The Token Not Taken: Sampling, State, and the Stochasticity of AI Agents
Pith reviewed 2026-07-03 23:57 UTC · model grok-4.3
The pith
Separating token sampling from extrinsic sources clarifies why agentic AI systems vary across runs even under deterministic execution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
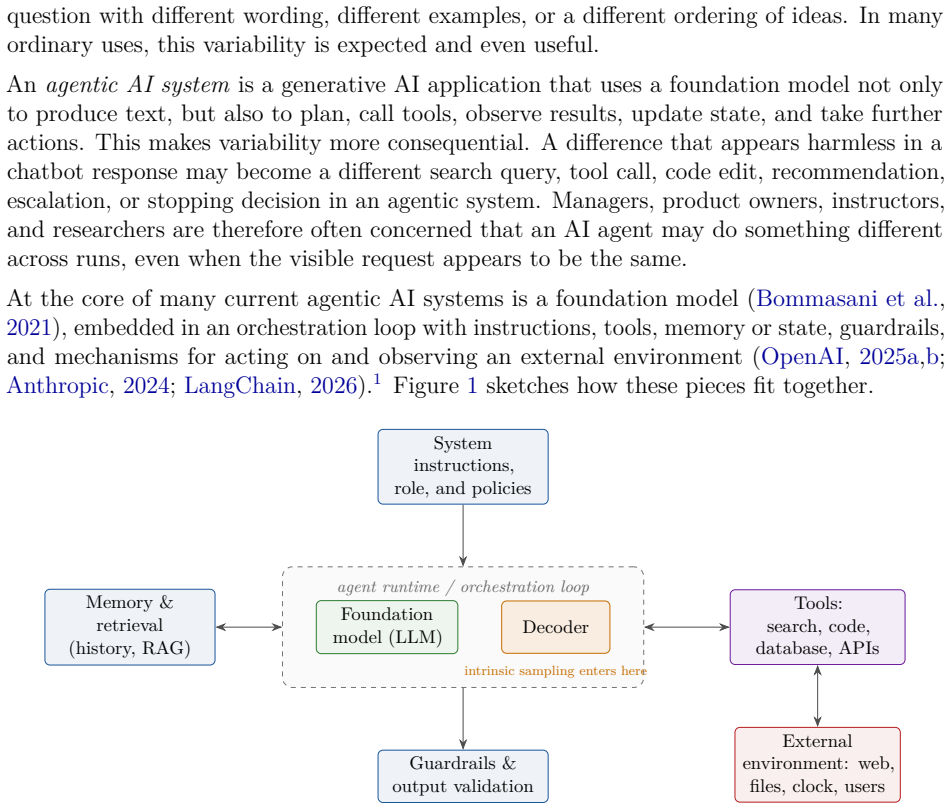
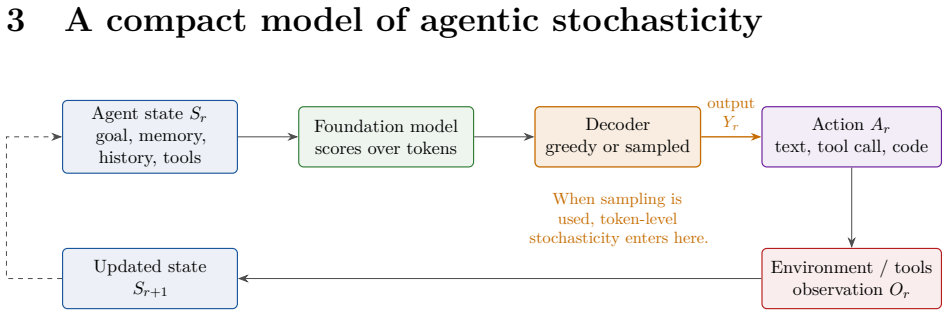
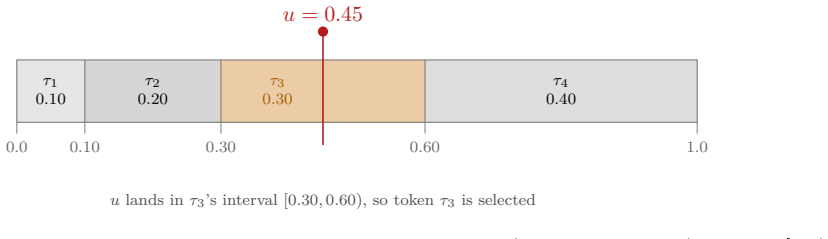
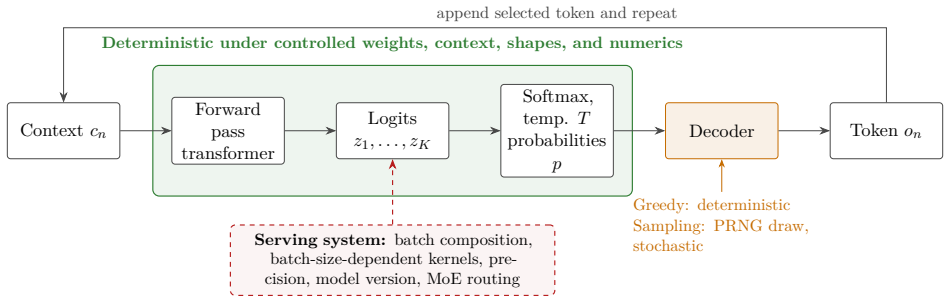
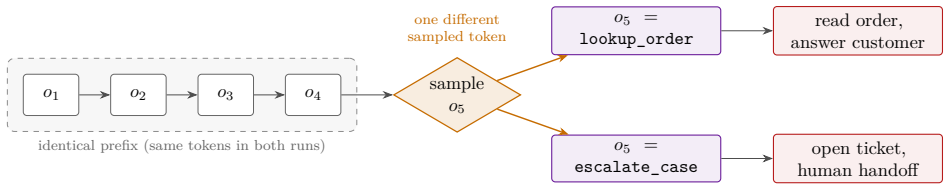
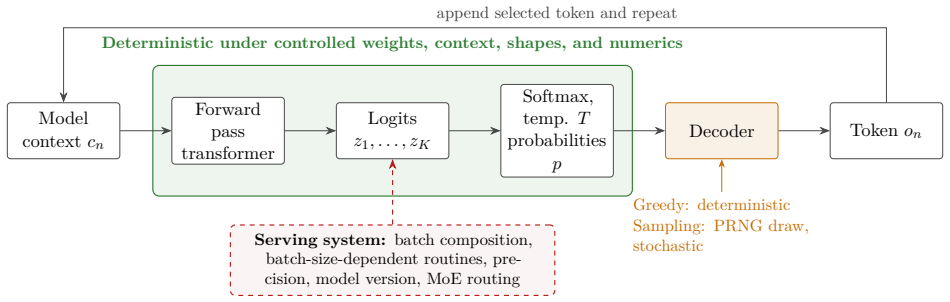
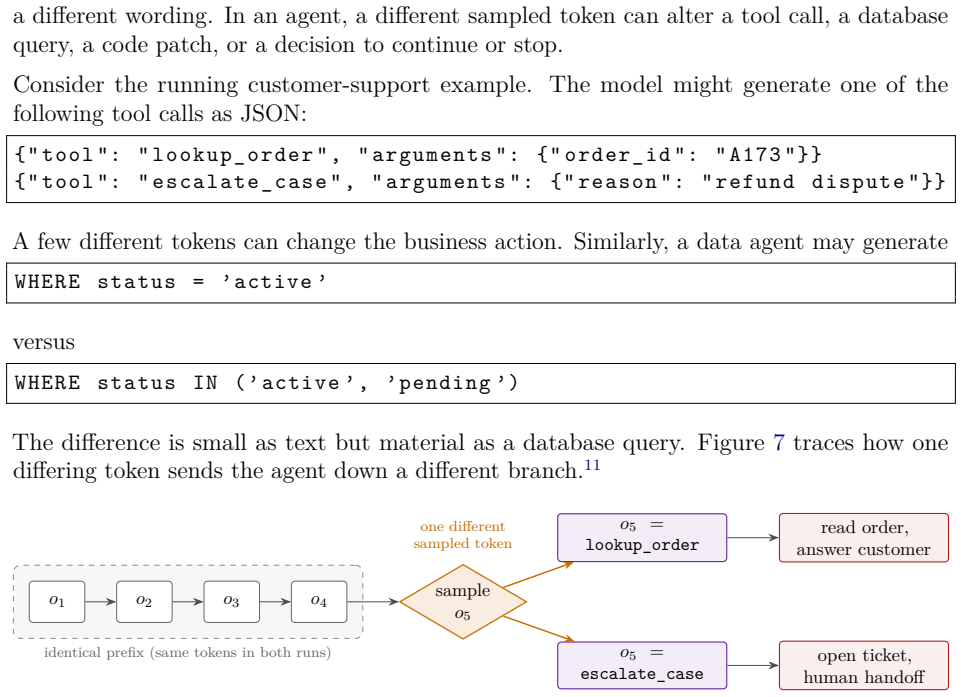
Agentic AI systems can behave differently across runs because the same request may produce a different plan, tool call, code edit, or final answer. Such variability arises from several layers that are often conflated. At the core is a foundation model embedded in an orchestration loop that plans, calls tools, observes results, and updates state. One explicit intrinsic source is token generation, where scores over next tokens are converted to probabilities and a decoder samples using a pseudo-random number generator, allowing small differences to cascade downstream. Other sources are extrinsic, including changing environments, live data, serving infrastructure, batch effects, and numerical de
What carries the argument
The partition of variability sources into intrinsic token-sampling effects (from the model's probability distribution and pseudo-random decoder) versus extrinsic effects (environment, data, infrastructure) within the foundation-model orchestration loop.
