Higher-Order Token Interactions via Quantum Attention
Pith reviewed 2026-06-27 09:39 UTC · model grok-4.3
The pith
A single shallow quantum attention head represents order-k token correlations that one classical self-attention layer cannot match under standard resource bounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
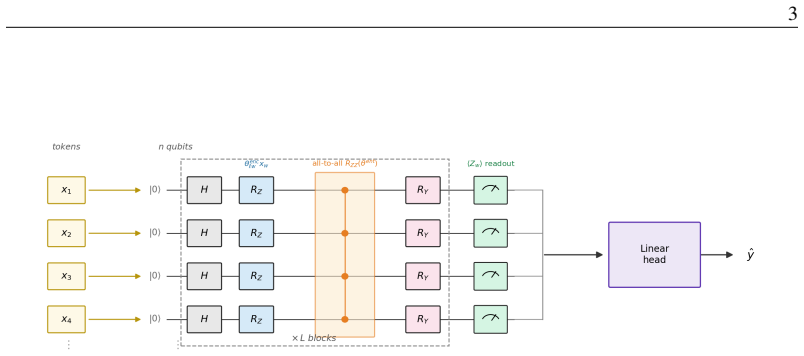
Quantum Higher-Order Attention (QHA) is a shallow quantum attention head that, via data re-uploading and an all-to-all non-Clifford entangler, synthesizes order-k token interactions inside the circuit and exposes them through a local single-qubit read-out. It proves that any single standard self-attention layer with embedding dimension m, H heads and p-bit precision satisfying mHp=o(N/log log N) cannot represent the order-k correlation family that one QHA head represents with circuit depth O(log k) using O(k) two-qubit gates, and it establishes a trainability guarantee for the local-design instantiation yielding gradient variance Omega(1/poly(n)) with O(log n) depth.
