Gonzalez Ballester, M.A., Sanroma, G., Napel, S., Petersen, S., Tziritas, G., Grinias, E., Khened, M., Kollerathu, V.A., Krishnamurthi, G., Rohe, M.M., Pennec, X., Sermesant, M., Isensee, F., Jager, P., Maier-Hein, K.H., Full, P.M., Wolf, I., En...
-
[2]
IEEE Transactions on Medical Imaging40(12), 3543–3554 (2021)
Campello, V.M., Gkontra, P., Izquierdo, C., Martin-Isla, C., Sojoudi, A., Full, P.M., Maier-Hein, K., Zhang, Y., He, Z., Ma, J., Parreno, M., Albiol, A., Kong, F., Shadden, S.C., Acero, J.C., Sundaresan, V., Saber, M., Elattar, M., Li, H., Menze, B., Khader, F., Haarburger, C., Scannell, C.M., Veta, M., Carscadden, A., Punithakumar, K.,Liu, X.,Tsaftaris, ...
-
[3]
Communi- cations Medicine (05 2026)
Fu, Y., Bai, W., Yi, W., Manisty, C., Bhuva, A.N., Treibel, T.A., Moon, J.C., Clarkson, M.J., Davies, R.H., Hu, Y.: Development and validation of a versatile foundation model for cine cardiac magnetic resonance image analysis. Communi- cations Medicine (05 2026). https://doi.org/10.1038/s43856-026-01636-0
-
[4]
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners (2021),https://arxiv.org/abs/2111.06377
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition (2015),https://arxiv.org/abs/1512.03385
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[6]
Journal of Cardiovascular Magnetic Resonance27(2), 101967 (2025)
Jacob, A.J., Borgohain, I., Chitiboi, T., Sharma, P., Comaniciu, D., Rueckert, D.: Towards a cardiovascular magnetic resonance foundation model for multi-task car- diac image analysis. Journal of Cardiovascular Magnetic Resonance27(2), 101967 (2025). https://doi.org/10.1016/j.jocmr.2025.101967
-
[7]
Medical Image Analysis88, 102869 (2023)
Li, L., Ding, W., Huang, L., Zhuang, X., Grau, V.: Multi-modality car- diac image computing: A survey. Medical Image Analysis88, 102869 (2023). https://doi.org/10.1016/j.media.2023.102869
-
[8]
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization (2019),https: //arxiv.org/abs/1711.05101
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[9]
Radiology310(1), e231269 (2024)
Morales, M.A., Manning, W.J., Nezafat, R.: Present and future in- novations in ai and cardiac mri. Radiology310(1), e231269 (2024). https://doi.org/10.1148/radiol.231269
-
[10]
Radiology314(2), e240597 (2025)
Paschali, M., Chen, Z., Blankemeier, L., Varma, M., Youssef, A., Blueth- gen, C., Langlotz, C., Gatidis, S., Chaudhari, A.: Foundation models in ra- diology: What, how, why, and why not. Radiology314(2), e240597 (2025). https://doi.org/10.1148/radiol.240597, pMID: 39903075
-
[11]
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision (2021),https://arxiv.org/abs/ 2103.00020 MetaCLIP-CMR 11
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Sanh, V., Debut, L., Chaumond, J., Wolf, T.: Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter (2020),https://arxiv.org/abs/1910.01108
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[13]
Nature Biomedical Engineering9(4), 521–538 (2025)
Sun, Y., Wang, L., Li, G., Lin, W., Wang, L.: A foundation model for en- hancing magnetic resonance images and downstream segmentation, registra- tion and diagnostic tasks. Nature Biomedical Engineering9(4), 521–538 (2025). https://doi.org/10.1038/s41551-024-01283-7
-
[14]
Wang, Z., Huang, M., Shi, Z., Hu, H., Lan, L., Zhang, H., Li, Y., Hu, X., Lu, Q., Zhu, Z., Yao, Q., Dai, Y., Wang, F., Wu, Y., Lyu, J., Gao, Q., Xu, G., Zhang, Z., Zhang, H., Li, Q., Wang, G., He, T., Lan, L., Li, S., Xue, L., Sun, M., Lyu, Y., Hu, J., Zhu, J., Ahmad, R., Bu, Z., Qian, X., Cai, G., Cao, R., Cai, W., Xu, C., Ren, Y., Yu, F., Ma, S., Xu, Z....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Radiology: Artificial Intelligence7(2), e240443 (2025)
Wang, Z., Wang, F., Qin, C., Lyu, J., Ouyang, C., Wang, S., Li, Y., Yu, M., Zhang, H., Guo, K., Shi, Z., Li, Q., Xu, Z., Zhang, Y., Li, H., Hua, S., Chen, B., Sun, L., Sun, M., Li, Q., Chu, Y.H., Bai, W., Qin, J., Zhuang, X., Prieto, C., Young, A., Markl, M., Wang, H., Wu, L.M., Yang, G., Qu, X., Wang, C.: Cmrxrecon2024: A multimodality, multiview k-space...
-
[16]
Zhang, S., Xu, Y., Usuyama, N., Xu, H., Bagga, J., Tinn, R., Preston, S., Rao, R., Wei, M., Valluri, N., Wong, C., Tupini, A., Wang, Y., Mazzola, M., Shukla, S., Liden, L., Gao, J., Crabtree, A., Piening, B., Bifulco, C., Lungren, M.P., Naumann, T., Wang, S., Poon, H.: Biomedclip: a multimodal biomedical foundation model pretrained from fifteen million sc...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Medical Image Analysis106, 103756 (2025)
Zhang, Y., Hager, P., Liu, C., Shit, S., Chen, C., Rueckert, D., Pan, J.: Towards cardiac mri foundation models: Comprehensive visual-tabular representations for whole-heart assessment and beyond. Medical Image Analysis106, 103756 (2025). https://doi.org/10.1016/j.media.2025.103756
-
[18]
Medical Image Analysis 102, 103551 (2025)
Zhao, Z., Liu, Y., Wu, H., Wang, M., Li, Y., Wang, S., Teng, L., Liu, D., Cui, Z., Wang, Q., Shen, D.: Clip in medical imaging: A survey. Medical Image Analysis 102, 103551 (2025). https://doi.org/10.1016/j.media.2025.103551
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.