If this is right
- Variability from token sampling can be reproduced by matching the pseudo-random number generator state.
- Deterministic execution of the orchestration loop can still yield non-identical agent behavior when extrinsic factors differ.
- Controlling only the sampling layer leaves other sources of non-reproducibility unaddressed.
- Understanding the layers allows targeted interventions to reduce or isolate specific forms of variability.
Where Pith is reading between the lines
- Testing frameworks could record and replay both the random seed and the extrinsic context to isolate which layer drives a given difference.
- Safety evaluations of agents may need separate protocols for sampling-induced versus environment-induced divergences.
- Deployment pipelines might log the full state of the orchestration loop to diagnose whether observed changes trace to sampling or to external inputs.
Load-bearing premise
The sources of variability can be cleanly partitioned into intrinsic token-sampling effects and extrinsic effects with limited interaction that would blur the distinction in real deployments.
What would settle it
Running an agentic system multiple times with identical inputs, fixed random seeds, and controlled environments yet still observing divergent tool calls or state updates would indicate that the clean partition does not hold.
Figures


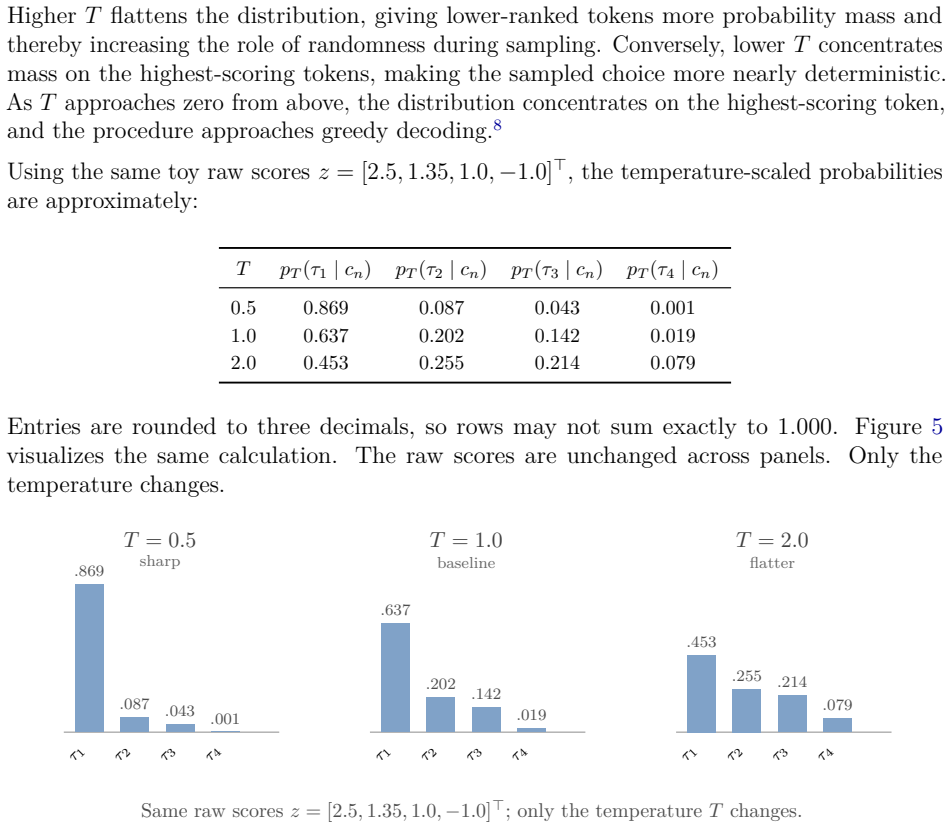
read the original abstract
Agentic AI systems can behave differently across runs: the same request may produce a different plan, a different tool call, a different code edit, or a different final answer. Such variability arises from several layers that are often conflated. At the core of many current agents is a foundation model, a large pretrained model adaptable to many downstream tasks, embedded in an orchestration loop that plans, calls tools, observes results, and updates state. One explicit intrinsic source of variability in such systems is token generation: the model computes scores over possible next tokens, the scores are converted into probabilities, and a decoder may sample tokens using a pseudo-random number generator. A small sampled token difference can then cascade downstream into a different tool call, code path, search query, or agent state. Other sources of variability are extrinsic to token sampling, including changing environments, live data, serving infrastructure, batch effects, and numerical details. By separating these layers, this tutorial clarifies what it means to call agentic AI systems stochastic, when such variability can be reproduced under matched conditions, and why deterministic execution need not imply identical behavior in deployed settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a tutorial that distinguishes intrinsic variability in agentic AI systems—arising from token sampling in foundation models during autoregressive decoding—from extrinsic sources such as changing environments, serving infrastructure, batch effects, and numerical details. It claims that cleanly separating these layers clarifies what it means to describe such systems as stochastic, identifies when variability can be reproduced under matched conditions, and explains why deterministic execution need not produce identical behavior in deployed settings.