What carries the argument
Quantum Higher-Order Attention (QHA) head, a shallow quantum circuit that uses data re-uploading together with an all-to-all non-Clifford entangler to synthesize order-k interactions, exposed by local single-qubit readout.
If this is right
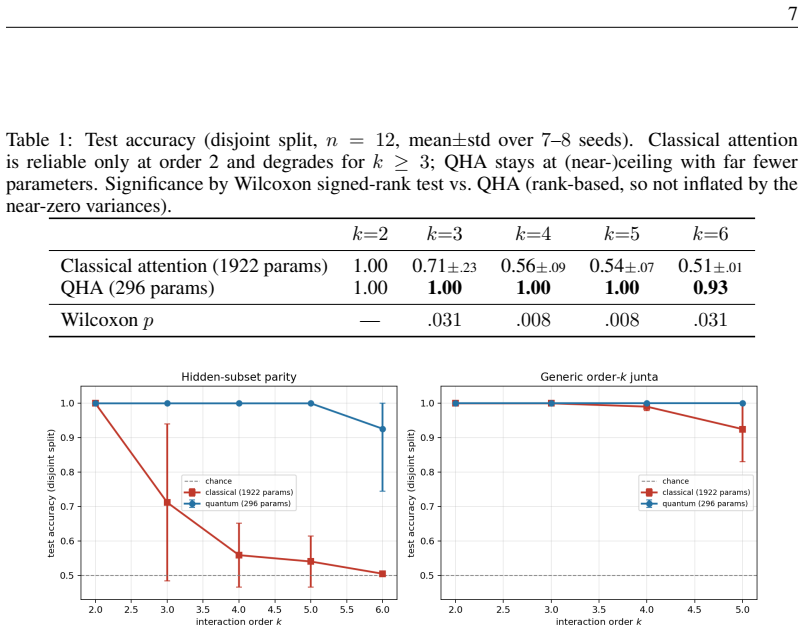
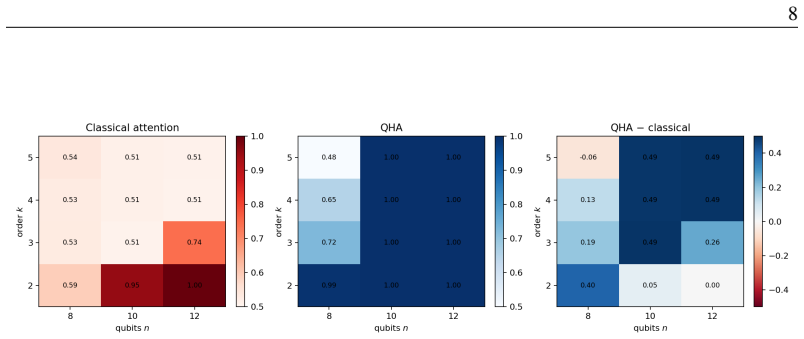
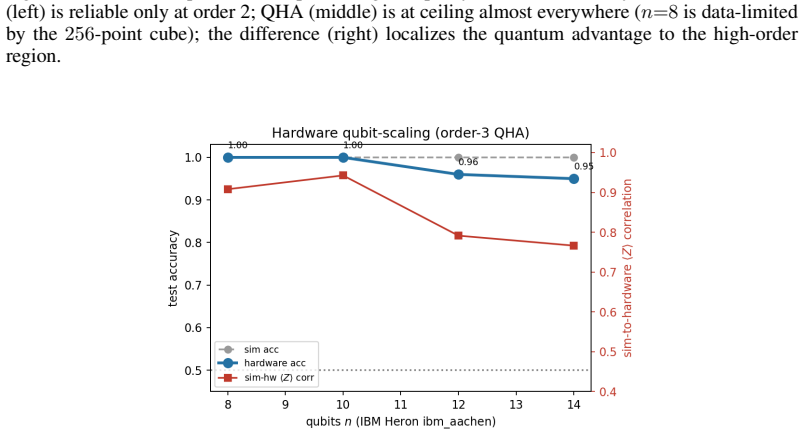
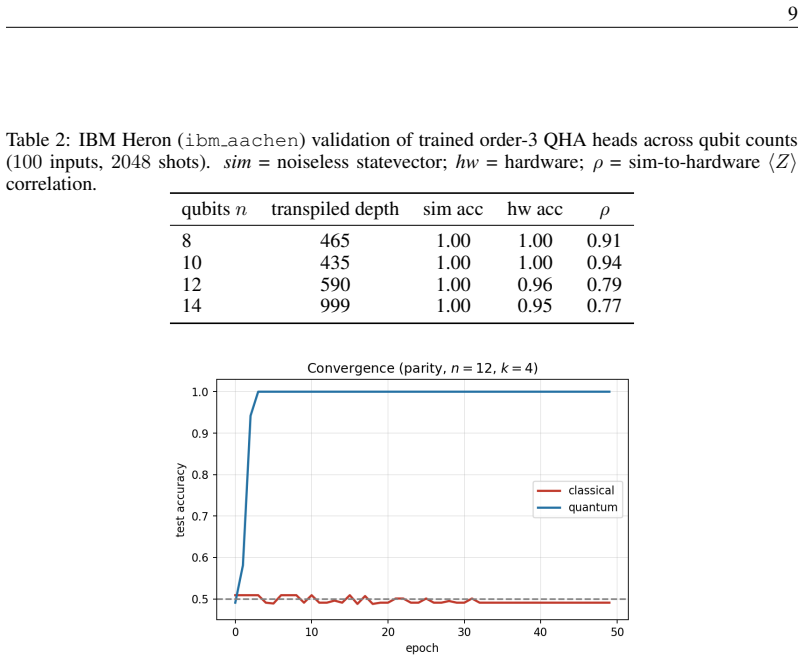
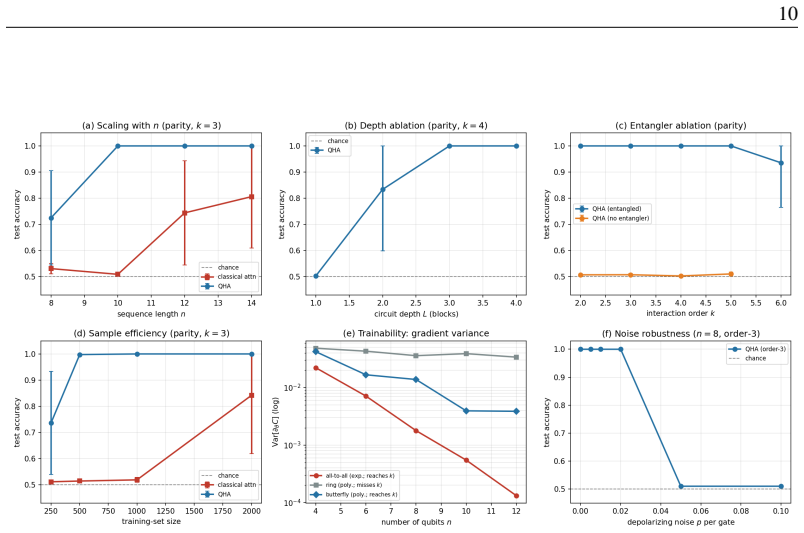
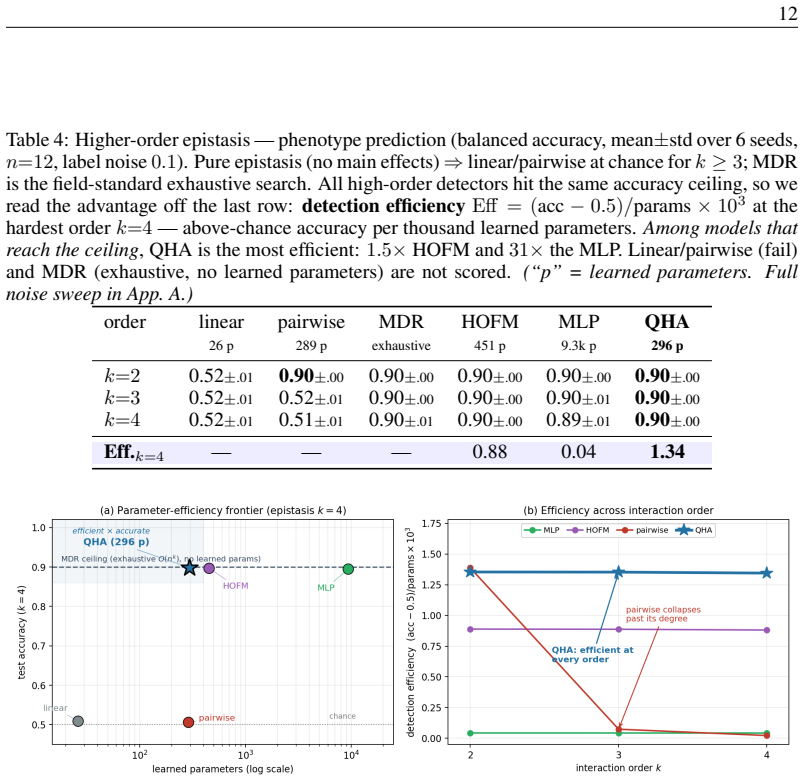
- QHA generalizes hidden-subset parity of every order k up to 6 from disjoint inputs at a 6.5 times smaller parameter budget while larger classical attention collapses past order 2.
- The size of the performance advantage tracks the target's Fourier degree and is largest for pure parity tasks.
- QHA functions as a compact high-order interaction detector that reaches the noise ceiling on genetic epistasis, learning parity with noise, and graph triangle detection where linear methods fail.
Where Pith is reading between the lines
- If the local-design version scales, transformers could replace several classical attention layers with one quantum head when sequences contain high-order dependencies.
- The separation result suggests quantum circuits may offer a route to constant-depth high-order feature extraction that classical depth scaling cannot match at fixed width.
- Empirical training of the all-to-all version despite decaying gradients indicates that practical optimization may remain viable even when theoretical variance bounds are not met.
Load-bearing premise
The classical attention model remains limited to order-2 interactions under the stated bounds on embedding dimension, number of heads, and bit precision.
What would settle it
A classical self-attention layer with mHp = o(N/log log N) that exactly computes the same order-k correlation functions represented by one QHA head of depth O(log k).
