The Right Call for Software Benchmarking: Consistent Decisions in Stateful Environments
Pith reviewed 2026-06-27 02:21 UTC · model grok-4.3
The pith
Benchmarking can identify the fastest program consistently by estimating performance contrasts that cancel biases in stateful environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By formalizing software benchmarking as the decision problem of identifying the fastest program, for which relative knowledge suffices, the paper proposes simple experiment designs admitting consistent estimators of contrasts. These designs ensure that program-specific biases cancel under tenable assumptions, asymptotically yielding the correct decision and affording a robust methodology for finite-budget benchmarking in stateful environments.
What carries the argument
Consistent estimators of contrasts in simple experiment designs, which cancel program-specific biases without explicit modeling of system dynamics.
If this is right
- These designs asymptotically yield the correct decision about which program is fastest.
- They afford a robust methodology for finite-budget benchmarking in stateful environments.
- Broad implications for the development of performance-sensitive software follow from the focus on relative knowledge.
- Naive estimators of individual program performance are biased due to temporal dependencies from adaptive mechanisms.
Where Pith is reading between the lines
- Such designs might be adapted to benchmarking in other adaptive systems like machine learning training environments.
- Future work could test these designs on real hardware with known stateful behaviors to verify bias cancellation.
- Emphasizing contrasts could lead to new standards in performance evaluation that avoid absolute measures altogether.
Load-bearing premise
The experiment designs make program-specific biases cancel under tenable assumptions about system dynamics.
What would settle it
A counterexample where the proposed designs lead to an incorrect decision on program speed in a controlled stateful environment with measurable biases that do not cancel.