Significance. If the separation can be maintained, the tutorial offers a clear conceptual framework for reasoning about reproducibility and stochasticity in agent loops, which could aid experiment design and deployment analysis. The work is purely descriptive with no free parameters, axioms, or invented entities, consistent with a tutorial format, but this also means it provides no empirical tests or formal models to anchor its distinctions.
major comments (1)
- [Abstract] Abstract: The central claim that intrinsic sampling effects and extrinsic factors can be partitioned with only limited interaction is load-bearing for the reproducibility distinction, yet the text supplies no independence condition, formal model of the agent loop, or worked example showing that a sampled token's downstream effect on state, tool calls, or queries does not materially alter the extrinsic inputs observed next.
Simulated Author's Rebuttal
We thank the referee for the detailed report and the opportunity to clarify the scope of our tutorial. The central concern is addressed point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that intrinsic sampling effects and extrinsic factors can be partitioned with only limited interaction is load-bearing for the reproducibility distinction, yet the text supplies no independence condition, formal model of the agent loop, or worked example showing that a sampled token's downstream effect on state, tool calls, or queries does not materially alter the extrinsic inputs observed next.
Authors: The manuscript is explicitly a conceptual tutorial and does not assert a formal statistical independence condition or supply a mathematical model of the agent loop; the separation is presented as a descriptive distinction between sources of variability rather than a claim of zero interaction. We acknowledge that the current text contains no worked example demonstrating traceability of downstream effects. To address this, we will revise the abstract to emphasize the conceptual nature of the distinction and add a short illustrative scenario in the main text showing how a single sampled token can produce a different tool call and subsequent observation while other extrinsic factors remain matched. This addition will not introduce formal axioms or empirical tests, consistent with the tutorial format. revision: yes
Circularity Check
No circularity; purely descriptive conceptual separation
full rationale
The manuscript is a tutorial that partitions variability sources into intrinsic token-sampling effects and extrinsic factors, then explains implications for reproducibility. No equations, fitted parameters, self-citations, or derivation steps appear in the provided text. The central claim is a clarification of terminology and conditions rather than a result obtained by reducing prior inputs to themselves. The separation is asserted as an organizing lens, not derived from any self-referential construction or ansatz. This is the expected non-finding for a non-mathematical descriptive paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Communications of the ACM , year =
Hydari, Muhammad Zia and Iqbal, Raja and Ramasubbu, Narayan , title =. Communications of the ACM , year =
-
[2]
and Adeli, Ehsan and Altman, Russ and Arora, Simran and von Arx, Sydney and Bernstein, Michael S
Bommasani, Rishi and Hudson, Drew A. and Adeli, Ehsan and Altman, Russ and Arora, Simran and von Arx, Sydney and Bernstein, Michael S. and Bohg, Jeannette and Bosselut, Antoine and Brunskill, Emma and others , title =. 2021 , url =
2021
-
[3]
2025 , howpublished =
2025
-
[4]
2023 , howpublished =
2023
-
[5]
2024 , howpublished =
2024
-
[6]
2026 , howpublished =
2026
-
[7]
2019 , howpublished =
2019
-
[8]
2025 , url =
He, Horace and. 2025 , url =
2025
-
[9]
and Kaiser, Lukasz and Polosukhin, Illia , title =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser, Lukasz and Polosukhin, Illia , title =. Advances in Neural Information Processing Systems , year =
-
[10]
, title =
Train, Kenneth E. , title =
-
[11]
International Conference on Learning Representations (ICLR) , year =
Holtzman, Ari and Buys, Jan and Du, Li and Forbes, Maxwell and Choi, Yejin , title =. International Conference on Learning Representations (ICLR) , year =
-
[12]
International Conference on Learning Representations (ICLR) , year =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , title =. International Conference on Learning Representations (ICLR) , year =