Figures
read the original abstract
Standard dot-product self-attention computes, in a single layer, only pairwise (order-2) interactions between tokens; representing a generic order-$k$ interaction is known to require either super-quadratic resources in one layer or composition across depth. We introduce \textbf{Quantum Higher-Order Attention (QHA)}, a shallow, hardware-realizable quantum attention head that, via data re-uploading and an all-to-all non-Clifford entangler, synthesizes order-$k$ token interactions inside the circuit and exposes them through a local single-qubit read-out. We prove (i) an expressivity separation: any single standard self-attention layer with embedding dimension $m$, $H$ heads and $p$-bit precision satisfying $mHp=o(N/\log\log N)$ cannot represent the order-$k$ correlation family that one QHA head represents with circuit depth $O(\log k)$ ($O(k)$ two-qubit gates); and (ii) a trainability guarantee for its local-design instantiation: with a local read-out and $O(\log n)$ depth the gradient variance is $\Omega(1/\mathrm{poly}(n))$ (no barren plateau), which we confirm empirically -- while being explicit that the more expressive all-to-all instantiation we benchmark is trained empirically and shows exponentially decaying gradients. Empirically, at a $6.5\times$ smaller parameter budget, QHA generalizes hidden-subset parity of every order $k\le6$ from disjoint inputs, whereas the larger classical attention head collapses past order~2; consistent with theory, the size of the advantage tracks the target's Fourier degree - largest for parity and shrinking when low-order structure is present. As an application, QHA serves as a compact high-order interaction detector across three domains - genetic epistasis, learning-parity-with-noise, and graph triangle detection - reaching the noise ceiling at the smallest parameter budget where field-standard linear methods fail.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Quantum Higher-Order Attention (QHA), a shallow quantum circuit attention head using data re-uploading and all-to-all non-Clifford entangling gates to synthesize order-k token interactions with local readout. It claims (i) an expressivity separation proving that any classical single-layer self-attention with embedding dimension m, H heads and p-bit precision where mHp = o(N/log log N) cannot represent the order-k correlation family that one QHA head realizes at O(log k) depth (O(k) two-qubit gates), and (ii) a trainability guarantee of gradient variance Ω(1/poly(n)) with no barren plateau for the local-design instantiation at O(log n) depth; empirical results at 6.5× smaller parameter budget show QHA generalizing hidden-subset parity up to k=6 while classical attention fails beyond order 2, with applications to epistasis, LPN, and triangle detection.
Significance. If the separation and local-design trainability hold, the result would be significant for quantum machine learning by demonstrating a hardware-efficient mechanism for higher-order interactions beyond the pairwise limit of standard attention, with the paper's explicit distinction between the guaranteed local variant and the empirically benchmarked all-to-all variant adding credibility. The tracking of advantage size with Fourier degree and the compact parameter budget on multiple domains strengthen the case for practical relevance if the central claims are substantiated.
major comments (2)
- [Abstract] Abstract (trainability guarantee paragraph): the expressivity separation is proven for the all-to-all QHA head, but the gradient-variance lower bound Ω(1/poly(n)) and absence of barren plateau are stated only for the local-design instantiation with local readout and O(log n) depth; the empirical benchmarks (hidden-subset parity, genetic epistasis, etc.) use the all-to-all version, which the abstract explicitly notes exhibits exponentially decaying gradients. This mismatch is load-bearing for the claim that the 6.5× parameter-budget advantage is achievable under a regime with proven trainability.
- [Abstract] Abstract (expressivity separation claim): the statement that classical attention with mHp=o(N/log log N) cannot represent the order-k family represented by one QHA head requires the precise definition of that correlation family, the exact circuit construction (data re-uploading plus all-to-all non-Clifford entangler), and the resource counting to be shown to be non-circular with respect to the classical bound; without these details the separation cannot be verified as load-bearing for the central claim.
minor comments (1)
- The abstract mentions 'O(k) two-qubit gates' for the QHA head; the main text should include an explicit gate-count table or circuit diagram relating depth O(log k) to this count for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (trainability guarantee paragraph): the expressivity separation is proven for the all-to-all QHA head, but the gradient-variance lower bound Ω(1/poly(n)) and absence of barren plateau are stated only for the local-design instantiation with local readout and O(log n) depth; the empirical benchmarks (hidden-subset parity, genetic epistasis, etc.) use the all-to-all version, which the abstract explicitly notes exhibits exponentially decaying gradients. This mismatch is load-bearing for the claim that the 6.5× parameter-budget advantage is achievable under a regime with proven trainability.