Figures

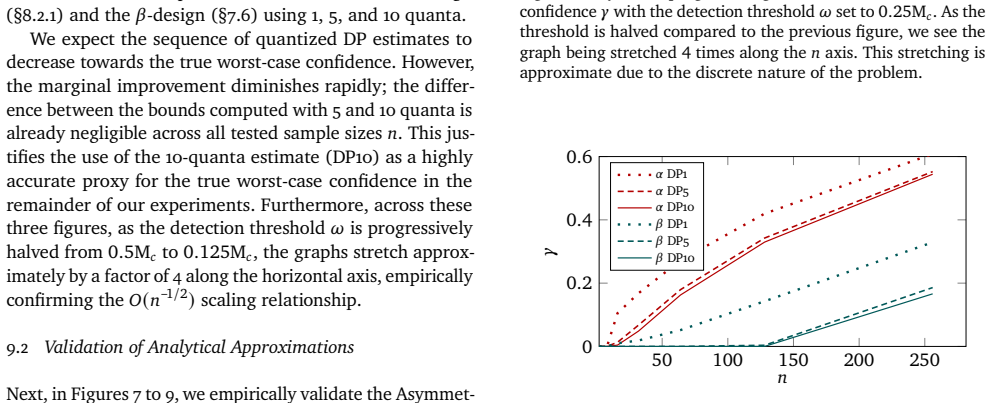

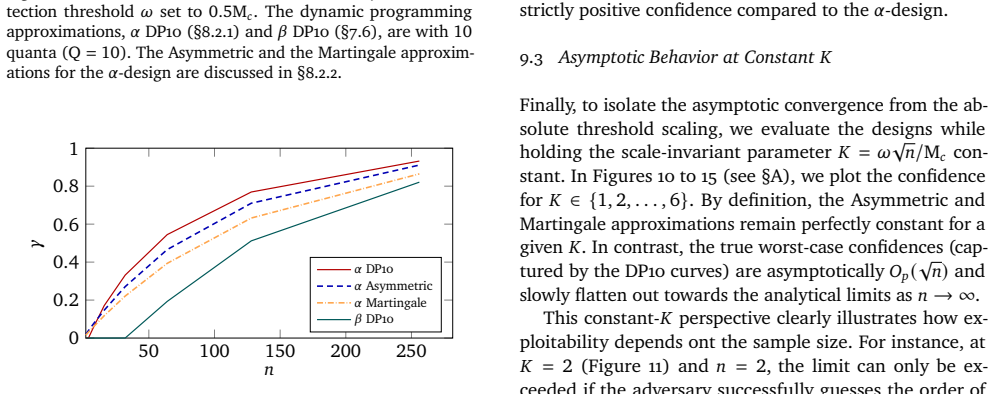
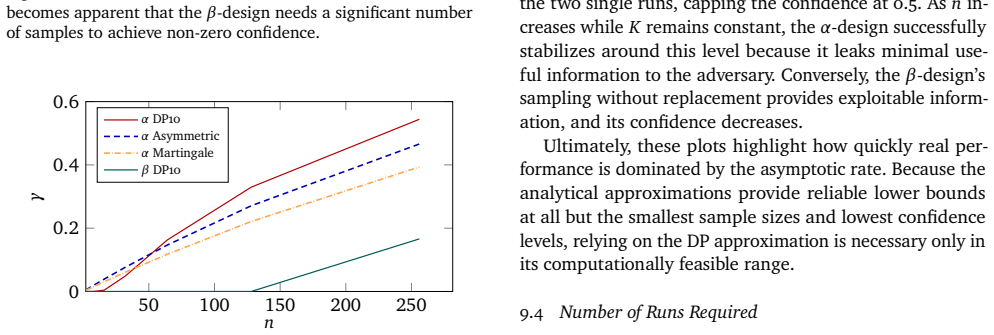
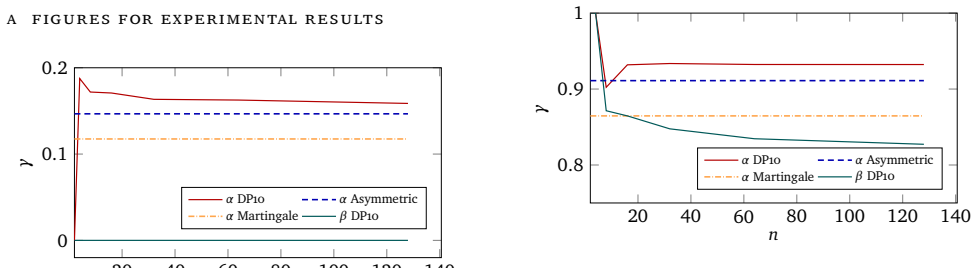
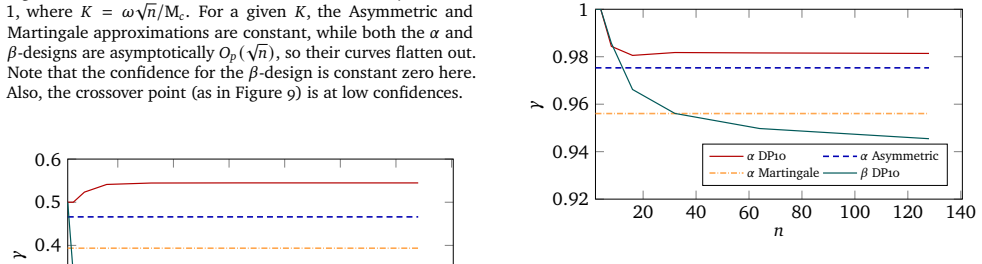

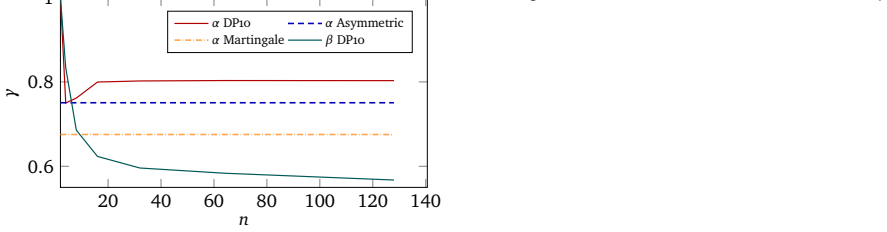
read the original abstract
In the perpetual pursuit of performance, modern computing systems rely ever more on stateful mechanisms to accommodate the dynamics of workloads and physical environments, bolstering efficiency but confounding benchmarking and thereby the optimization of software. Indeed, by their nature, adaptive mechanisms introduce temporal dependencies between measurements and render naive estimators of individual program performance biased. Observing that rectifying such biases necessitates speculative assumptions about system dynamics, we call for prioritizing performance differentials over absolute measures and formalize software benchmarking as the decision problem of identifying the fastest program, for which relative knowledge suffices. To this end, we propose simple experiment designs admitting consistent estimators of contrasts, whereby program-specific biases cancel under tenable assumptions. These designs asymptotically yield the correct decision and afford a robust methodology for finite-budget benchmarking in stateful environments, bearing broad implications for the development of performance-sensitive software.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that stateful mechanisms in modern computing systems introduce temporal dependencies that bias naive estimators of individual program performance. It reframes software benchmarking as the decision problem of identifying the fastest program (rather than estimating absolute performance), and proposes simple experiment designs that admit consistent estimators of performance contrasts. Under tenable assumptions on system dynamics, program-specific biases cancel, so that the designs asymptotically yield the correct decision and support robust finite-budget benchmarking.