-
[13]
Advances in Neural Information Processing Systems , year =
Schick, Timo and Dwivedi-Yu, Jane and Dessi, Roberto and Raileanu, Roberta and Lomeli, Maria and Zettlemoyer, Luke and Cancedda, Nicola and Scialom, Thomas , title =. Advances in Neural Information Processing Systems , year =
-
[14]
and Burger, Doug and Wang, Chi , title =
Wu, Qingyun and Bansal, Gagan and Zhang, Jieyu and Wu, Yiran and Li, Beibin and Zhu, Erkang and Jiang, Li and Zhang, Xiaoyun and Zhang, Shaokun and Liu, Jiale and Awadallah, Ahmed Hassan and White, Ryen W. and Burger, Doug and Wang, Chi , title =. Conference on Language Modeling (COLM) , year =
-
[15]
Tool use with Claude
Anthropic . Tool use with Claude . Claude API documentation, 2024. URL https://perma.cc/H73D-K98H
2024
-
[16]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani, Drew A. Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S. Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the Opportunities and Risks of Foundation Models . Stanford CRFM, 2021. URL https://arxiv.org/abs/2108.07258
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
About GitHub Copilot cloud agent
GitHub . About GitHub Copilot cloud agent . GitHub Docs, 2025. URL https://perma.cc/P7C4-U93C
2025
-
[18]
Defeating Nondeterminism in LLM Inference
Horace He and Thinking Machines Lab . Defeating Nondeterminism in LLM Inference . Thinking Machines Lab: Connectionism, 2025. URL https://perma.cc/EQ8Z-BR32
2025
-
[19]
The Curious Case of Neural Text Degeneration
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration . In International Conference on Learning Representations (ICLR), 2020. URL https://arxiv.org/abs/1904.09751
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[20]
openai-community/gpt2
Hugging Face . openai-community/gpt2 . Hugging Face model repository, 2019. URL https://perma.cc/K4BD-FL76
2019
-
[21]
Generation strategies
Hugging Face . Generation strategies . Transformers documentation, 2026. URL https://perma.cc/26E6-N4GT
2026
-
[22]
Governing technical debt in agentic AI systems
Muhammad Zia Hydari, Raja Iqbal, and Narayan Ramasubbu. Governing technical debt in agentic AI systems . Communications of the ACM, in press
-
[23]
LangChain . Agents . LangChain documentation, 2026. URL https://perma.cc/L9AB-YLZE
2026
-
[24]
How to make your completions outputs consistent with the new seed parameter
OpenAI . How to make your completions outputs consistent with the new seed parameter . OpenAI Cookbook, 2023. URL https://perma.cc/S8BA-K5LH
2023
-
[25]
OpenAI . Agents . OpenAI Agents SDK documentation, 2025 a . URL https://perma.cc/B968-432N
2025
-
[26]
Agents SDK
OpenAI . Agents SDK . OpenAI API documentation, 2025 b . URL https://perma.cc/5X7Z-Z3R6
2025
-
[27]
OpenAI . Codex . OpenAI Developers documentation, 2025 c . URL https://perma.cc/U45T-X6SW
2025
-
[28]
OpenAI . Tools . OpenAI Agents SDK documentation, 2025 d . URL https://perma.cc/6WNJ-JYNY
2025
-
[29]
PyTorch . Dropout . PyTorch documentation, 2026 a . URL https://perma.cc/P5UD-HP55
2026
-
[30]
torch.multinomial
PyTorch . torch.multinomial . PyTorch documentation, 2026 b . URL https://perma.cc/KG62-JC5K
2026
-
[31]
Reproducibility
PyTorch . Reproducibility . PyTorch documentation, 2026 c . URL https://perma.cc/SX9P-7NQ8
2026
-
[32]
Toolformer: Language Models Can Teach Themselves to Use Tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools . In Advances in Neural Information Processing Systems, 2023. URL https://arxiv.org/abs/2302.04761
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Kenneth E. Train. Discrete Choice Methods with Simulation . Cambridge University Press, 2nd edition, 2009
2009
-
[34]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need . In Advances in Neural Information Processing Systems, 2017. URL https://arxiv.org/abs/1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[35]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W. White, Doug Burger, and Chi Wang. AutoGen: Enabling next-gen LLM applications via multi-agent conversation framework . In Conference on Language Modeling (COLM), 2024. URL https://arxiv.org/abs/2308.08155
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models . In International Conference on Learning Representations (ICLR), 2023. URL https://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.