Authors: The abstract already states the distinction between the proven trainability guarantee for the local-design instantiation and the empirical training of the all-to-all version (which exhibits decaying gradients). We agree, however, that the wording around the 6.5× parameter-budget advantage could be clarified to avoid any implication that this empirical result occurs under the proven trainability regime. We will revise the abstract to make this separation more explicit while preserving the existing distinction. revision: partial
-
Referee: [Abstract] Abstract (expressivity separation claim): the statement that classical attention with mHp=o(N/log log N) cannot represent the order-k family represented by one QHA head requires the precise definition of that correlation family, the exact circuit construction (data re-uploading plus all-to-all non-Clifford entangler), and the resource counting to be shown to be non-circular with respect to the classical bound; without these details the separation cannot be verified as load-bearing for the central claim.
Authors: The precise definition of the order-k correlation family, the circuit construction (data re-uploading plus all-to-all non-Clifford entangler), and the independent resource counting for the classical bound (based solely on mHp and p-bit precision) are all provided in the main text. The classical bound is derived from parameter counting and does not rely on the quantum construction, avoiding circularity. To improve verifiability from the abstract alone, we will add a brief cross-reference to the relevant sections. revision: partial
Circularity Check
No circularity: expressivity separation and trainability results are independent mathematical claims
full rationale
The paper states explicit proofs of an expressivity separation (any classical single-layer attention with mHp=o(N/log log N) cannot represent the order-k family that one QHA head does with O(log k) depth) and a trainability guarantee (gradient variance Ω(1/poly(n)) for the local-design instantiation with O(log n) depth). These are presented as derived from circuit analysis and variance calculations rather than reducing by the paper's own equations to fitted parameters, self-referential definitions, or load-bearing self-citations. The explicit distinction between the local-design guarantee and the all-to-all empirical benchmarks further indicates the claims do not collapse into tautologies or renamings of inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Quantum circuits support data re-uploading and all-to-all non-Clifford entanglers that can be realized on hardware
invented entities (1)
-
Quantum Higher-Order Attention (QHA) head
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Joseph Bowles, Shahnawaz Ahmed, and Maria Schuld. Better than classical? the subtle art of benchmarking quantum machine learning models.arXiv preprint arXiv:2403.07059,
-
[2]
Chi-Sheng Chen and En-Jui Kuo. Do quantum transformers help? a systematic vqc architecture comparison on tabular benchmarks.arXiv preprint arXiv:2604.23931,
-
[3]
Quantum vision transformers.Quantum, 8(arXiv: 2209.08167):1265,
El Amine Cherrat, Iordanis Kerenidis, Natansh Mathur, Jonas Landman, Martin Strahm, and Yun Yvonna Li. Quantum vision transformers.Quantum, 8(arXiv: 2209.08167):1265,
-
[4]
Quixer: A quantum transformer model.arXiv preprint arXiv:2406.04305,
Nikhil Khatri, Gabriel Matos, Luuk Coopmans, and Stephen Clark. Quixer: A quantum transformer model.arXiv preprint arXiv:2406.04305,
-
[5]
Alexander Kozachinskiy, Felipe Urrutia, Hector Jimenez, Tomasz Steifer, Germ ´an Pizarro, Mat´ıas Fuentes, Francisco Meza, Cristian B Calderon, and Crist ´obal Rojas. Strassen attention: Unlock- ing compositional abilities in transformers based on a new lower bound method.arXiv preprint arXiv:2501.19215,
-
[6]
Soroush Omranpour, Guillaume Rabusseau, and Reihaneh Rabbany. Higher order transformers: Efficient attention mechanism for tensor structured data.arXiv preprint arXiv:2412.02919,
-
[7]
Transformers, parallel computation, and loga- rithmic depth.arXiv preprint arXiv:2402.09268,
Clayton Sanford, Daniel Hsu, and Matus Telgarsky. Transformers, parallel computation, and loga- rithmic depth.arXiv preprint arXiv:2402.09268,
-
[8]
Transformer dissection: An unified understanding for transformer’s attention via the lens of kernel
Yao-Hung Hubert Tsai, Shaojie Bai, Makoto Yamada, Louis-Philippe Morency, and Ruslan Salakhutdinov. Transformer dissection: An unified understanding for transformer’s attention via the lens of kernel. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language proc...