Significance. If the consistency results hold, the work supplies a statistically grounded methodology that avoids the need to model system dynamics explicitly while still guaranteeing asymptotically correct identification of the best program. This has clear practical value for performance evaluation in adaptive environments and shifts emphasis from absolute metrics to relative contrasts, which aligns with the decision-theoretic nature of benchmarking.
minor comments (3)
- [Abstract] The abstract is dense and would benefit from a single concrete example of one of the proposed designs (e.g., the interleaving pattern or the contrast estimator formula) to make the central idea immediately accessible.
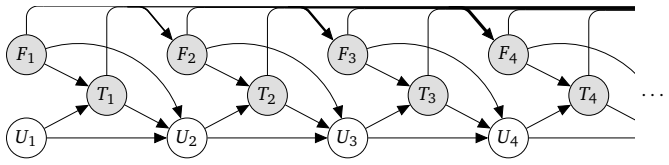
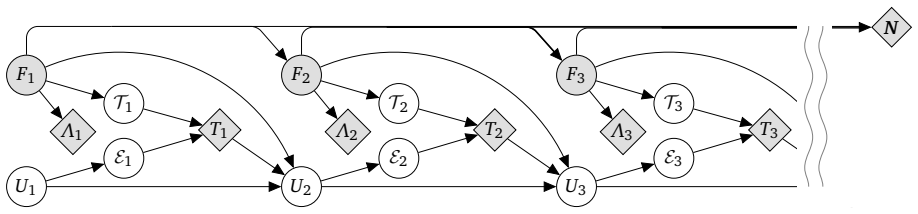
- [§3] Notation for the contrast estimators and the bias-cancellation conditions should be introduced with a small running example in the main text before the general theorems; the current presentation jumps directly to the general case.
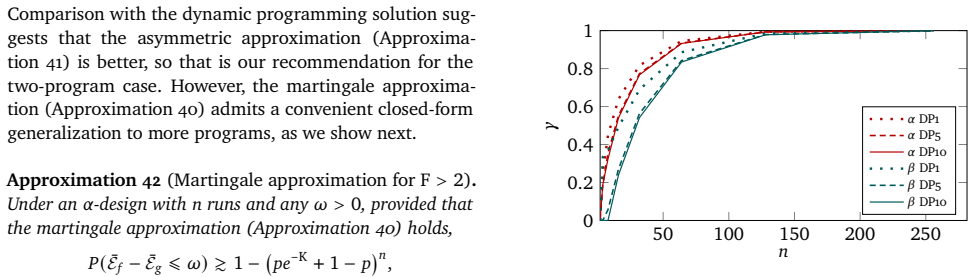
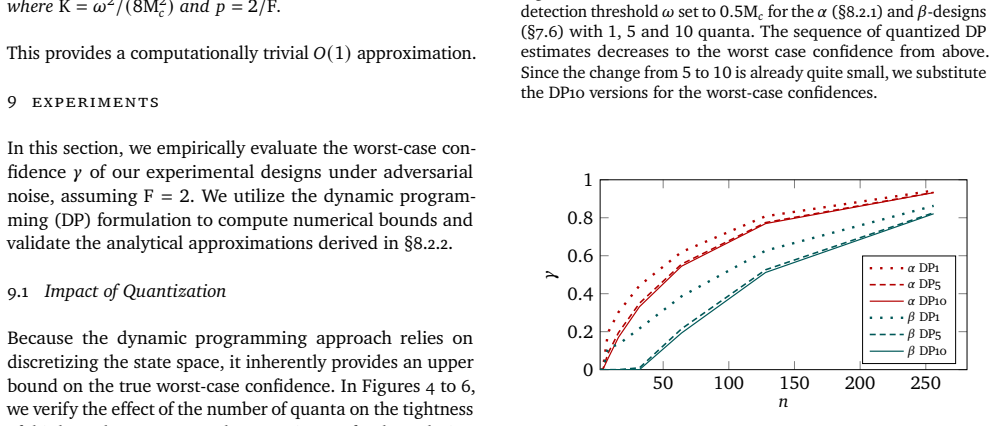
- [§5] Figure 2 (or equivalent) showing the finite-sample behavior of the decision error rate would be strengthened by adding a baseline that uses naive independent sampling, to quantify the practical gain of the proposed designs.