2019
-
[9]
Hui Zhang, Qinglin Zhao, Mengchu Zhou, Li Feng, Dusit Niyato, Shenggen Zheng, and Lin Chen. A survey of quantum transformers: Architectures, challenges and outlooks.arXiv preprint arXiv:2504.03192,
-
[10]
Inputs areX∈ {−1,+1} n
15 16 A EXPERIMENTAL DETAILS Data.For sequence lengthnand orderk, a hidden supportS⊂[n],|S|=k, is drawn per seed. Inputs areX∈ {−1,+1} n. The label is eitherparity,y= Q i∈S xi, or ak-junta,y=T(x S)for a fixed balanced random truth tableT:{0,1} k → {0,1}(chance= 0.5). Train and test inputs are disjoint: for smallnwe enumerate the Boolean cube and partition...
2000
-
[11]
number of edges
uses 7–8seeds; the broader baseline and application studies use3. We report each run’s best-epoch accuracy on thedisjointtest set. Because the classical head stays at chance ateveryepoch fork≥3 (and QHA reaches the ceiling within a few epochs without subsequent decay, Fig. 6), the separation reflects representational capacity rather than epoch selection: ...
2023
-
[12]
So no single attention layer withmHp= o(N/log logN)computes MATCH k fork≥3; thek= 3case recovers Sanford et al
gives budget =mHp= Ω N 2O(k) log logN , which for everyfixedkisΩ(N/log logN). So no single attention layer withmHp= o(N/log logN)computes MATCH k fork≥3; thek= 3case recovers Sanford et al. (2023), Thm
2023
-
[13]
Heisenberg picture
Remark (honest scope).The only non-textbook ingredient is the multiparty disjointness bound, whose constant degrades as2 −O(k); for the constant-kregime of our experiments this is immaterial, but removing it to get a bound uniform inkis left open (Sec. 7). The lemma is asingle-layer statement; multi-layer lower bounds for the same task are conjectural (Sa...
2023
-
[14]
5 confirms empirically — the role we assign to the experiments
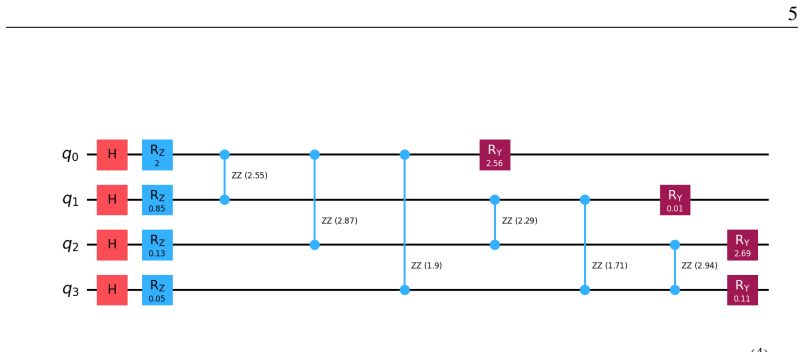
and is what Sec. 5 confirms empirically — the role we assign to the experiments. Resource count.Accumulating the parity with a balanced binary tree of CNOTs onto the support qubitr(rather than a chain) usesO(k)two-qubit gates at circuit depthO(logk). Each tree level is a set ofdisjoint(commuting)R ZZ couplings, which one QHA block’s all-to-all entangler r...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.