Simulated Author's Rebuttal
We thank the referee for the supportive summary, significance assessment, and recommendation of minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity; derivation is self-contained statistical argument
full rationale
The paper formalizes benchmarking as a decision problem of identifying the fastest program and proposes experiment designs whose consistent estimators of contrasts rely on program-specific biases canceling under stated assumptions about system dynamics. This is a direct application of standard statistical consistency results for relative estimators and does not reduce any claimed prediction or result to a fitted parameter, self-definition, or self-citation chain. No equations or steps in the provided abstract or claim description exhibit the enumerated circularity patterns; the argument remains independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Program-specific biases cancel under tenable assumptions in the proposed experiment designs for contrasts.
Reference graph
Works this paper leans on
-
[1]
Tracking down performance variation against source code evolution
Juan Pablo Sandoval Alcocer and Alexandre Bergel. Tracking down performance variation against source code evolution. ACM SIGPLAN Notices, 51 0 (2): 0 129--139, 2015
2015
-
[2]
Writing fast code, 2015
Andrei Alexandrescu. Writing fast code, 2015. URL https://www.youtube.com/watch?v=vrfYLlR8X8k&t=914s. Accessed: 2024-08-25
2015
-
[3]
Identification of causal effects using instrumental variables
Joshua D Angrist, Guido W Imbens, and Donald B Rubin. Identification of causal effects using instrumental variables. Journal of the American statistical Association, 91 0 (434): 0 444--455, 1996
1996
-
[4]
Virtual machine warmup blows hot and cold
Edd Barrett, Carl Friedrich Bolz-Tereick, Rebecca Killick, Sarah Mount, and Laurence Tratt. Virtual machine warmup blows hot and cold. Proceedings of the ACM on Programming Languages, 1 0 (OOPSLA): 0 1--27, 2017
2017
-
[5]
Conditional inference from confidence sets
George Casella. Conditional inference from confidence sets. Lecture Notes-Monograph Series, pages 1--12, 1992
1992
-
[6]
Robust benchmarking in noisy environments
Jiahao Chen and Jarrett Revels. Robust benchmarking in noisy environments. arXiv preprint arXiv:1608.04295, 2016
Pith/arXiv arXiv 2016
-
[7]
Statistical performance comparisons of computers
Tianshi Chen, Qi Guo, Olivier Temam, Yue Wu, Yungang Bao, Zhiwei Xu, and Yunji Chen. Statistical performance comparisons of computers. IEEE Transactions on Computers, 64 0 (5): 0 1442--1455, 2014
2014
-
[8]
Planning of experiments
David Roxbee Cox. Planning of experiments. Wiley, 1958
1958
-
[9]
Stabilizer: S tatistically sound performance evaluation
Charlie Curtsinger and Emery D Berger. Stabilizer: S tatistically sound performance evaluation. ACM SIGARCH Computer Architecture News, 41 0 (1): 0 219--228, 2013
2013
-
[10]
Paired benchmarking: H ow to measure performance, 2023
Denis Bazhenov . Paired benchmarking: H ow to measure performance, 2023. URL https://www.bazhenov.me/posts/paired-benchmarking/. Accessed: 2024-03-03
2023
-
[11]
An introduction to probability theory and its applications
William Feller. An introduction to probability theory and its applications. John Wiley & Sons, 3 edition, 1968. ISBN 978-0-471-25708-0
1968
-
[12]
Statistically rigorous J ava performance evaluation
Andy Georges, Dries Buytaert, and Lieven Eeckhout. Statistically rigorous J ava performance evaluation. ACM SIGPLAN Notices, 42 0 (10): 0 57--76, 2007
2007
-
[13]
A microbenchmark case study and lessons learned
Joseph Yossi Gil, Keren Lenz, and Yuval Shimron. A microbenchmark case study and lessons learned. In Proceedings of the compilation of the co-located workshops on DSM'11, TMC'11, AGERE! 2011, AOOPES'11, NEAT'11, & VMIL'11, pages 297--308, 2011
2011
-
[14]
Longest interval between zeros of the tied-down random walk, the B rownian bridge and related renewal processes
Claude Godreche. Longest interval between zeros of the tied-down random walk, the B rownian bridge and related renewal processes. Journal of Physics A: Mathematical and Theoretical, 50 0 (19): 0 195003, 2017
2017
-
[15]
URL https://github.com/google/benchmark/
Google Benchmark l ibrary, 2020. URL https://github.com/google/benchmark/. Accessed: 2024-04-14
2020
-
[16]
Frequentist post-data inference
Constantinos Goutis and George Casella. Frequentist post-data inference. International Statistical Review/Revue Internationale de Statistique, pages 325--344, 1995
1995
-
[17]
Continuous benchmarking: U sing system benchmarking in build pipelines
Martin Grambow, Fabian Lehmann, and David Bermbach. Continuous benchmarking: U sing system benchmarking in build pipelines. In 2019 IEEE International Conference on Cloud Engineering (IC2E), pages 241--246. IEEE, 2019
2019
-
[18]
Benchmarking as empirical standard in software engineering research
Wilhelm Hasselbring. Benchmarking as empirical standard in software engineering research. In Proceedings of the 25th International Conference on Evaluation and Assessment in Software Engineering, pages 365--372, 2021
2021
-
[19]
An alternative to the kolmogrov-smirnov two-sample test
Walter Katzenbeisser and Peter Hackl. An alternative to the kolmogrov-smirnov two-sample test. Communications in Statistics-Theory and Methods, 15 0 (4): 0 1163--1177, 1986
1986
-
[20]
A note on the higher moments of the random variable t associated with the number of returns of a simple random walk
Walter Katzenbeisser and Wolfgang Panny. A note on the higher moments of the random variable t associated with the number of returns of a simple random walk. Advances in applied probability, 18 0 (1): 0 279--282, 1986
1986
-
[21]
The structure of scientific revolutions, volume 962
Thomas S Kuhn. The structure of scientific revolutions, volume 962. University of Chicago press Chicago, 1997
1997
-
[22]
War of the benchmark means: T ime for a truce
John R Mashey. War of the benchmark means: T ime for a truce. ACM SIGARCH Computer Architecture News, 32 0 (4): 0 1--14, 2004
2004
-
[23]
Producing wrong data without doing anything obviously wrong! ACM Sigplan Notices, 44 0 (3): 0 265--276, 2009
Todd Mytkowicz, Amer Diwan, Matthias Hauswirth, and Peter F Sweeney. Producing wrong data without doing anything obviously wrong! ACM Sigplan Notices, 44 0 (3): 0 265--276, 2009
2009
-
[24]
Theory of games and economic behavior
John von Neumann and Oskar Morgenstern. Theory of games and economic behavior. Princeton University Press, Princeton, NJ, USA, 1944
1944
-
[25]
Using benchmarking to advance research: A challenge to software engineering
Susan Elliott Sim, Steve Easterbrook, and Richard C Holt. Using benchmarking to advance research: A challenge to software engineering. In 25th International Conference on Software Engineering, 2003. Proceedings., pages 74--83. IEEE, 2003
2003
-
[26]
SPEC CPU 2006 B enchmarks, 2006
SPEC . SPEC CPU 2006 B enchmarks, 2006. URL http://www.spec.org/cpu2006/. Accessed: 2024-08-20
2006
-
[27]
Some pairwise independent sequences for which the central limit theorem fails
Janson Svante. Some pairwise independent sequences for which the central limit theorem fails. Stochastics: An International Journal of Probability and Stochastic Processes, 23 0 (4): 0 439--448, 1988
1988
-
[28]
Should computer scientists experiment more? Computer, 31 0 (5): 0 32--40, 1998
Walter F Tichy. Should computer scientists experiment more? Computer, 31 0 (5): 0 32--40, 1998
1998
-
[29]
Dynamic frequency scaling, 2024
Wikipedia . Dynamic frequency scaling, 2024. URL https://en.wikipedia.org/w/index.php?title=Dynamic_frequency_scaling&oldid=1215993085. Accessed: 2024-08-20
2024
-
[30]
Non-stationary A B tests
Yuhang Wu, Zeyu Zheng, Guangyu Zhang, Zuohua Zhang, and Chu Wang. Non-stationary A B tests. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 2079--2089, 2022
2079
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.